Qwen3-TTS 모델 개요
Alibaba의 Qwen 팀은 최근 텍스트-음성 변환(TTS) 기술의 새로운 지평을 여는 Qwen3-TTS 시리즈를 전격 공개했습니다. 최근 인공지능 분야에서는 GPT-4o와 같이 텍스트, 오디오, 이미지를 통합적으로 이해하고 생성하는 옴니(Omni) 모델이 주목받고 있습니다.
그러나 기존의 고품질 음성 생성 기술이나 정교한 음성 복제(Voice Cloning) 기능은 대부분 폐쇄적인 상용 API 형태로만 제공되어, 연구자와 개발자들이 내부 구조를 파악하거나 직접 최적화하기 어려웠습니다. Qwen3-TTS는 이러한 한계를 극복하고자 모델의 가중치(Weights)는 물론, 핵심 기술인 음성 토크나이저(Tokenizer), 학습 코드, 그리고 상세한 기술 보고서(Technical Report)까지 Apache 2.0 라이선스 하에 완전히 공개했습니다.
Qwen3-TTS는 500만 시간(5 million hours)이 넘는 방대한 다국어 음성 데이터를 학습하여 탄생했습니다. 이를 통해 10개 이상의 언어에서 자연스러운 발화가 가능하며, 특히 실시간 대화형 AI 구축에 필수적인 스트리밍(Streaming) 능력과 사용자의 복잡한 지시사항을 이행하는 제어 가능성(Controllability)에서 탁월한 성능을 보여줍니다.
Qwen3-TTS 모델 라인업 및 기능
Qwen3-TTS는 사용 목적에 따라 Base, VoiceDesign, CustomVoice의 세 가지 주요 변형 모델로 제공되며, 모델 크기에 따라 0.6B와 1.7B로 나뉩니다. 모든 모델은 한국어를 비롯하여 중국어, 영어, 일본어, 독일어, 프랑스어, 러시아어, 포르투갈어, 스페인어, 이탈리아어 등 10개 언어를 지원합니다.
-
Qwen3-TTS-12Hz-1.7B-Base / 0.6B-Base: 가장 기본이 되는 파운데이션 모델입니다. 사용자 오디오 입력으로부터 단 **3초 만에 빠른 음성 복제(Rapid Voice Clone)**를 수행할 수 있습니다. 또한, 연구자들이나 개발자들이 특정 도메인이나 화자에 맞춰 다른 모델을 파인튜닝(Fine-tuning)하기 위한 베이스 모델로 활용됩니다.
-
Qwen3-TTS-12Hz-1.7B-VoiceDesign: 이 모델은 사용자의 텍스트 설명(Description)을 바탕으로 완전히 새로운 목소리를 창조하는 데 특화되어 있습니다. 예를 들어 "중저음의 신뢰감 있는 뉴스 앵커 톤으로"와 같은 자연어 입력을 받아 그에 맞는 음성을 디자인합니다.
-
Qwen3-TTS-12Hz-1.7B-CustomVoice / 0.6B-CustomVoice: CustomVoice 모델은 성별, 연령, 언어, 방언 등 다양한 조합을 커버하는 9가지 프리미엄 음색(Premium Timbres) 을 내장하고 있습니다. 또한 사용자의 지시사항(Instruction)에 따라 특정 대상의 음색 스타일을 정교하게 제어할 수 있는 기능을 제공합니다.
제공하는 모델별 지원 언어 및 기능은 다음과 같습니다:
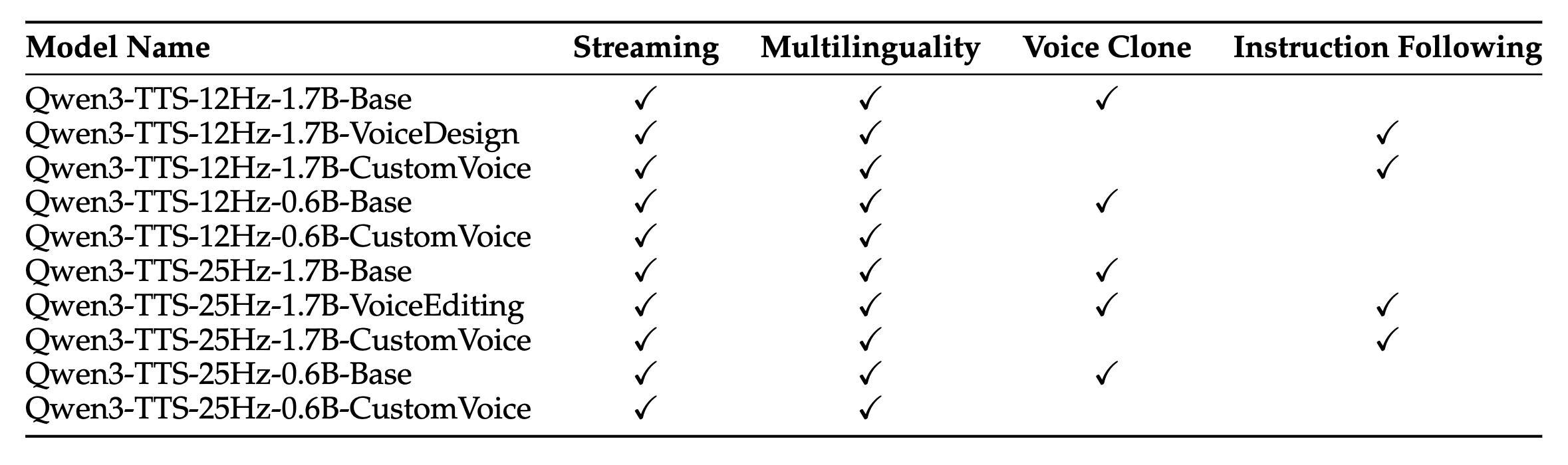
(모든 모델은 스트리밍(Streaming) 및 한국어를 포함한 다국어(Multilinguality) 기능을 기본적으로 지원합니다.)
Qwen3-TTS의 핵심: 이중 트랙(Dual-track) 구조와 토크나이저 전략
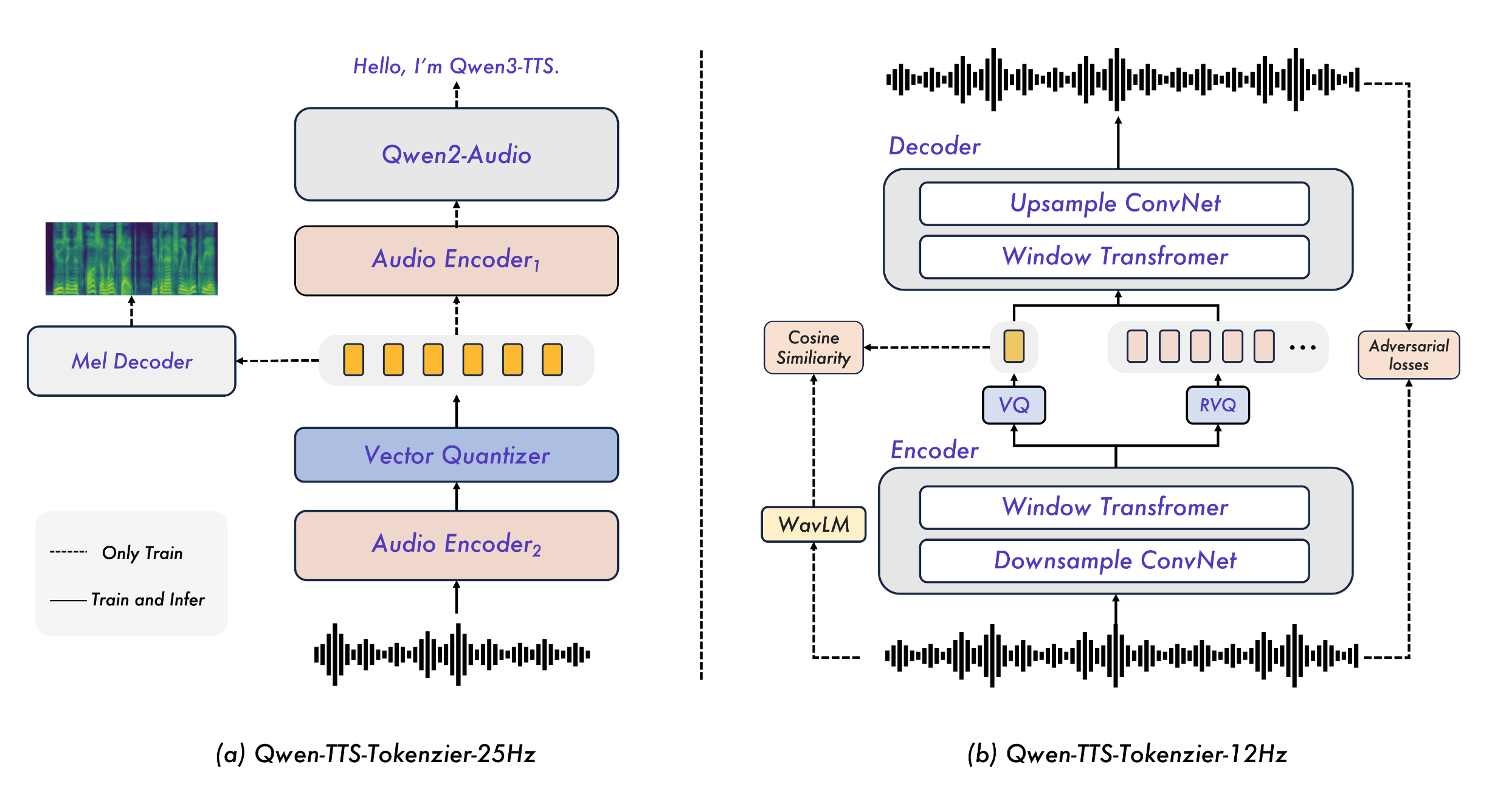
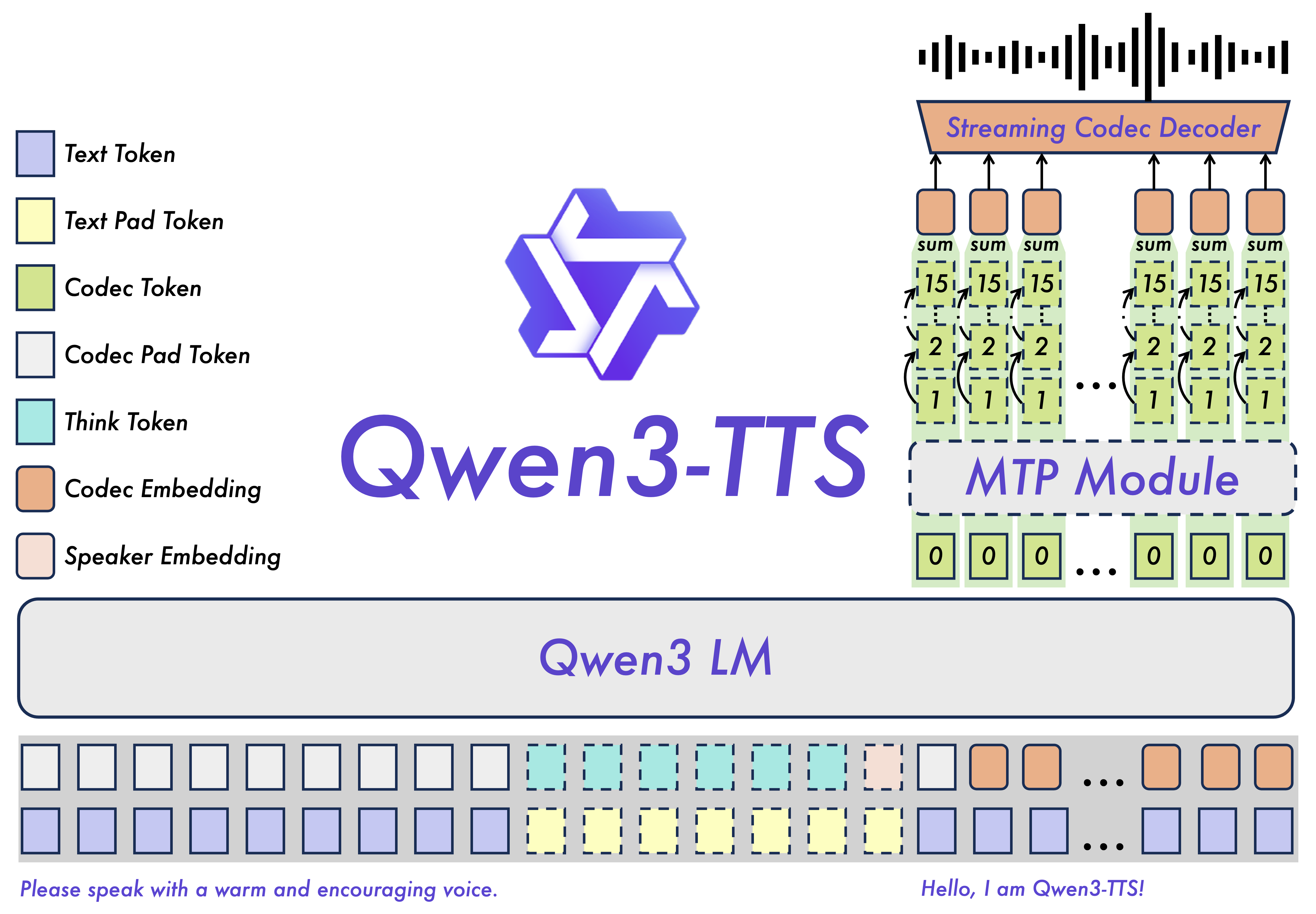
Qwen3-TTS의 가장 큰 기술적 특징은 전통적인 TTS 파이프라인(음향 모델 + 보코더)을 탈피하고, 대규모 언어 모델(LLM)의 아키텍처를 음성 생성에 도입했다는 점입니다. 하지만 단순히 LLM에 오디오를 입력하는 것을 넘어, Qwen-TTS-Tokenizer라는 독자적인 기술을 통해 오디오를 이산적인 토큰(Discrete Token)으로 변환하여 처리합니다.
Qwen 팀은 실시간성과 고품질이라는 두 마리 토끼를 잡기 위해 서로 다른 설계 철학을 가진 12Hz/25Hz의 두 가지 토크나이저를 개발했습니다. 이 두 토크나이저는 사용 목적에 따라 선택적으로 사용할 수 있으며, 각각의 작동 방식은 다음과 같습니다.
실시간성의 극대화(12Hz Tokenizer): Qwen-TTS-Tokenizer-12Hz
실시간 대화 시스템에서 가장 중요한 것은 응답 속도(Latency) 입니다. 이를 위해 개발된 12Hz 토크나이저는 오디오를 초당 12.5번이라는 매우 낮은 빈도로 샘플링하여 압축합니다. 이는 1초의 음성을 불과 12~13개의 토큰으로 표현한다는 의미이며, 덕분에 모델이 처리해야 할 데이터 양이 획기적으로 줄어듭니다.
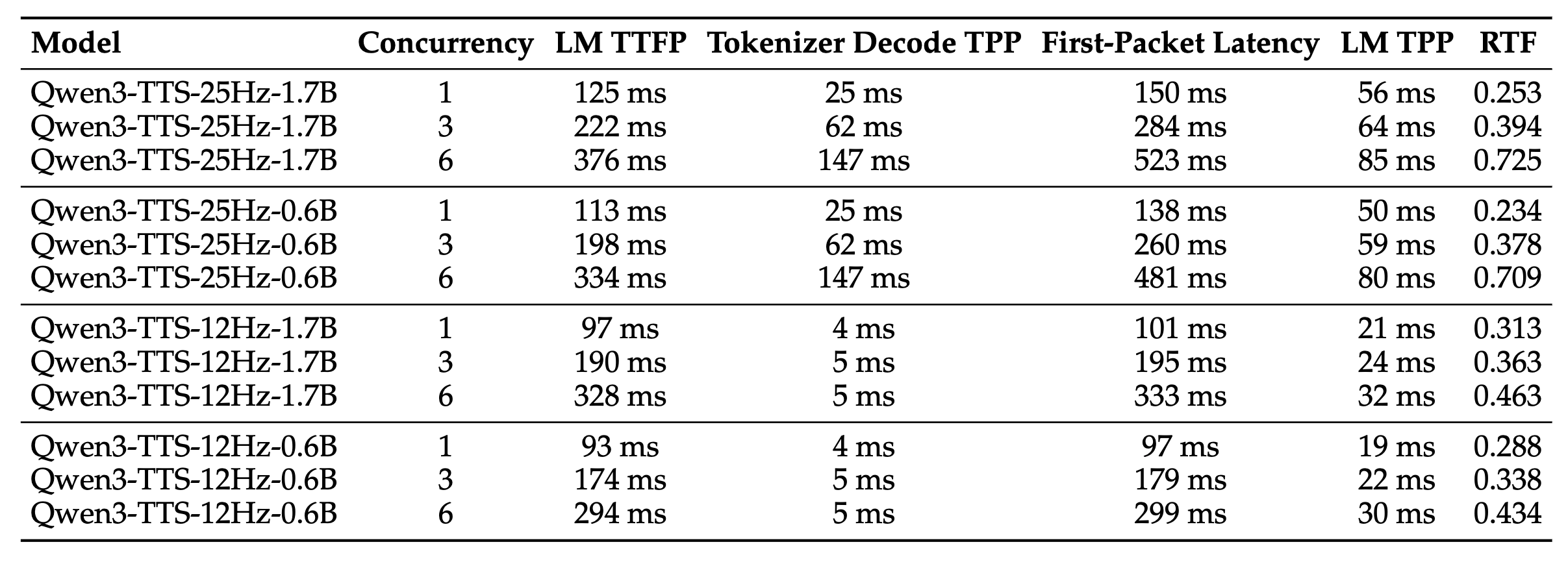
이 토크나이저는 다중 코드북(Multi-codebook) 구조를 채택하여 정보를 계층적으로 저장합니다. 첫 번째 코드북 레이어는 음성의 의미(Semantic) 정보를 담고, 이후의 레이어들이 음향적 디테일(Acoustic detail)과 운율을 보완하는 방식입니다. 특히 주목할 점은 완전한 인과적(Causal) 설계입니다. 일반적인 고품질 TTS가 음성을 생성할 때 미래의 정보를 참조(Look-ahead)해야 해서 지연 시간이 발생하는 반면, 12Hz 토크나이저는 가벼운 ConvNet 기반의 디코더를 사용하여 이전 시점의 데이터만으로 즉시 파형을 생성할 수 있습니다. 그 결과, 97ms(0.097초) 라는 극도로 짧은 시간 안에 첫 번째 오디오 패킷을 전송할 수 있어 사람이 지연을 거의 느끼지 못하는 수준의 실시간 대화를 구현합니다.
고품질과 안정성(25Hz Tokenizer): Qwen-TTS-Tokenizer-25Hz
반면, 영화 더빙이나 오디오북 제작처럼 '최상의 음질'과 '정교한 복제'가 목표라면 25Hz 토크나이저가 적합합니다. 이 모델은 초당 25회의 빈도로 음성을 토큰화하며, 단일 코드북(Single-codebook)을 사용하여 구조를 단순화했습니다.
25Hz 모델의 핵심은 Flow Matching 기반의 디퓨전 트랜스포머(DiT)를 디코더로 사용한다는 점입니다. 이는 최신 이미지 생성 AI가 사용하는 방식과 유사하게, 노이즈로부터 점진적으로 고품질의 멜-스펙트로그램(Mel-spectrogram)을 재구성해 냅니다. 이 과정에서 Qwen2-Audio 인코더가 추출한 풍부한 의미 정보와 음향 정보를 결합하여 매우 자연스럽고 깨끗한 음성을 만들어냅니다.
25Hz 모델은 비록 Flow Matching 과정에서 약간의 지연 시간(약 190ms)이 발생하지만, 생성된 음성의 품질과 안정성은 현존하는 오픈소스 모델 중 최상위권에 속합니다.
![]()
![]() Flow Matching과 관련해서는 다음 논문(Flow Matching for Generative Modeling)을 참고해주세요:
Flow Matching과 관련해서는 다음 논문(Flow Matching for Generative Modeling)을 참고해주세요:
Qwen3-TTS 모델 구조
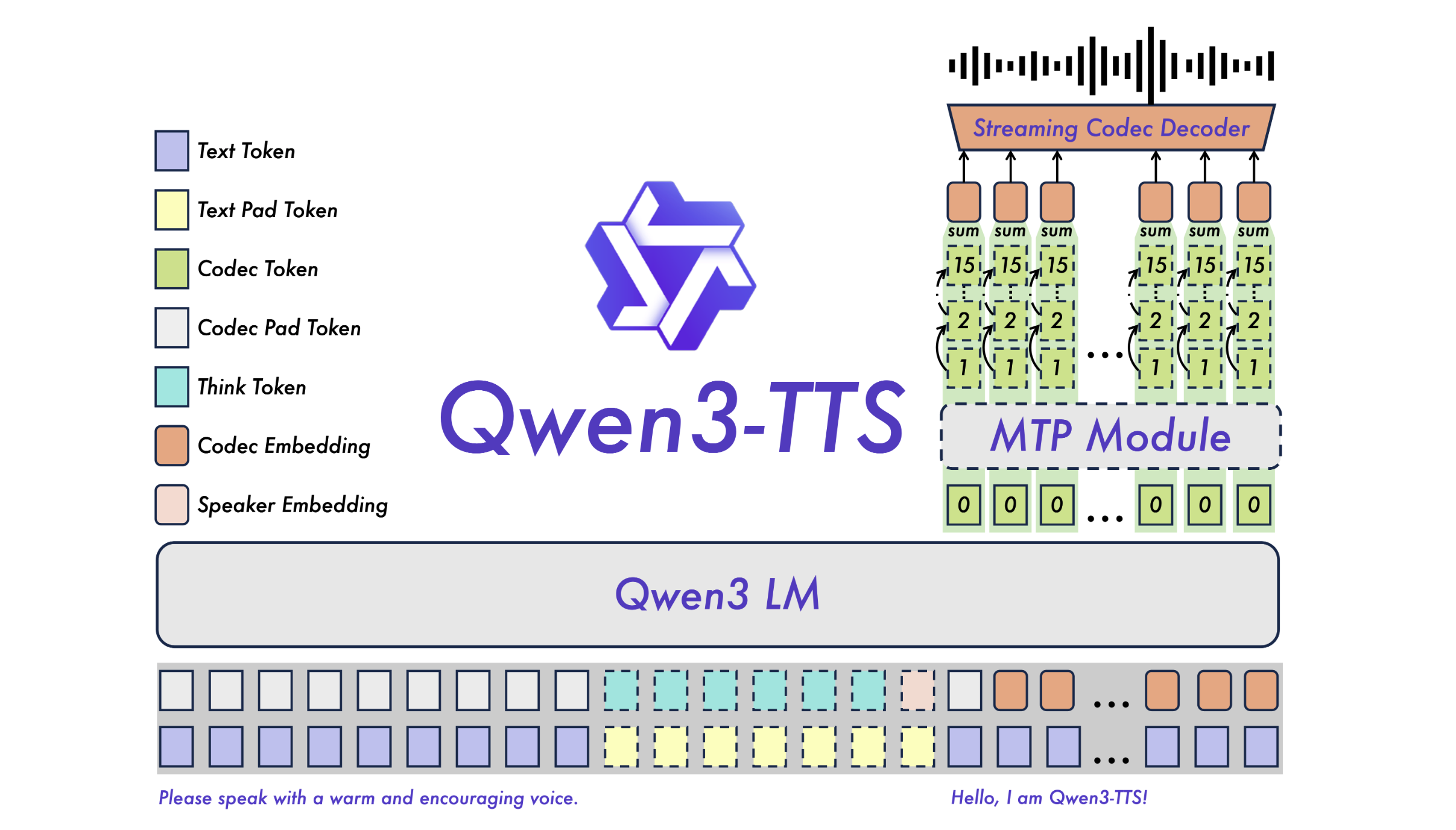
Qwen3-TTS는 단순한 음성 합성 모델이 아닌, 대규모 언어 모델(LLM)의 추론 능력을 음성 생성에 접목시킨 시스템입니다. 이 모델은 Qwen3-LM 제품군을 백본(Backbone)으로 사용하여 높은 동시성 처리 능력과 낮은 추론 지연 시간을 확보했습니다.
앞서 살펴본 토크나이저(Tokenizer, Qwen-TTS-Tokenizer)가 소리를 토큰으로 만드는 역할(Audio to Token)을 한다면, Qwen3-TTS 모델은 텍스트를 입력받아 적절한 음성 토큰(Audio Token)을 예측하는 두뇌 역할을 합니다.
이 아키텍처의 가장 큰 특징은 텍스트와 음성 정보를 처리하는 방식과 모델의 버전에 따른 차별화된 예측 메커니즘에 있습니다.
Qwen3 LM 기반의 백본(Backbone)
Qwen3-TTS는 강력한 텍스트 이해 능력을 가진 Qwen3-LM 을 백본으로 사용합니다. 입력되는 텍스트는 표준 Qwen 토크나이저로 처리되고, 음성은 앞서 설명한 Qwen-TTS-Tokenizer로 인코딩됩니다. 또한, 특정 화자의 목소리를 정확하게 제어하기 위해 학습 가능한 **화자 인코더(Speaker Encoder)**를 백본 모델과 함께 공동 학습(Joint Training)시키는 방식을 채택했습니다. 모든 입력 데이터는 ChatML 형식으로 표준화되어 있어, 사용자의 지시사항(Instruction)을 따르는 대화형 생성에 최적화되어 있습니다.
이중 트랙 표현 (Dual-Track Representation) 및 입력 처리
Qwen3-TTS는 실시간 합성을 구현하기 위해 이중 트랙 표현(Dual-track Representation) 이라는 독창적인 방식을 채택했습니다. 이는 텍스트 토큰과 음성(Acoustic) 토큰을 시퀀스 길이(Sequence Length)가 아닌 채널 축(Channel axis)을 따라 연결(Concatenate)하여 모델에 입력하는 방식입니다.
이를 통해 모델이 텍스트 토큰을 입력받는 즉시, 그에 대응하는 음성 토큰을 지체 없이 예측할 수 있도록 설계되어 동시성 처리가 가능해졌습니다. 또한, 특정 화자의 아이덴티티를 정교하게 제어하기 위해, 학습 가능한 화자 인코더(Speaker Encoder) 를 백본 모델과 함께 공동 학습(Joint Training)시켜, 화자 제어(Speaker Control)가 가능합니다.
모든 입력 데이터는 ChatML 포맷으로 표준화되어 있어, 단순 발화뿐만 아니라 사용자의 복잡한 제어 명령(Instruction)을 따르는 데 최적화되어 있습니다.
버전별 예측 메커니즘의 차이 (25Hz vs 12Hz)
모델은 텍스트 토큰을 받으면 즉시 그에 해당하는 음성 토큰을 예측하기 시작하며, 이 토큰들은 Code2Wav 모듈을 통해 즉각적으로 파형으로 변환됩니다. 이 과정은 Qwen3-TTS가 사용하는 토크나이저의 특성(단일 코드북 vs 다중 코드북)에 따라 서로 다른 예측 아키텍처를 가집니다:
계층적 예측 및 MTP 모듈을 적용한 Qwen3-TTS-12Hz: 12Hz 모델은 RVQ(Residual Vector Quantization) 기반의 다중 코드북 토큰을 처리해야 하므로, 계층적 예측(Hierarchical Prediction) 전략을 사용합니다.
-
0번째 코드북 예측: 백본 모델은 먼저 압축된 코드북 특징들을 입력받아, 가장 기초적인 정보가 담긴 **0번째 코드북(Zeroth Codebook)**을 예측합니다.
-
다중 토큰 예측(MTP, Multi-Token Prediction): 이후 한 번에 여러 토큰을 예측하는 MTP 모듈 이 활성화되어 나머지 잔여 코드북(Residual Codebooks, 1~15번 레이어) 전체를 예측합니다.
-
단일 프레임 즉시 생성: 이러한 다중 토큰 예측 전략 덕분에 모델은 복잡한 음향 디테일과 운율 정보를 놓치지 않으면서도, 단일 프레임 내에서 모든 계층의 토큰을 즉시 생성(Single-frame instant generation)할 수 있습니다. 이는 12Hz 모델이 초저지연 스트리밍을 구현할 수 있는 핵심적인 기술적 근거가 됩니다.
단일 레벨 예측 및 DiT 디코딩을 수행하는 Qwen3-TTS-25Hz: 앞서 살펴본 12Hz 모델에 비해, 25Hz 모델은 단일 레이어의 음성 토큰을 다루므로 구조가 상대적으로 직관적입니다. 백본 모델은 텍스트 특징과 이전에 생성된 음성 토큰 정보를 통합한 뒤, 선형 헤드(Linear Head) 를 통해 현재 시점의 음성 토큰을 예측합니다.
- 파형 재구성: 이렇게 생성된 토큰 시퀀스는 청크 단위(Chunk-wise)의 DiT(Diffusion Transformer) 모듈로 전달되어 고품질의 파형으로 변환됩니다. 이 과정은 높은 음질을 보장하지만, DiT의 특성상 일정 수준의 청크 처리가 필요합니다.
![]()
![]() 12Hz 모델이 사용하는 RVQ(Residual Vector Quantization)에 대해서는 관련 논문(SoundStream: An End-to-End Neural Audio Codec)을 참고해주세요:
12Hz 모델이 사용하는 RVQ(Residual Vector Quantization)에 대해서는 관련 논문(SoundStream: An End-to-End Neural Audio Codec)을 참고해주세요:
Qwen3-TTS 모델 학습
Qwen3-TTS의 뛰어난 성능은 체계적인 3단계 사전 학습(Pre-training)과 사후 학습(Post-training) 과정에서 비롯되었습니다:
먼저 사전 학습의 첫 번째 단계인 일반 단계(General Stage) 에서는 500만 시간 이상의 다국어 음성 데이터를 사용하여 텍스트와 음성 간의 기본적인 매핑 능력을 학습시켰습니다. 이어지는 고품질 단계(High-Quality Stage) 에서는 데이터의 품질을 엄격하게 선별하여 지속적인 사전 학습(CPT)을 수행함으로써, 초기 단계의 노이즈 데이터로 인해 발생할 수 있는 환각(Hallucination) 현상을 억제하고 음성 품질을 대폭 향상시켰습니다. 마지막 장문 맥락 단계(Long-Context Stage) 에서는 최대 토큰 길이를 32,768개까지 늘리고 긴 음성 데이터를 집중적으로 학습시켜, 긴 문장을 말할 때도 문맥을 잃지 않는 능력을 배양했습니다.
사후 학습 단계에서는 모델을 인간의 선호도에 맞추기 위해 DPO(Direct Preference Optimization) 기법을 도입했습니다. 인간 피드백을 바탕으로 다국어 음성 샘플의 선호도 쌍을 구성하여 모델을 튜닝함으로써, 기계적인 느낌을 줄이고 더욱 사람 같은 자연스러운 음성을 생성하도록 했습니다. 또한, 특정 화자의 목소리를 완벽하게 모사하고 제어하기 위해 경량화된 화자 파인튜닝(Speaker Fine-tuning)을 수행하여 표현력과 제어 가능성을 완성했습니다.
Qwen-TTS의 주요 기능 및 성능
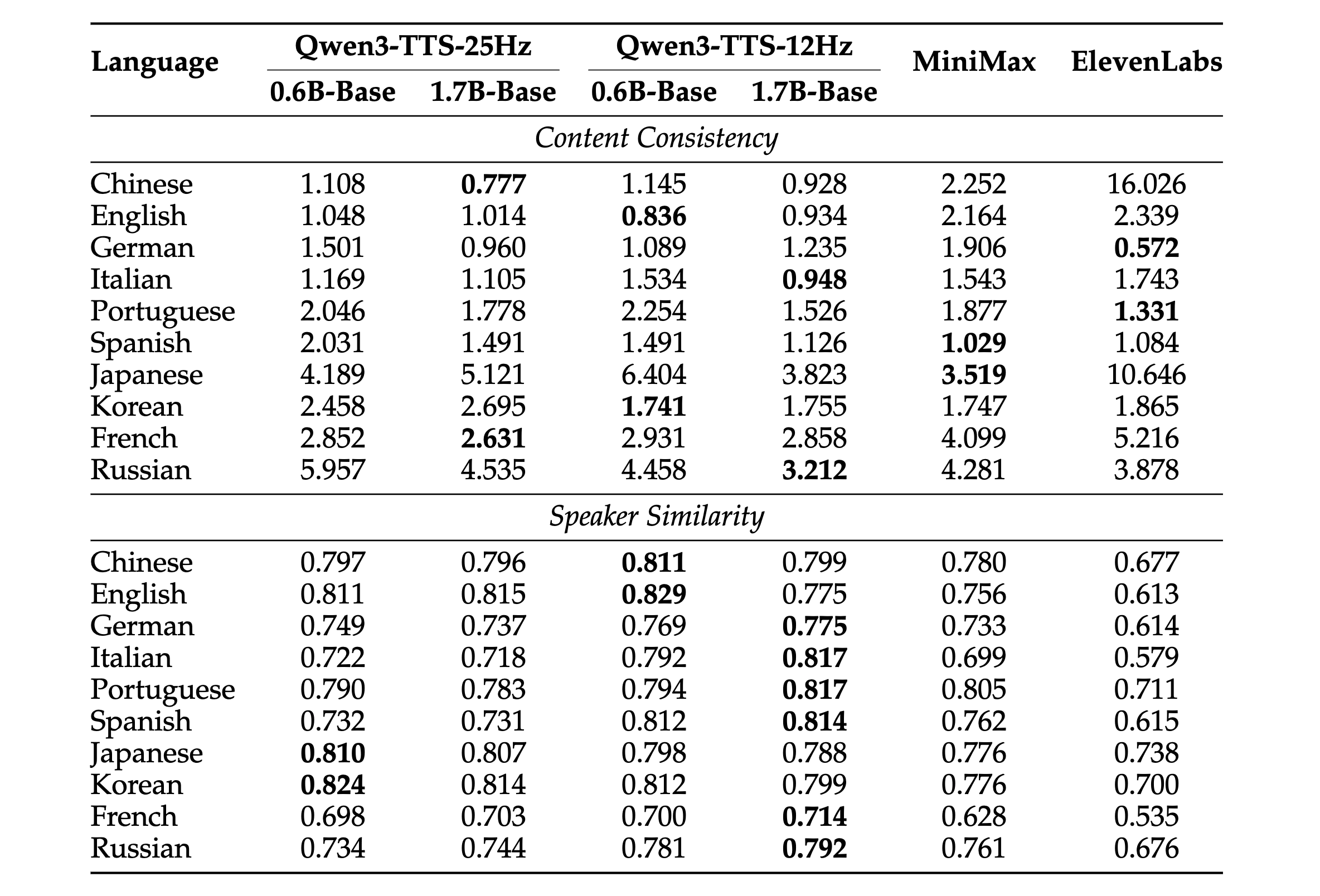
Qwen3-TTS는 단순한 낭독을 넘어선 다양한 고급 기능을 하나의 모델 안에서 통합적으로 제공합니다.
제로샷 음성 복제 (Zero-Shot Voice Cloning) 및 디자인
사용자는 단 3초 분량의 참조 오디오만 있으면 훈련에 없던 목소리라도 즉시 복제할 수 있습니다. Qwen3-TTS는 단순히 목소리의 톤(Timbre)만 흉내 내는 것이 아니라, 참조 오디오에 담긴 운율과 감정선까지 파악하여 반영합니다.
또한, 음성 디자인(Voice Design) 기능을 통해 텍스트 프롬프트만으로 세상에 없는 목소리를 창조할 수 있습니다. 예를 들어 "중저음의 신뢰감 있는 뉴스 앵커 톤으로"라거나 "약간 술에 취한 듯한 쉰 목소리로"와 같은 구체적인 지시를 내리면, 모델은 내부적으로 생각하는 토큰(Thinking Token) 메커니즘을 활성화하여 발화 스타일을 계획하고 음성을 생성합니다.
압도적인 다국어 및 교차 언어(Cross-Lingual) 성능
Qwen3-TTS는 한국어를 비롯하여 영어, 중국어, 일본어, 독일어, 프랑스어, 이탈리아어, 스페인어, 포르투갈어, 러시아어 등 10개 이상의 언어를 기본적으로 지원합니다. 특히 기술 보고서에서 강조하는 부분은 교차 언어 성능입니다. 일반적으로 중국어 화자의 목소리로 한국어를 말하게 시키면 억양이 어색해지는 문제가 발생하기 쉽습니다.
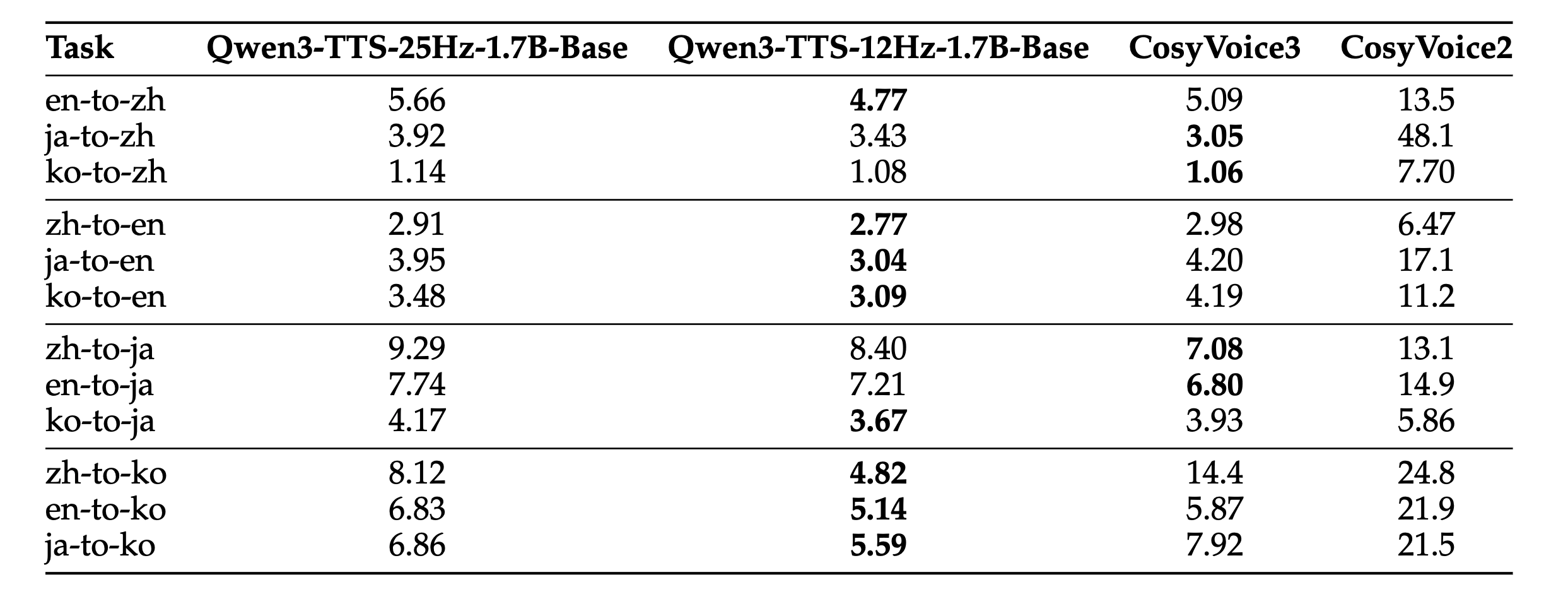
그러나 Qwen3-TTS는 중국어-한국어(Zh-to-Ko) 변환 테스트에서 기존 SOTA 모델인 CosyVoice3 대비 오류율(WER)을 약 66%나 감소시키며(WER 4.82), 언어 장벽을 넘어서도 화자의 고유한 목소리 특징을 유지하는 능력을 입증했습니다.
롱폼(Long-form) 생성의 안정성 확보
긴 문장을 읽을 때 중간에 발음이 뭉개지거나, 같은 단어를 반복하거나, 혹은 문장을 건너뛰는 현상은 AR(Autoregressive) 기반 TTS 모델들의 고질적인 문제였습니다.

Qwen 팀은 이를 해결하기 위해 전체 텍스트를 청크(Chunk) 단위로 쪼개서 처리하되, 청크 간의 경계를 매끄럽게 연결하는 특수 훈련을 진행했습니다. 그 결과 10분이 넘는 긴 텍스트를 생성할 때도 처음부터 끝까지 일정한 호흡과 톤을 유지하며, 뚝뚝 끊기는 느낌(Artifacts) 없이 자연스러운 낭독이 가능합니다.
성능 평가 및 벤치마크 결과
객관적인 성능 지표에서도 Qwen3-TTS는 괄목할 만한 성과를 보였습니다.

음질 복원력 측면에서는 12Hz 토크나이저(Qwen-TTS-Tokenizer-12Hz)는 극도로 낮은 비트레이트에도 불구하고 PESQ 3.21, UTMOS 4.16이라는 높은 점수를 기록했습니다. 이는 기존의 SpeechTokenizer나 Mimi와 같은 SOTA 코덱들을 모든 주요 지표에서 능가하는 수치입니다.
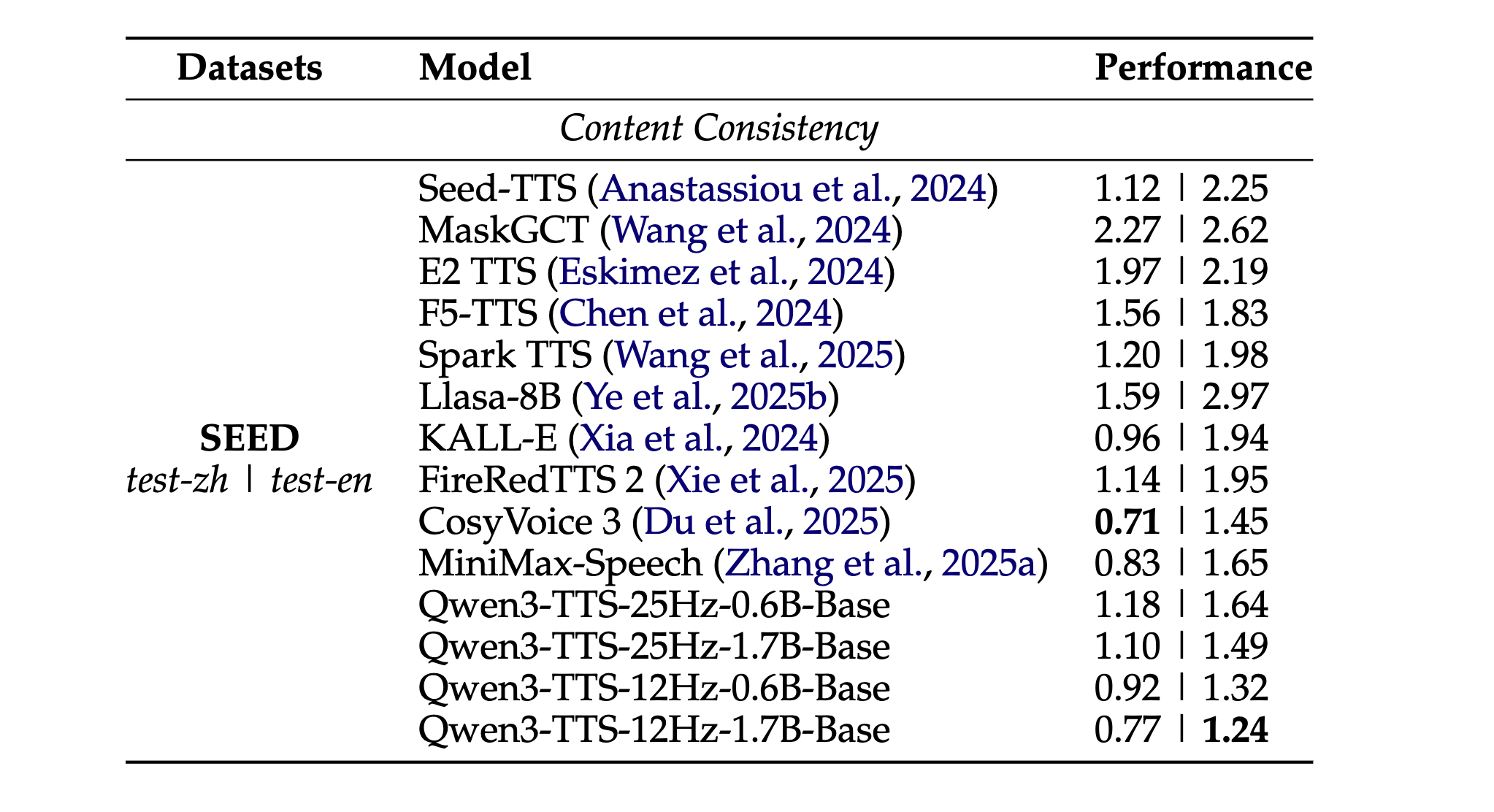
음성 인식 정확도 측면에서는 생성된 음성이 얼마나 명확한지를 측정하는 Seed-TTS 벤치마크에서, Qwen3-TTS-12Hz-1.7B 모델은 영어 테스트 셋 기준 WER 1.24를 기록하며 현재 시장을 선도하는 모델들을 제치고 1위를 차지했습니다.
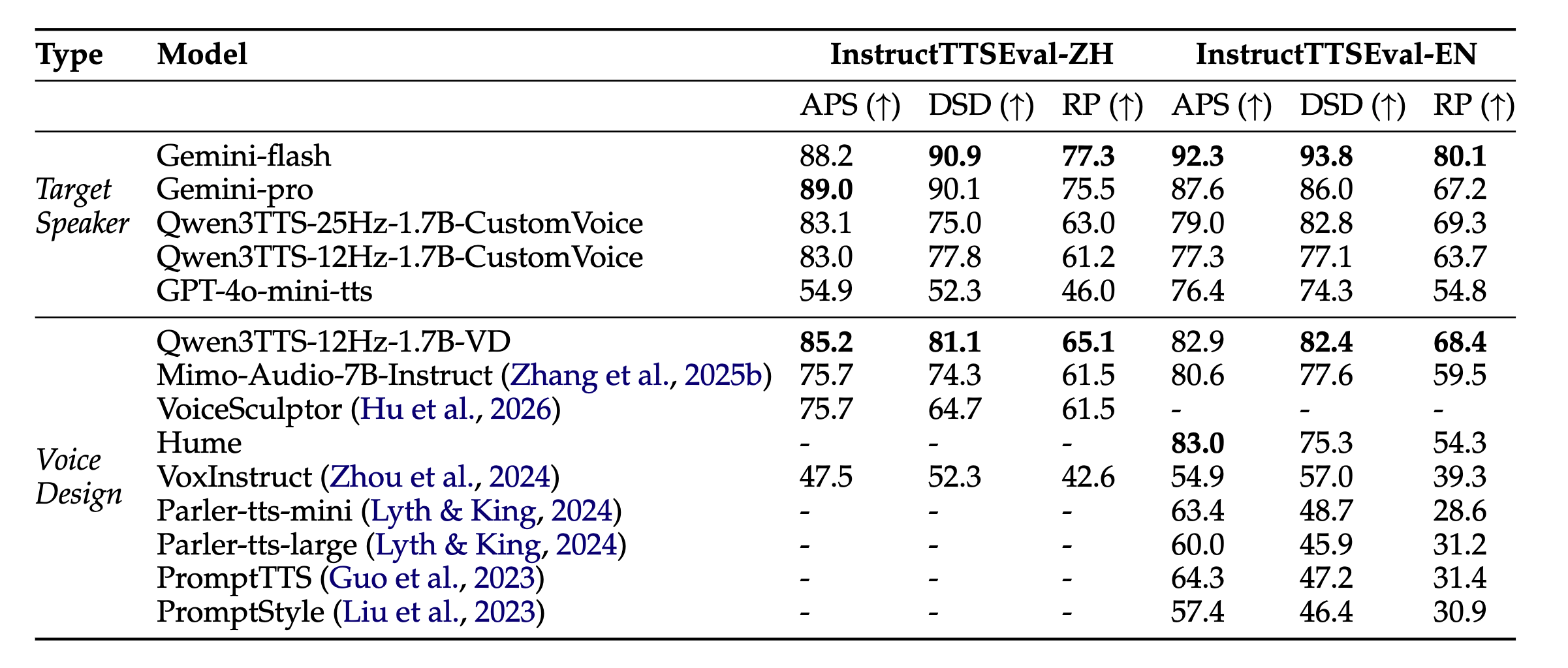
마지막으로 지시 이행 능력은 사용자의 스타일 제어 명령을 얼마나 잘 따르는지를 평가하는 InstructTTSEval 벤치마크에서도 GPT-4o-mini-tts보다 높은 점수를 획득하며, 텍스트 이해 능력과 음성 생성 능력의 결합이 성공적임을 증명했습니다.
Qwen3-TTS 모델 설치 및 사용 예시: Qwen3-TTS-12Hz-1.7B-VoiceDesign
환경 설정 및 설치
가장 쉬운 사용 방법은 PyPI를 통해 공식 qwen-tts 패키지를 설치하는 것입니다. 충돌 방지를 위해 Python 3.12 버전의 새로운 가상환경을 사용하는 것을 권장합니다:
Conda를 사용하는 경우, 다음과 같이 Python 3.12 기반 가상환경 생성 및 활성화를 진행합니다:
conda create -n qwen3-tts python=3.12 -y
conda activate qwen3-tts
이후, qwen-tts 패키지를 설치합니다:
pip install -U qwen-tts
선택적으로, GPU 메모리 사용량을 줄이기 위해 FlashAttention 관련 패키지를 함께 설치하는 것을 권장합니다:
pip install -U flash-attn --no-build-isolation
Python 사용 예시 코드
다음은 Qwen3-TTS-12Hz-1.7B-VoiceDesign 모델을 사용하여 텍스트 설명으로 목소리를 생성하는 예시 코드입니다:
import torch
import soundfile as sf
from qwen_tts import Qwen3TTSModel
# 1. 모델 로드
# Hugging Face 모델 ID를 통해 자동으로 가중치를 다운로드하고 로드합니다.
model = Qwen3TTSModel.from_pretrained(
"Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign",
device_map="cuda:0", # GPU 사용 설정
dtype=torch.bfloat16, # 데이터 타입 설정
attn_implementation="flash_attention_2", # FlashAttention 2 사용 (설치된 경우)
)
# 2. 음성 생성 (Voice Design)
# instruct 파라미터에 원하는 목소리의 특징을 자연어로 묘사합니다.
text = "안녕하세요? 저는 텍스트 설명만으로 만들어진 새로운 목소리입니다."
instruct = "차분하고 신뢰감 있는 중저음의 남성 뉴스 앵커 목소리, 전문적인 톤."
wavs, sr = model.generate_voice_design(
text=text, # 음성으로 변환할 입력 텍스트입니다.
language="Korean", # 언어 설정 (Auto로 설정 가능하나 명시 권장, 예: "Korean", "English", "Chinese" 등)
instruct=instruct # 목소리 묘사 프롬프트 (생성할 목소리의 성별, 연령, 톤, 스타일 등을 설명)
)
# 3. 결과 저장
sf.write("output_voice_design.wav", wavs[0], sr)
print("생성 완료: output_voice_design.wav")
 Qwen3-TTS 모델 사용 데모
Qwen3-TTS 모델 사용 데모
 Qwen3-TTS 모델 소개 블로그
Qwen3-TTS 모델 소개 블로그
Qwen3-TTS 모델 기술 문서(Technical Report)
 Qwen3-TTS 모델 다운로드
Qwen3-TTS 모델 다운로드
현재 Qwen3-TTS 모델은 12Hz 모델군이 공개되었으며, 25Hz 모델군은 공개 에정입니다.
| 모델명 (Model Name) | 모델 크기 | 토크나이저 | 유형 (Type) | 다운로드 링크 |
|---|---|---|---|---|
| Qwen3-TTS-12Hz-1.7B-VoiceDesign | 1.7B | 12Hz | VoiceDesign | 다운로드 |
| Qwen3-TTS-12Hz-1.7B-CustomVoice | 1.7B | 12Hz | CustomVoice | 다운로드 |
| Qwen3-TTS-12Hz-1.7B-Base | 1.7B | 12Hz | Base | 다운로드 |
| Qwen3-TTS-12Hz-0.6B-CustomVoice | 0.6B | 12Hz | CustomVoice | 다운로드 |
| Qwen3-TTS-12Hz-0.6B-Base | 0.6B | 12Hz | Base | 다운로드 |
| Qwen3-TTS-Tokenizer-12Hz | - | 12Hz | Tokenizer | 다운로드 |
| Qwen3-TTS-25Hz-1.7B-VoiceEditing | 1.7B | 25Hz | VoiceEditing | (TBD) |
| Qwen3-TTS-25Hz-1.7B-CustomVoice | 1.7B | 25Hz | CustomVoice | (TBD) |
| Qwen3-TTS-25Hz-1.7B-Base | 1.7B | 25Hz | Base | (TBD) |
| Qwen3-TTS-25Hz-0.6B-CustomVoice | 0.6B | 25Hz | CustomVoice | (TBD) |
| Qwen3-TTS-25Hz-0.6B-Base | 0.6B | 25Hz | Base | (TBD) |
| Qwen3-TTS-Tokenizer-25Hz | - | 25Hz | Tokenizer | (TBD) |
Qwen3-TTS-1.7B 모델은 정교한 음성 품질과 지시 이행 능력을 제공하며, Qwen3-TTS-0.6B 모델은 모바일이나 엣지 환경에서 더욱 낮은 지연 시간(약 97ms)으로 작동하도록 최적화되었습니다.
 Qwen3-TTS 프로젝트 GitHub 저장소
Qwen3-TTS 프로젝트 GitHub 저장소
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()