
Qwen3-VL 소개
Qwen3-VL은 알리바바 클라우드 산하 Qwen 팀이 새롭게 공개한 멀티모달 대규모 언어 모델 시리즈로, 현재까지 발표된 Qwen 계열 모델 중 가장 포괄적이고 정교한 성능을 제공하는 모델입니다. 이 모델은 단순히 시각 데이터를 인식하거나 텍스트를 생성하는 수준을 넘어, 언어와 비전 정보를 유기적으로 융합하여 세계를 이해하고 추론하며, 나아가 실제 작업을 수행할 수 있는 단계로 진화하였습니다.

기존의 Qwen2-VL 및 Qwen2.5-VL이 주로 시각 인식과 문서 이해에 초점을 두었다면, Qwen3-VL은 인지(cognition), 추론(reasoning), 실행(execution)의 전 과정에 걸쳐 능력을 확장하였습니다. 특히 텍스트 처리 성능이 Qwen3-235B-A22B와 같은 전용 언어 모델과 동등한 수준에 이르렀으며, 시각 정보까지 무손실로 통합하여 처리할 수 있는 점에서 새로운 기준을 제시합니다.
Qwen3-VL은 Dense 아키텍처와 Mixture of Experts(MoE) 아키텍처로 제공되며, 엣지 장치에서 클라우드 환경까지 다양한 배포 시나리오를 지원합니다. 또한 사용 목적에 따라 지시 수행(Instruct) 버전과 고난도의 수학·과학적 추론에 특화된 Thinking 버전으로 구분되어 제공됩니다.
주요 기술적 개선 사항

Qwen3-VL은 단순한 성능 향상을 넘어, 멀티모달 인공지능 모델이 도달할 수 있는 새로운 가능성을 보여주는 대표적인 사례라 할 수 있습니다. Qwen3-VL 모델이 가진 핵심적인 혁신을 다음과 같이 정리할 수 있습니다:
-
시각적 에이전트(Visual Agent) 기능: Qwen3-VL은 전통적인 인식 모델과 달리 실제 컴퓨터와 모바일 인터페이스를 직접 조작할 수 있는 능력을 갖추고 있습니다. 버튼이나 입력 창과 같은 GUI 요소를 정확히 식별하고, 이들의 기능을 이해한 뒤 적절한 도구를 호출하거나 작업을 완료할 수 있습니다. 특히 OS World 벤치마크에서 세계 최고 수준의 성능을 기록하였으며, 외부 도구와 연동할 경우 세밀한 인식 과제에서 성능이 더욱 향상되는 것이 확인되었습니다. 이는 단순 분석을 넘어 실제 디지털 작업을 수행할 수 있는 자율 에이전트로의 진화를 의미합니다.
-
텍스트 중심 성능 강화: Qwen3-VL은 학습 초기 단계에서부터 텍스트와 비전 정보를 공동 학습하는 전략을 채택하여, 언어 능력을 지속적으로 강화하였습니다. 그 결과, 순수 텍스트 기반 과제에서도 Qwen3-235B-A22B-2507과 동등한 수준의 성능을 발휘하게 되었습니다. 이는 Qwen3-VL이 단순한 비전-언어 모델을 넘어, 텍스트에 기반한 멀티모달 추론의 차세대 중심축으로 자리매김했음을 보여줍니다.
-
비주얼 코딩(Visual Coding)의 도약: Qwen3-VL은 시각 정보를 활용하여 실제 코드로 변환할 수 있는 능력을 대폭 강화하였습니다. 예를 들어, UI 설계 초안을 입력하면 자동으로 Draw.io 다이어그램, HTML, CSS, JavaScript 코드를 생성할 수 있습니다. 이는 “보고-만드는(What You See Is What You Get)” 시각 프로그래밍의 가능성을 열어주며, 프로토타이핑 및 신속한 개발 환경에서 개발자의 생산성을 획기적으로 향상시킬 수 있습니다.
-
향상된 공간 이해 능력: 본 모델은 절대 좌표에서 상대 좌표로 확장된 2D grounding을 지원할 뿐 아니라, 시점 변화, 물체 간의 가림 관계까지 정밀하게 판별할 수 있습니다. 더 나아가 3D grounding을 지원함으로써 복잡한 공간 추론과 Embodied AI 응용을 위한 토대를 마련하였습니다. 이는 로보틱스, 자율주행, 증강현실(AR)과 같은 실제 환경 기반 응용 분야에서 큰 잠재력을 갖습니다.
-
더 긴 문맥(Long Context) 및 장시간 비디오 이해: Qwen3-VL은 모든 모델이 기본적으로 256K 토큰 길이의 문맥을 지원하며, 필요할 경우 최대 100만 토큰까지 확장 가능합니다. 이로써 수백 페이지에 달하는 기술 문서, 전체 교과서, 혹은 2시간 이상의 영상까지도 무손실로 기억하고, 특정 장면이나 구절을 초 단위로 정확히 재현할 수 있습니다. 이는 연구 논문 분석, 법률 문서 처리, 장시간 동영상 요약 등에서 실질적인 활용 가능성을 열어줍니다.
-
강화된 멀티모달 추론(Thinking 버전): Qwen3-VL의 Thinking 모델은 특히 STEM 및 수학적 추론에 최적화되어 있습니다. 세부적인 요소를 관찰하고 문제를 단계적으로 분해하며, 인과 관계를 논리적으로 분석한 뒤 근거에 기반한 해답을 제시할 수 있습니다. 실제로 MathVision, MMMU, MathVista 등 주요 벤치마크에서 뛰어난 성과를 보이며, 복잡한 학문적 문제 해결에서 탁월한 성능을 입증하였습니다.
-
시각 인식 및 객체 판별 성능 강화: 학습 데이터의 질과 다양성을 개선함으로써, Qwen3-VL은 이제 유명 인물, 애니메이션 캐릭터, 상품, 랜드마크, 동식물 등 일상과 전문 영역을 아우르는 폭넓은 인식 능력을 확보하였습니다. 이는 단순히 물체를 구별하는 수준을 넘어, 실제 응용 환경에서 필요한 **범용적인 ‘무엇이든 인식할 수 있는 모델’**로 확장된 것입니다.
-
다국어 OCR과 복잡한 장면 이해: OCR 성능은 기존 10개 언어에서 32개 언어로 확대되었으며, 조명 부족, 흐림, 기울어진 텍스트와 같은 까다로운 조건에서도 안정적인 결과를 제공합니다. 또한 희귀 문자, 고대 문자, 전문 용어의 인식률이 크게 개선되었고, 긴 문서를 분석할 때도 레이아웃과 구조를 보존하여 더욱 정밀한 결과를 산출할 수 있습니다. 이는 국제적 환경과 전문 문헌 처리에서 특히 유용합니다.
Qwen3-VL 모델 구조
Qwen3-VL은 전 세대에서 도입된 동적 해상도(dynamic resolution) 설계를 그대로 유지하면서도, 구조적 설계 측면에서 세 가지 중대한 개선을 이루었습니다. 이러한 변화는 단순한 미세 조정 수준을 넘어, 모델이 긴 맥락 이해, 세밀한 시각 인식, 정밀한 시간적 추론을 가능하게 하는 토대를 마련하였습니다. 이번 Qwen3-VL 모델에 도입된 3가지 주요 개선점들은 다음과 같습니다:
Interleaved-MRoPE: 보다 균형 잡힌 위치 임베딩
기존의 **MRoPE(Multi-dimensional Rotary Position Embedding)**는 시간(t), 높이(h), 너비(w)의 축을 블록 단위로 나누어 차원에 할당하였습니다. 이 방식은 모든 시간 정보가 고주파 차원(high-frequency dimensions)에 집중되는 한계를 가지고 있었으며, 특히 긴 비디오 데이터의 시간적 맥락 이해에서 성능 저하가 발생하곤 했습니다.
이에 Qwen3-VL은 Interleaved-MRoPE를 도입하였습니다. 이 기법은 t, h, w를 교차적으로 배치하여 주파수 대역 전반에 고르게 분산시킴으로써, 시간·공간 축 전체에서 균형 잡힌 위치 인코딩을 제공합니다. 그 결과 이미지 인식 능력을 유지하면서도, 장시간 비디오 분석과 같은 과제에서 현저히 강화된 성능을 발휘할 수 있게 되었습니다.
DeepStack: 다층적 시각 특징의 통합
두 번째 혁신은 DeepStack 구조입니다. 전통적인 멀티모달 대규모 모델(LMM)들은 대체로 시각적 토큰을 언어 모델의 단일 계층에 삽입하는 방식을 채택해 왔습니다. 그러나 이러한 접근은 세밀한 시각 정보가 고차원 언어 표현으로 충분히 전달되지 못하는 한계를 지녔습니다.
Qwen3-VL은 이러한 문제를 해결하기 위해, **ViT(Vision Transformer)**에서 추출한 다층적 시각 특징을 토큰화한 뒤 이를 LLM의 여러 계층에 걸쳐 주입하는 방식을 도입하였습니다. 이 다층 주입(multi-layer injection) 구조를 통해 저수준의 디테일(예: 질감, 색상)부터 고수준의 의미적 개념(예: 객체 종류, 맥락)까지 폭넓은 시각 정보를 보존하고 활용할 수 있습니다.
실험 결과, DeepStack 구조는 이미지-텍스트 정렬 정확도를 크게 향상시켰으며, 다양한 시각 이해 과제에서 일관된 성능 개선을 보여주었습니다. 즉, Qwen3-VL은 세밀한 시각적 특징과 고차원 언어 표현을 정교하게 결합할 수 있는 구조적 진화를 달성한 것입니다.
Text-Timestamp Alignment: 정밀한 시간적 추론
세 번째 개선은 비디오의 시간적 모델링 방식에서 이루어졌습니다. 기존의 **T-RoPE(Time-aware RoPE)**는 프레임 수준의 시간 정보를 표현하는 데 한계가 있었으며, 사건의 시작·종료 시점을 정밀하게 포착하기에는 부족했습니다.
이를 보완하기 위해 Qwen3-VL은 텍스트-타임스탬프 정렬(text-timestamp alignment) 메커니즘을 도입하였습니다. 입력 데이터를 “타임스탬프-비디오 프레임”의 교차 형식으로 재구성함으로써, 프레임별 시각 정보와 시간적 맥락 간의 정밀한 정렬이 가능해졌습니다.
또한 Qwen3-VL은 초 단위(seconds)뿐 아니라 시:분:초(HMS) 형식의 시간 출력을 기본적으로 지원합니다. 이를 통해 이벤트 위치 지정(event localization), 행동 경계 탐지(action boundary detection), 그리고 시각-언어 결합형 시간 추론(cross-modal temporal QA) 과제에서 더욱 견고한 성능을 발휘할 수 있게 되었습니다. 실제 실험에서는 복잡한 비디오 내 사건들을 정확히 구분하고, 해당 시점까지 정밀하게 회상하는 능력이 크게 강화된 것으로 보고되었습니다.
Qwen3-VL의 활용 및 배포
Qwen3-VL은 Hugging Face Transformers와 ModelScope를 비롯한 주요 AI 생태계와 완전하게 호환되며, 연구자와 개발자가 다양한 시나리오에서 손쉽게 사용할 수 있도록 설계되었습니다. 단일 이미지 입력뿐 아니라 멀티 이미지 비교, 동영상 처리, 문서 이해 등 복합적인 멀티모달 입력을 지원하여 실제 연구 및 산업 응용에서 활용 범위를 넓히고 있습니다.
특히 qwen-vl-utils 라이브러리를 통해 사용자는 시각 입력의 픽셀 제약, 프레임 샘플링, GPU 메모리에 따른 토큰 예산 제어를 유연하게 조정할 수 있으며, 초장문맥 입력을 위해 YaRN 기반 rope scaling 기법을 적용하여 최대 100만 토큰까지 확장할 수 있습니다.
배포 측면에서도 Qwen3-VL은 vLLM 및 SGLang 기반 고속 추론 서버를 제공하며, OpenAI 호환 API 인터페이스를 지원하기 때문에 기존 워크플로우에 손쉽게 통합할 수 있습니다. 또한 공식 Docker 이미지 역시 제공되어, 복잡한 환경 설정 과정을 최소화하고 빠른 실험 및 배포를 가능하게 합니다.
Hugging Face Transformers를 활용한 간단한 예제
아래는 Hugging Face Transformers 라이브러리를 사용하여 Qwen3-VL 모델에 단일 이미지와 텍스트를 함께 제공하고 모델의 출력을 확인하는 예시 코드입니다:
from transformers import AutoModelForImageTextToText, AutoProcessor
# 모델 로드
model = AutoModelForImageTextToText.from_pretrained(
"Qwen/Qwen3-VL-235B-A22B-Instruct",
device_map="auto",
dtype="auto"
)
processor = AutoProcessor.from_pretrained("Qwen/Qwen3-VL-235B-A22B-Instruct")
# 입력 준비
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg"},
{"type": "text", "text": "이 이미지를 설명해 주세요."},
],
}
]
inputs = processor.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt").to(model.device)
# 추론
generated_ids = model.generate(**inputs, max_new_tokens=128)
output_text = processor.batch_decode(generated_ids[:, inputs.input_ids.shape[1]:], skip_special_tokens=True)
print(output_text)
멀티 이미지 입력 예시
또한, Qwen3-VL 모델을 제공하는 API Server에 다음과 같이 여러 장의 이미지를 동시에 입력하여 비교 분석을 수행할 수 있습니다:
# ...(생략)...
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "file:///path/to/image1.jpg"},
{"type": "image", "image": "file:///path/to/image2.jpg"},
{"type": "text", "text": "이 두 이미지의 공통점을 설명해 주세요."},
],
}
]
inputs = processor.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt").to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=128)
output_text = processor.batch_decode(generated_ids[:, inputs.input_ids.shape[1]:], skip_special_tokens=True)
print(output_text)
Qwen3-VL 모델의 API Server 실행은 아래쪽의 vLLM을 활용하는 섹션을 참고해주세요
동영상 입력 예시
API Server에 동영상을 입력으로 제공할 수 있으며, 장시간의 비디오에 대해서도 안정적인 추론이 가능합니다:
messages = [
{
"role": "user",
"content": [
{"type": "video", "video": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-VL/space_woaudio.mp4"},
{"type": "text", "text": "이 동영상의 내용을 설명해 주세요."},
],
}
]
inputs = processor.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt").to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=128)
output_text = processor.batch_decode(generated_ids[:, inputs.input_ids.shape[1]:], skip_special_tokens=True)
print(output_text)
Qwen3-VL 모델의 API Server 실행은 아래쪽의 vLLM을 활용하는 섹션을 참고해주세요
qwen-vl-utils를 통한 세밀한 제어
qwen-vl-utils 라이브러리를 활용하면 이미지와 비디오 입력에 대해 픽셀 크기와 프레임 수를 제어할 수 있습니다:
from qwen_vl_utils import process_vision_info
processor = AutoProcessor.from_pretrained("Qwen/Qwen3-VL-235B-A22B-Instruct")
# 픽셀 예산 설정
processor.image_processor.size = {"longest_edge": 1280*32*32, "shortest_edge": 256*32*32}
processor.video_processor.size = {"longest_edge": 16384*32*32, "shortest_edge": 256*32*32}
# 비디오 입력 처리
messages = [
{
"role": "user",
"content": [
{"type": "video", "video": "file:///path/to/video.mp4"},
{"type": "text", "text": "이 비디오의 주요 장면을 요약해 주세요."},
],
}
]
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
images, videos, video_kwargs = process_vision_info(messages, image_patch_size=16, return_video_kwargs=True)
vLLM을 이용한 배포 예시
Qwen3-VL 모델의 빠른 추론을 지원하는 vLLM을 사용하여 모델 서빙도 가능합니다. 다음은 8장의 GPU에 22002번 포트를 사용하는 추론 서버(Inference Server)를 실행하는 예시 명령어입니다:
python -m vllm.entrypoints.openai.api_server \
--model Qwen/Qwen3-VL-235B-A22B-Instruct \
--served-model-name Qwen3-VL \
--tensor-parallel-size 8 \
--dtype bfloat16 \
--port 22002
추론 서버가 실행된 후에는 다음과 같은 OpenAI API와 같은 방식으로 API 호출을 할 수 있습니다:
from openai import OpenAI
client = OpenAI(api_key="EMPTY", base_url="http://127.0.0.1:22002/v1")
messages = [
{"role": "user", "content": [
{"type": "image_url", "image_url": {"url": "https://path/to/image.jpg"}},
{"type": "text", "text": "이미지 속 내용을 설명해 주세요."},
]}
]
response = client.chat.completions.create(model="Qwen3-VL", messages=messages, max_tokens=512)
print(response.choices[0].message.content)
Docker 기반 실행
환경 설정을 최소화하고자 할 경우, 공식 Docker 이미지를 활용하여 바로 실행하는 것도 가능합니다:
docker run --gpus all --ipc=host --network=host --rm --name qwen3vl -it qwenllm/qwenvl:qwen3vl-cu128 bash
Qwen3-VL 모델의 성능 및 의의
Qwen3-VL은 단순히 특정 영역에서만 성능을 높이는 것이 아니라, 다양한 차원의 멀티모달 과제를 포괄적으로 평가하여 일관되게 우수한 결과를 보여주었습니다. 모델은 총 열 가지 평가 영역에서 검증을 거쳤으며, 이는 대학 수준의 종합 문제, 수학 및 과학적 추론, 논리 퍼즐, 범용 시각 질의응답, 주관적 경험과 지시 수행, 다국어 텍스트 인식과 차트/문서 파싱, 2D/3D 객체 grounding, 다중 이미지 이해, Embodied 및 공간 지각, 비디오 이해, 에이전트 작업 수행, 그리고 코드 생성까지 포함됩니다.
Qwen3-VL Instruct 모델의 성능

Qwen3-VL-235B-A22B-Instruct 모델은 추론 중심이 아닌 일반 멀티모달 과제에서 대부분의 지표에서 최고 성능을 기록하였습니다. 특히 Gemini 2.5 Pro와 GPT-5와 같은 폐쇄형 모델을 능가하는 성능을 보여주었으며, 공개된 오픈소스 멀티모달 모델 중에서는 새로운 SOTA(state-of-the-art) 결과를 달성하였습니다. 이는 Qwen3-VL이 단순히 특정 과제에 최적화된 모델이 아니라, 광범위한 시각적 과제 전반에서 뛰어난 일반화 능력을 발휘한다는 점을 의미합니다.

흥미로운 점은 Instruct 모델이 도구 사용을 통한 이미지 기반 추론을 지원한다는 사실입니다. 네 가지 정밀 인식 및 Embodied 상호작용 벤치마크에서 테스트한 결과, “이미지 분석 + 도구 호출”을 결합했을 때 성능이 일관되게 향상되는 것이 확인되었습니다. 이는 향후 에이전트형 시스템에서 Qwen3-VL을 실질적으로 활용할 수 있는 가능성을 보여줍니다.
Qwen3-VL Thinking 모델의 성능

Qwen3-VL-235B-A22B-Thinking 모델은 특히 STEM 및 수학적 추론에서 탁월한 성능을 보였습니다. MathVision, MMMU, MathVista와 같은 멀티모달 수학 문제 벤치마크에서 Gemini 2.5 Pro를 능가하는 성과를 기록하였으며, 복잡한 문제를 세부적으로 분해하고 논리적, 근거 기반 답변을 도출하는 능력을 입증하였습니다.
물론, 다학제 문제나 고난도의 시각 추론, 장시간 비디오 이해와 같은 특정 영역에서는 여전히 일부 폐쇄형 SOTA 모델에 미치지 못하는 면이 존재합니다. 그러나 에이전트 기능, 문서 이해, 2D/3D grounding 과제에서는 확실한 우위를 확보하였습니다. 이는 Qwen3-VL이 모든 영역에서 절대적 우위를 가지기보다는, 실제 활용성이 높은 영역에서 경쟁력을 확보하고 있음을 보여줍니다.
텍스트 중심 과제에서의 성능


Qwen3-VL Instruct와 Thinking 모델 모두 텍스트 기반 과제에서 Qwen3-235B-A22B-2507 언어 모델과 대등한 성능을 기록하였습니다. 이는 Qwen3-VL이 단순히 비전-언어 통합 모델에 머무르지 않고, 순수 언어 처리에서도 최상위권 성능을 유지함을 보여줍니다. 다시 말해, Qwen3-VL은 언어와 시각 양쪽을 모두 최상위 수준으로 이해하는 통합 모델이라 할 수 있습니다.
초장문맥(long-context) 성능 평가

초장문맥 처리 능력은 Qwen3-VL의 또 다른 두드러진 특징입니다. “needle-in-a-haystack” 실험을 통해 긴 동영상에서 특정 정보를 검색하는 테스트를 진행한 결과, 256K 문맥 길이에서는 100% 정확도를 기록하였습니다. 심지어 **100만 토큰(약 2시간 분량의 연속 비디오)**까지 확장된 상황에서도 99.5%라는 매우 높은 정확도를 유지했습니다. 이는 Qwen3-VL이 긴 시퀀스 데이터를 처리할 때도 기억과 검색 능력이 극히 안정적임을 의미합니다.
다국어 성능 평가
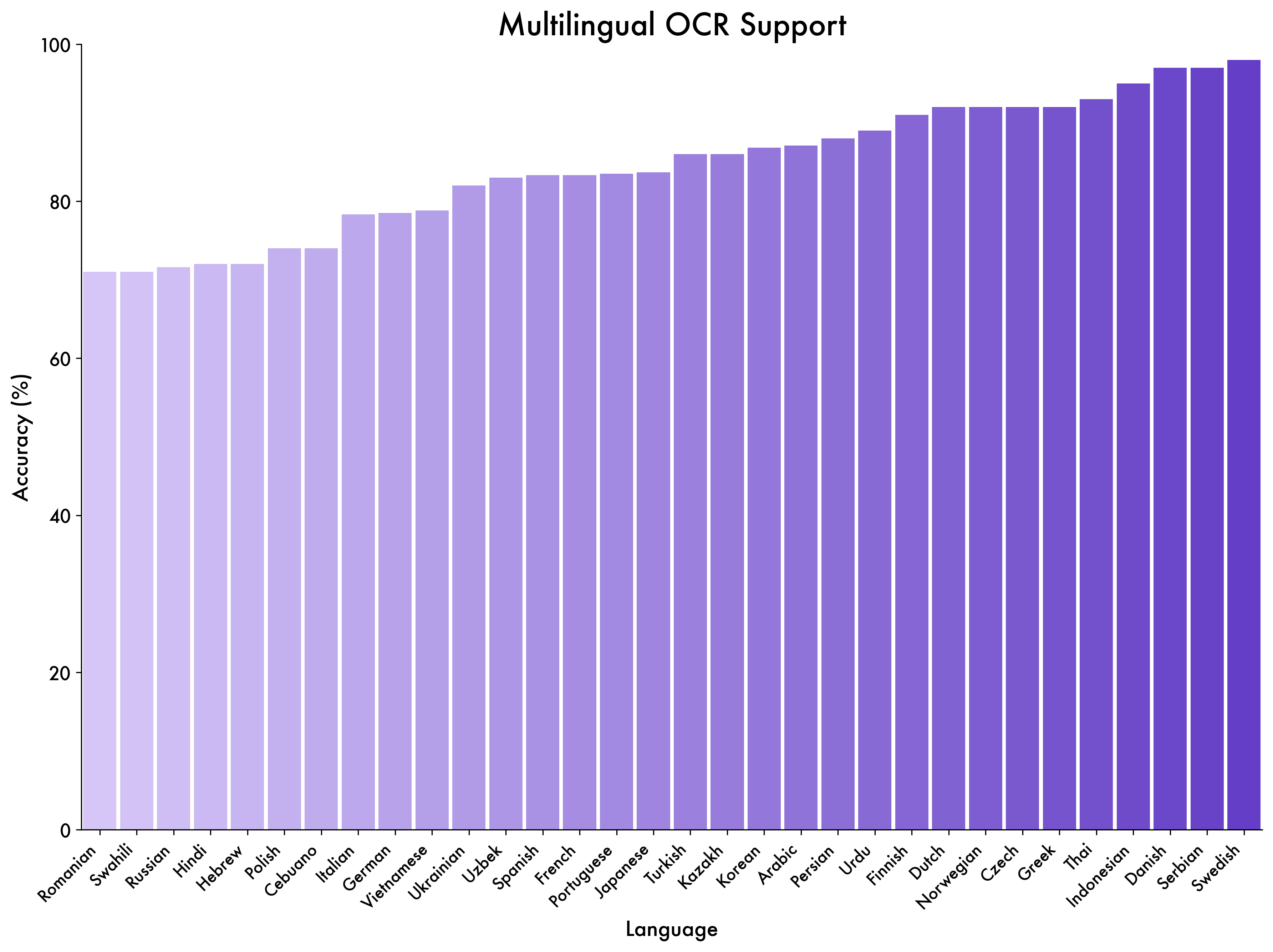
Qwen3-VL은 영어와 중국어를 넘어선 다국어 인식에서도 강점을 보였습니다. 한국어를 포함한 39개 언어로 구성된 테스트 세트에서 평가한 결과, 32개 언어에서 70% 이상의 정확도를 달성하여 실제 활용 가능한 수준에 도달했습니다. 이는 Qwen3-VL이 단일 언어 모델에 머무르지 않고, 국제적 환경에서 활용 가능한 범용 멀티모달 AI임을 보여주는 중요한 결과입니다.
Qwen3-VL은 시각 인식 과제에서 Gemini 2.5 Pro 및 GPT-5와 같은 폐쇄형 모델과 동등하거나 그 이상의 성능을 기록하였으며, 멀티모달 추론 과제에서는 공개된 모델 중 새로운 기준을 수립하였습니다. STEM 문제 풀이, 장시간 비디오 이해, 복잡한 문서 처리에서 우수한 성과를 나타내었으며, 동시에 실제 환경에서 적용 가능한 에이전트 기능과 코드 생성 능력까지 구현하였습니다.
이러한 성과는 멀티모달 AI가 단순히 정보를 “이해”하는 단계를 넘어, 실제 문제를 “추론하고 실행”하는 단계로 진입하였음을 의미합니다. 특히 Qwen3-VL이 오픈소스로 공개되었고 Apache 2.0 라이선스를 채택하여 상업적 활용까지 자유롭다는 점은 학계와 산업계 전반에서 그 파급력을 더욱 확대할 것입니다.
Qwen3-VL 모델 정리
Qwen3-VL은 텍스트와 이미지를 각각 독립적으로 처리하는 기존 접근을 넘어, 둘 모두를 완전히 통합하여 하나의 인지적 체계로 작동하는 모델입니다. 이를 통해 멀티모달 AI가 단순한 조력자 수준을 넘어, 실제 세계의 사건과 관계를 깊이 이해하고, 논리적으로 추론하며, 필요 시 구체적인 행동을 수행할 수 있는 단계에 도달했음을 보여줍니다.
향후 Qwen3-VL은 자율 에이전트, 로보틱스, 지능형 사용자 인터페이스, 초장문맥 기반 연구 및 교육 등 다양한 분야에서 활용될 것으로 기대됩니다. 이는 멀티모달 인공지능의 진정한 실용화에 한 걸음 더 다가서는 중요한 진전이라 평가할 수 있습니다.
 Qwen 모델 홈페이지
Qwen 모델 홈페이지
 Qwen3-VL 출시 블로그
Qwen3-VL 출시 블로그
 Qwen3-VL GitHub 저장소
Qwen3-VL GitHub 저장소
Qwen3-VL 모델 활용 안내서(Cookbook)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()