
Qwen3 모델 소개
Alibaba Qwen팀이 새로운 대형 언어 모델 시리즈인 Qwen3를 공개했습니다. 기존 Qwen2.5보다 두 배 가까이 늘어난 데이터로 학습되었고, “생각하는” 모드와 “빠르게 반응하는” 모드를 자유롭게 전환할 수 있다고 하는데요. ![]() 작은 모델부터 235B급 초대형 모델까지 다양한 라인업을 공개했으며, Hugging Face, ModelScope, Kaggle 등에서도 사용할 수 있게 했다고 합니다.
작은 모델부터 235B급 초대형 모델까지 다양한 라인업을 공개했으며, Hugging Face, ModelScope, Kaggle 등에서도 사용할 수 있게 했다고 합니다.
Qwen3는 Qwen2.5 시리즈의 후속작으로, 대규모 사전학습 언어 모델(Large Language Model, LLM)입니다. 이번에 공개된 Qwen3는 총 8개의 모델 버전을 포함하며, 특히 235B 파라미터 모델과 30B MoE(Mixture of Experts) 모델이 오픈웨이트로 제공되어 주목받고 있습니다.
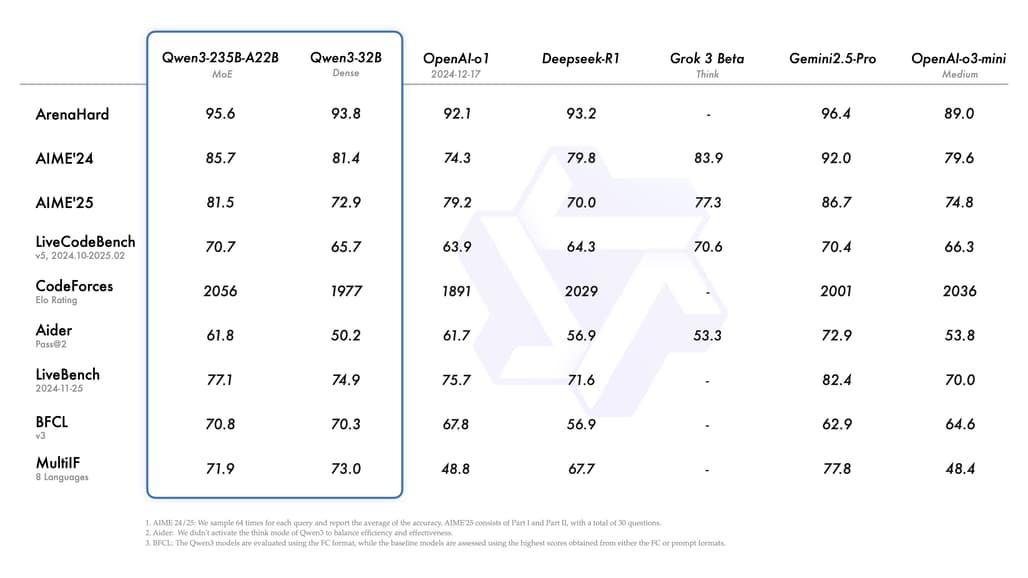
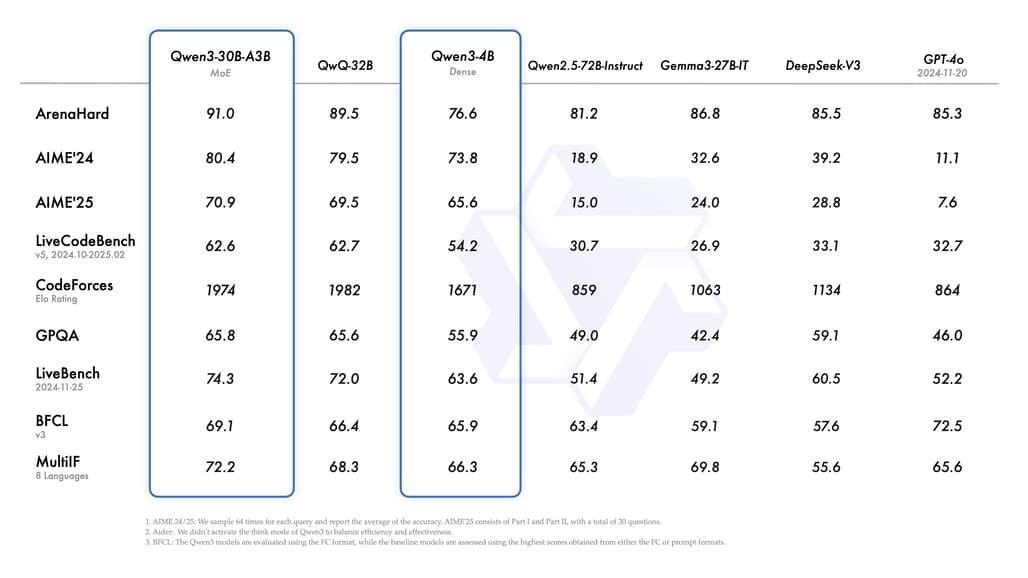
Qwen3는 기존 대비 두 배 가까운 36조 토큰 데이터를 기반으로 학습되었고, 사전 학습(pre-training)과 사후 학습(post-training) 모두에서 “긴CoT(Chain-of-Thought)”와 “빠른 응답”을 동시에 달성하기 위해 특별히 설계되었습니다. 특히 복잡한 문제는 천천히 사고하는 방식(Thinking Mode)으로, 간단한 문제는 빠르게 답변하는 방식(Non-Thinking Mode)으로 모드를 선택할 수 있는 것이 큰 특징입니다.
또한, 119개 언어 및 방언을 지원하고, 코드 생성과 에이전트 역할 수행(Agentic Capability)에서도 뛰어난 성능을 보이고 있어 글로벌 개발자 커뮤니티에서도 활용도가 기대됩니다. 또한, Qwen3는 여러 최신 모델들과 성능을 비교했을 때, 다음과 같은 특징을 보였습니다:
- Qwen3-235B-A22B는 DeepSeek-R1, o1, o3-mini, Grok-3, Gemini-2.5-Pro와 같은 최신 모델들과 비슷하거나 더 좋은 결과를 기록했습니다.
- Qwen3-30B-A3B는 MoE 구조를 통해 적은 활성 파라미터 수(3B)로도 기존 32B 모델 수준의 성능을 넘었습니다.
- 작은 모델인 Qwen3-4B조차도 이전 Qwen2.5-72B-Instruct 모델과 비슷한 성능을 보였습니다.
다른 대형 모델들과 비교해도 Qwen3는 “사고 모드”와 “비사고 모드”를 자유롭게 넘나들 수 있는 독특한 기능 덕분에 차별화된 장점을 가집니다.
주요 특징
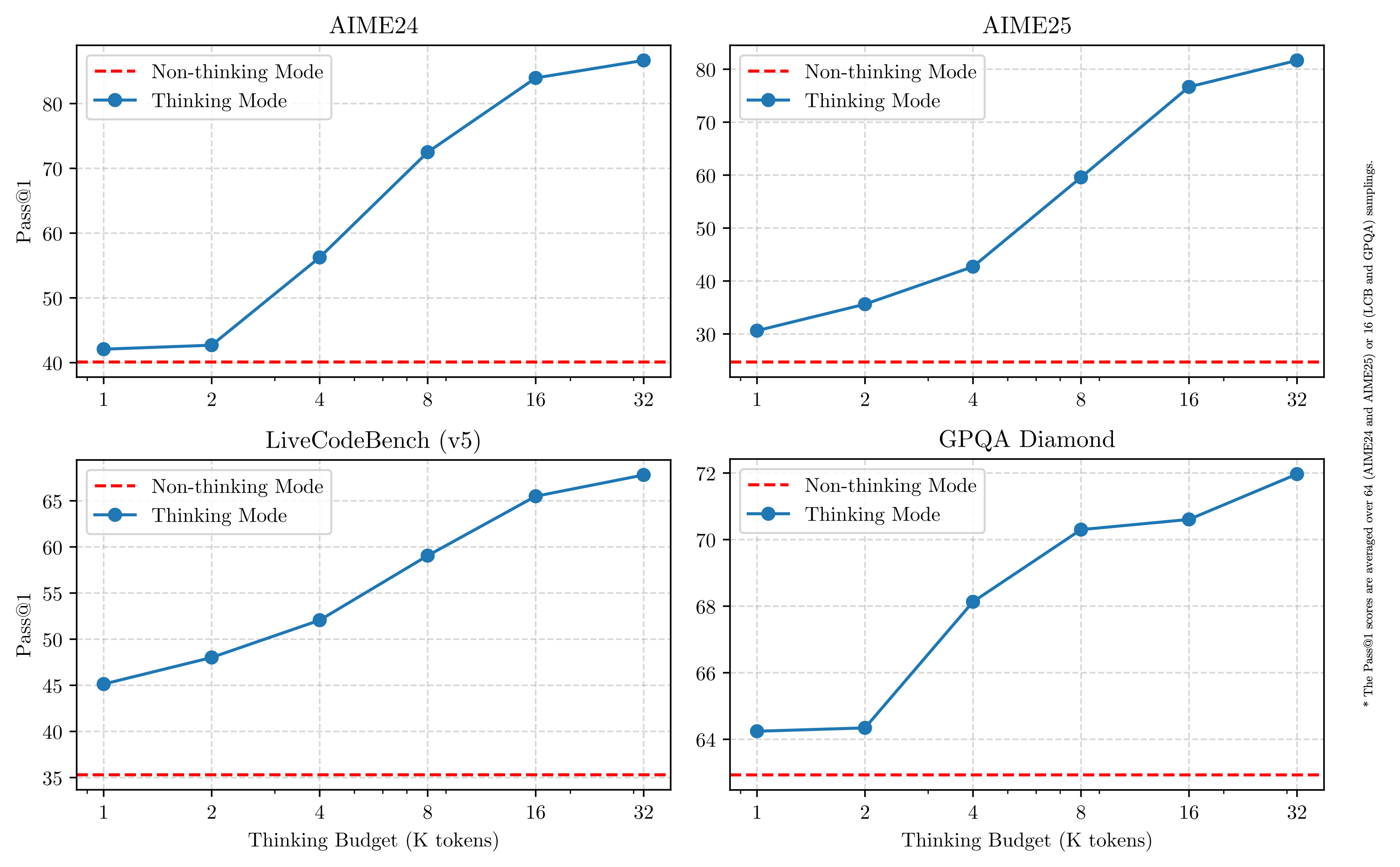
- 하이브리드 사고 모드: 문제 난이도에 따라 깊이 사고하거나 빠르게 답변하는 두 가지 모드를 지원합니다.
- 광범위한 다국어 지원: 한국어를 포함하여, 총 119개 언어와 방언을 지원합니다.
- 에이전트 능력 강화: 외부 툴 연동, 명령 실행 등 다양한 자동화 및 에이전트 시나리오에 강력하게 대응할 수 있습니다.
- MoE(혼합 전문가) 모델 제공: 계산 비용을 대폭 절감하면서도 높은 성능을 유지할 수 있도록 설계되었습니다.
- 확장된 학습 데이터: Qwen2.5 대비 약 2배 많은 36조 토큰을 사용하여 학습하였고, 수학, 코딩 데이터도 대폭 강화했습니다.
사용 방법
Qwen3 모델은 다양한 플랫폼과 툴을 통해 쉽게 사용할 수 있습니다:
- Hugging Face Transformers 예시 코드:
from modelscope import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-30B-A3B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", device_map="auto")
prompt = "대형 언어 모델에 대해 간단히 소개해 주세요."
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True, enable_thinking=True)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs, max_new_tokens=32768)
output = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
print(output)
- Thinking 모드 토글: enable_thinking=True 또는 False로 조정할 수 있으며, 프롬프트 안에 /think 또는 /no_think 명령어를 넣어 대화 중에도 변경 가능합니다.
- 서버 배포: SGLang이나 vLLM을 통해 OpenAI API 호환 서버를 구축할 수 있습니다.
- 로컬 개발: Ollama, LMStudio, llama.cpp, KTransformers 등을 이용하여 개인 PC에서도 실행 가능합니다.
 Qwen3 출시 블로그
Qwen3 출시 블로그
 Qwen3 GitHub 저장소
Qwen3 GitHub 저장소
https://github.com/QwenLM/Qwen3
 Qwen 모델 데모
Qwen 모델 데모
 Qwen3 모델 다운르도
Qwen3 모델 다운르도
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()