
RAG-Anything 소개
검색 증강 생성(Retrieval-Augmented Generation, RAG)은 LLM이 외부 지식 저장소를 활용하여 정확하고 최신의 정보를 바탕으로 답변을 생성하는 기법입니다. 그러나 기존의 RAG 시스템들은 대부분 텍스트 중심으로 설계되어 있어, 실제 문서에서 빈번하게 등장하는 다이어그램, 표, 수식, 차트 같은 비텍스트 요소들을 효과적으로 처리하지 못하는 한계가 있었습니다. 학술 연구에서는 실험 결과가 그래프와 다이어그램으로 표현되고, 금융 분석에서는 시장 차트와 상관 행렬에 핵심 인사이트가 담겨 있으며, 의료 문헌에서는 영상 이미지와 진단 차트가 결정적 정보를 포함합니다. 홍콩대학교 데이터 인텔리전스 랩(HKUDS)은 이 문제를 해결하기 위해 RAG-Anything를 공개하였습니다.
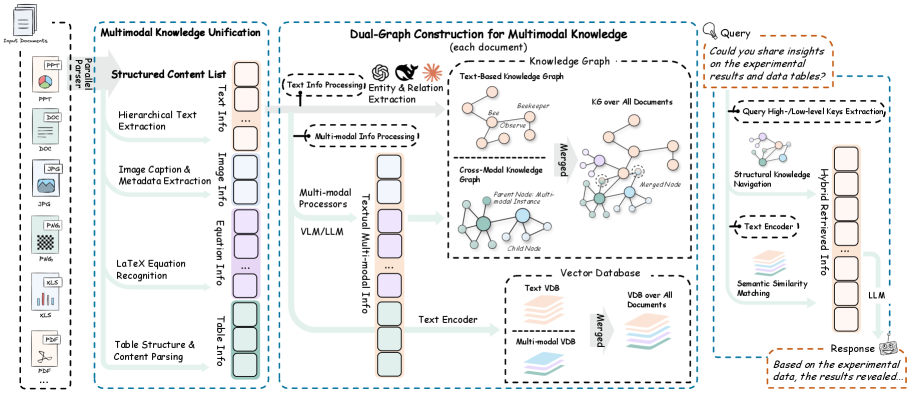
RAG-Anything는 LightRAG(EMNLP 2025)를 기반으로 구축된 올인원 멀티모달 RAG 시스템입니다. 이 프레임워크는 텍스트는 물론 이미지, 표, 수식까지 단일 인터페이스로 처리할 수 있는 통합 파이프라인을 제공합니다. 기존에는 모달리티별로 서로 다른 RAG 시스템을 연결해야 했거나, 아예 비텍스트 정보를 손실시키면서 처리해야 했는데, RAG-Anything는 이러한 복잡성을 단일 파이프라인으로 통합합니다. 사용자는 pip install raganything 명령 하나로 설치하여 PDF, Office 문서, 이미지를 포함한 다양한 형식의 문서에 RAG를 적용할 수 있습니다.
멀티모달 RAG의 세 가지 기술적 도전 과제
논문은 멀티모달 RAG가 단순히 텍스트 RAG의 확장이 아니라, 본질적으로 다른 아키텍처 접근이 필요하다고 분석합니다. RAG-Anything는 다음 세 가지 도전 과제를 풀기 위해 설계되었습니다.
1) 통합 멀티모달 표현(Unified Multimodal Representation): 서로 다른 정보 유형을 매끄럽게 통합하면서도 각 모달리티의 고유한 특성과 모달리티 간 관계를 보존해야 합니다. 모달리티 내부(intra-modal) 의존성과 모달리티 간(inter-modal) 의존성을 동시에 포착할 수 있는 표현이 필요합니다.
2) 구조 인지 분해(Structure-Aware Decomposition): 복잡한 레이아웃을 지능적으로 파싱하면서 공간적, 계층적 관계를 유지해야 합니다. 문서 구조를 해석하고 멀티모달 요소들의 문맥적 위치를 보존하는 레이아웃 인지 파싱이 요구됩니다.
3) 크로스-모달 검색(Cross-Modal Retrieval): 서로 다른 모달리티 사이를 탐색하고 그 상호 연결을 추론할 수 있는 정교한 메커니즘이 필요합니다. 텍스트 질의가 시각적, 구조적 정보에 효과적으로 접근할 수 있도록 의미적 대응 관계를 이해하는 크로스-모달 정렬이 핵심입니다.
이러한 도전은 관련 증거가 여러 모달리티와 섹션에 분산되어 있는 긴 문서(long-context) 시나리오에서 더욱 증폭됩니다.
RAG-Anything의 핵심 기여
RAG-Anything는 위 도전 과제에 대해 다음과 같은 기여를 제시합니다.
-
이중 그래프 구축(Dual-Graph Construction) 은 크로스-모달 지식 그래프와 텍스트 기반 지식 그래프를 별도로 구축한 뒤 엔티티 정렬(entity alignment)로 융합하는 전략입니다. 모달리티별 구조 신호를 잃지 않으면서 텍스트 의미 관계도 함께 포착합니다.
-
크로스-모달 하이브리드 검색 은 그래프의 구조적 탐색(structural navigation)과 임베딩 공간의 의미 유사도 매칭(semantic matching)을 결합하여 다중 홉 추론과 의미 검색을 동시에 수행합니다.
-
모달리티 인지 질의 처리 는 질의에 포함된 "figure", "table", "equation" 같은 단서를 분석해 모달리티 선호를 추론하고, 검색 결과 융합 점수에 반영합니다.
-
긴 문서 강건성 은 문서가 길어질수록 베이스라인 대비 성능 격차가 커지는 것을 실험적으로 입증하였습니다.
RAG-Anything의 멀티모달 파이프라인
RAG-Anything는 문서 처리부터 답변 생성까지 네 가지 핵심 모듈로 구성된 엔드-투-엔드 파이프라인을 제공합니다.
멀티모달 파싱 엔진: PDF, DOCX, PPTX 등 다양한 형식의 문서를 입력받아 각 페이지와 구성 요소를 분석합니다. 텍스트 추출, 이미지 분석, 수식 인식, 표 파싱의 4개 서브모듈이 협력하여 문서의 모든 정보를 손실 없이 처리합니다. 논문의 실험에서는 MinerU를 파서로 사용합니다.
크로스-모달 지식 그래프 구축: 각 지식 소스 k_i 를 원자적 콘텐츠 단위 \{c_j = (t_j, x_j)\} 로 분해합니다. 여기서 t_j 는 모달리티 유형(텍스트, 이미지, 표, 수식 등)이고 x_j 는 추출된 원본 콘텐츠입니다. 멀티모달 LLM은 각 단위에서 검색용 상세 설명 d_j^{\text{chunk}} 와 그래프 구축용 엔티티 요약 e_j^{\text{entity}} 두 가지 텍스트 표현을 생성하며, 이때 이웃 윈도우 C_j = \{c_k \mid |k-j| \leq \delta\} 를 함께 고려해 문맥을 반영합니다.
그래프 융합과 인덱스 생성: 비텍스트 단위에서 추출된 멀티모달 그래프 (\tilde{V}, \tilde{E}) 와 텍스트 청크에서 LightRAG/GraphRAG 방식으로 추출된 텍스트 기반 지식 그래프를 엔티티 이름을 키로 정렬하여 통합 그래프 \mathcal{G} = (\mathcal{V}, \mathcal{E}) 를 만듭니다. 모든 엔티티, 관계, 청크에 대해 dense embedding \mathcal{T} 를 생성해 최종 인덱스 \mathcal{I} = (\mathcal{G}, \mathcal{T}) 를 구성합니다.
크로스-모달 하이브리드 검색: 질의가 들어오면 두 검색 경로를 병행합니다. 구조적 탐색은 키워드/엔티티 매칭으로 시작점을 찾은 뒤 그래프 이웃 확장으로 후보 \mathcal{C}_{\text{stru}}(q) 를 만들고, 의미 유사도 매칭은 질의 임베딩 \mathbf{e}_q 와 \mathcal{T} 의 코사인 유사도로 후보 \mathcal{C}_{\text{seman}}(q) 를 얻습니다. 두 후보 풀은 \mathcal{C}(q) = \mathcal{C}_{\text{stru}}(q) \cup \mathcal{C}_{\text{seman}}(q) 로 통합되고, 그래프 위상에서 도출한 구조적 중요도, 임베딩 유사도, 모달리티 선호를 결합한 다중 신호 융합 점수로 재정렬됩니다.
멀티모달 응답 합성: 최종 후보 \mathcal{C}^{\star}(q) 의 텍스트 컨텍스트와, 시각 자료에 대해 역참조(dereferencing)한 원본 이미지 \mathcal{V}^{\star}(q) 를 함께 비전-언어 모델에 입력하여 응답을 생성합니다.
이 설계는 텍스트 프록시로 효율적으로 검색하고 합성 시점에는 원본 시각 콘텐츠를 직접 활용하여 풍부한 의미를 보존합니다.
RAG-Anything의 실험 결과
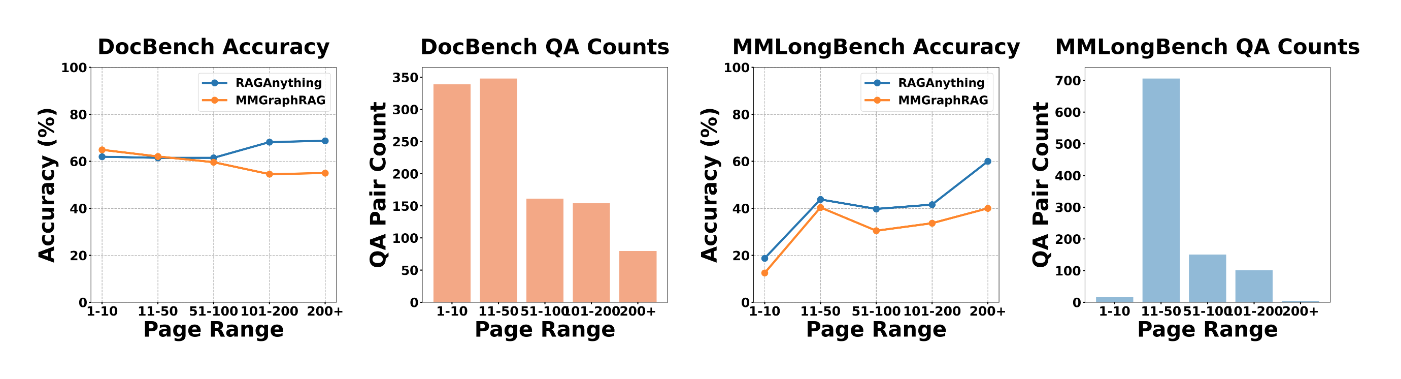
저자들은 DocBench(229개 문서, 평균 66페이지, 1,102개 질의)와 MMLongBench(135개 문서, 7개 문서 유형, 1,082개 질의) 두 멀티모달 문서 QA 벤치마크에서 평가를 수행했습니다. 모든 베이스라인은 GPT-4o-mini를 백본으로 사용하고, text-embedding-3-large 임베딩과 bge-reranker-v2-m3 리랭커를 적용했습니다.
DocBench 정확도(%)
| 방법 | Aca. | Fin. | Gov. | Law. | News | Txt. | Mm. | Una. | Overall |
|---|---|---|---|---|---|---|---|---|---|
| GPT-4o-mini | 40.3 | 46.9 | 60.3 | 59.2 | 61.0 | 61.0 | 43.8 | 49.6 | 51.2 |
| LightRAG | 53.8 | 56.2 | 59.5 | 61.8 | 65.7 | 85.0 | 59.7 | 46.8 | 58.4 |
| MMGraphRAG | 64.3 | 52.8 | 64.9 | 40.0 | 61.5 | 67.6 | 66.0 | 60.5 | 61.0 |
| RAG-Anything | 61.4 | 67.0 | 61.5 | 60.2 | 66.3 | 85.0 | 76.3 | 46.0 | 63.4 |
MMLongBench 정확도(%)
| 방법 | Res. | Tut. | Acad. | Guid. | Broch. | Admin. | Fin. | Overall |
|---|---|---|---|---|---|---|---|---|
| GPT-4o-mini | 35.5 | 44.0 | 24.6 | 33.1 | 29.5 | 46.8 | 31.1 | 33.5 |
| LightRAG | 40.8 | 34.1 | 36.2 | 39.4 | 41.0 | 44.4 | 38.3 | 38.9 |
| MMGraphRAG | 40.8 | 36.5 | 35.7 | 35.8 | 28.2 | 46.9 | 38.5 | 37.7 |
| RAG-Anything | 46.6 | 43.5 | 38.7 | 43.9 | 34.0 | 45.7 | 43.6 | 42.8 |
긴 문서에서의 우위: 문서 길이가 길어질수록 RAG-Anything의 강점이 두드러집니다. DocBench에서 100페이지를 초과하는 문서의 경우 MMGraphRAG와의 격차가 13점 이상으로 벌어졌으며(101-200페이지에서 68.2% 대 54.6%, 200페이지 이상에서 68.8% 대 55.0%), MMLongBench에서도 51-100페이지에서 9.3점, 101-200페이지에서 7.9점의 정확도 향상을 보였습니다.
어블레이션 연구: 어떤 구성요소가 중요한가
저자들은 두 가지 변형을 두고 핵심 설계의 기여도를 측정했습니다.
| 방법 | Aca. | Fin. | Gov. | Law. | News | Txt. | Mm. | Una. | Overall |
|---|---|---|---|---|---|---|---|---|---|
| Chunk-only | 55.8 | 61.5 | 60.1 | 60.7 | 64.0 | 81.6 | 66.2 | 43.5 | 60.0 |
| w/o Reranker | 60.9 | 63.5 | 58.8 | 60.2 | 68.6 | 81.7 | 74.7 | 45.4 | 62.4 |
| RAG-Anything | 61.4 | 67.0 | 61.5 | 60.2 | 66.3 | 85.0 | 76.3 | 46.0 | 63.4 |
이중 그래프 구축을 제거하고 전통적 청크 검색만 사용하는 Chunk-only 변형은 60.0%에 그쳐, 그래프 기반 구조 표현이 멀티모달 추론에 결정적임을 보여줍니다. 리랭커를 제거한 w/o Reranker는 62.4%로 소폭 하락하여, 성능의 주된 원천이 리랭커가 아니라 그래프 기반 검색과 크로스-모달 통합임을 시사합니다.
케이스 스터디: 구조 인지 검색의 효과
논문은 두 가지 대표 사례로 구조 인지 그래프의 효용을 보여줍니다.
다중 패널 그림 해석: t-SNE 시각화처럼 여러 서브패널을 가진 그림에서, RAG-Anything는 패널, 축 라벨, 범례, 캡션을 노드로 하고 "패널-포함", "캡션-설명", "서브패널-계층" 등의 의미 관계를 엣지로 가지는 시각 레이아웃 그래프를 구축합니다. 이를 통해 인접한 content-space 패널과 혼동하지 않고 style-space 패널의 클러스터 분리 패턴에 정확히 집중할 수 있습니다.
금융 표 탐색: 행 헤더, 열 헤더(연도), 데이터 셀, 단위를 노드로 하고 row-of, column-of, header-applies-to, unit-of 관계를 명시적으로 모델링하여, 유사한 용어가 반복되는 재무 표에서도 "Wages and salaries" 행과 "2020" 열의 교차점(26,778 million)을 정확히 짚어냅니다. 표를 선형 텍스트로 평탄화하는 기존 방법과 달리 구조적 모호성을 해소합니다.
저자들은 부록에서 한계도 솔직히 짚고 있습니다. 시스템이 시각 정보가 명시적으로 요구되는 질의에서도 텍스트 소스를 선호하는 텍스트 중심 검색 편향(text-centric retrieval bias)과, 표준 레이아웃을 벗어난 문서(셀 병합, 비표준 칼럼 경계)에 대한 경직된 공간 처리(rigid spatial processing)는 향후 적응적 공간 추론과 레이아웃 인지 파싱으로 보완해야 할 과제로 남아 있습니다.
RAG-Anything 설치 및 사용법
pip install raganything
import asyncio
from raganything import RAGAnything
async def main():
# RAG-Anything 초기화
rag = RAGAnything(
llm_model_func=your_llm_func,
vision_model_func=your_vision_func # 이미지 처리용
)
# 멀티모달 문서 인덱싱 (PDF, DOCX 등)
await rag.process_document_complete(
file_path="research_paper.pdf",
output_dir="./rag_output"
)
# 멀티모달 질의 응답
result = await rag.query(
"논문의 주요 실험 결과와 관련 그림을 설명해줘",
mode="hybrid" # 그래프 + 벡터 하이브리드 검색
)
print(result)
asyncio.run(main())
LightRAG와의 통합 설정도 간단합니다:
# LightRAG에 멀티모달 처리 기능 추가
from raganything import RAGAnything
from lightrag import LightRAG
rag = RAGAnything(
working_dir="./lightrag_cache",
llm_model_func=openai_compatible_model,
vision_model_func=vision_model # 멀티모달 파싱용
)
기존 RAG 시스템과의 비교
RAG-Anything가 해결하는 핵심 문제를 기존 시스템과 비교하면 다음과 같습니다:
| 기능 | RAG-Anything | 기존 텍스트 RAG | GraphRAG |
|---|---|---|---|
| 텍스트 처리 | |||
| 이미지 분석 | |||
| 표 파싱 | 부분적 | 부분적 | |
| 수식 인식 | |||
| 크로스-모달 추론 | |||
| 통합 인터페이스 |
라이선스
RAG-Anything는 MIT 라이선스로 공개되어 있어 개인 및 상업적 목적으로 자유롭게 사용, 수정, 배포할 수 있습니다.
 RAG-Anything 논문
RAG-Anything 논문
 RAG-Anything 프로젝트 GitHub 저장소
RAG-Anything 프로젝트 GitHub 저장소
더 읽어보기
-
LightRAG: 지식 그래프 기반의 이중 검색 구조로 GraphRAG보다 빠른 RAG 프레임워크 (feat. EMNLP 2025)
-
Agentic RAG for Dummies: Agentic 기반 RAG 시스템을 이해하고 구축할 수 있도록 돕는 오픈소스 프로젝트 (feat. LangGraph)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()