글 소개
Together AI Platform에서 Mistral 7B Instruct v0.2를 RAG(검색 증강 생성) 기법으로 미세 조정하여 더 정확하고 빠르며 비용 효율적인 코드 생성 모델을 개발했습니다. 최신 코드베이스와 정확한 코드 구조를 생성하는데 LLM과 RAG 기술을 어떻게 활용했는지 알아보세요.
코드 작성에서의 LLM과 RAG
대규모 언어 모델(LLM)은 코드 생성, 작업 계획 및 문서 이해와 같은 여러 응용 분야에서 유망한 성능을 보여주고 있습니다. 그러나 이러한 모델은 두 가지 주요 이유로 종종 부족한 성능을 보입니다: 환각과 모델의 오래된 지식입니다. 이러한 이유들로 LLM은 특정 코드베이스를 참조하는 코드를 생성하는 데 제한이 있으며 최신 코드와 정확한 코드 구조가 필요합니다.
RAG(검색 강화 생성, Retrieval-Augmented Generation)는 언어 모델의 한계를 극복하기 위해 검색 방법을 텍스트 생성 과정에 통합하는 기술입니다. 이 접근 방식은 두 가지 주요 단계인 인덱싱과 쿼리로 구성됩니다. 인덱싱 단계에서는 외부 지식 소스(예: 내부 문서)가 청크로 나누어져 임베딩 모델을 사용해 벡터로 변환된 후 벡터 데이터베이스에 저장됩니다. 쿼리 단계에서는 이 데이터베이스에서 관련 정보를 검색하여 초기 쿼리와 결합하여 최종 출력을 생성합니다.
코드 생성에서의 LLM의 문제점
기존의 LLM은 대량의 데이터를 학습하여 일반화 능력을 향상시키지만, 많은 잡음 데이터와 부정확한 정보를 학습할 수 있습니다. 또한, 더 일반화된 기능을 가지게 되면 특정 코드베이스와 같은 도메인별 지식을 희생할 수 있습니다. 이로 인해 사용자의 쿼리에 기반한 그럴듯하지만 부정확한 코드를 생성할 수 있습니다.
또한, 코드베이스가 발전함에 따라 LLM의 정적 지식은 최신 프로그래밍 관행이나 라이브러리 업데이트를 따르지 못하게 되는 문제가 있습니다.
RAG를 이용한 온라인 저장소 수준의 미세 조정
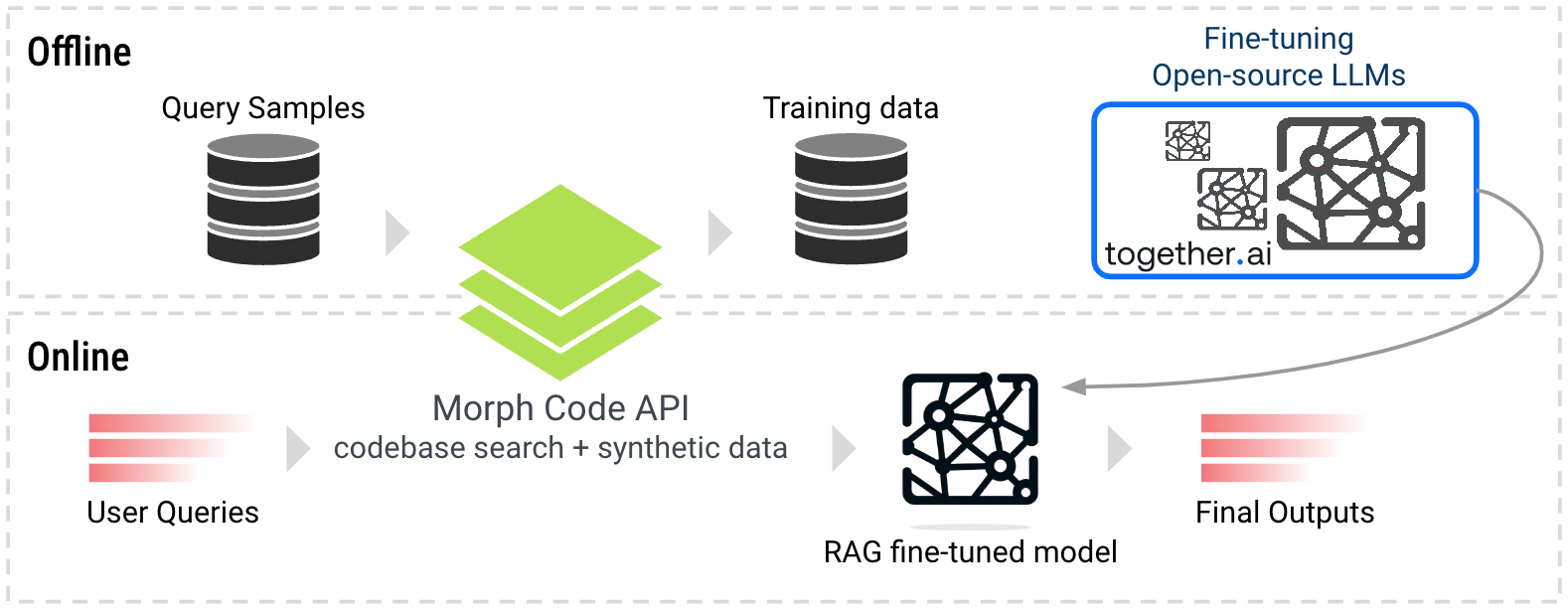
RAG는 이러한 한계를 극복하기 위해 인기 있는 기술이지만, 기존의 오픈소스 모델은 도메인별 지식이나 형식을 사용하여 검색된 정보를 활용하는 데 제한이 있습니다. RAG 성능을 향상시키기 위해 우리는 RAG 미세 조정 방법을 연구하고 코드 생성 작업에 적용했습니다. 이 접근 방식은 각 쿼리에 따라 코드 저장소에서 관련 코드 스니펫을 먼저 검색한 후, 이를 컨텍스트로 사용하여 모델의 훈련 단계에서 정확하고 최신 코드베이스를 기반으로 하는 코드를 생성하도록 합니다.
Morph Labs는 질문과 정답 쌍을 포함한 합성 데이터셋을 생성했습니다. 각 질문에 대해 Morph Code API를 통해 검색된 코드 스니펫이 RAG 컨텍스트로 사용되어 질문-답변 쌍과 결합됩니다. 이를 통해 모델이 사전 데이터를 사용하는 대신 쿼리에서 제공된 실시간 지식을 활용하는 방법을 학습할 수 있습니다.
이 글에서는 다섯가지의 서로 다른 코드베이스(Axolotl, Deepspeed, vLLM, Mapbox, WandB에서 실험을 수행했습니다. 이 코드베이스들은 기계 학습 코드베이스를 포괄적으로 다루며, 많은 기존 LLM이 복잡하고 빠르게 발전하는 특성 때문에 이해하는 데 어려움을 겪고 있습니다.
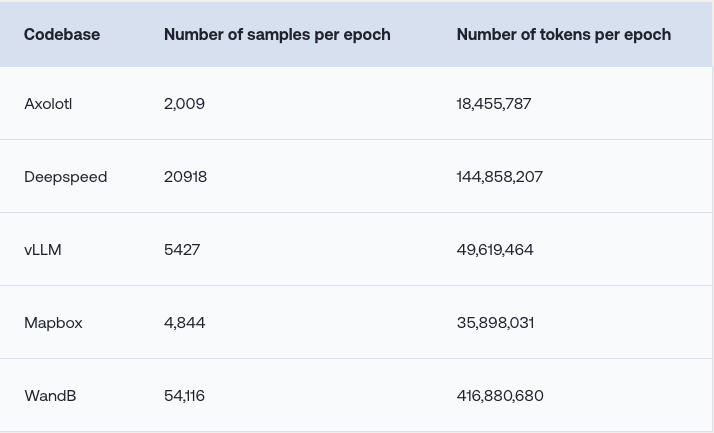
이후,개인 맞춤형 코드 어시스턴트를 만들기 위해, Together Fine-tuning API를 사용하여 각 코드베이스에 대해 언어 생성 모델을 미세 조정했습니다. 실험에서는 Mistral 7B Instruct v0.2를 기본 모델로 사용했으며, 4개의 에포크, 배치 크기 12, 학습률 4e-6으로 설정했습니다.
추론 시에는 실시간 쿼리 처리 중 Morph Code API를 통해 각 쿼리에 대해 가장 관련 있고 최신 코드 스니펫을 온라인으로 검색한 후 응답을 생성합니다.
파인튜닝 결과
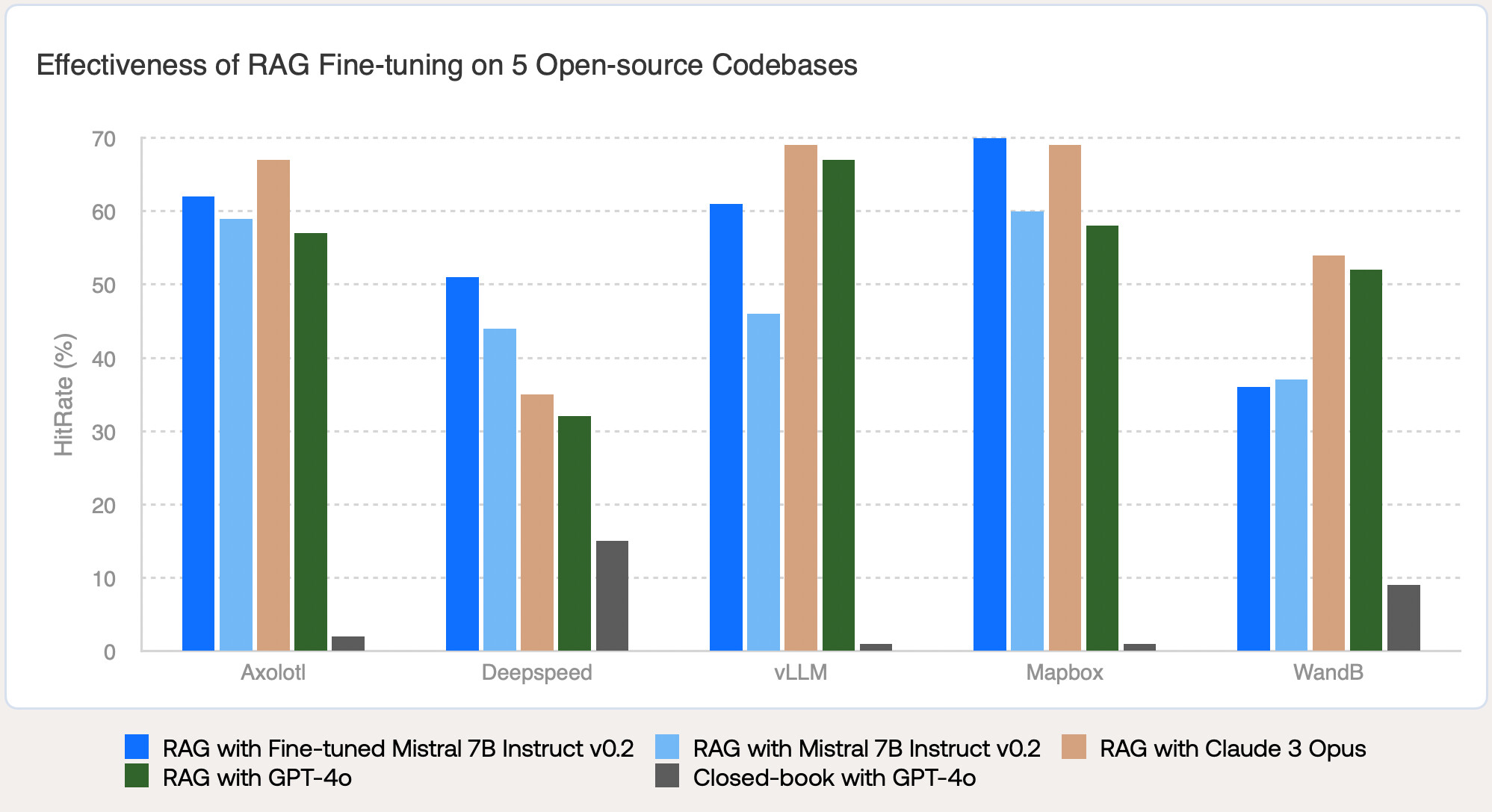
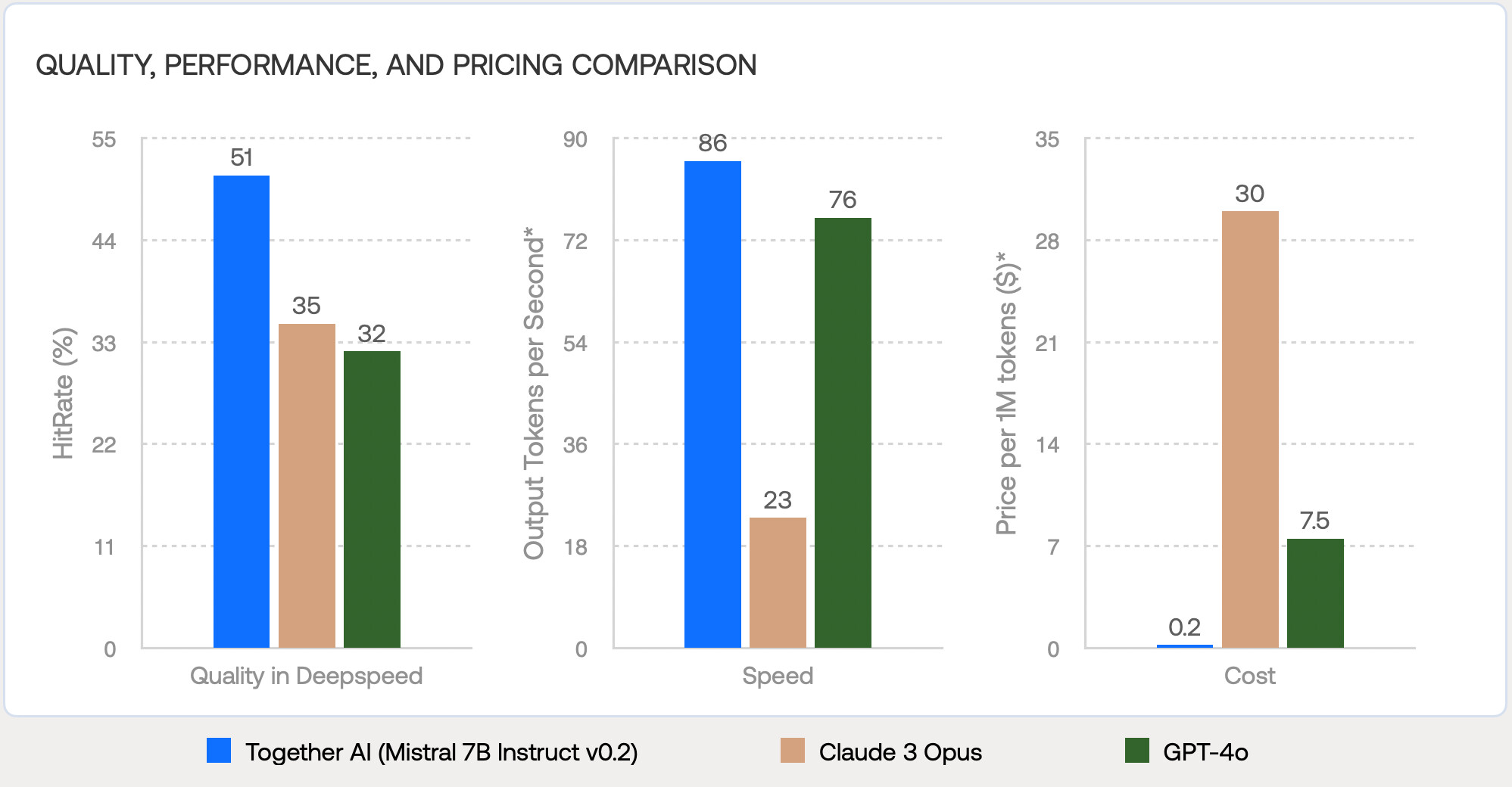
RAG 미세 조정된 Mistral 7B Instruct v0.2를 세 가지 다른 모델(Mistral 7B Instruct v0.2, Claude 3 Opus, GPT-4o)과 비교했습니다. RAG 설정에서 RAG 미세 조정 모델은 5개 코드베이스 중 4개에서 원래 모델보다 성능이 크게 향상되었습니다. RAG 미세 조정된 모델은 품질 측면에서 GPT-4o 및 Claude 3 Opus와 대등하거나 더 나은 성능을 보였습니다. RAG로 미세 조정된 Mistral 7B Instruct v0.2는 Claude 3 Opus보다 최대 16% 더 높은 정확도를 제공하며, 속도는 3.7배 빠르고 비용은 150배 저렴합니다. GPT-4o와 비교했을 때도 최대 19% 품질 개선, 1.1배 속도 향상, 37.5배 비용 절감을 보여줍니다.
원문: Building a personalized code assistant with open-source LLMs using RAG Fine-tuning
참고 문헌
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()