
RaptorML 소개
머신러닝(ML) 프로젝트를 진행할 때 데이터 과학자나 ML 엔지니어가 직면하는 가장 큰 어려움 중 하나는 바로 '연구' 단계에서 '운영(Production)' 단계로의 전환입니다. Jupyter 노트북이나 Python 스크립트 환경에서 성공적으로 검증된 모델과 데이터 로직을 실제 서비스에 안정적으로 배포하는 과정은, 연구와는 전혀 다른 차원의 엔지니어링 복잡성을 동반합니다. 확장성, 안정성, 데이터 파이프라인 연결, API 구축, 모니터링 등 백엔드 엔지니어링에 대한 깊은 지식이 필요하기 때문입니다.
RaptorML은 바로 이 고질적인 '연구-프로덕션 격차'를 해소하기 위해 등장한 도구입니다. 데이터 과학자들이 익숙한 Python 환경을 벗어나지 않고도, 자신들의 연구 결과물(피처 엔지니어링 로직, 모델 등)을 손쉽게 프로덕션 환경에 배포 가능한 '아티팩트(artifact)'로 컴파일할 수 있게 지원합니다. 즉, 데이터 과학자는 데이터 과학 본연의 업무에만 집중하고, 복잡한 백엔드 엔지니어링의 부담은 RaptorML이 Kubernetes 위에서 처리하도록 위임하는 것입니다.
RaptorML의 핵심 가치는 데이터 과학자가 작성한 Python 코드를 기반으로 확장 가능하고 신뢰할 수 있는 운영 시스템을 구축하는 데 있습니다. Python 데코레이터(@feature, @model 등)를 사용하여 피처와 모델을 '선언'하면, RaptorML은 이 정의를 해석하여 Kubernetes 네이티브 아티팩트로 변환합니다. 이 아티팩트들은 프로덕션 환경에서 데이터 소스에 자동으로 연결되고, 필요에 따라 실시간으로 피처를 계산하며, API를 통해 서빙됩니다.
무엇보다 Raptor가 주목받는 이유 중 하나는 머신러닝 시스템의 '학습/서빙 편향(training-serving skew)' 문제를 효과적으로 제거한다는 점입니다. 학습/서빙 편향은 모델 학습 시 사용한 데이터(혹은 피처 계산 로직)와 실제 프로덕션 환경에서 예측을 위해 사용한 데이터가 불일치하여 발생하는 성능 저하 문제입니다. RaptorML은 학습과 서빙에 동일한 Python 코드 베이스를 사용하도록 강제함으로써 이러한 불일치를 원천적으로 방지하고, 모델의 신뢰성을 높여줍니다.
RaptorML은 기존 MLOps 스펙트럼의 여러 도구들과 명확한 차별점을 가집니다. 아래 소개하는 다른 도구들과의 차이점을 이해하는 것은 RaptorML의 독특한 포지셔닝을 이해하는 데 중요합니다:
-
MLOps 플랫폼 (MLFlow, Kubeflow 등)과의 차이점: MLFlow나 Kubeflow와 같은 전통적인 MLOps 플랫폼은 주로 머신러닝 리소스의 수명 주기(lifecycle) 를 관리하는 데 중점을 둡니다. 예를 들어, 실험 추적, 모델 레지스트리, 파이프라인 오케스트레이션 등이 주요 기능입니다. 하지만 RaptorML은 리소스 관리보다는 프로덕션 환경에서 실행될 운영 모델과 피처의 비즈니스 로직 을 구축하고 컴파일하는 데 특화되어 있습니다. 물론 이 두 영역은 상호 보완적이며, RaptorML은 이러한 MLOps 플랫폼과 통합되어 사용될 수 있습니다.
-
피처 스토어 (Feast, Hopsworks 등)와의 차이점: 가장 큰 차별점이 드러나는 지점입니다. 전통적인 피처 스토어는 기본적으로 사전에 계산된 피처 값들을 저장하는 데이터 스토리지 시스템 입니다. 피처를 사용하기 위해서는 별도의 데이터 파이프라인(예: Spark, Flink)을 구축하고 오케스트레이션하여 피처 값을 계산하고 저장소에 적재해야 하는 부담이 있습니다.
RaptorML은 이에 대해 "근본적으로 다른 접근 방식"을 취한다고 설명합니다. RaptorML은 단순히 피처를 저장하는 시스템이 아닙니다. 대신, Python 코드로 정의된 피처 계산 로직 자체 를 관리하며, 통합된 캐싱 시스템을 통해 필요시(on-demand) 혹은 실시간으로 피처를 계산합니다. 이는 데이터 파이프라인 오케스트레이션이라는 복잡한 과정을 추상화하고, 데이터 과학자가 작성한 Python 함수가 곧 프로덕션 피처가 되도록 만듭니다. -
모델 서버 (BentoML, Sagemaker, KServe 등)와의 차이점: 모델 서버는 이미 학습된 모델을 API 엔드포인트로 서빙하는 역할을 합니다. RaptorML은 모델 서버와 경쟁하는 것이 아니라, 이들과 원활하게 통합 됩니다. RaptorML은 피처 계산 로직과 모델을 함께 패키징하여, Sagemaker나 BentoML 같은 모델 서버가 해당 모델을 올바르게 서빙할 수 있도록 준비하는 역할을 수행합니다.
RaptorML 동작 방식
RaptorML의 작업 흐름은 데이터 과학자의 연구 환경(노트북, IDE)에서 시작됩니다. 개발자는 Python 데코레이터를 사용하여 선언적으로, 그리고 Python 함수를 사용하여 논리적으로 작업을 정의합니다.
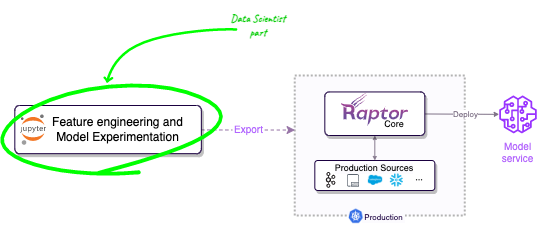
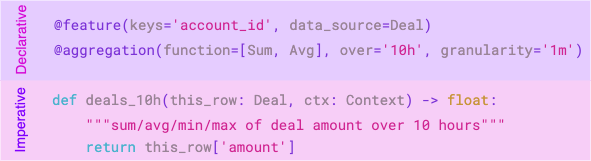
RaptorML 아키텍처의 핵심은 '선언적 데코레이터'와 '논리적 함수 코드'의 조합입니다. 예를 들어, @aggregation(function=AggregationFunction.Sum, over='10h')와 같은 데코레이터는 '무엇을 할지'(지난 10시간의 합계)를 선언합니다. 그러면 RaptorML은 이 선언을 해석하여 Kubernetes 환경에 최적화된 고성능 구현(예: 실시간 집계 파이프라인)으로 변환합니다. 반면, 개발자가 작성한 Python 함수 본문(비즈니스 로직)은 그대로 패키징되어 실행됩니다.
개발이 완료되면, .export() 메서드를 호출하여 이 정의들을 프로덕션 아티팩트로 컴파일합니다. 이 아티팩트들은 표준 CI/CD 파이프라인을 통해 Kubernetes 클러스터에 배포됩니다. 배포가 완료되면 'Raptor Core'(서버 사이드 컴포넌트)가 이 아티팩트들을 관리하며, 실제 프로덕션 데이터 소스에 연결하고, 스케일링, 상태 복구, 모니터링 등을 자동으로 처리합니다.
핵심 개념을 이루는 주요 데코레이터는 다음과 같습니다:
@data_source: 데이터가 어디에서 오는지(예: CSV, 스트리밍 Kafka, Parquet 파일 등)를 정의합니다.@feature: 특정 키(예: 'customer_id')를 기준으로 계산되는 피처 로직을 Python 함수로 정의합니다.@aggregation: 합계, 평균 등과 같은 시계열 집계 작업을 선언적으로 정의합니다.@model: 모델이 어떤 피처를 입력으로 사용하고, 어떻게 학습되며, 어떤 모델 서버(예: 'sagemaker-ack')로 서빙되어야 하는지를 정의합니다.
RaptorML의 주요 특징
RaptorML은 데이터 과학자와 백엔드 엔지니어링 간의 간극을 메우는 데 초점을 맞추고 있습니다:
첫째, 연구 작업에 집중할 수 있습니다. 데이터 과학자는 백엔드 엔지니어링을 배울 필요 없이 모델과 피처 로직 개발이라는 본연의 업무에만 집중할 수 있습니다.
둘째, 학습/서빙 편향을 제거합니다. 모델 학습 시 사용했던 피처 정의 코드와 프로덕션 서빙 시 사용되는 코드가 100% 동일하므로, 두 환경 간의 불일치로 인한 모델 성능 저하를 원천적으로 차단합니다.
셋째, 실시간/온디맨드 처리 및 캐싱을 지원합니다. 전통적인 피처 스토어처럼 모든 피처를 미리 계산하여 저장하는 대신, 요청 시점에 피처를 계산하거나(on-demand) 스트리밍 데이터를 실시간으로 처리합니다. 또한 강력한 캐싱 시스템이 내장되어 있어 반복적인 계산을 방지하고 응답 속도를 보장합니다.
넷째, Kubernetes 네이티브 아티팩트를 생성합니다. RaptorML이 컴파일한 결과물은 Kubernetes 환경에서 기본적으로 작동하도록 설계되었습니다. 이는 자동 확장, 자가 치유, 모니터링 등 Kubernetes의 이점을 모두 활용할 수 있음을 의미하며, 기존 DevOps 워크플로우(CI/CD)와 자연스럽게 통합됩니다.
시작하기: 설치 및 빠른 예제
RaptorML을 로컬 연구 환경(노트북, IDE)에서 사용하기 위해서는 RaptorLabSDK 패키지를 설치해야 합니다.
pip install raptor-labsdk
다음은 공식 GitHub 저장소에서 제공하는 간단한 예제 코드입니다. 이 코드는 은행 거래 내역을 데이터 소스로 하여, 특정 고객의 최근 10시간 동안의 총지출액을 피처로 계산하고, 이 피처를 입력받아 지출액을 예측하는 'sklearn' 모델을 정의한 뒤, 이를 프로덕션 아티팩트로 내보내는 전체 과정을 보여줍니다.
import pandas as pd
from raptor import *
from typing_extensions import TypedDict
# 1. 데이터 소스 정의 (CSV 파일 및 스트리밍 설정)
@data_source(
training_data=pd.read_csv(
'https://gist.githubusercontent.com/AlmogBaku/8be77c2236836177b8e54fa8217411f2/raw/hello_world_transactions.csv'
),
production_config=StreamingConfig()
)
class BankTransaction(TypedDict):
customer_id: str
amount: float
timestamp: str
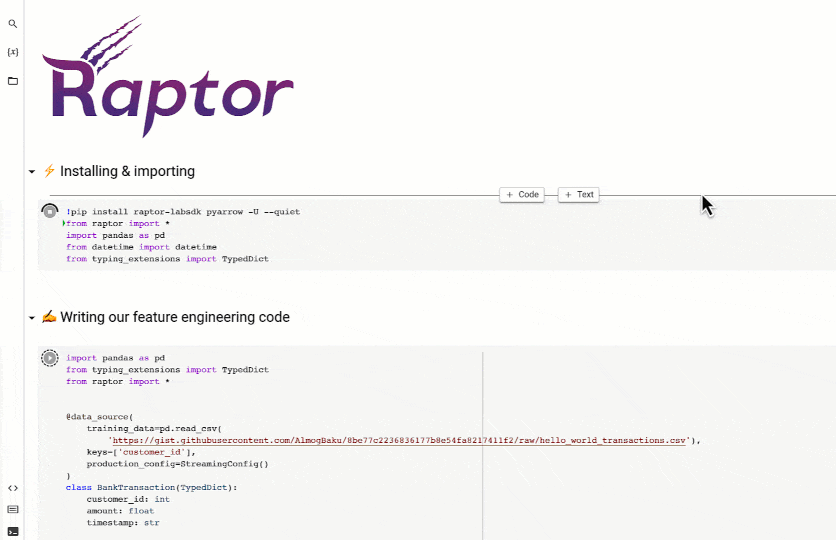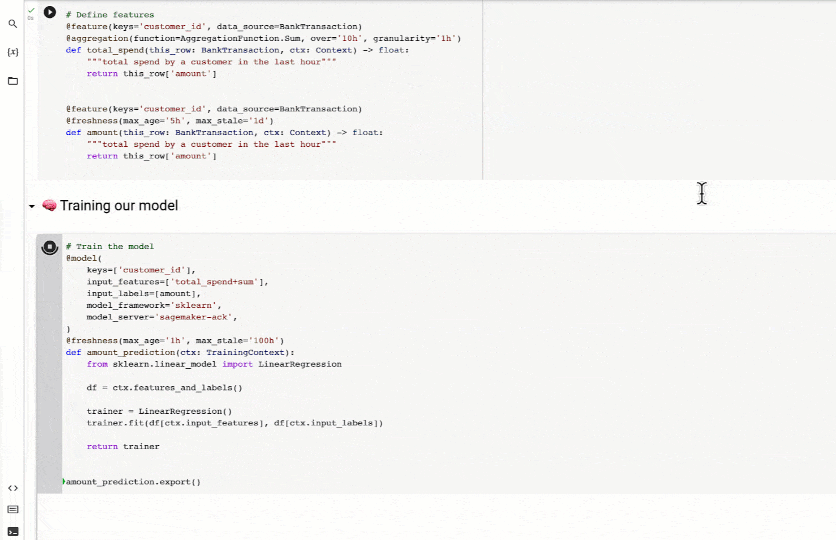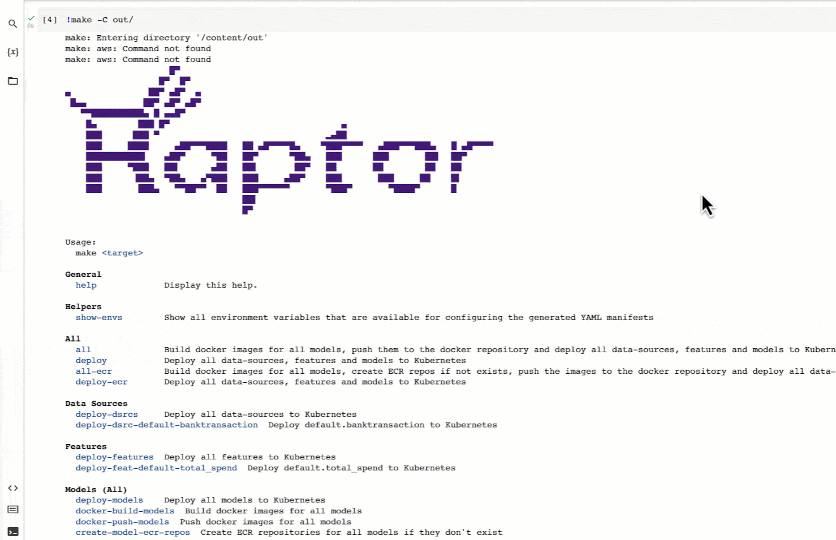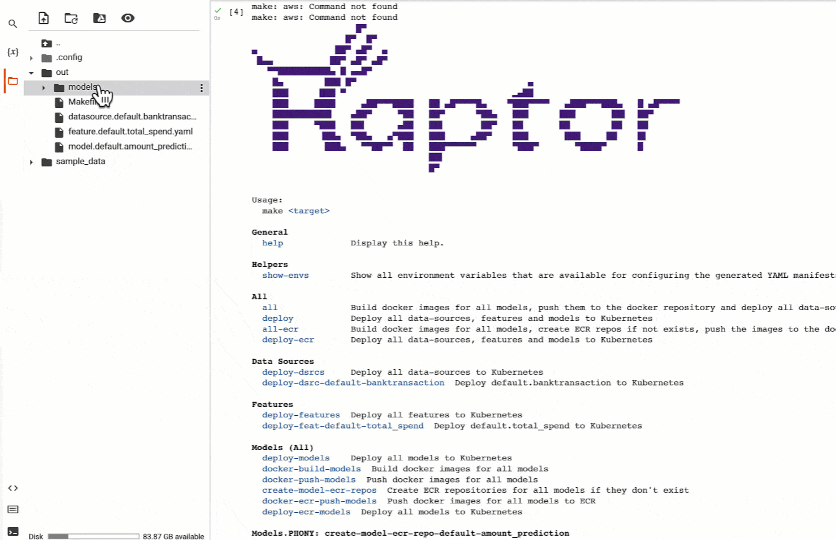
# 2. 피처 정의 (10시간 합계 집계)
@feature(keys='customer_id', data_source=BankTransaction)
@aggregation(function=AggregationFunction.Sum, over='10h', granularity='1h')
def total_spend(this_row: BankTransaction, ctx: Context) -> float:
"""total spend by a customer in the last hour"""
return this_row['amount']
# 3. 또 다른 피처 정의 (단순 값 반환)
@feature(keys='customer_id', data_source=BankTransaction)
@freshness(max_age='5h', max_stale='1d')
def amount(this_row: BankTransaction, ctx: Context) -> float:
"""total spend by a customer in the last hour"""
return this_row['amount']
# 4. 모델 정의 (sklearn, Sagemaker 서빙)
@model(
keys='customer_id',
input_features=['total_spend+sum'], # 2번 피처 사용
input_labels=[amount], # 3번 피처를 라벨로 사용
model_framework='sklearn',
model_server='sagemaker-ack',
)
@freshness(max_age='1h', max_stale='100h')
def amount_prediction(ctx: TrainingContext):
from sklearn.linear_model import LinearRegression
df = ctx.features_and_labels()
trainer = LinearRegression()
trainer.fit(df[ctx.input_features], df[ctx.input_labels])
return trainer
# 5. 프로덕션 아티팩트로 내보내기
amount_prediction.export()
위 코드의 마지막 줄 amount_prediction.export()가 실행되면, 현재 디렉터리의 out 폴더에 Kubernetes 배포에 필요한 YAML 파일 및 기타 아티팩트가 생성됩니다. 이 아티팩트에는 CI/CD 파이프라인에서 사용할 수 있는 Makefile도 포함되어 있습니다.
프로덕션 배포
pip install raptor-labsdk 명령어로 설치한 Raptor LabSDK는 로컬 개발 및 학습을 위한 패키지입니다. 실제 프로덕션(또는 스테이징) 환경에 배포하기 위해서는 Kubernetes 클러스터에 Raptor Core(서버 사이드 컴포넌트)를 설치해야 합니다.
프로덕션 환경을 위한 사전 요구 사항은 다음과 같습니다:
- Kubernetes 클러스터 (EKS, GKE 등)
- Redis 서버 (2.8.9 버전 이상)
- (선택 사항) Snowflake 또는 S3 버킷 (재학습을 위한 이력 데이터 저장용)
자세한 프로덕션 설치 방법은 RaptorML 공식 문서를 참고해주세요:
라이선스
RaptorML 프로젝트는 Apache-2.0 라이선스로 공개 및 배포되고 있습니다.
 RaptorML 공식 홈페이지
RaptorML 공식 홈페이지
 RaptorML 프로젝트 GitHub 저장소
RaptorML 프로젝트 GitHub 저장소
https://github.com/raptor-ml/raptor
 RaptorML 문서 사이트
RaptorML 문서 사이트
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()