
ReasoningBank 소개
에이전트 메모리의 현재와 한계
우리가 처음으로 매우 어려운 프로그래밍 과제를 마주했을 때를 떠올려 봅시다. 단순히 교과서에 나온 예제를 따라 하는 것만으로는 해결되지 않는 문제 앞에서, 우리는 여러 번 시도하고 실패하며 그 과정에서 얻은 작은 힌트들을 통해 점차 해결책에 다가갑니다. "아, 이 접근법은 메모리 오버플로우가 발생하니까 다음에는 피해야지"와 같은 실패에서의 교훈이 오히려 더 깊이 각인되는 경우가 많습니다. 그런데 현재의 AI 에이전트들은 이런 인간의 학습 방식과는 거리가 멉니다. 매번 새로운 작업을 마치 처음 보는 것처럼 접근하며, 과거의 경험에서 아무것도 배우지 못합니다.
최근 대규모 언어 모델(LLM) 기반 에이전트는 웹 탐색부터 소프트웨어 엔지니어링까지 복잡한 실세계 작업에서 점점 더 중요한 역할을 맡고 있습니다. GPT-4o, Claude, Gemini와 같은 최신 모델들이 에이전트의 추론 능력을 크게 향상시켰지만, 이들 에이전트가 지속적이고 장기적인 역할로 전환될수록 근본적인 한계가 드러납니다. 배포 이후 자신의 성공과 실패 경험을 분석하고 학습하는 능력이 현저히 부족하다는 것입니다. 메모리 메커니즘 없이 매번 새 작업에 접근하는 에이전트는 같은 전략적 실수를 반복하고, 이전에 얻은 귀중한 인사이트를 버리게 됩니다.
이 문제를 해결하기 위해 다양한 형태의 에이전트 메모리가 제안되었지만, 기존 접근법들은 두 가지 근본적인 한계를 가지고 있습니다.
첫 번째 접근법은 궤적 메모리(Trajectory Memory) 입니다. Synapse와 같은 시스템에서 사용하는 이 방식은 에이전트가 수행한 모든 행동을 상세히 기록합니다. "검색창을 클릭하고, '데이터셋'이라고 입력하고, 엔터 키를 누르고, 세 번째 결과를 클릭했다"와 같은 저수준의 행동 시퀀스를 그대로 저장하는 것입니다. 하지만 이 접근법은 마치 요리사가 "오른손으로 소금통을 집고, 왼쪽으로 3 cm 이동하여 냄비 위에서 손을 45 도 기울여 소금을 뿌렸다"고 기록하는 것과 같습니다. 지나치게 세밀한 행동 기록은 전이 가능한 고수준의 추론 패턴을 추출하는 데 실패합니다. 동일한 웹사이트에서도 UI가 바뀌면 궤적 전체가 무용지물이 되며, 다른 유형의 작업에 일반화할 수 없습니다.
두 번째 접근법은 워크플로우 메모리(Workflow Memory) 입니다. Agent Workflow Memory(AWM)에서 사용하는 이 방식은 성공한 시도에서 워크플로우를 요약하여 저장합니다. 궤적 메모리보다는 한 단계 더 추상화된 접근이지만, 성공 경험에만 지나치게 집중한다는 근본적 결함이 있습니다. 인간이 실패에서 가장 큰 교훈을 얻듯이, 에이전트 역시 실패 경험에서 "무엇을 하지 말아야 하는지"를 배울 수 있어야 합니다. 에이전트가 무한 스크롤 함정에 빠져 실패한 경험이 있다면, 이 실패에서 "페이지 식별자를 먼저 확인하라"는 예방적 교훈을 배울 수 있어야 하지만, 워크플로우 메모리는 이런 실패 사례를 아예 기록하지 않습니다.

정리하면, 궤적 메모리는 "너무 구체적이어서 일반화가 안 되는" 문제를, 워크플로우 메모리는 "성공만 기억하고 실패를 무시하는" 문제를 가지고 있습니다. 에이전트가 진정으로 경험에서 학습하려면, 이 두 가지 한계를 동시에 극복해야 합니다.
ReasoningBank의 핵심 아이디어: 경험에서 추론 전략을 증류하다
Google Research 팀은 ICLR 2026에 채택된 논문 "ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory"에서 이 두 가지 한계를 동시에 극복하는 새로운 에이전트 메모리 프레임워크인 ReasoningBank(GitHub 링크)를 제안합니다.
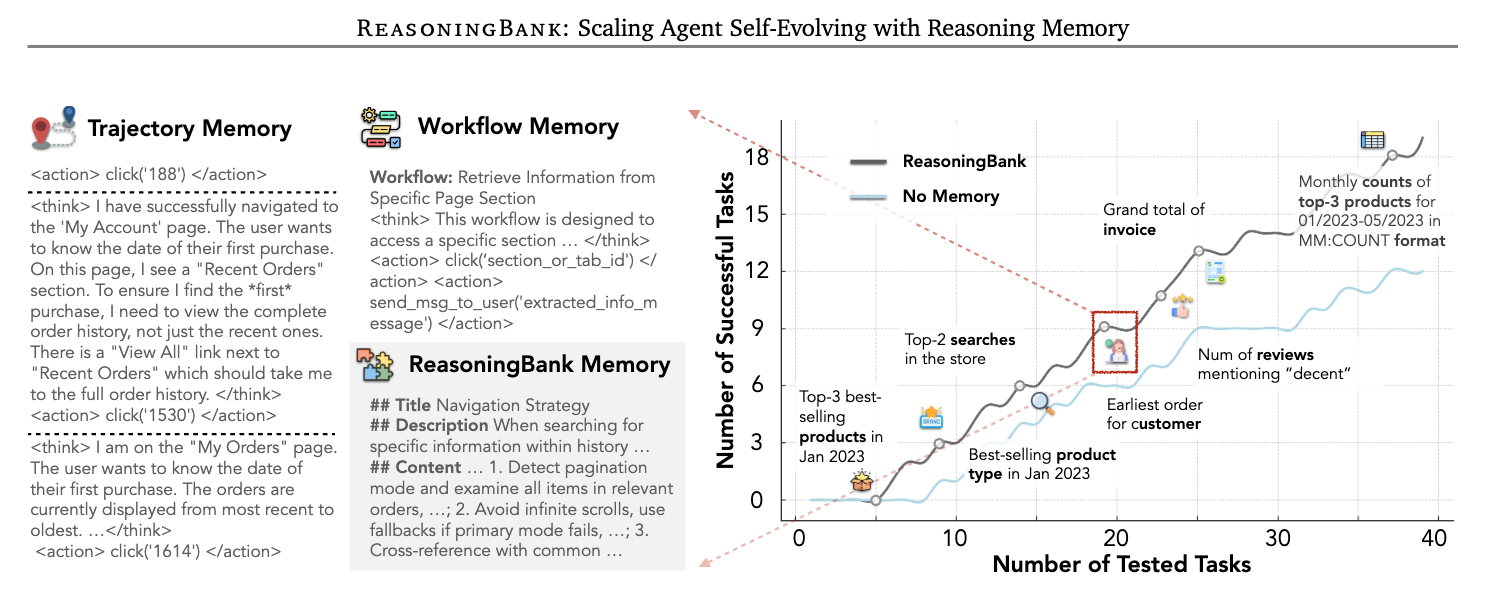
ReasoningBank의 핵심 발상 전환은 두 가지입니다: 첫째, 구체적인 행동 기록이나 성공 워크플로우가 아닌, 일반화 가능한 추론 전략(Reasoning Strategies)을 증류(Distill)하여 저장합니다. 이는 마치 숙련된 개발자가 "파일을 열고, 23번째 줄에서 변수명을 바꾸고, 저장했다"가 아니라 "타입 불일치 오류가 발생하면, 호출 체인을 역추적하여 최초 타입 변환 지점을 찾아라"와 같은 전략적 인사이트를 기억하는 것과 같습니다.
둘째, 성공 경험뿐 아니라 실패 경험에서도 적극적으로 교훈을 추출합니다. 마치 과학계가 선행 연구의 성공과 실패를 모두 인용하며 발전해 나가는 누적적 과학(cumulative science)의 과정을 AI 에이전트 세계에 구현한 것이라 할 수 있습니다.
나아가 연구팀은 메모리 인식 테스트 시점 스케일링(Memory-aware Test-Time Scaling, MaTTS) 이라는 개념을 도입하여, 메모리와 추론 시점 연산 확장 사이의 강력한 시너지를 만들어냅니다. 고품질 메모리가 더 효과적인 탐색을 이끌고, 확장된 탐색이 더 풍부한 학습 신호를 생성하여 메모리를 다시 향상시키는 선순환 구조를 형성합니다.
실험 결과, ReasoningBank는 웹 브라우징 벤치마크인 WebArena에서 메모리 없는 에이전트 대비 8.3\% 의 성공률 향상을, 소프트웨어 엔지니어링 벤치마크인 SWE-Bench-Verified에서 4.6\% 의 향상을 달성했습니다. 또한 작업당 실행 스텝 수도 크게 줄여, 에이전트의 효과성(effectiveness)과 효율성(efficiency)을 동시에 개선했습니다.
ReasoningBank 프레임워크
구조화된 메모리 아이템
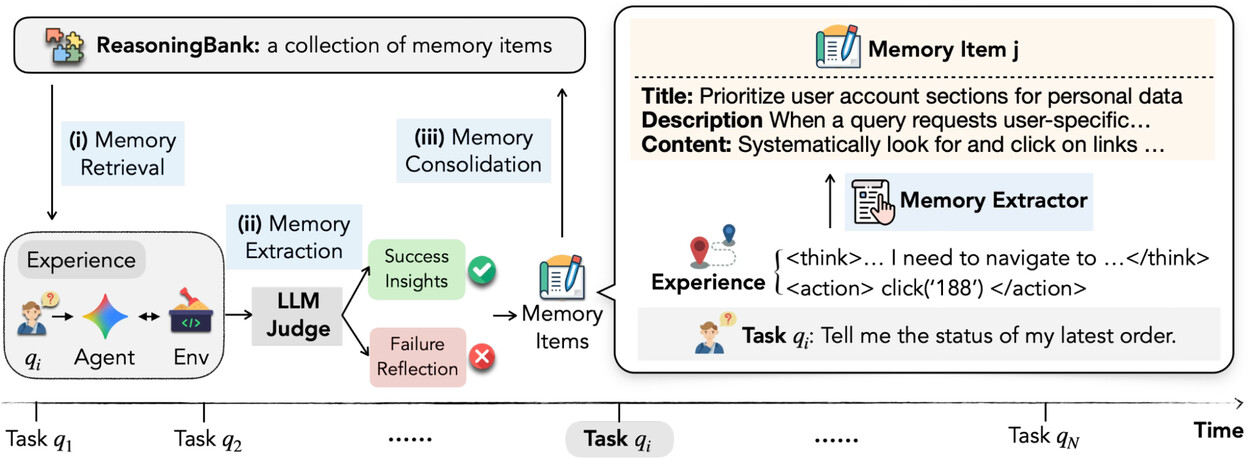
ReasoningBank는 에이전트의 경험에서 전역적 추론 패턴을 고수준의 구조화된 메모리로 증류합니다. 기존의 궤적 메모리가 원시 행동 시퀀스를 저장하고, 워크플로우 메모리가 성공 워크플로우만 기록하는 것과 달리, ReasoningBank는 각 메모리 아이템을 세 가지 명확한 구성 요소로 구조화합니다.
-
제목(Title): 핵심 전략을 요약하는 간결한 식별자. 예를 들어 "페이지네이션 탐지를 통한 데이터셋 필터링 전략"과 같은 제목입니다.
-
설명(Description): 메모리 아이템에 대한 짧은 요약. 검색 시 관련성 판단에 활용됩니다.
-
내용(Content): 과거 경험에서 추출한 증류된 추론 단계, 의사결정 근거, 또는 운영 인사이트. 이 부분이 에이전트가 실제로 활용하는 핵심 지식입니다.
이 구조화가 얼마나 중요한지는 세 가지 접근법을 직접 비교해 보면 명확해집니다. 동일한 실패 상황, "웹페이지에서 추가 데이터를 로드하려다가 페이지가 루프에 빠진 경우"에 대해 각 방식이 저장하는 내용은 다음과 같습니다.
-
궤적 메모리: "click('Load More'), observe(page_unchanged), click('Load More'), observe(page_unchanged), ..."와 같은 원시 행동 기록
-
워크플로우 메모리: 이 실패 사례를 아예 기록하지 않음 (성공만 저장)
-
ReasoningBank:
제목: 무한 스크롤 함정 회피 전략 / 내용: 더 많은 결과를 로드하기 전에, 현재 페이지 식별자(URL 파라미터, 페이지 번호)를 먼저 확인하라. 식별자가 변경되지 않으면 같은 페이지임을 의미하므로, 대신 필터나 검색어를 조정하라.
세 번째 표현만이 다음 번 유사한 상황에서 재사용 가능한 전략적 지식입니다. 추상화 수준이 높을수록 다양한 상황에 적용 가능한 전이성(transferability)이 높아집니다.
메모리 워크플로우: 검색, 추출, 통합의 폐쇄 루프
ReasoningBank의 메모리 워크플로우는 검색(Retrieval), 추출(Extraction), 통합(Consolidation)의 지속적인 폐쇄 루프(Closed-Loop)로 작동합니다. 이 과정은 에이전트가 작업을 수행할 때마다 반복되며, 경험이 쌓일수록 메모리의 품질이 점진적으로 향상됩니다. 마치 소프트웨어 개발에서의 CI/CD 파이프라인처럼, 매 실행 사이클에서 자동으로 피드백을 수집하고 시스템을 개선하는 구조입니다.
1단계: 검색
에이전트는 새로운 작업에 착수하기 전에 ReasoningBank에서 관련 메모리를 검색하여 자신의 컨텍스트에 포함시킵니다. 현재 작업의 특성에 맞는 메모리를 선택적으로 가져오기 때문에, 에이전트는 작업 시작 시점부터 이미 관련 경험의 혜택을 받게 됩니다. 이는 마치 신임 개발자가 코드리뷰를 받기 전에 팀의 코딩 컨벤션 문서와 이전에 발생했던 버그 패턴 목록을 먼저 참조하는 것과 같습니다. 아무것도 모른 채 작업하는 것보다, 선배들의 경험이 녹아든 지식을 미리 갖추고 시작하는 것이 훨씬 효율적입니다.
2단계: 실행 및 자체 평가
에이전트가 환경과 상호작용을 마친 뒤, LLM-as-a-judge 방식을 사용하여 자신의 궤적을 자체 평가합니다. 성공한 경우에는 "어떤 전략이 효과적이었는가"라는 성공 인사이트를, 실패한 경우에는 "어디서 잘못되었고 다음에는 어떻게 해야 하는가"라는 실패 반성(failure reflection)을 추출합니다.
흥미로운 점은, 이 자체 판단이 완벽하게 정확할 필요가 없다는 것입니다. 연구팀은 ReasoningBank가 판단 노이즈에 대해 상당히 강건(robust)하다는 것을 발견했습니다. 이는 메모리가 개별 판단의 정확성보다는 다수의 경험에서 반복적으로 나타나는 패턴에 의존하기 때문으로 해석됩니다. 한두 번의 잘못된 판단이 전체 메모리 품질에 미치는 영향은 제한적입니다. 예를 들어, 실제로는 성공한 전략을 실패로 잘못 판단한 경우, 그 전략은 다른 성공 사례들을 통해 결국 메모리에 올바르게 기록될 것입니다.
3단계: 추출 및 통합
에이전트는 궤적에서 워크플로우와 일반화 가능한 인사이트를 증류하여 새로운 메모리로 변환합니다. 이 과정에서 구체적인 행동 시퀀스가 아닌 전략적 수준의 패턴으로 추상화가 이루어집니다. 현재 구현에서는 새로 생성된 메모리를 단순히 ReasoningBank에 추가(append)하는 방식을 사용하며, 더 정교한 통합 전략(중복 병합, 갈등 해결 등)은 향후 연구로 남겨두고 있습니다.
실패 경험으로부터의 학습: 반사실적 교훈
ReasoningBank가 기존 접근법과 가장 크게 차별화되는 지점은 바로 실패 경험의 적극적 활용입니다. 기존의 워크플로우 메모리 전략이 성공한 실행에서만 학습하는 것은, 마치 학생이 정답만 외우고 오답 노트를 작성하지 않는 것과 같습니다. 시험에서 같은 실수를 반복할 확률이 높아집니다.
ReasoningBank는 실패한 경험을 적극적으로 분석하여 반사실적 신호(counterfactual signals)와 함정(pitfalls)을 추출합니다. "만약 이 시점에서 다른 선택을 했다면 어떻게 되었을까?"라는 반사실적 사고를 통해, 실패의 원인을 구조적으로 파악하고 이를 예방적 교훈으로 변환합니다.
이러한 실수들을 예방적 교훈으로 증류함으로써, ReasoningBank는 강력한 전략적 가드레일(strategic guardrails) 을 구축합니다. 이는 마치 체스 선수가 과거의 패배에서 "이런 상황에서는 절대 이 수를 두면 안 된다"는 교훈을 배우거나, 경험 많은 시스템 관리자가 과거 장애에서 "이 설정을 변경하기 전에 반드시 백업을 먼저 해야 한다"는 운영 규칙을 체화하는 것과 같습니다. 성공에서 배우는 "무엇을 해야 하는가"만큼이나, 실패에서 배우는 "무엇을 하지 말아야 하는가"가 에이전트의 성능 향상에 핵심적으로 기여합니다.
메모리 인식 테스트 시점 스케일링 (MaTTS)
테스트 시점 스케일링과 에이전트 메모리의 연결
테스트 시점 스케일링(Test-Time Scaling, TTS), 즉 추론 시점에서 연산을 확장하는 방식은 수학이나 경쟁 프로그래밍과 같은 추론 영역에서 놀라운 효과를 보여주었습니다. 더 많은 연산을 투입할수록 더 나은 답변을 생성할 수 있다는 것이 핵심 아이디어입니다.
하지만 에이전트 환경에서 기존 TTS 방법들은 심각한 비효율을 안고 있습니다. 에이전트가 여러 번 시도하는 과정에서 생성되는 탐색 궤적을 모두 버리고, 최종 답변만을 유용한 결과물로 취급합니다. 이는 마치 과학자가 100 번의 실험을 수행했는데, 최종 성공 실험의 결과만 기록하고 나머지 99 번의 시행착오에서 얻은 모든 관찰과 교훈을 폐기하는 것과 같습니다. 이 간과된 탐색 과정이 사실은 에이전트의 경험 학습을 가속화할 수 있는 풍부한 데이터 소스입니다.
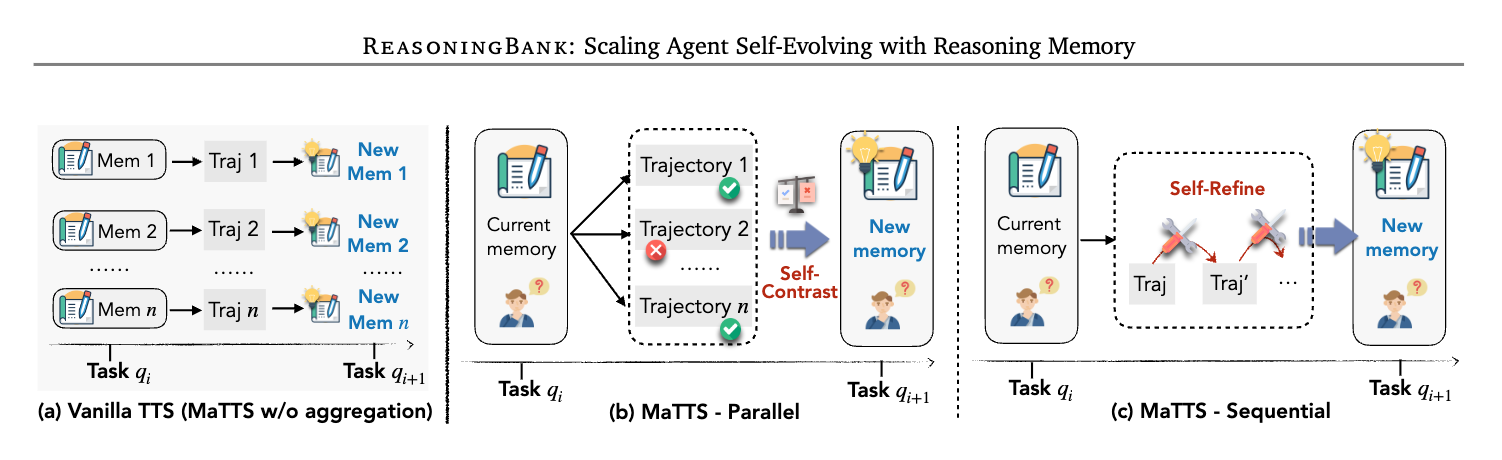
연구팀은 이 격차를 메우기 위해 메모리 인식 테스트 시점 스케일링(MaTTS) 을 제안합니다. ReasoningBank를 강력한 경험 학습기로 활용하여, 확장된 탐색에서 대비적(contrastive) 신호와 개선(refinement) 신호를 통해 고품질 메모리를 증류합니다. MaTTS는 두 가지 형태의 스케일링을 제공합니다.
병렬 스케일링 (Parallel Scaling)
병렬 스케일링에서 에이전트는 메모리의 안내 아래 동일한 쿼리에 대해 여러 개의 서로 다른 궤적을 생성합니다. 스케일링 팩터 k=5 라면, 같은 작업에 대해 5 개의 독립적인 시도가 병렬로 수행됩니다. 이후 자체 대비(self-contrast)를 통해 ReasoningBank는 성공한 궤적과 잘못된 추론을 보인 궤적을 비교하여 더 강건한 전략을 증류하고 더 높은 품질의 메모리를 합성합니다.
이는 마치 과학 실험에서 대조군과 실험군을 비교하여 핵심 변인을 파악하는 과정과 유사합니다. 5 개의 시도 중 3 개가 성공하고 2 개가 실패했다면, "성공한 3 개에서는 공통으로 나타나지만 실패한 2 개에서는 빠진 전략이 무엇인가?"를 분석함으로써, 단순히 "이렇게 하면 된다"를 넘어 "이 전략이 성공의 결정적 요인이다"라는 깊이 있는 인사이트를 추출할 수 있습니다. 병렬로 생성된 다양한 시도들이 서로 대비적 학습 신호로 작용하여, 단일 시도에서는 얻기 어려운 구별적 특징(discriminative features)을 포착하게 됩니다.
순차 스케일링 (Sequential Scaling)
순차 스케일링에서 에이전트는 단일 궤적 내에서 추론을 반복적으로 개선(refine)하여 강력한 중간 근거(intermediate rationale)를 생성합니다. 각 시도의 결과를 바탕으로 점진적으로 전략을 개선해 나가는 과정이며, ReasoningBank는 에이전트의 시행착오와 점진적 개선 과정에서 얻어지는 이러한 중간 인사이트를 고품질 메모리 아이템으로 포착합니다.
이는 프로그래밍에서 디버깅 과정과 유사합니다. 한 번에 완벽한 코드를 작성하는 것이 아니라, 오류를 발견하고, 수정하고, 다시 실행하는 반복적 과정에서 "이 상황에서는 이 패턴을 먼저 확인해야 한다"는 깊이 있는 인사이트를 얻게 됩니다. 순차 스케일링은 이 반복적 개선 과정 자체를 학습 데이터로 활용합니다.
병렬 스케일링이 "여러 경로를 동시에 탐색하여 비교"하는 방식이라면, 순차 스케일링은 "하나의 경로를 깊이 탐구하며 개선"하는 방식입니다. 두 방식은 서로 다른 유형의 학습 신호를 제공하며, 작업의 성격과 가용 연산 자원에 따라 적절히 선택할 수 있습니다.
메모리와 스케일링의 선순환
MaTTS의 진정한 힘은 메모리와 테스트 시점 스케일링 사이에 확립되는 강력한 선순환(virtuous cycle)에 있습니다. 이 시너지는 양방향으로 작동합니다.
메모리 → 스케일링 방향: ReasoningBank에서 나온 고품질 메모리가 확장된 탐색을 더 유망한 전략 방향으로 이끕니다. 메모리 없이 맹목적으로 탐색하는 것보다, 과거 경험에 기반한 가이드가 있으면 같은 연산량으로도 훨씬 더 생산적인 탐색이 가능합니다.
스케일링 → 메모리 방향: 확장된 상호작용은 훨씬 더 풍부한 학습 신호를 생성합니다. 더 많은 시도가 더 다양한 성공과 실패 사례를 만들어내고, 이것이 더 정교한 대비적 분석을 가능하게 하여 더 높은 품질의 메모리로 이어집니다.
이러한 양방향 강화 구조가 반복될수록, 에이전트는 점점 더 똑똑해지는 경험 기반 자기 진화(self-evolution)를 달성하게 됩니다. 단순히 "같은 문제를 반복적으로 풀어 성능을 올린다"는 좁은 의미의 파인튜닝이 아니라, 새로운 유형의 문제에도 적용되는 일반화된 전략적 지식이 쌓인다는 점에서 근본적으로 다릅니다.
실험 결과 및 성능 분석
실험 설정
연구팀은 동적 환경을 다루는 두 가지 도전적인 벤치마크에서 ReasoningBank를 평가했습니다. 모든 에이전트의 기반으로 ReAct 프롬프팅 전략을 사용했으며, 세 가지 메모리 구성과 비교했습니다.
- Vanilla ReAct: 메모리를 사용하지 않는 기본 에이전트
- Synapse : 궤적 메모리(Trajectory Memory) 방식으로, 에이전트의 모든 행동을 상세히 기록하여 재사용
- AWM : 워크플로우 메모리(Workflow Memory) 방식으로, 성공한 작업의 워크플로우만 요약하여 저장
평가 모델로는 Gemini-2.5-Flash를 사용했으며, 두 가지 벤치마크에서 성능을 측정했습니다.
WebArena는 Reddit, GitLab, 온라인 쇼핑몰 등 실제 웹사이트 환경에서 에이전트가 다양한 웹 탐색 작업을 수행하는 벤치마크입니다. 페이지 탐색, 양식 작성, 검색, 정보 추출 등 실세계 웹 에이전트에게 요구되는 폭넓은 능력을 평가합니다.
SWE-Bench-Verified는 실제 오픈소스 프로젝트의 GitHub 이슈를 해결하는 소프트웨어 엔지니어링 벤치마크입니다. 에이전트가 코드베이스를 탐색하고, 문제를 파악하고, 패치를 생성하여 테스트를 통과시켜야 합니다.
주요 실험 결과
성공률 향상: 스케일링 없이 ReasoningBank만 적용했을 때, WebArena에서 메모리 없는 에이전트 대비 8.3\% 의 성공률 향상을, SWE-Bench-Verified에서 4.6\% 의 향상을 달성했습니다. 이는 궤적 메모리(Synapse)와 워크플로우 메모리(AWM)를 모두 일관되게 능가하는 수치입니다. 특히 주목할 점은, ReasoningBank가 성격이 매우 다른 두 벤치마크 모두에서 최고 성능을 기록했다는 것입니다. 웹 탐색(자유로운 UI 탐색 위주)과 소프트웨어 엔지니어링(코드 이해 및 수정 위주)은 요구하는 전략이 전혀 다름에도 불구하고, ReasoningBank의 추론 전략 증류 방식이 두 도메인 모두에서 유효하게 작동했습니다.
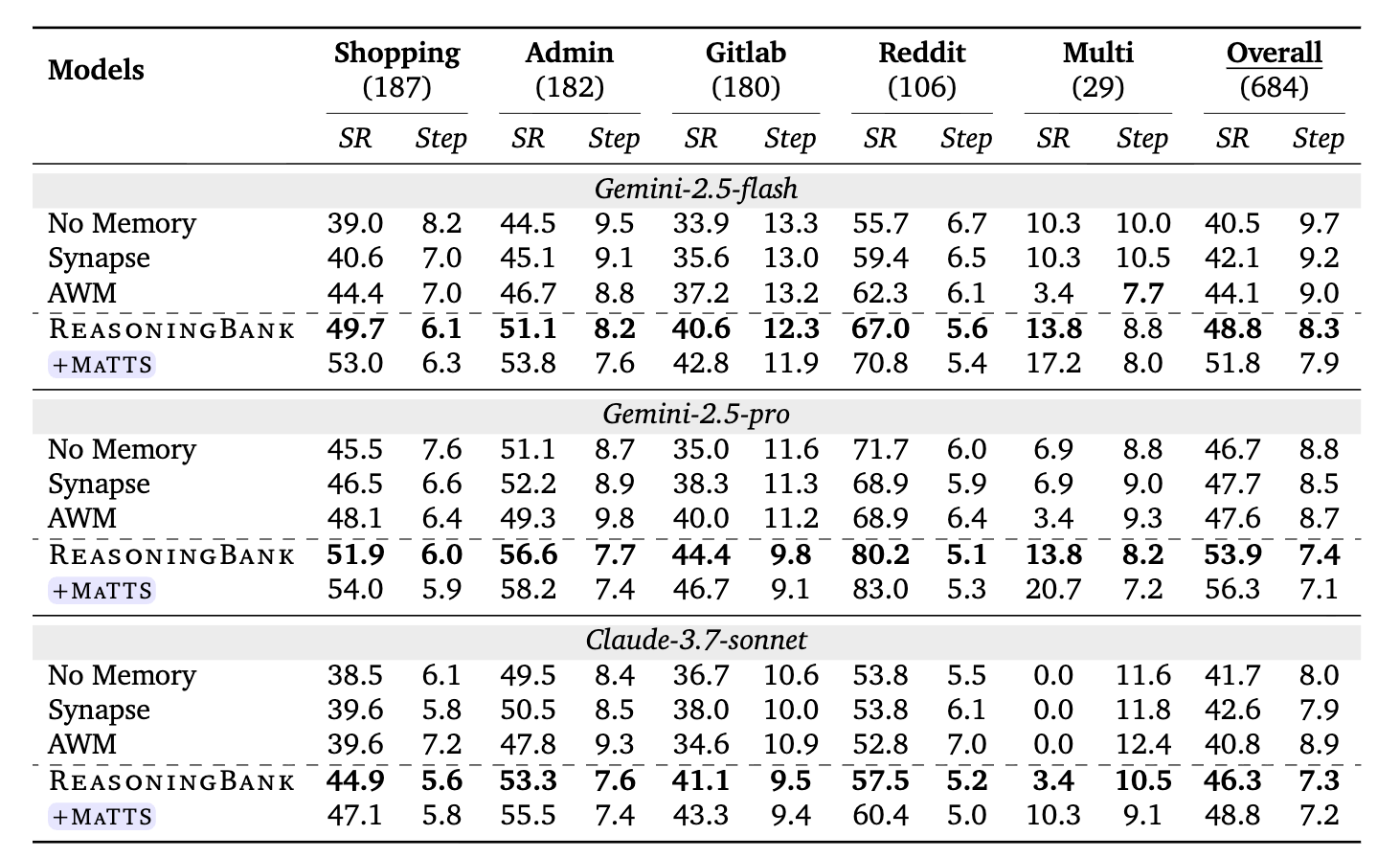
효율성 개선: 에이전트가 과거의 의사결정 근거에 적극적으로 접근하기 때문에, 목적 없는 탐색이 크게 줄어들었습니다. SWE-Bench-Verified에서 ReasoningBank는 메모리 없는 기본 에이전트 대비 작업당 거의 3 스텝을 절약했습니다. 이는 단순히 "더 정확하게"가 아니라 "더 효율적으로"도 작업을 수행한다는 것을 의미합니다. 실제 배포 환경에서 스텝 수 감소는 API 호출 비용 절감과 응답 시간 단축으로 직결되므로, 실용적 가치가 매우 큽니다.
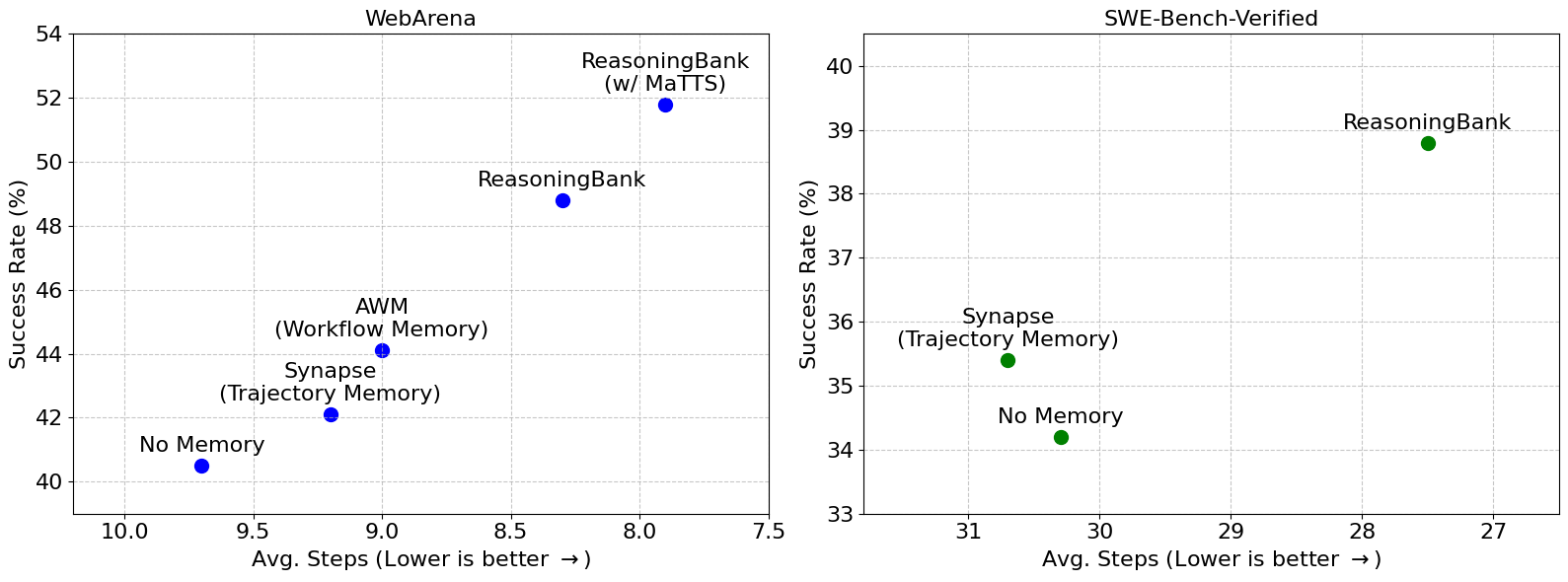
MaTTS 시너지 효과: MaTTS(스케일링 팩터 k=5 의 병렬 스케일링)를 추가하면 성능이 더욱 향상됩니다. WebArena에서 ReasoningBank 단독 대비 3\% 의 추가 성공률 향상과 작업당 0.4 스텝 절약을 달성했습니다. 메모리 없이 단순히 시도 횟수만 늘리는 기존 TTS와 달리, ReasoningBank와 결합된 MaTTS는 각 시도에서의 교훈을 체계적으로 축적하여 탐색 효율 자체를 높입니다.
전략적 성숙도의 창발
하지만 "왜 이 방법이 작동하는가?"와 "단순한 수치 향상 너머에 어떤 질적 변화가 일어나는가?"에 대해서도 궁금하실 것입니다. 연구팀은 평가 과정에서 매우 흥미로운 전략적 성숙도(strategic maturity) 의 창발 현상을 관찰했습니다.
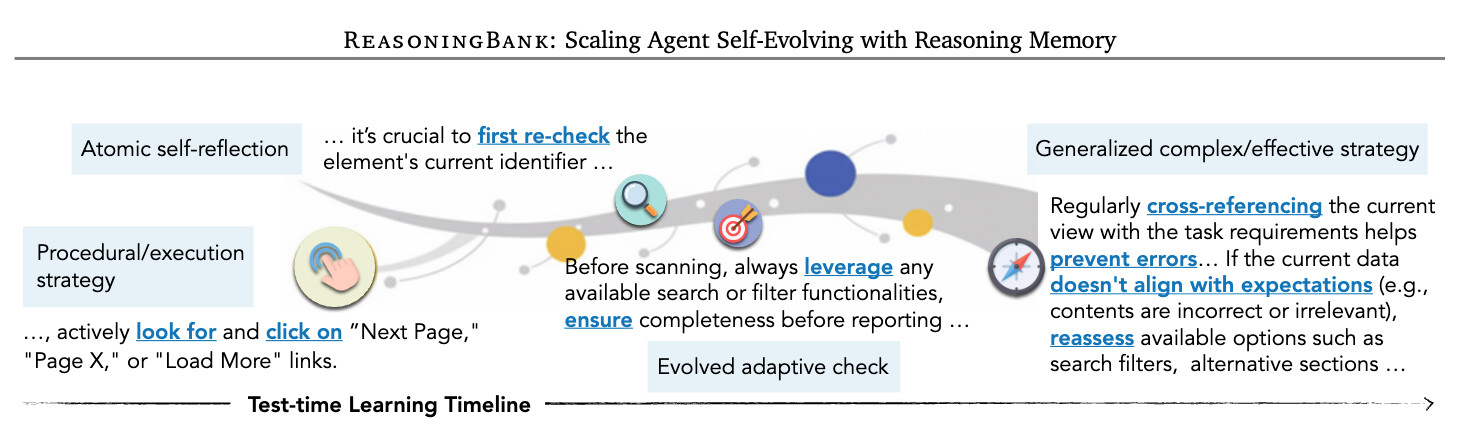
웹 브라우징 실험에서 에이전트의 초기 메모리는 "페이지 링크를 찾아라"와 같은 단순한 절차적 체크리스트에 불과했습니다. 이는 마치 프로그래밍을 배우기 시작한 초보자가 "에러가 나면 스택 트레이스를 읽어라"라는 단순한 규칙을 따르는 것과 유사합니다.
하지만 에이전트가 더 많은 문제를 풀어나가면서, 기존 메모리가 실행 과정에서 활용되고, 그 위에 새로운 궤적에서의 인사이트가 증류되며 메모리가 점차 진화했습니다. 시간이 지나면서, 단순한 체크리스트는 "검색된 데이터셋이 조기에 페이지 분할되지 않도록, 활성 페이지 필터와 작업을 지속적으로 교차 검증하라"와 같은 조합적(compositional)이고 예방적(preventative)인 논리 구조 를 가진 메모리로 발전했습니다.
이러한 자발적인 전략 고도화는 별도의 훈련이나 명시적 지시 없이, ReasoningBank의 경험 증류 메커니즘을 통해 자연스럽게 나타난 창발적 현상입니다. 에이전트가 경험을 누적하면서 스스로 더 정교한 전략을 발전시킨다는 것은, 진정한 의미의 "경험으로부터의 학습"이 이루어지고 있음을 시사합니다.
(전략적 성숙도의 구체적인 진화 과정과 추가 분석은 논문을 참고해주세요)
ReasoningBank 설치 및 사용 방법
ReasoningBank는 WebArena(웹 브라우징)와 SWE-Bench(소프트웨어 엔지니어링) 두 가지 환경에 대한 코드를 GitHub 저장소를 통해 공개하고 있으며, GPT, Gemini, Claude 세 가지 모델 패밀리를 지원합니다.
먼저 저장소를 복제하고 필요한 패키지를 설치합니다.
git clone https://github.com/google-research/reasoning-bank
cd reasoning-bank
pip install -r requirements.txt
모델 설정: 사용할 모델에 따라 환경변수를 설정합니다.
GPT 모델(gpt-4o 등)을 사용하는 경우:
export OPENAI_API_KEY="your-openai-api-key"
Gemini 또는 Claude 모델을 Vertex AI를 통해 사용하는 경우:
gcloud auth application-default login
export GOOGLE_CLOUD_PROJECT="your-project-id"
export GOOGLE_CLOUD_LOCATION="your-region"
export GOOGLE_GENAI_USE_VERTEXAI="True"
WebArena 실행: Docker 기반 WebArena 환경을 설정한 뒤 run.sh를 실행합니다. model, output_dir, website, memory_mode 파라미터를 상황에 맞게 지정합니다.
# PYTHONPATH에 vendored webarena 추가
export PYTHONPATH="$(pwd)/third_party:$PYTHONPATH"
# ReasoningBank 메모리 모드로 실행
bash WebArena/run.sh
MaTTS 스케일링을 적용하려면 pipeline_scaling.py와 induce_scaling.py를 참고하면 됩니다.
SWE-Bench 실행: mini-swe-agent 기반으로 구현되어 있으며, 먼저 소스에서 설치합니다.
pip install -e ./third_party
bash SWE-Bench/run.sh
평가는 sb-cli 명령을 사용하며, 공식 문서에 상세한 절차가 안내되어 있습니다.
ReasoningBank 기법의 한계점 및 향후 전망
현재 ReasoningBank는 몇 가지 한계점을 가지고 있으며, 이는 향후 연구의 방향을 제시합니다:
첫째, 메모리 통합 전략의 단순성 입니다. 현재는 새로 생성된 메모리를 단순히 기존 메모리에 추가하는 방식을 사용합니다. 경험이 누적됨에 따라 메모리의 양이 선형적으로 증가하면, 검색 효율성이 저하되거나 중복 및 상충되는 메모리가 쌓일 수 있습니다. 중복 메모리의 병합, 오래된 메모리의 갱신이나 만료, 상충하는 메모리 간의 갈등 해결 등 더 정교한 통합 전략이 필요합니다.
둘째, 모델 일반화의 검증 범위 입니다. 현재 주요 평가는 Gemini-2.5-Flash 모델에 초점이 맞추어져 있습니다. 다양한 규모와 아키텍처의 모델에서 ReasoningBank가 동일하게 효과적인지에 대해서는 추가 검증이 필요합니다. 코드는 GPT, Gemini, Claude를 모두 지원하지만, 논문의 주요 실험은 Gemini-2.5-Flash를 중심으로 수행되었습니다.
셋째, 스케일링 비용 대비 효율 입니다. MaTTS의 스케일링 팩터(k 값) 선택에 따른 연산 비용과 성능 향상 사이의 트레이드오프는 실용적 관점에서 중요한 고려 사항입니다. k=5 에서 3\% 의 추가 성능 향상을 얻었지만, 이를 위해 약 5 배의 추가 연산이 필요합니다. 최적의 k 값은 작업의 복잡도와 가용 연산 자원에 따라 달라질 것입니다.
결론적으로, ReasoningBank는 LLM 에이전트가 배포 이후에도 경험으로부터 지속적으로 학습하고 자기 진화할 수 있는 프레임워크를 제시합니다. 연구팀이 "메모리 기반 경험 스케일링(memory-driven experience scaling)"이라 명명한 이 새로운 스케일링 차원은, 기존의 모델 크기 확장(파라미터 스케일링)이나 학습 데이터 확장(데이터 스케일링)과는 다른 방향에서 에이전트 성능 향상의 가능성을 열어줍니다. 특히 전략적 성숙도의 자연스러운 창발은, 충분한 경험과 적절한 메모리 메커니즘이 갖추어지면 에이전트가 스스로 더 높은 수준의 추론 능력을 발전시킬 수 있음을 시사하는 중요한 이정표입니다.
 ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory 논문
ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory 논문
ReasoningBank: Enabling agents to learn from experience 소개 블로그
 ReasoningBank GitHub 저장소
ReasoningBank GitHub 저장소
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()