
ReCode (Recursive Code Generation) 소개
실제 세계에서의 문제 해결은 단일 수준의 의사결정으로 구성되어 있지 않습니다. 우리는 높은 수준의 전략적 계획부터 구체적인 행동 단계에 이르기까지 다양한 입자 수준(granularity)의 사고를 유기적으로 연결하며 문제를 해결합니다. 예를 들어, “점심을 준비하자”라는 계획은 “재료를 꺼내고”, “재료를 썰고”, “요리를 하자”와 같은 세부 계획을 거쳐, 결국 “칼을 들어”, “냉장고 문을 열고”, “프라이팬을 켠다”는 식의 구체적인 행동으로 이어집니다. 이러한 과정은 사람이 자연스럽게 수행하는 반면, 기존의 AI 시스템, 특히 LLM 기반의 에이전트는 이처럼 고수준의 계획(Planning) 과 저수준의 실행(Action) 수준의 추론을 자유롭게 넘나드는 데 한계가 있었습니다.
기존의 많은 대규모 언어 모델(LLM) 기반의 AI 에이전트(Agent) 구조는 대개 고수준 계획을 수립하는 플래너(Planner)와 저수준의 행동을 실행하는 실행기(Executor)를 엄격하게 분리하거나, 단순한 행동 반복 기반의 체계로 구성돼 있었습니다. 즉, “계획 → 실행” 혹은 “실행만”의 루프를 별도로 설계해 두는 경우가 많습니다. 이 경우, 환경 변화에 따른 적응성이 떨어지고, 일반화 능력 또한 제한되는 문제가 발생합니다. 특히 새로운 과제나 복잡한 태스크가 주어졌을 때, 에이전트는 “계획”만 하거나 “행동”만 하면서 진정한 문제 해결 능력을 보여주지 못하는 경우가 많습니다.
ReCode(Recursive Code Generation) 는 이러한 한계를 극복하기 위해 제안된 AI 에이전트 설계 패러다임입니다. ReCode는 기존의 이분법적인 계획/실행 체계를 넘어, 하나의 일관된 코드 표현 내에서 계획과 행동을 통합하여 표현합니다. 구체적으로, 고수준의 계획은 추상적인 ‘함수 호출’ 형태로 나타내고, 이를 재귀적으로 더 구체적인 하위 함수 또는 원시 행동 호출로 확장해 나가는 방식입니다. 이 구조 덕분에 ReCode는 다양한 의사 결정의 수준(Granularity)을 자유롭게 다루며, 필요에 따라 추상적 사고와 구체적 실행 사이를 유연하게 전환할 수 있습니다.
ReCode의 중요한 특징은 그 자체로 계층적 추론 데이터를 생성할 수 있는 구조적 학습 방식을 내포하고 있다는 점입니다. 에이전트가 계획을 세우고 행동을 생성하는 과정은 일종의 프로그램 트리를 형성하며, 이는 학습 데이터로 활용되어 향후 더 효율적인 모델 학습을 가능하게 합니다. 실험 결과, 이 방식은 단순히 계획과 실행을 통합하는 것 이상의 효과를 보여주며, 성능 향상과 데이터 효율성 면에서도 기존 방식들을 뛰어넘는 결과를 보여줍니다.
주요 개념: 에이전트(Agent)와 환경(Environment)
일반적으로 인공지능 에이전트(Agent)는 어떤 환경(Environment) 안에서 관찰(Observation)을 받고, 행동(Action)을 하며 상태(State)가 바뀌고, 보상(Reward)을 얻거나 목표(Goal)를 달성하려고 합니다. 에이전트 설계에서는 보통 다음과 같은 구성요소가 있습니다: 상태 공간 S, 행동 공간 A, 관찰 공간 O, 전이 함수 T (상태 × 행동 → 다음 상태) 및 보상 함수 R.
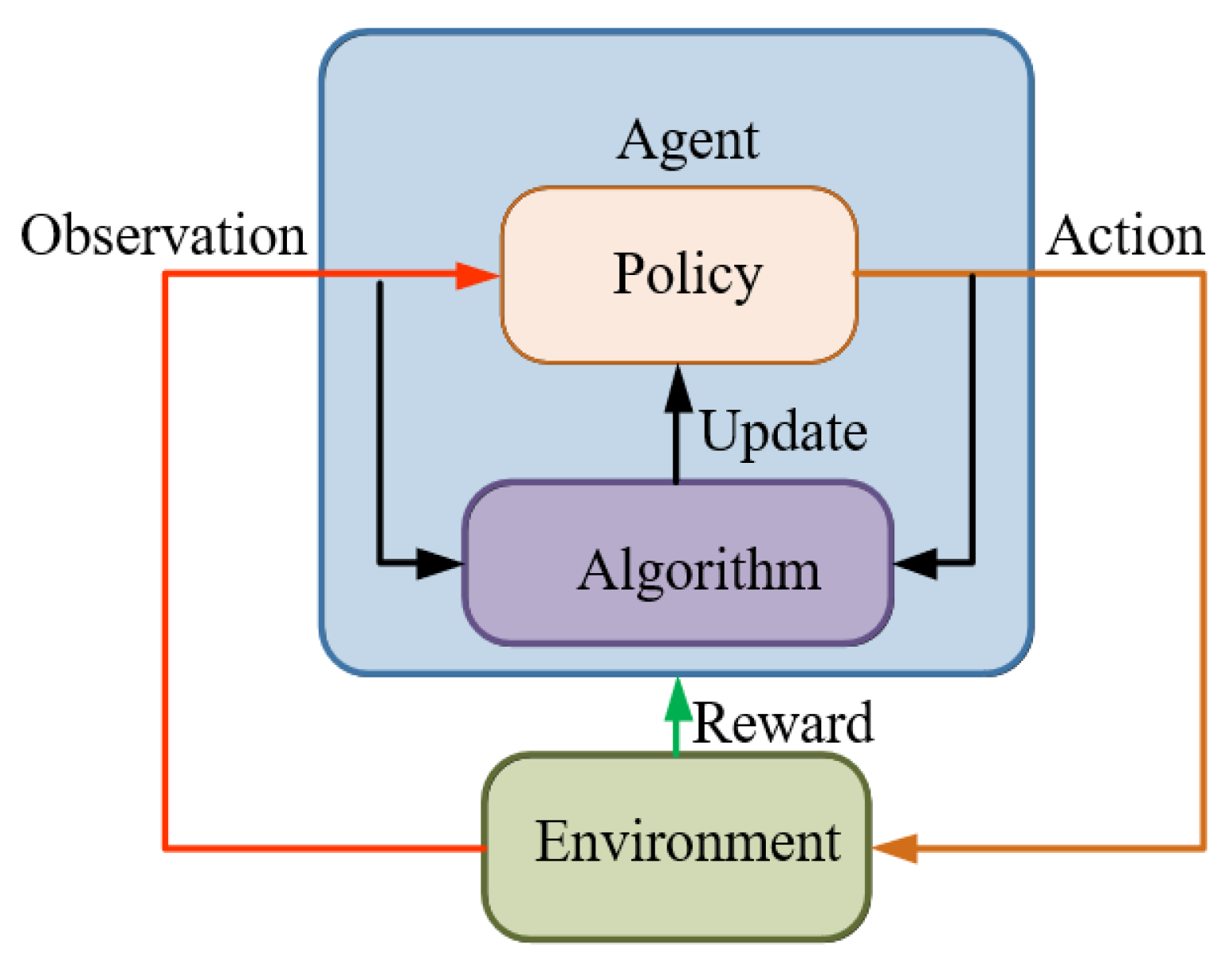
예컨대 로봇이 집 안에서 컵을 옮기는 과제라면, 상태는 현재 컵과 로봇 팔 등의 정보, 행동은 “팔을 움직인다”, “집는다” 등이 될 수 있고, 관찰은 센서로 받은 정보 등이 될 수 있습니다.
주요 개념: 결정(Decision) 수준 (Granularity)
이번 연구에서 핵심으로 삼는 개념 중 하나는 결정 수준(decision granularity), 즉 “어떤 수준(level)에서 결정을 내릴 것인가?”입니다.
-
매우 미세한 수준(fine-grained)에서는, 한 걸음 한 걸음의 원시 행동(primitive action)을 생각합니다. 예컨대 “컵을 집는다”, “팔을 펴고”, “손을 쥐고” 등이 여기에 해당할 수 있습니다.
-
반면 매우 거시적인 수준(coarse-grained)에서는, “책상 위의 컵을 옮긴다”처럼 비교적 높은 수준의 계획(plan)을 생각할 수 있습니다.사람은 이러한 여러 수준 사이를 자연스럽게 오가며 행동하는데, 현재 많은 대형 언어모델(LLM, Large Language Model) 기반 에이전트들은 고정된 수준(예: 행동만, 또는 계획만)에서 머무르는 경우가 많다는 것이 문제로 지적됩니다. 즉, “지금 어떤 수준으로 결정을 내려야 할까?”를 유연하게 바꿀 수 있어야 복잡한 작업에서 유리하다는 것이 이 논문의 출발점입니다.
주요 개념: 계획(Planning) vs 행동(Action)
전통적인 에이전트 설계에서는 보통 “계획” 단계와 “실행” 단계(즉 행동)로 역할이 나뉘어 있습니다. 예컨대 먼저 계획 모듈(planner)이 “컵을 옮긴다”라는 큰 목표를 세우고, 실행 모듈(executor)이 그 계획을 실제 행동으로 바꾸는 구조입니다.
그런데 이 구조에는 다음과 같은 한계가 있습니다:
- 계획과 행동이 별개 모듈로 나뉘어 있으므로, 중간 수준의 계획이 필요할 때 유연하게 개입하기 어렵습니다.
- 행동 수준만으로 모든 결정을 하려면 전략적 관점이 부족할 수 있고, 계획 수준만으로 행동을 수행하면 세부 사항이 빠질 수 있습니다.
이 연구(ReCode)에서는 “계획은 결국 높은 수준의 행동이다(“A plan is simply a higher-level action”)”라는 인식 하에 이 둘을 통합하려고 합니다.
ReAct 및 계획 중심 에이전트(Agent w/ Planner)와의 차이
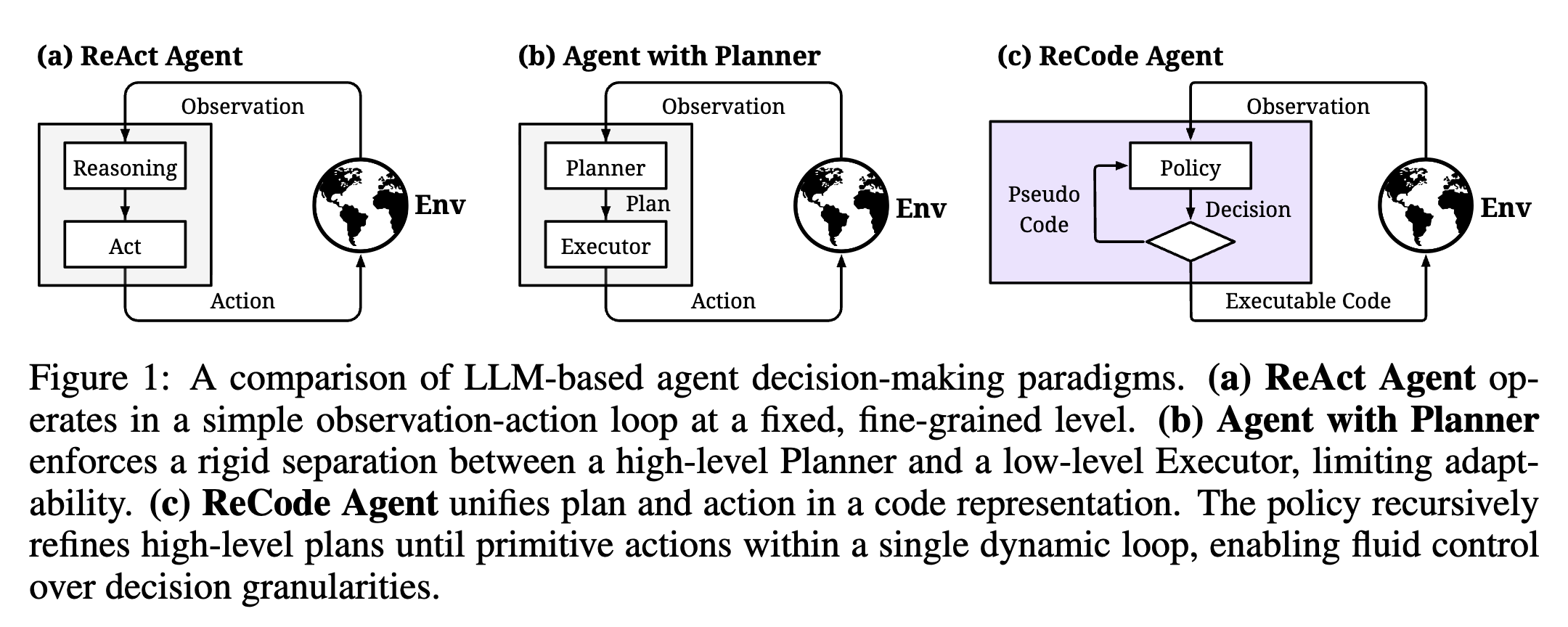
ReCode를 이해하기 위해서는 먼저 기존의 LLM 에이전트 방식이 어떻게 동작했는지를 살펴볼 필요가 있습니다. 먼저 ReAct와 같은 프레임워크는 사용자로부터 입력을 받아 ’생각(thought)’이라는 중간 단계를 거친 뒤, 바로 행동(action)을 수행하고, 이를 반복하는 구조로 설계되어 있습니다. 이러한 구조는 단순하고 구현이 쉬운 장점이 있지만, 추론 과정이 지나치게 단편적이며, 복잡한 목표를 장기적으로 수행하기 위한 전략적인 사고 능력이 부족합니다.
반면, 계획 중심의 에이전트(Agent with Planner) 는 높은 수준에서 전체 태스크를 먼저 계획한 뒤, 이후 각 단계를 실행에 옮기는 방식을 사용합니다. 이러한 구조는 체계적이지만, 계획과 실행의 경계가 고정되어 있어 실제 환경에서 요구되는 동적 적응성이 부족합니다. 특히 계획이 잘못되었거나 환경이 변화하였을 때, 기존 계획을 유연하게 수정하거나 재조정하는 능력이 부족하다는 단점이 있습니다.
ReCode는 이러한 한계를 해결하고자 계획과 실행을 분리하지 않고 하나의 코드 구조 내에서 통합적으로 표현하는 새로운 패러다임을 제안합니다. 고수준 계획은 단순한 자연어 문장이 아닌, 추상적인 함수(예: prepare_lunch())로 표현되며, 이 함수는 내부적으로 더 세분화된 하위 함수들(예: take_ingredients(), cut_vegetables(), heat_pan())로 재귀적으로 분해됩니다. 최종적으로는 실제 환경에서 작동 가능한 원시 행동(primitive action, 예: run("crack egg"))에 도달하게 되며, 이는 실제 코드 실행 환경에서 수행됩니다.
이러한 방식은 기존 방식과 비교할 때 크게 세 가지 면에서 차별화됩니다. 첫째, 다양한 수준의 추론을 하나의 통일된 표현 방식으로 처리할 수 있습니다. 둘째, 계획과 실행 사이의 경계를 유동적으로 설정할 수 있어 보다 유연한 문제 해결이 가능합니다. 셋째, 이 과정을 통해 생성되는 코드 트리는 자체적으로 학습 가능한 데이터가 되어, 모델의 학습 효율을 극대화할 수 있습니다.
ReCode (Recursive Code Generation) 방법론
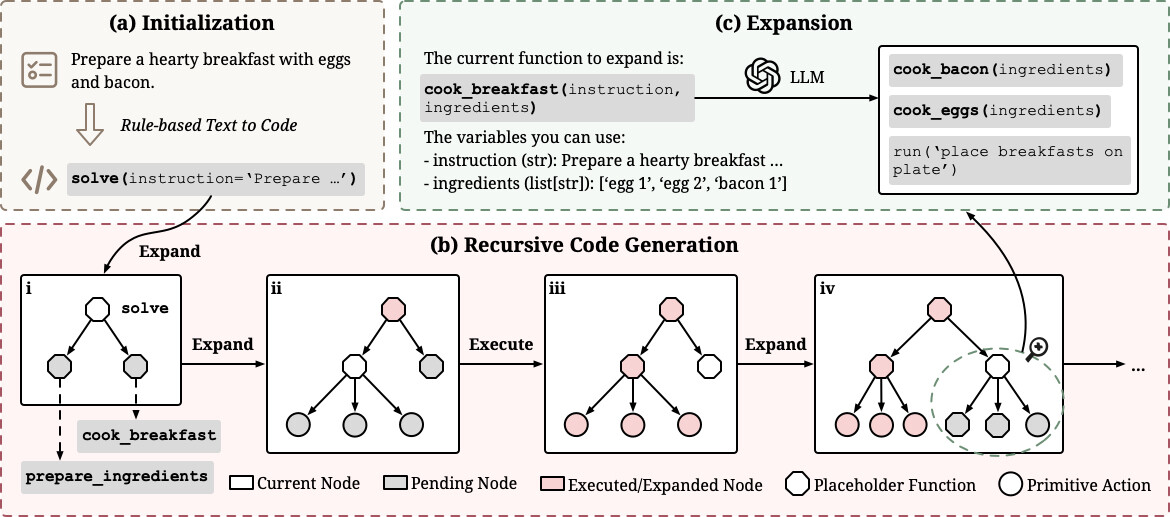
ReCode는 이름 그대로 Recursive Code Generation, 즉 “재귀적으로 코드를 생성하는 방식”으로 에이전트의 행동과 계획을 통합하는 방법론입니다. 논문 저자들이 이 구조를 만든 이유는, 기존 에이전트들이 “계획(planning)”과 “행동(action)”을 완전히 분리해 처리하다 보니 중간 단계의 유연성이 사라진다는 점이었습니다.
ReCode는 “계획이란 결국 높은 수준의 행동일 뿐이고, 행동 역시 낮은 수준의 계획일 뿐이다”라는 철학(A plan is simply a higher-level action)을 바탕으로 합니다. 그래서 두 개념을 하나의 공통 언어로 표현하고, 그 언어를 실행 가능한 코드로 삼습니다. 다시 말해, ReCode에서 계획과 행동은 모두 코드 함수 형태로 표현되며, 차이는 단지 그 함수가 더 세분화된 하위 함수를 포함하는가 아니면 실제 실행 가능한 최종 행동인가의 차이에 불과합니다.
ReCode는 인간이 문제를 푸는 방식과 닮아 있습니다. 예를 들어 누군가 “아침을 준비하라”라고 지시하면, 사람은 바로 행동하지 않습니다. 대신 머릿속에서 “커피를 끓이고, 토스트를 굽고, 달걀을 볶자”라는 식의 하위 계획을 세우고, 각 계획을 다시 “커피 포트를 켜고, 물을 붓고, 필터를 끼운다”처럼 더 작은 단계로 나눕니다. 결국 마지막에는 손을 움직이는 물리적 동작에 이릅니다. ReCode가 제안하는 것은 이 인간의 사고 흐름을 코드 생성 절차로 형식화한 것입니다.
이제 ReCode의 상세 실행 구조 및 방법론에 대해서 살펴보도록 하겠습니다.
ReCode의 실행 구조: 함수로 표현된 사고의 트리
ReCode의 중심에는 하나의 함수 호출 트리(Call Tree) 가 있습니다. 트리의 뿌리(Root)는 주어진 문제 전체를 대표하는 가장 상위 계획이며, 그 아래에는 여러 하위 함수들이 연결되어 있습니다. 각 함수는 다시 자신의 하위 함수를 포함할 수도 있고, 혹은 실제 환경에서 실행되는 원시 행동(Primitive Action)으로 끝날 수도 있습니다.
이 트리는 고정된 것이 아니라, 모델이 스스로 만들어갑니다. 상위 계획 함수가 실행되면, 내부에서 “이 일을 하기 위해 어떤 하위 단계가 필요할까?”를 스스로 생각하고, 그 결과를 코드 형태로 만들어내는 것입니다. 이렇게 생성된 코드 블록은 곧바로 실행되거나, 또다시 세분화되어 새로운 코드로 확장됩니다. 이 과정이 반복되면서 ReCode는 재귀적으로 계획을 세우고 실행합니다.
ReCode의 실행 루프를 좀 더 구체적으로 따라가 보겠습니다. 먼저, 모델은 자연어 형태의 지시문을 입력으로 받습니다. 예를 들어 “책상 위의 컵을 주방으로 옮겨라”라는 지시가 주어졌다고 합시다. 일반적인 LLM 기반 시스템이라면 이 문장을 토큰화하여 일련의 텍스트 응답을 만들겠지만, ReCode에서는 그 지시문을 하나의 함수 호출로 변환합니다.
예를 들어, move_cup_to_kitchen() 같은 함수가 생성됩니다. 이 함수는 아직 내부 구현이 비어 있는 “플레이스홀더 함수(Placeholder Function)”입니다. 이 단계가 바로 상위 계획의 코드화입니다.
이제 모델은 이 함수를 분석합니다. 이 함수는 실행할 수 있는 코드가 아니므로, 모델은 “이 함수를 완성하기 위해 무엇을 해야 할까?”라는 질문을 스스로 던지고, 그 답을 코드 형태로 작성합니다. 예를 들어 다음과 같은 코드 블록을 생성할 수 있습니다:
def move_cup_to_kitchen():
locate_cup()
grasp_cup()
carry_cup_to_kitchen()
place_cup_on_counter()
여기서 locate_cup(), grasp_cup(), carry_cup_to_kitchen(), place_cup_on_counter()는 모두 아직 정의되지 않은 하위 함수들입니다. 모델은 이제 각 하위 함수를 다시 같은 방식으로 확장할 수 있습니다. 예를 들어 grasp_cup()를 열어보면 아래와 같은 코드가 생성될 수 있습니다.
def grasp_cup():
move_hand_to_cup()
close_gripper()
그리고 이 두 함수는 더 이상 분해(Decomposition)할 필요가 없는, 즉 실제 물리적 행동(Primitive Action)에 해당하는 코드로 매핑됩니다. 예를 들어 move_hand_to_cup()는 로봇 시스템에서는 모터 명령으로, 웹 에이전트라면 “마우스 클릭”과 같은 명령으로 바뀔 수 있습니다.
이러한 과정을 일반화하면 다음과 같은 재귀 함수(Recursive Function) 구조로 표현할 수 있습니다:
def RECODE(task_function):
if task_function.is_primitive():
execute(task_function)
else:
sub_code = LLM_generate(task_function)
for sub_function in sub_code:
RECODE(sub_function)
이 단 몇 줄의 의사코드(Pseudo-Code)가 바로 ReCode 전체의 구조를 요약합니다. 실제 논문에서는 이 과정을 아래와 같인 알고리즘으로 표현하고 있으며, 모델이 코드 트리를 완성할 때까지 RECODE()가 재귀적으로 호출되는 구조임을 명시합니다.

이 구조의 아름다움은 단순함에 있습니다. ReCode는 기존의 “계획 세우기 → 행동하기”처럼 두 개의 별도 모듈이 아니라, 단 하나의 재귀 함수 안에서 모든 결정을 다룹니다. 함수가 스스로 분해되며, 더 이상 분해할 수 없을 때 비로소 행동이 실행됩니다.
코드 생성과 실행의 통합
ReCode의 또 다른 중요한 특징은 “코드 생성과 코드 실행이 하나의 루프(loop) 안에서 일어난다”는 점입니다. 모델은 단순히 계획을 세우는 것이 아니라, 자신이 생성한 코드를 실제로 실행합니다. 이 때, “실행(execution)”이란 반드시 로봇의 물리적 동작만을 의미하지 않습니다. 브라우저를 조작하는 웹 에이전트라면 클릭이나 입력 같은 액션이 될 수도 있고, 소프트웨어 환경에서는 API 호출이나 함수 실행이 될 수도 있습니다.
실행 단계에서 모델은 각 행동의 결과를 관찰하고, 그 정보를 다시 상위 호출 스택으로 전달합니다. 즉, 모델은 단순히 “다음 행동을 생성”하는 것이 아니라 “이전 행동의 실행 결과”를 고려하여 다음 행동을 갱신할 수 있습니다. 이 구조 덕분에 ReCode는 정적인 계획 생성기가 아니라, 실행 중 실시간으로 계획을 수정할 수 있는 자기 조정형 에이전트로 작동합니다.
예를 들어 carry_cup_to_kitchen()이 실행 중에 “문이 닫혀 있다”는 관찰 결과를 받는다면, 모델은 이 함수를 다시 열어 하위 단계로 분해할 수 있습니다. 그 결과, 다음과 같은 코드로 확장될 수 있습니다:
def carry_cup_to_kitchen():
if not door_is_open():
open_door()
walk_to_kitchen()
carry_cup()
이처럼 실행 결과를 기반으로 계획이 즉시 수정되는 것은 전통적인 플래너(Planner)에서는 불가능한 행동입니다. ReCode는 계획과 실행이 동일한 코드 트리 안에 공존하기 때문에, 계획의 수정과 실행의 반복이 완전히 통합된 구조를 갖습니다.
재귀적 제어의 장점과 구현 세부사항
재귀 구조의 장점은 유연성과 단순성입니다. 하나의 통일된 메커니즘만으로 상위 목표부터 하위 행동까지 다룰 수 있기 때문입니다. 그러나 실제 구현에서는 몇 가지 추가적인 제어 로직이 필요합니다.
가장 먼저 고려해야 하는 것은 “재귀 깊이(Recursive Depth)”입니다. 너무 깊이 들어가면 코드 트리가 폭발적으로 커지고, 실행 시간이 길어질 수 있습니다. 그래서 ReCode에서는 최대 재귀 깊이를 미리 설정하고, 그 깊이에 도달하면 더 이상 하위 함수를 생성하지 않고 현재 수준에서 실행 가능한 행동을 선택하도록 설계했습니다. 이는 인간의 사고에서도 유사하게 일어나는 제어입니다. 사람 역시 모든 행동을 끝없이 쪼개지 않고, 적당한 수준에서 멈추고 실행합니다.
또 하나 중요한 것은 “오류 복구(Self-Correction)”입니다. 모델이 생성한 코드가 실행되지 않거나 문법 오류를 일으킬 수 있기 때문입니다. ReCode는 이러한 오류를 단순히 실패로 처리하지 않고, 오류 메시지를 모델에 다시 입력으로 제공합니다. 모델은 그 정보를 바탕으로 코드를 수정하여 다시 실행합니다. 즉, 코드가 실패하면 스스로 디버깅하는 구조가 포함되어 있습니다. 논문에서는 이 과정을 “Error-Driven Recursive Refinement”라고 부릅니다.
이러한 제어 구조 덕분에 ReCode는 완전히 자동화된 재귀 루프임에도 불구하고, 무한 루프나 비효율적인 분해로 빠지지 않고 안정적으로 동작할 수 있습니다.
데이터 측면에서 본 ReCode의 가치
ReCode가 가지는 가장 큰 공학적 가치는 학습 데이터 효율성입니다. 일반적인 LLM 기반 에이전트는 보통 “행동 예시”만을 학습합니다. 즉, 입력(상황)과 출력(행동) 사이의 직접적인 매핑을 배웁니다. 그러나 ReCode는 계획과 행동을 코드 트리로 표현하기 때문에, 하나의 에피소드에서 다양한 수준의 데이터를 동시에 얻을 수 있습니다.
예를 들어, 하나의 문제 해결 과정에서 루트 노드(상위 계획), 중간 노드(하위 계획), 리프 노드(행동)가 모두 기록됩니다. 따라서 학습 데이터로는 단일 행동 데이터뿐 아니라, “계획이 어떻게 세분화되는가”에 대한 정보까지 활용할 수 있습니다. 이는 일반적인 데이터셋보다 훨씬 풍부한 구조적 신호를 포함하며, 적은 데이터로도 더 깊이 있는 의사결정 학습이 가능해집니다.
ReCode의 핵심 철학
ReCode의 철학은 간단히 말해 “계획과 행동의 경계를 코드 수준에서 지워버린다”는 것입니다. 계획이 함수 정의라면, 행동은 함수 호출입니다. 계획을 세운다는 것은 곧 실행 가능한 코드를 작성한다는 의미이고, 행동한다는 것은 그 코드를 호출한다는 뜻입니다.
ReCode는 전통적 AI의 사고 체계인 “계획–실행–평가”라는 3단계 구조를 단일 코드 생명주기 안으로 통합해버렸으며, 그 결과 에이전트는 계획을 세우면서 동시에 실행할 수 있고, 실행하면서 동시에 계획을 수정할 수 있습니다. 이러한 방식은 단순히 성능을 높이기 위한 기술적 기교가 아니라, 인간의 사고 구조에 한 걸음 더 가까이 다가가려는 시도라고 볼 수 있습니다.
ReCode의 실험 결과 및 분석
ReCode는 다양한 시뮬레이션 환경에서 정밀하게 평가되었습니다. 대표적으로 ALFWorld(가정 내 로봇 행동 시뮬레이터), WebShop(온라인 상품 탐색 및 구매 시뮬레이터), 그리고 ScienceWorld(과학 실험 수행 환경) 등을 사용되었습니다.
이들 세 환경은 모두 서로 다른 종류의 의사결정 능력을 요구하기 때문에, ReCode가 얼마나 유연하게 “계획과 행동의 통합 구조”를 다룰 수 있는지를 검증하는 데 이상적이었습니다. ALFWorld는 물체 인식 및 위치 조작 등 순차적 추론(Reasoning)이 필요하고, WebShop은 검색/선택/클릭 같은 고수준 판단이 포함되며, ScienceWorld는 실험 절차의 논리적 순서를 추론해야 합니다. 즉, 이 세 환경은 결합적으로 언어 기반 계획, 코드 실행, 그리고 상황 의존적 추론을 모두 테스트할 수 있는 벤치마크로 동작할 수 있습니다.
실험 결과, ReCode는 전반적으로 모든 환경에서 기존 방법론보다 유의미하게 높은 성공률과 효율성을 보였습니다:
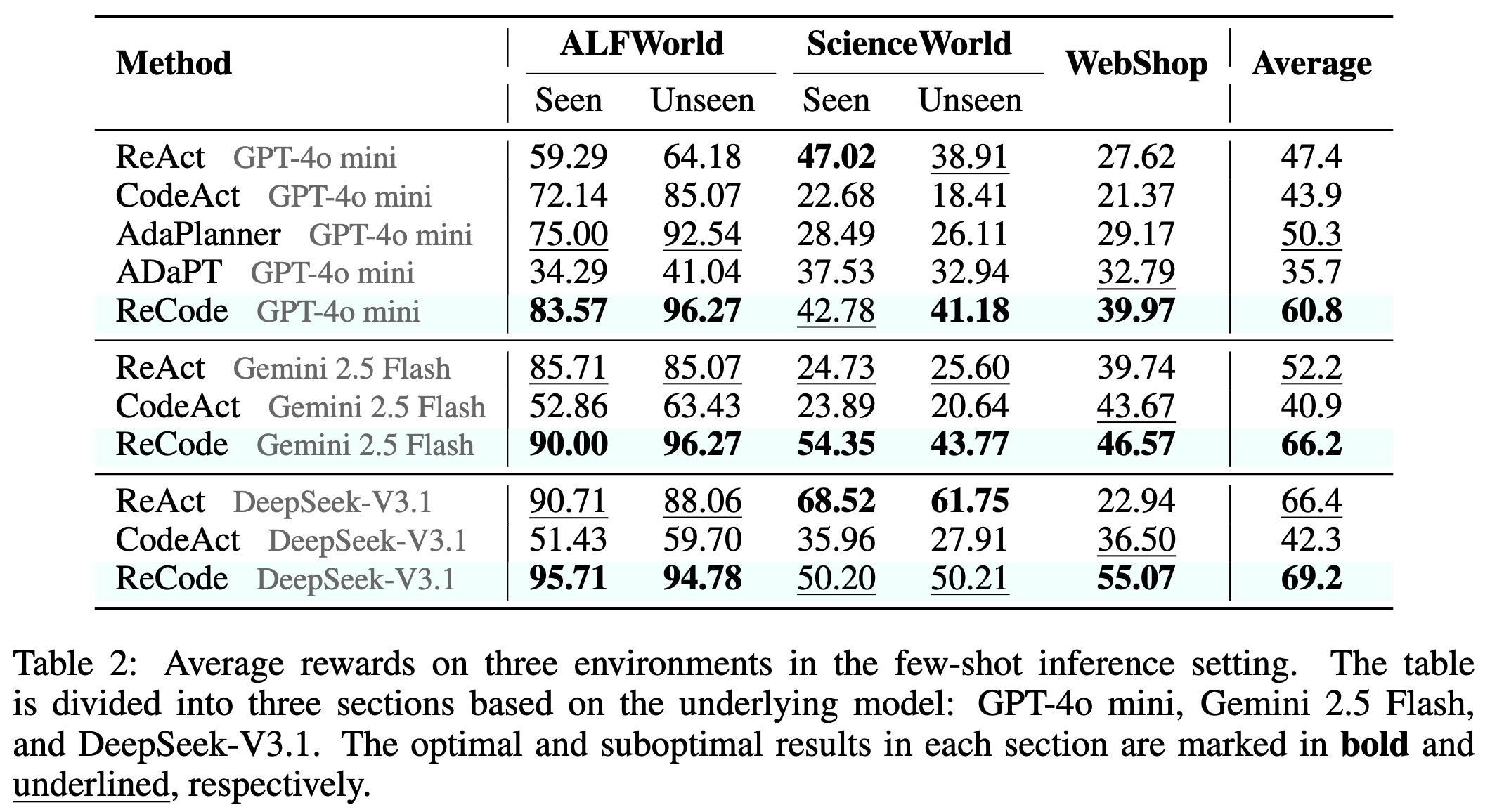
전반적인 추론(inference) 성능의 경우, GPT-4o mini에서 ReCode의 평균 성공률은 60.8%로, 기존 최고 성능 대비 약 10.5 향상되었습니다. 특히 ALFWorld의 학습 시 보지 못한 과제(Unseen Task)에서 ReCode는 96.27 의 성공률을 달성한 반면, ReAct는 64.18, CodeAct는 85.07 로 현저히 낮았습니다.
WebShop 환경에서도 ReCode는 39.97의 성공률을 기록하여 ReAct(27.62)와 CodeAct(21.37)를 크게 상회했습니다. ScienceWorld에서는 수치가 다소 낮지만, ReCode가 학습 시 보지 못한 과제에서 가장 좋은 성적을 거뒀습니다.
이러한 결과는 ReCode가 단순히 특정 환경에 최적화된 방식이 아니라, 다양한 추론 구조를 포괄적으로 다룰 수 있는 범용적 성능 개선(Universal Performance Gain) 을 실현했다는 점을 의미합니다.
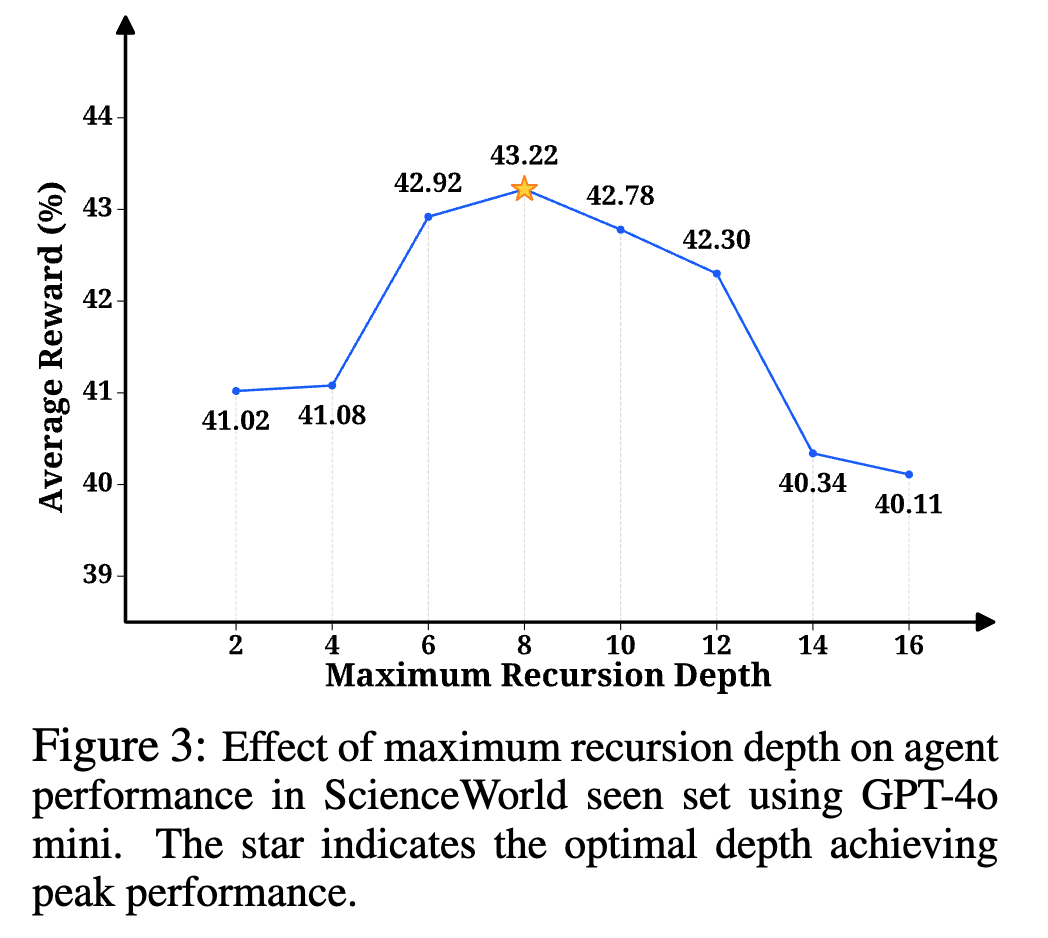
또한, 위와 같이 재귀 깊이(Recursion Depth)에 따른 성능 변화를 살펴보면, 그래프는 완만한 역U자형 곡선(Inverted U-shape) 을 그립니다. 즉, 깊이가 너무 얕으면(≤ 4단계) 세부 계획이 충분히 생성되지 않아 성능이 하락하고, 반대로 깊이가 14 단계를 넘어서면 과도한 함수 분해로 인해 탐색 비용이 증가하며 오히려 효율이 감소합니다. 결과적으로 6 ~ 12단계 수준에서 성능이 최고점을 형성했으며, 이 구간이 가장 안정적이고 효율적인 계획/행동 전환 구조로 분석되었습니다.
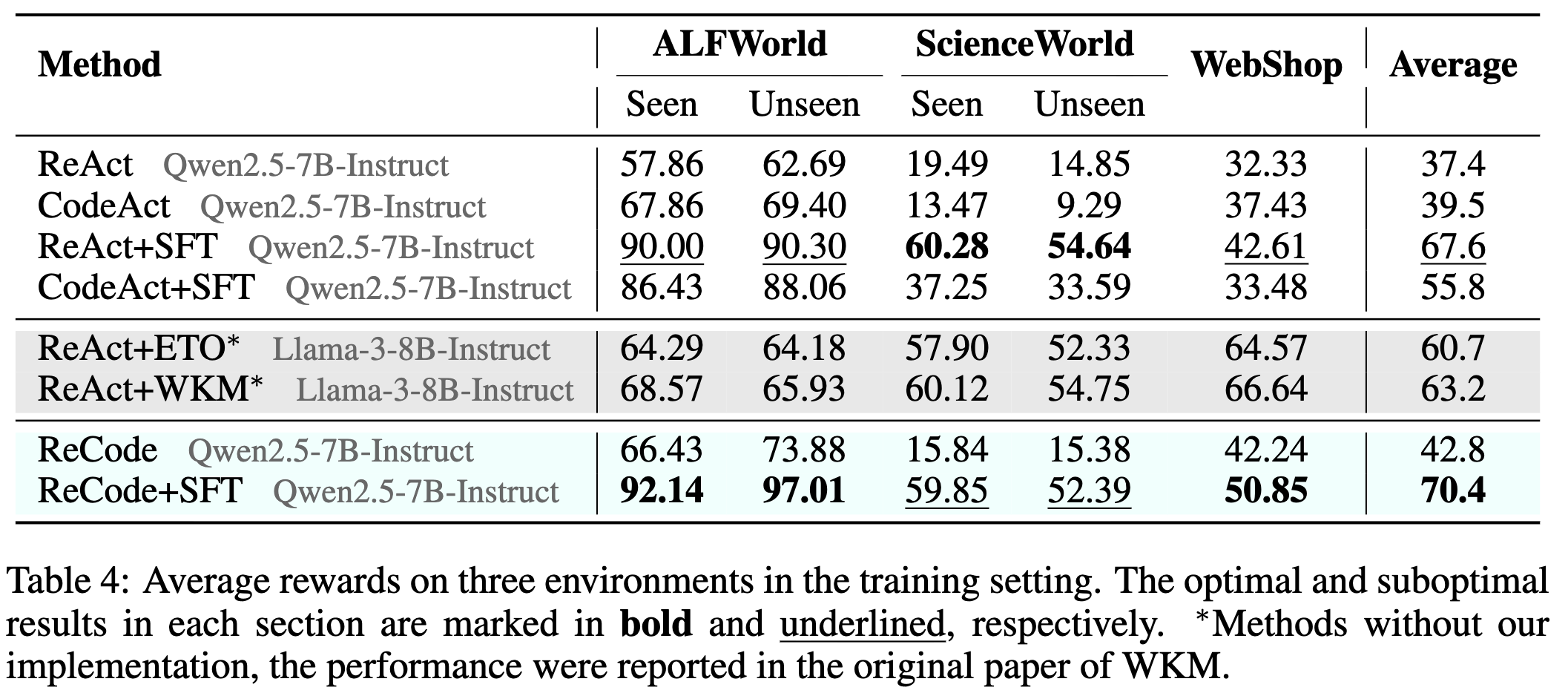
미세 조정(Fine-Tuning) 시나리오에서도 ReCode는 데이터 효율성(data efficiency) 에서 확실한 우위를 보였습니다. 위 표와 같이 동일한 학습 데이터 크기에서 ReCode + SFT(Supervised Fine-Tuning) 모델의 평균 성능은 70.4로, ReAct + SFT의 67.6, CodeAct + SFT의 55.8보다 높게 나타났습니다.
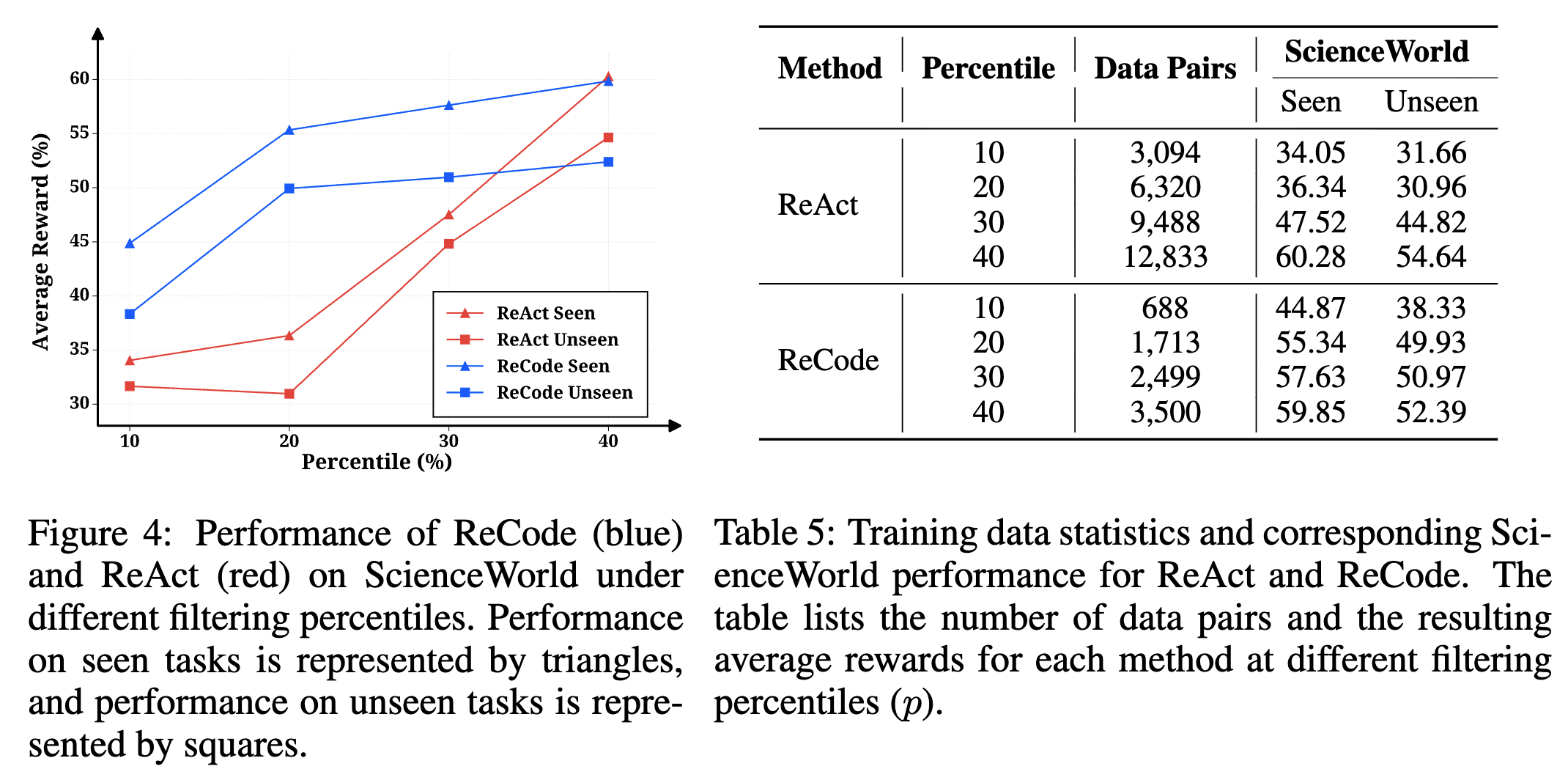
특히 주목할 부분은, 학습 데이터 수가 줄어드는 상황에서도 성능 유지력이 뛰어났다는 점입니다. ReCode가 “왜 더 적은 학습 데이터로 더 나은 성능을 내는가?”를 체계적으로 검증하기 위해, 보상 퍼센타일(reward percentile) 값에 따라 학습 데이터를 부분 샘플링하여 실험을 진행했습니다(p ∈ \{10, 20, 30, 40\}). 즉, 보상 점수가 상위 10%, 20%, 30%, 40%에 해당하는 데이터만을 각각 사용하여 학습을 수행한 것입니다.
ScienceWorld에서 얻어진 구체적 수치를 살펴보면, ReCode는 ReAct가 필요로 하는 데이터의 3~4배 적은 양으로 동일하거나 더 높은 성능을 달성했습니다. 또한, ReCode의 성능 곡선이 초기 데이터 증가 구간에서 급격히 상승한 뒤 완만한 포화(Plateau) 형태를 보이는 반면, ReAct의 곡선은 완만하고 지속적으로 증가합니다.
이러한 차이는 ReCode의 계층적 구조(Hierarchical Structure)가 각 학습 예시(example)에서 더 많은 학습 신호를 제공한다는 것을 입증합니다. 즉, ReCode는 데이터량이 늘지 않더라도 “하나의 학습 예시 안에서 상위 계획과 하위 행동을 동시에 학습”하기 때문에, 동일한 양의 데이터로 더 깊은 추론 패턴을 내재화할 수 있습니다.
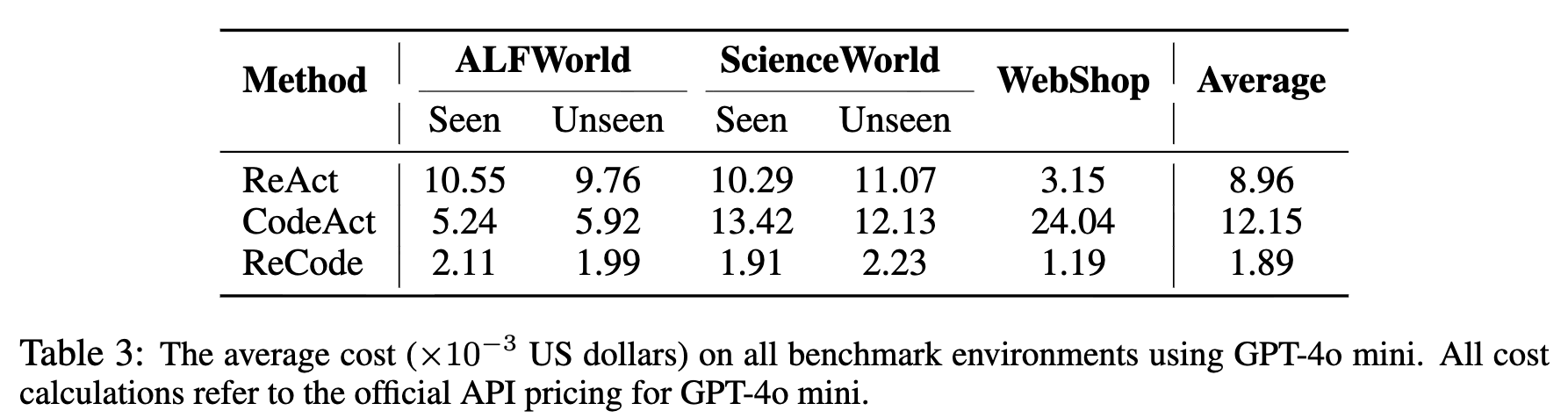
마지막으로, ReCode의 비용 효율성(Cost Efficiency) 측면에서도 주목할만한 결과가 도출되었습니다. 위 표의 비용 분석 결과에 따르면, ReCode는 한 학습 에피소드(Episode) 또는 실행 궤적(Trajectory) 당 평균 비용이 ReAct 대비 78.9, CodeAct 대비 84.4 절감되었습니다. 이러한 결과는 ReCode의 구조가 단순히 성능을 향상시킬 뿐 아니라, 불필요한 모델 호출과 중복 추론을 제거하여 실제 운영 비용을 줄여준다고 볼 수 있습니다.
또한, 위 성능 대비 비용 곡선(Figure 4)을 살펴보면, ReCode는 재귀 깊이(Recursive Depth) 8 근방에서 성능/비용 비율이 최대에 도달한 뒤 점차 안정화됩니다. 즉, 이 깊이가 ReCode가 최소한의 연산으로 최대의 결과를 내는 최적점(Sweet Spot) 으로 볼 수 있습니다.
결과적으로 ReCode는 데이터 사용량과 계산 자원 모두에서 기존 방식 대비 높은 효율을 보이며, “더 적은 데이터, 더 적은 호출, 더 높은 성능”이라는 세 가지 목표를 동시에 달성했습니다. 이러한 정량적 결과는 ReCode가 단순한 이론적 제안이 아니라, 실제 산업 환경에서도 비용-효율적인 추론형 에이전트 구조로 적용될 수 있음을 뒷받침합니다.
결론 및 한계
ReCode는 기존 LLM 기반 에이전트가 직면했던 “계획과 실행의 단절” 문제를 근본적으로 해결하려는 시도로, 고수준의 계획에서 저수준의 행동까지를 하나의 통합된 코드 구조로 연결했습니다.
이 접근법은 단순히 추론 정확도를 높이는 것을 넘어, 계층적 의사결정(hierarchical decision-making) 의 일반화 가능성을 실험적으로 입증했다는 점에서 의미가 큽니다. 특히 평균 20 이상 향상된 성공률, 3배 이상의 데이터 효율성, 80 수준의 비용 절감이라는 실험 수치는 ReCode가 단순한 연구용 개념이 아니라 실용적이고 확장 가능한 프레임워크임을 보여줍니다.
그럼에도 불구하고 ReCode에는 아직 해결해야 할 몇 가지 과제가 존재합니다:
우선, 코드 생성 과정이 여전히 LLM의 언어적 생성 품질에 크게 의존한다는 점에서, 생성된 코드의 안정성·일관성 보장은 완전하지 않습니다. 실행 중 오류나 문법 불일치가 발생할 경우 ReCode는 자체적인 오류 수정 루프(Self-Correction Loop)를 통해 복구하지만, 그 효율이 항상 보장되는 것은 아닙니다.
또한 변수 네임스페이스 관리, 무한 재귀 방지, 실행기의 보안성(Sandbox Safety) 등 시스템 레벨의 엔지니어링 과제가 여전히 남아 있습니다. 특히, 실제 하드웨어 제어나 웹 환경에서 ReCode를 적용할 때는 코드 실행의 안전성(safety)과 외부 리소스 접근 권한 제어가 필수적으로 고려되어야 합니다.
그럼에도 ReCode는 지금까지 제안된 방법 중 가장 체계적이고 실용적인 계층형 코드 기반 추론 프레임워크가 될 것으로 보입니다. 즉, 복잡한 환경에서도 일관된 의사결정을 수행하며, 데이터와 리소스를 모두 효율적으로 활용할 수 있다는 점에서, 코드 생성 기반 AI 에이전트 설계에 관심 있는 개발자·연구자들에게 매우 유용한 참고 사례가 될 것입니다.
ReCode는 “계획은 코드이며, 행동은 그 코드의 실행이다”라는 새로운 철학적 명제를 기술적으로 실현한, 현시점에서 가장 진보된 통합형 에이전트 프레임워크라 할 수 있습니다.
 ReCode 논문: Unify Plan and Action for Universal Granularity Control
ReCode 논문: Unify Plan and Action for Universal Granularity Control
 ReCode 프로젝트 GitHub 저장소
ReCode 프로젝트 GitHub 저장소
https://github.com/FoundationAgents/ReCode
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()