RedPajama - HELM 벤치마크 기준, 공개된 7B LLM 모델보다 뛰어난 7B 모델 공개
RedPajama 7B now available, instruct model outperforms all open 7B models on HELM benchmarks

소개
LLaMA 논문 기반의 RedPajama의 RedPajama-Data-1T 데이터셋 공개를 소개한 적이 있는데요,
이렇게 공개한 5TB짜리 데이터셋이 수천번 다운로드 & 100개가 넘는 모델 학습에 사용되었다고 합니다.
The 5 terabyte dataset has been downloaded thousands of times and used to train over 100 models!
1달 전쯤에는 자체적으로 학습 및 공개했던 3B와 7B 모델(Preview, v0.1) 공개 소식을 전해드렸었는데요,
조금 전 v1.0의 정식(?) 7B 모델군(RedPajama-INCITE-7B) 3종을 Apache 2.0으로 공개했습니다.
7B 모델은 Instruct / Chat / Base의 3종인데요, 공식 블로그의 설명을 아래 간략히 번역하여 공개합니다. ![]()
RedPajama-INCITE-7B 모델 3종 소개
RedPajama-INCITE-7B-Instruct 모델
- 기존 모델의 Instruct 튜닝 버전
- P3 (BigScience) 및 Natural Instruction (AI2)을 사용하여 학습
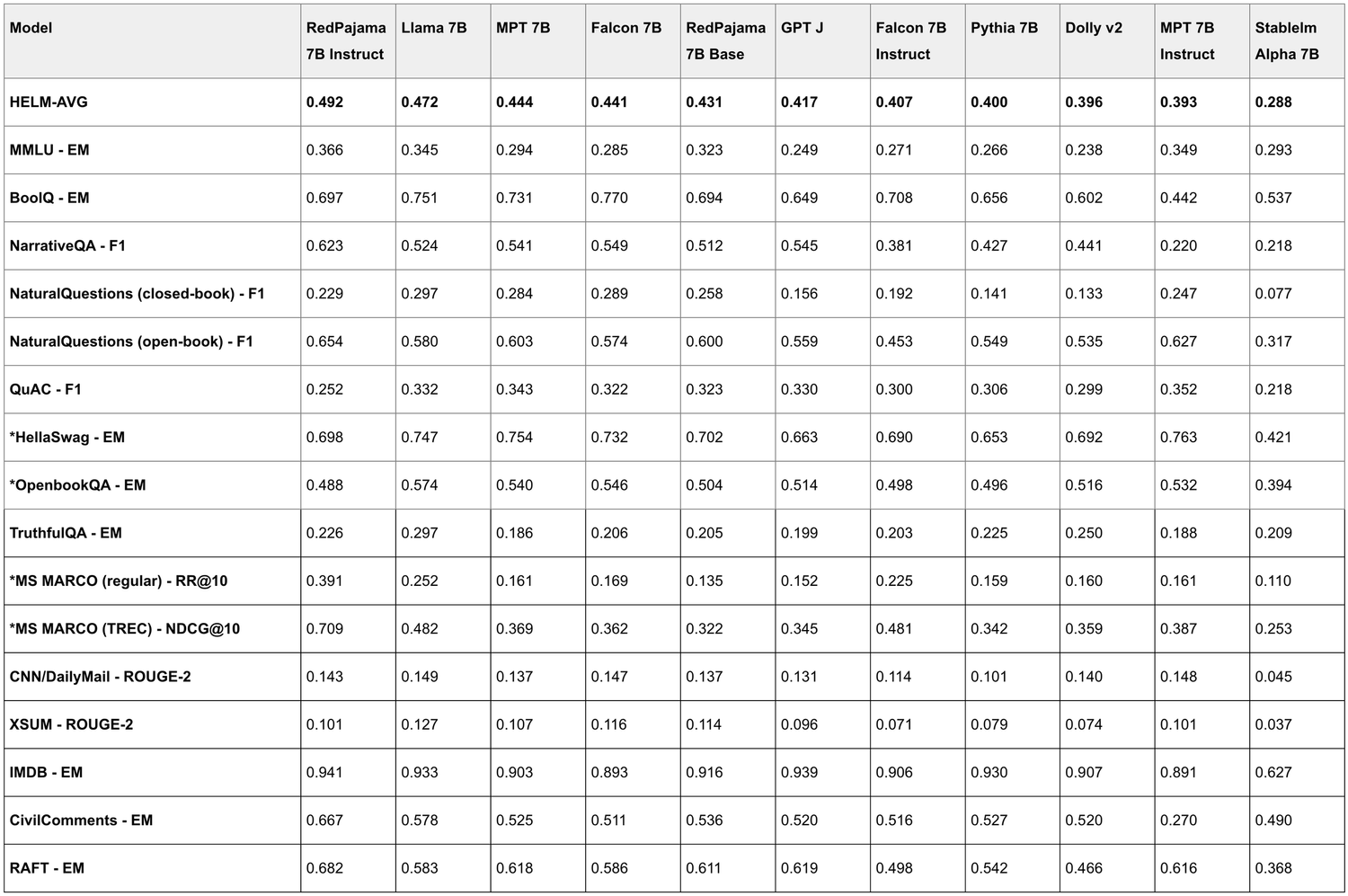
- HELM 벤치마크에서 가장 높은 점수를 받은 개방형 모델로 다양한 작업에 이상적
- HELM 기준, LLaMA-7B 및 Falcon-7B(Base&Instruct), MPT-7B(Base&Instruct)보다 높은 성능
- HELM 벤치마크 결과
* indicates tests that use logprob to compute results.
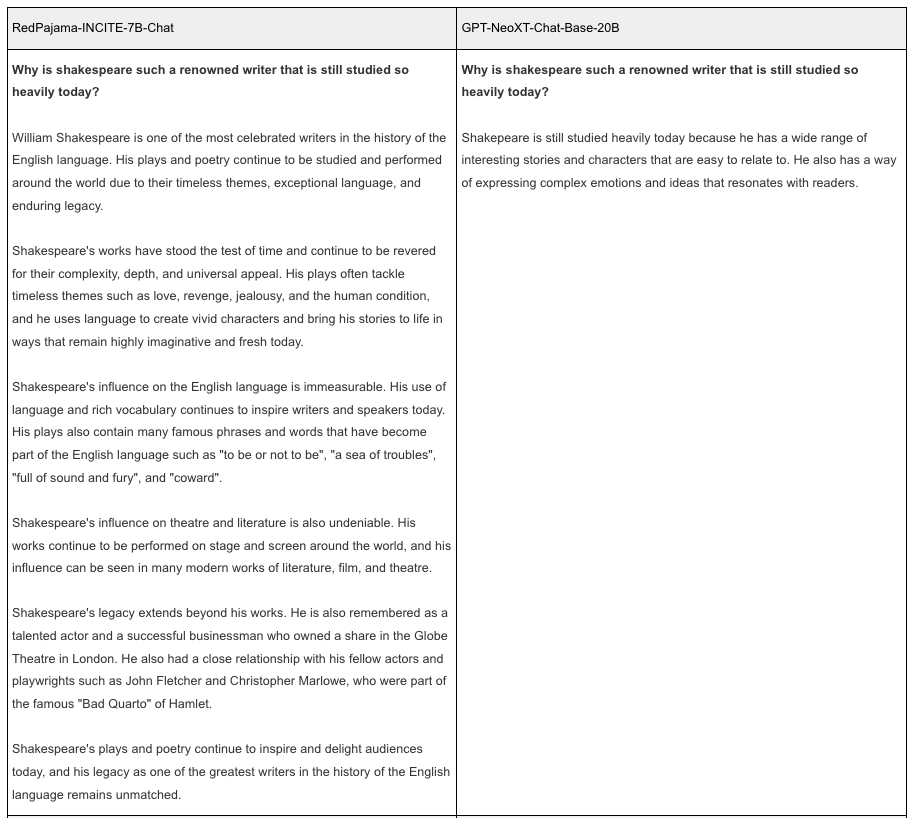
RedPajama-INCITE-7B-Chat 모델
- Dolly2 및 OASST 등과 같은 오픈소스 데이터만을 사용하여 학습
 상업적 사용 가능
상업적 사용 가능
- (+ Chat 모델 뿐만 아니라, RedPajama-INCITE 모델군은 모두 상업적 사용이 가능)
- 파인튜닝을 위한 학습 스크립트를 포함하여 공개 OpenChatKit에서 바로 사용 가능
- RedPajama.cpp(LLaMA.cpp의 fork)를 지원 - CPU에서 실행 가능
- MLC LLM등의 프로젝트와 협력 향후 다양한 하드웨어 상에서 동작 가능하게 할 것
RedPajama-INCITE-7B-Base 모델
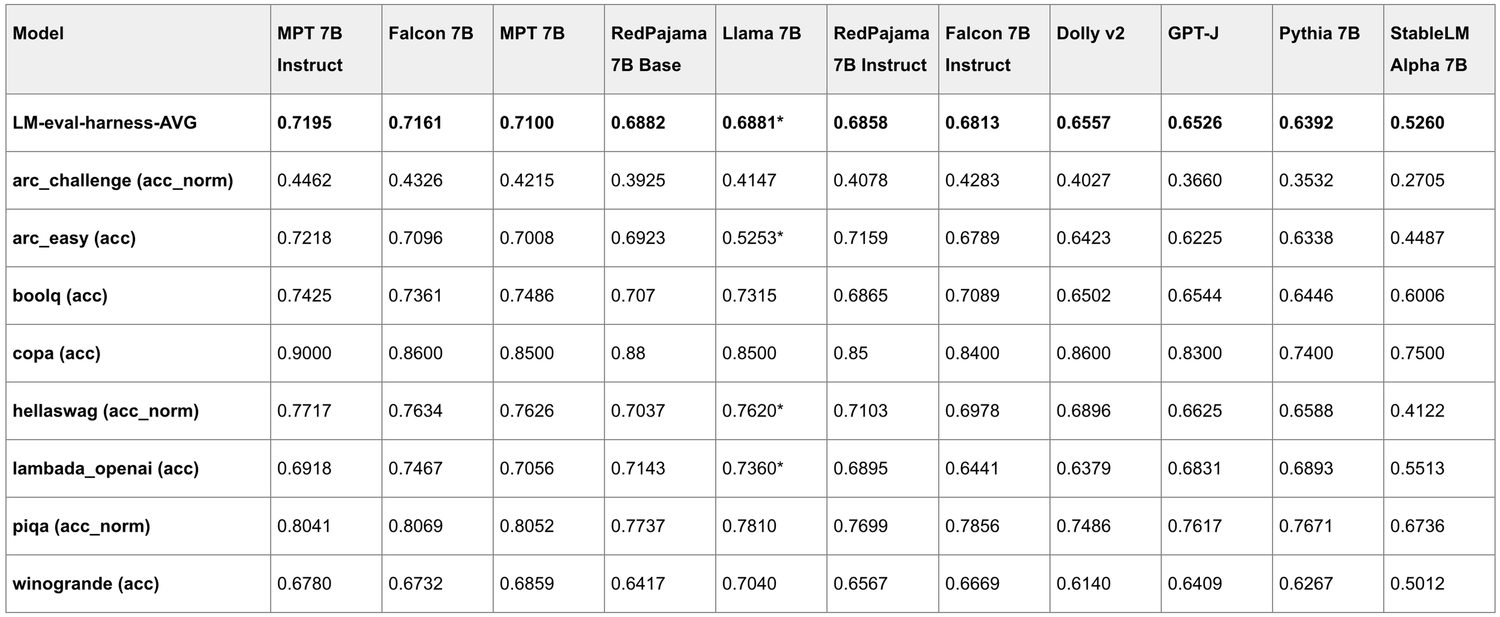
- EleutherAI의 Pythia 모델과 동일한 아키텍처를 사용, RedPajama-Data-1T 데이터셋으로 학습
 HuggingFace의 togethercomputer/RedPajama-INCITE-7B-Base에서 다운로드 가능
HuggingFace의 togethercomputer/RedPajama-INCITE-7B-Base에서 다운로드 가능- HELM 벤치마크 기준 LLaMA-7B보다 4점, Falcon-7B/MPT-7B보다 1.3점 가량 낮은 성능
- 위 결과는 학습 시 FP16을 사용했기 때문으로 추정 향후 더 높은 정밀도에서 학습 예정
향후 계획 (RedPajama2)
- 아래와 같은 계획으로 2~3T 토큰의 새로운 데이터셋 RedPajama2 개발 중::
- DoReMi와 같은 기술을 사용하여 데이터 혼합의 균형을 맞출 예정
- 다양성과 크기를 보완하기 위해 Eleuther.ai의 Pile v1 및 CarperAI의 Pile v2 등의 데이터 사용
- 더 많은 양의 CommonCrawl 데이터 처리
- LLaMA 논문의 접근 방법 외의 다양한 데이터 중복 제거 전략 탐색
- 150B 이상의 코드 토큰을 추가하여 코딩과 추론(reasoning) 작업의 품질 개선
- Understand in a principled way how to balance data mixture over each data slice. We are excited to try out techniques like DoReMi to automatically learn a better data mixture.
- Include complementary slices from Pile v1 (from Eleuther.ai), Pile v2 (from CarperAI), and other data sources to enrich the diversity and size of the current dataset.
- Process an even larger portion of CommonCrawl.
- Explore further data deduplication strategies beyond the approaches in the LLaMA paper.
- Include at least 150B more code tokens in the mixture to help improve quality on coding and reasoning tasks.