Reflection 70B 소개
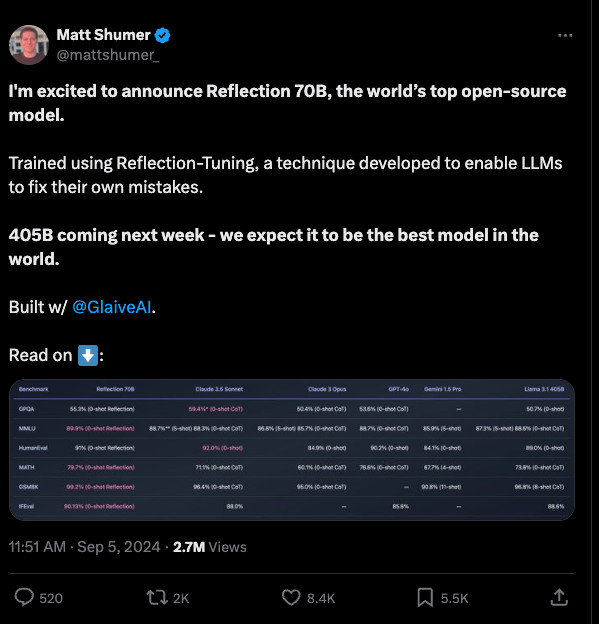
HyperWrite의 CEO인 Matt Shumer는 새로운 오픈소스 AI 모델인 Reflection 70B를 발표했습니다. 이 모델은 Meta의 Llama 3.1-70B Instruct를 기반으로 개발되었으며, 새로운 오류 자체 교정 기술인 Reflection Tuning 기법을 사용하여 성능을 향상시키고, 여러 벤치마크 테스트에서 우수한 결과를 보여주었습니다.
Reflection 70B 모델의 주요한 특징은 다음과 같습니다:
-
오류 자체 교정: Reflection 70B는 "Reflection-Tuning"이라는 기술을 사용하여 모델이 자체적으로 오류를 인식하고 교정할 수 있습니다. 이 기술은 모델이 내부적으로 생각하고 반영하는 과정을 통해 최종 답변을 제공합니다.
-
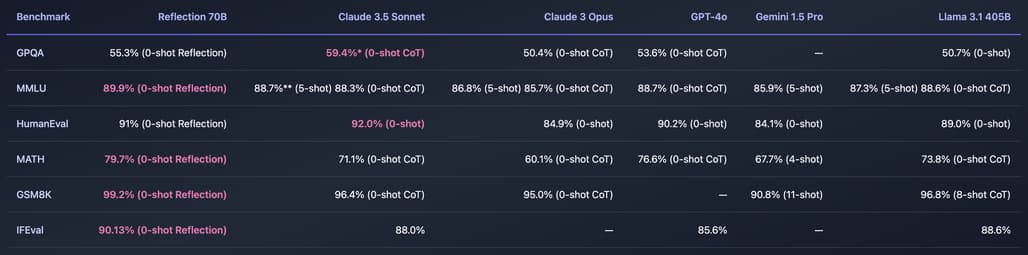
성능: Reflection 70B는 여러 벤치마크 테스트에서 우수한 결과를 보여주었습니다. MMLU, MATH, IFEval, GSM8K 등 다양한 테스트에서 Llama 3.1 405B를 능가하고, GPT-4o와 Sonnet과 같은 상용 모델과 경쟁할 수 있는 성능을 보였습니다.
-
오픈소스: Reflection 70B는 오픈소스 모델로, Hugging Face에서 모델 파일을 다운로드할 수 있으며, Hyperbolic Labs를 통해 API가 곧 제공될 예정입니다.
벤치마크 결과
-
ProLLM StackUnseen: Reflection 70B는 ProLLM StackUnseen 벤치마크에서 50%의 정확도를 보여주었으며, 이는 기존의 Llama 70B 모델보다 9% 높은 결과입니다.
-
MMLU와 HumanEval: Reflection 70B는 MMLU와 HumanEval 벤치마크에서도 우수한 결과를 보여주었습니다. LMSys의 LLM Decontaminator를 사용하여 결과가 오염되지 않은 것을 확인했습니다.
-
GSM8K: Reflection 70B는 GSM8K 벤치마크에서 75%의 정확도를 보여주었으며, 이는 기존의 Llama 70B 모델보다 10% 높은 결과입니다.
하지만, 이러한 벤치마크에 대해서는 일부 논란과 한계가 있습니다:
-
비교의 공정성: 일부 사용자는 Reflection 70B와 다른 모델의 비교가 공정하지 않다고 주장합니다. Reflection 70B는 특정한 출력 포스트프로세싱 기술을 사용하기 때문에, 다른 모델과 직접 비교하는 것이 어렵다고 합니다.
-
성능 한계: Reflection 70B는 70B의 파라미터를 사용하기 때문에, 더 큰 모델과 비교했을 때 성능이 떨어질 수 있습니다. 예를 들어, Mistral 123B와 비교했을 때, Reflection 70B는 일부 테스트에서 더 낮은 성능을 보였습니다.
사용 방법
- 로컬 실행: Reflection 70B를 로컬에서 실행하기 위해서는 Hugging Face에서 모델 파일을 다운로드하고, Pinocchio를 사용하여 모델을 설치하고 실행할 수 있습니다.
- API: Hyperbolic Labs를 통해 API가 곧 제공될 예정입니다.
 Reflection 70B 모델 사용해보기
Reflection 70B 모델 사용해보기
 Reflection 70B 모델 가중치
Reflection 70B 모델 가중치
 Reflection Tuning 논문 (Ming Li 외, 2023년 10월 / ACL'24)
Reflection Tuning 논문 (Ming Li 외, 2023년 10월 / ACL'24)
 Reflection Tuning GitHub 저장소
Reflection Tuning GitHub 저장소
https://github.com/tianyi-lab/Reflection_Tuning
Selective Reflection Tuning 논문 (Ming Li 외, 2024년 02월)
관련 기사
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()