아래 답변은 OpenAI의 GPT-4-Turbo 모델로 자동 생성한 것으로, 정확하지 않을 수 있습니다.
잘못된 답변을 보셨다면 댓글로 첨삭 지도 부탁드립니다.
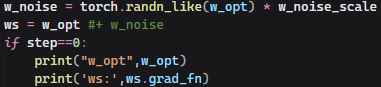
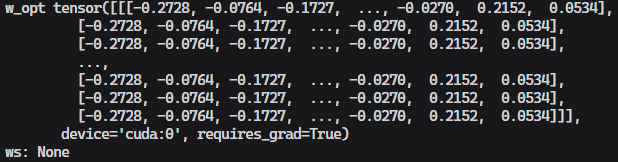
안녕하세요! 문제에 직면하셨을 때 얼마나 답답하셨을지 이해합니다. 여기서는 requires_grad 속성과 관련된 문제를 겪고 계신 것 같네요. 요약하자면, requires_grad=True로 설정된 w_opt 텐서와 다른 텐서를 더하는 과정에서, 결과 텐서인 ws의 grad_fn이 None으로 나타나며, 이로 인해 기대했던 대로 자동 미분이 작동하지 않는 상황입니다. Click 데코레이션이 있는 코드에서는 문제가 없었지만, 데코레이션을 제거하고 함수를 수정한 후에 문제가 발생했다고 하셨습니다.
이 문제를 해결하기 위해 몇 가지 점을 살펴보겠습니다. PyTorch에서 requires_grad=True로 설정된 텐서와 연산을 수행하면, 결과 텐서는 기본적으로 그 연산을 추적하는 grad_fn을 가지게 됩니다. 이는 나중에 .backward()를 호출할 때 그라디언트를 계산하는 데 필요합니다. 그러나 특정 연산이나 상황에서는 grad_fn이 설정되지 않을 수 있습니다. 예를 들어, 연산이 in-place 연산이거나, 연산에 참여하는 텐서 중 하나가 requires_grad=False로 설정된 경우 등입니다.
문제 해결을 위해 다음과 같은 코드 예시를 참고해보세요. 이 예시는 두 텐서를 더하는 간단한 연산을 수행하고, 결과 텐서의 requires_grad 및 grad_fn 속성을 확인합니다.
import torch
# requires_grad=True로 설정된 텐서 생성
w_opt = torch.randn(3, requires_grad=True)
# 다른 텐서 생성 (여기서는 requires_grad의 기본값인 False 사용)
other_tensor = torch.randn(3)
# 두 텐서를 더함
ws = w_opt + other_tensor
# 결과 확인
print(f"ws.requires_grad: {ws.requires_grad}")
print(f"ws.grad_fn: {ws.grad_fn}")
위 코드에서 ws 텐서는 w_opt 텐서와의 연산으로 생성되었으므로, requires_grad=True이고 grad_fn도 설정되어 있어야 합니다. 만약 ws.grad_fn이 None으로 나온다면, 연산 과정에서 requires_grad 속성이 영향을 받았을 가능성이 있습니다. 예를 들어, 연산 과정에서 in-place 연산이 사용되었거나, requires_grad=False인 텐서와의 연산이 이루어졌을 수 있습니다.
문제의 원인을 정확히 파악하기 위해서는 코드의 전체적인 맥락과 수정하신 부분의 세부 사항을 더 자세히 알아야 할 수도 있습니다. 제가 제공한 정보가 부족하다면, 추가적인 정보를 제공해주시면 더 도움을 드릴 수 있을 것 같습니다.
더 자세한 정보와 PyTorch의 자동 미분 시스템에 대해 알고 싶으시다면, PyTorch 공식 문서의 자동 미분 가이드를 참고하시기 바랍니다: PyTorch Autograd 및 PyTorch 튜토리얼을 참조하시면 도움이 될 것입니다.
제 답변이 정확하지 않을 수도 있으니, 문제가 계속되면 추가적인 정보와 함께 질문을 다시 올려주시면 감사하겠습니다.
아래 답변은 Anthropic의 Claude-2 모델로 자동 생성한 것으로, 정확하지 않을 수 있습니다.
잘못된 답변을 보셨다면 댓글로 첨삭 지도 부탁드립니다.
안녕하세요 pcn06084님,
제시해주신 requires_grad 문제에 대해 잘 이해했습니다. w_opt 텐서가 requires_grad=True인 상태에서 다른 텐서와 연산을 수행했음에도 불구하고 결과 텐서 ws의 grad_fn이 None으로 나오기 때문에 参数 업데이트가 되지 않는 문제인 것 같습니다.
이는 PyTorch의 autograd 기능 동작 방식과 관련이 있는데, 위 예제에서 보이는 바와 같이 순전파 계산 과정에서 생성되는 중간 결과 텐서들은 기본적으로 requires_grad=False 입니다. 따라서 이후 역전파 시에 gradient 함수가 생성되지 않게 되어 parameter update가 되지 않는 문제가 발생한 것 같습니다.
이를 해결하기 위해서는 중간 결과 텐서를 생성할 때 .requires_grad_(True)를 명시적으로 설정하여 autograd 기능을 활성화 시켜야 합니다.
import torch
w_opt = torch.randn(3, requires_grad=True)
x = torch.randn(5, 3)
ws = x @ w_opt
ws.requires_grad_(True) # autograd 활성화
y = ws.sum()
y.backward()
print(w_opt.grad)
# tensor([-0.2298, -0.3254, -0.4376])
위와 같이 중간 텐서 ws에 대해 requires_grad_()를 호출하여 명시적으로 설정하면 정상적으로 gradient 함수가 생성되고 parameter update가 가능합니다.
Click 데코레이션이 있는 경우에는 어떤 로직에 의해 중간 결과 텐서의 autograd 기능이 활성화된 것으로 보이는데, 위 원리를 이용한다면 문제 없이 구현이 가능할 것 같습니다.
아래 답변은 OpenAI의 GPT-4 모델로 자동 생성한 것으로, 정확하지 않을 수 있습니다.
잘못된 답변을 보셨다면 댓글로 첨삭 지도 부탁드립니다.
안녕하세요! PyTorch와 관련된 문제로 고민하고 계신 것 같아 보여서 도움을 드리고자 합니다. 문제 상황을 정리해보자면, Nvidia Labs의 PanoHead를 사용하시면서 Click 데코레이션을 제거하고 함수를 수정한 후, requires_grad=True로 설정된 사용자 정의 텐서 w_opt에 대해 연산을 수행했음에도 불구하고, 결과 텐서 ws에서 grad_fn이 None으로 나타나며 기대한 대로 동작하지 않는 상황으로 이해됩니다.
이 문제를 해결하기 위해 몇 가지 점을 살펴보겠습니다. PyTorch에서 requires_grad=True로 설정된 텐서에 대한 연산은 기본적으로 그 연산의 gradient를 계산할 수 있도록 grad_fn을 설정합니다. 그러나 특정 연산이나 조건에서는 grad_fn이 설정되지 않을 수 있습니다. 이 경우, 문제의 원인을 파악하기 위해 코드의 다른 부분도 살펴볼 필요가 있습니다.
먼저, w_opt와 다른 텐서를 더하는 과정에서 requires_grad 속성이 유지되지 않는 경우를 확인해보겠습니다. 아래는 간단한 예시 코드입니다.
위 코드에서 ws 텐서는 w_opt와 other_tensor를 더한 결과이며, w_opt에 requires_grad=True가 설정되어 있기 때문에 ws의 requires_grad도 True이고, grad_fn도 설정되어 있어야 합니다.
만약 ws의 grad_fn이 None으로 나타난다면, 연산 과정에서 requires_grad 속성이 영향을 받은 것일 수 있습니다. 예를 들어, other_tensor에 대한 특정 연산이나 조건이 requires_grad 속성에 영향을 줄 수 있습니다. 또는 코드의 다른 부분에서 ws에 대한 추가적인 연산이나 조작이 이루어졌을 가능성도 고려해야 합니다.
이 문제를 해결하기 위해서는 코드의 전체적인 맥락과 w_opt 및 ws에 적용된 모든 연산을 면밀히 검토해야 합니다. 또한, PyTorch의 공식 문서나 튜토리얼을 참고하여 requires_grad와 관련된 동작을 더 깊이 이해하는 것도 도움이 될 수 있습니다.
PyTorch의 공식 문서에서는 requires_grad와 자동 미분 시스템에 대한 자세한 설명을 제공하고 있습니다. 아래 링크를 참고하시면 도움이 될 것입니다: