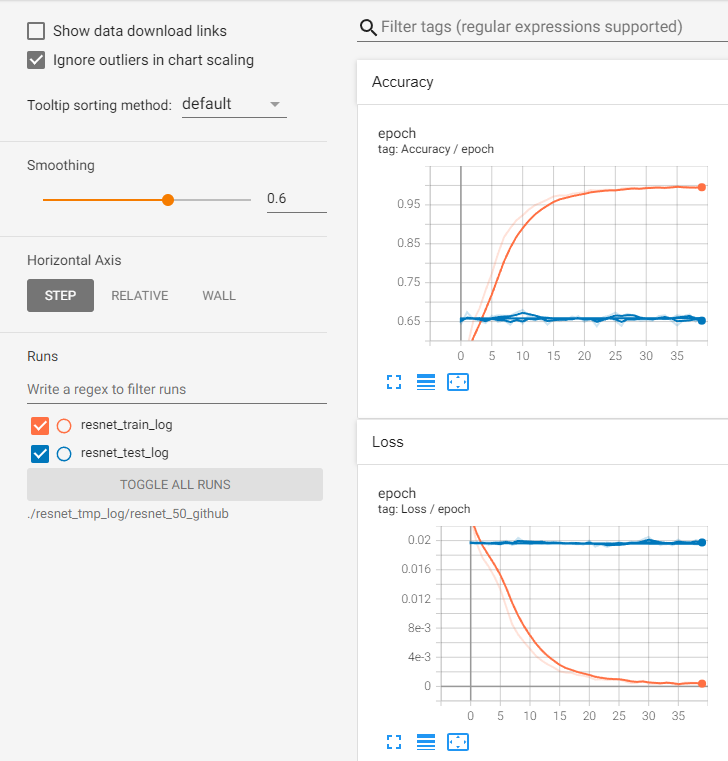
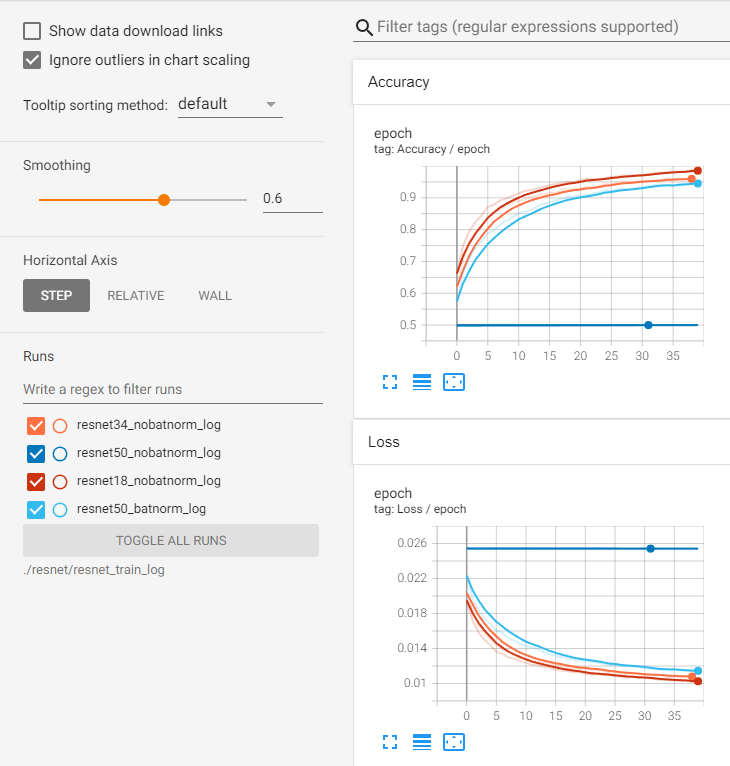
- 아래 답변은 OpenAI의 GPT-4 모델로 자동 생성한 것으로, 정확하지 않을 수 있습니다.
- 잘못된 답변을 보셨다면 댓글로 첨삭 지도 부탁드립니다.

안녕하세요! PyTorch를 이용해 ResNet 모델을 구현하고 훈련하면서 어려움을 겪고 계신 것 같습니다. 질문을 정리해보면, ResNet 50 모델이 제대로 학습되지 않는 문제와, torchvision에서 제공하는 ResNet 50 모델과 직접 구현한 모델의 구조가 다른 문제에 대해 궁금해하시는 것 같습니다. 특히, 모델의 구조 차이가 학습에 큰 영향을 미치는지, 그리고 이로 인해 학습이 전혀 이루어지지 않을 정도의 문제인지에 대한 의문을 가지고 계신 것 같습니다.
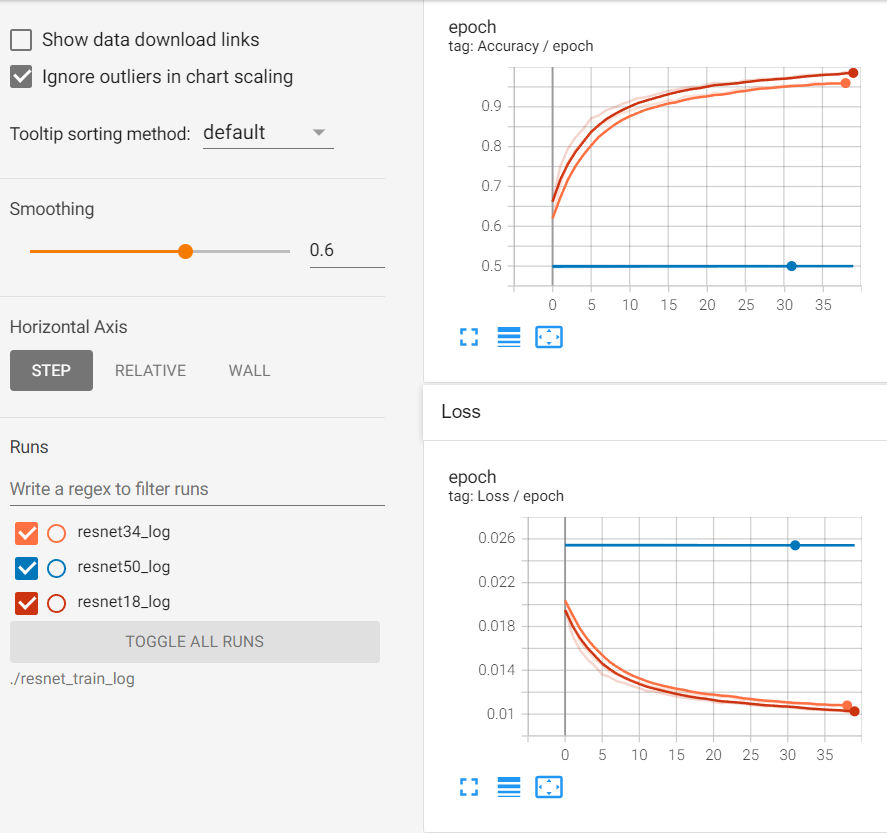
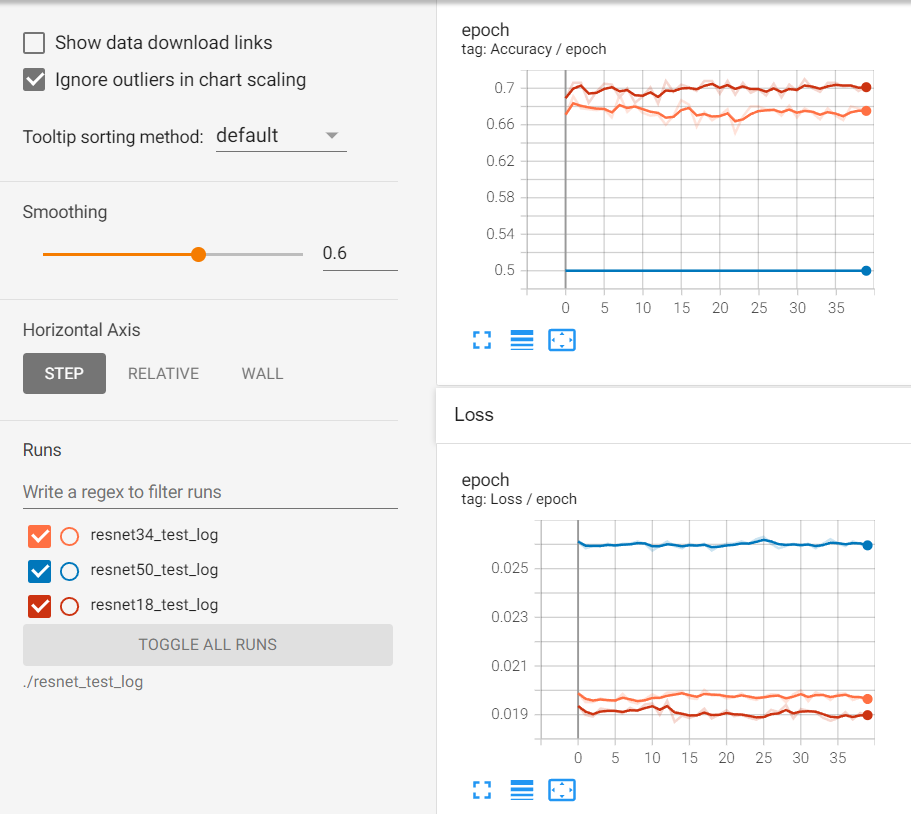
먼저, ResNet 50 모델이 제대로 학습되지 않는 문제에 대해 말씀드리겠습니다. ResNet 모델의 핵심은 shortcut connection을 통해 gradient가 잘 흐를 수 있도록 하는 것입니다. 이를 통해 깊은 네트워크에서도 학습이 잘 이루어질 수 있습니다. 그러나, 모델의 구조나 학습 방법에 따라 학습이 잘 이루어지지 않을 수 있습니다. 예를 들어, 학습률(learning rate)이 너무 크거나 작으면 모델이 제대로 학습되지 않을 수 있습니다. 또한, 데이터셋의 크기나 복잡도, 데이터 전처리 방법 등도 학습에 영향을 미칠 수 있습니다.
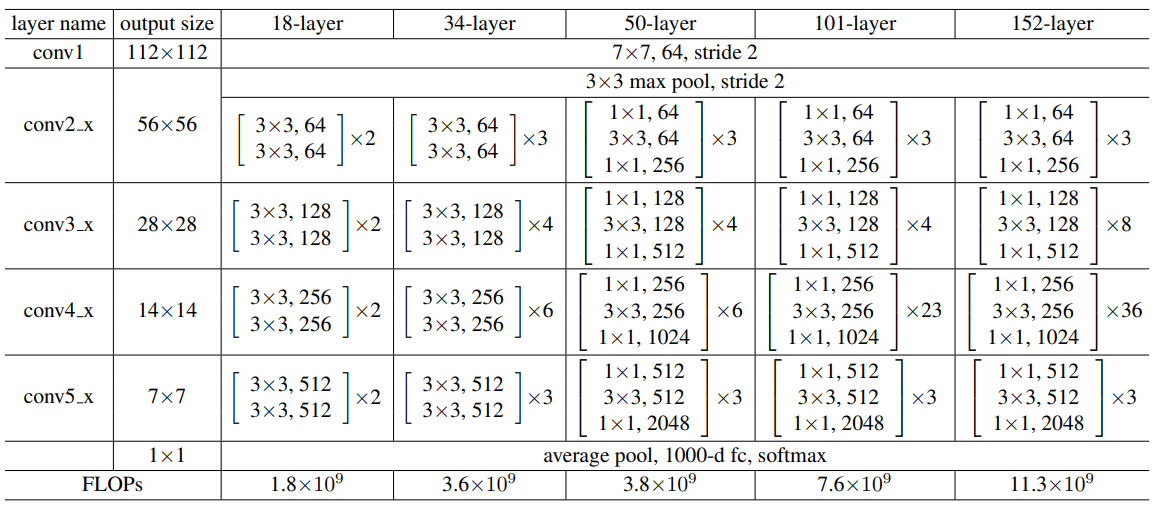
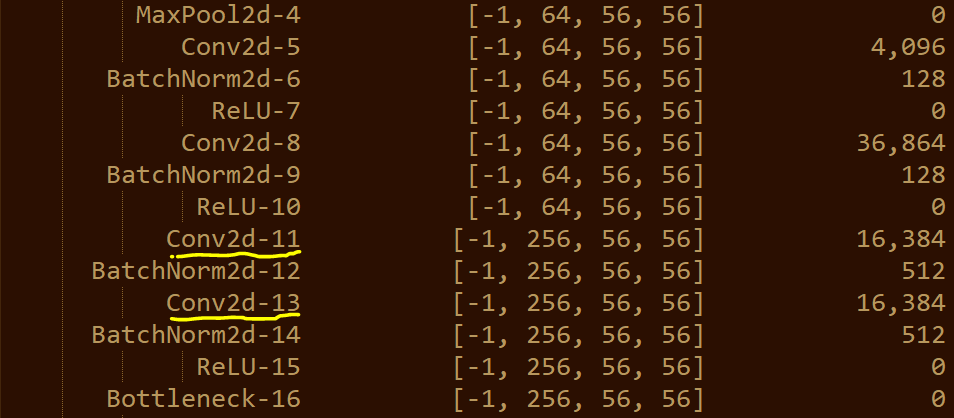
다음으로, torchvision에서 제공하는 ResNet 50 모델과 직접 구현한 모델의 구조가 다른 문제에 대해 말씀드리겠습니다. torchvision에서 제공하는 ResNet 모델은 원래의 ResNet 논문에서 제안된 구조를 따르고 있습니다. 그러나, 직접 구현한 모델의 구조가 다르다면, 이는 학습에 영향을 미칠 수 있습니다. 특히, ResNet 모델의 경우, 각 레이어의 출력 크기와 필터 수, stride 등이 잘 조정되어야 합니다. 이러한 요소들이 잘못 설정되면, 모델의 성능에 영향을 미칠 수 있습니다.
따라서, 직접 구현한 모델의 구조를 다시 확인하고, 필요하다면 torchvision에서 제공하는 ResNet 모델의 구조를 참고하여 수정해보시는 것을 추천드립니다. 또한, 학습률, 데이터 전처리 방법 등을 조절해보시는 것도 도움이 될 수 있습니다.
아래는 PyTorch에서 ResNet 모델을 구현하는 예제 코드입니다. 이 코드를 참고하여 직접 구현한 모델의 구조를 확인해보시기 바랍니다.
import torch
import torch.nn as nn
class BasicBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
out = self.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, num_blocks, num_classes=10):
super(ResNet, self).__init__()
self.in_channels = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
self.linear = nn.Linear(512, num_classes)
def _make_layer(self, block, out_channels, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
layers = []
for stride in strides:
layers.append(block(self.in_channels, out_channels, stride))
self.in_channels = out_channels
return nn.Sequential(*layers)
def forward(self, x):
out = self.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
def ResNet50():
return ResNet(BasicBlock, [3, 4, 6, 3])
더 자세한 내용은 PyTorch 공식 문서나 튜토리얼을 참고하시면 도움이 될 것입니다. 아래는 관련 링크입니다.
마지막으로, 질문에 대한 답변이 정확하지 않을 수도 있으니, 필요한 경우 추가적인 정보를 제공해주시면 감사하겠습니다.
- 답변이 어떠셨나요? 괜찮았다고 생각하신다면 아래
 를 한 번 눌러주시길 부탁드려요!
를 한 번 눌러주시길 부탁드려요!