Samba: Microsoft가 공개한 효율적인 무제한 컨텍스트 언어 모델 (Mamba + MLP + Sliding Window Attention + 고품질 Dataset)

들어가며 

Microsoft가 최근 공개한 새로운 언어 모델, Samba를 소개합니다. Samba는 단순하면서도 강력한 하이브리드 모델로, 무제한 컨텍스트 길이를 제공합니다. 특히, 효율적인 성능과 확장성을 자랑하며, 다양한 벤치마크에서 뛰어난 성과를 보여줍니다. 이 글을 통해 Samba의 주요 특징과 활용 방법을 자세히 살펴보세요. ![]()
Samba 소개
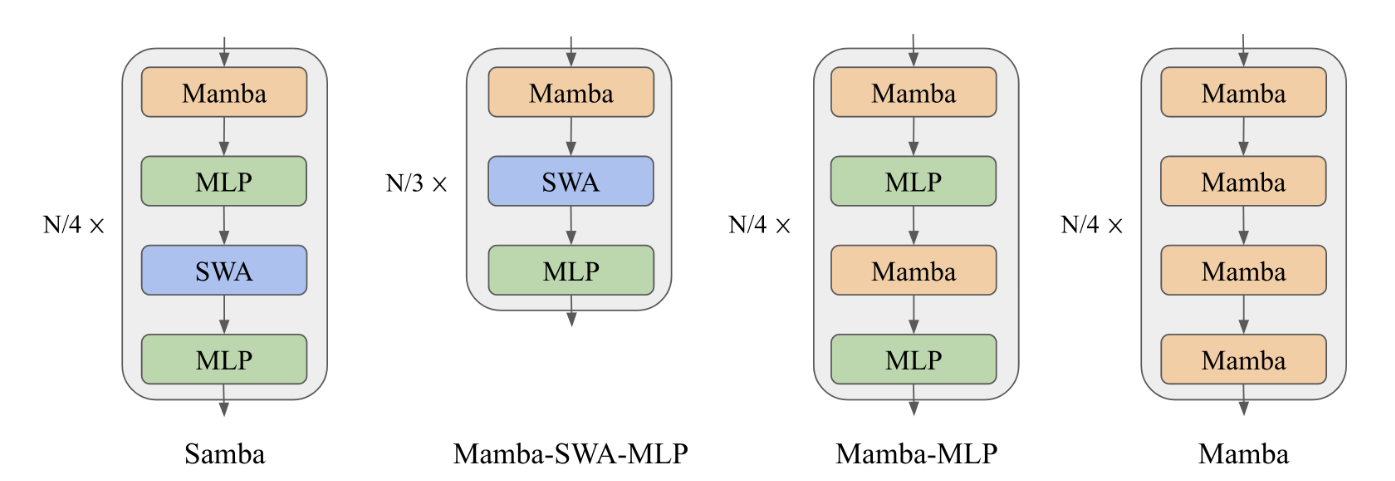
Samba는 Microsoft에서 개발한 최신 언어 모델로, Mamba, MLP, 슬라이딩 윈도우 어텐션, MLP 스태킹을 결합한 하이브리드 모델입니다. 이 모델의 가장 큰 특징은 무제한 컨텍스트 길이를 지원하면서도 선형 복잡도를 유지한다는 점입니다. 다음과 같이 매우 간단한 아키텍처를 갖췄습니다:
- Samba = Mamba + MLP + 슬라이딩 윈도우 어텐션 + 레이어 레벨의 MLP 스태킹.
Samba-3.8B 모델은 Phi3 데이터셋에서 3.2조 개의 토큰으로 학습되어, 주요 벤치마크(MMLU, GSM8K, HumanEval)에서 기존 Phi3-mini 모델을 큰 차이로 능가합니다. Samba는 최소한의 인스트럭션 튜닝만으로도 완벽한 장기 컨텍스트 검색 능력을 발휘하며, 이는 장기 컨텍스트 요약과 같은 다운스트림 작업에서도 뛰어난 성과를 제공합니다.
성능 비교


Samba는 여러 벤치마크에서 우수한 성능을 입증했습니다. 아래 표는 Samba-3.8B 모델과 Phi-3-mini-4K 모델의 성능을 비교한 것입니다.
| 모델 | MMLU | GSM8K | HumanEval | GovReport | SQuALITY |
|---|---|---|---|---|---|
| Phi-3-mini-4K-instruct | 68.8 | 82.5 | 58.5 | 14.4 | 21.6 |
| Samba-3.8B-instruct (preview) | 71.9 | 87.6 | 62.8 | 18.9 | 21.2 |
Samba는 MMLU에서 5-shot, GSM8K에서 8-shot CoT, HumanEval에서 0-shot pass@1, GovReport와 SQuALITY에서 ROUGE-L 점수를 기록했습니다.
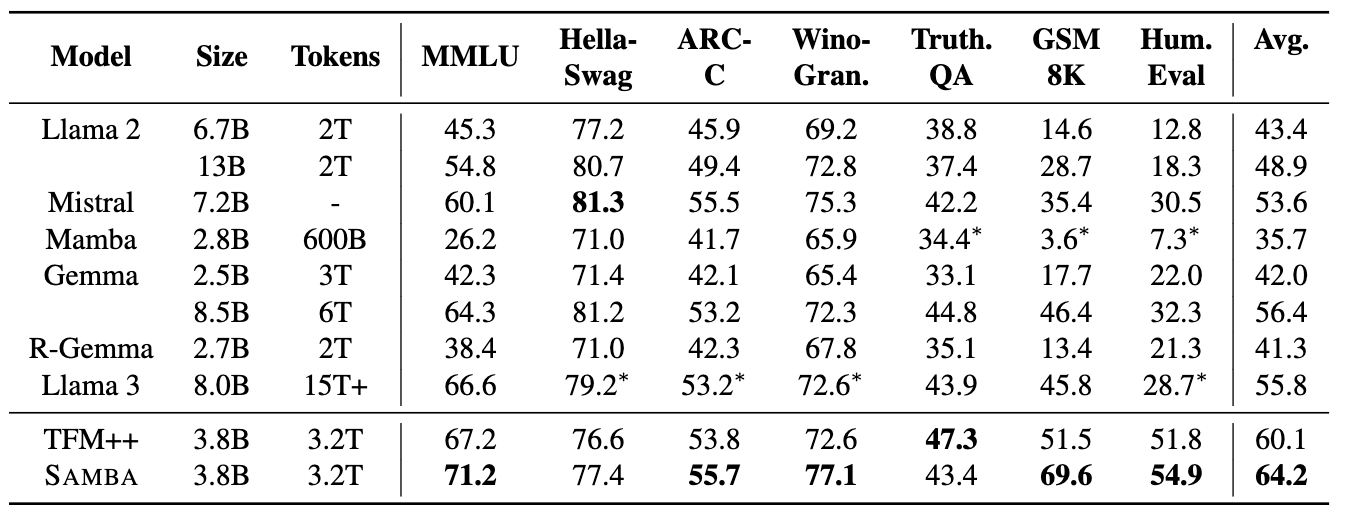
그 외 Samba-3.8B 모델에 대한 Downstream 성능을 다른 모델들과 비교한 것입니다. Llama-2, Mistral, Mamba, Gemma, R-Gemma(Recurrent-Gemma), Llama-3, TFM++ 등과 같은 모델들과 비교했을 때 다양한 벤치마크에서 가장 높은 평균 점수를 보였습니다:
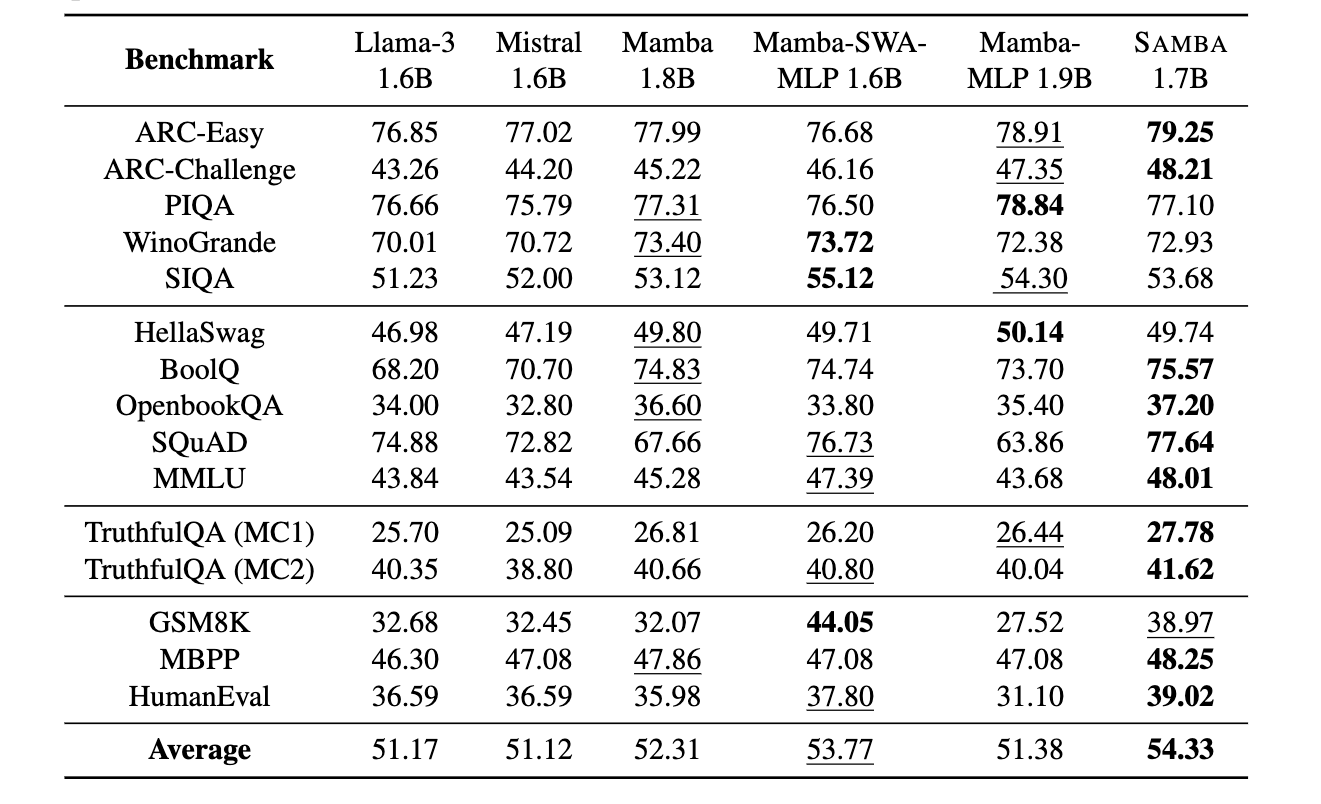
또한, Phi-2 데이터셋의 230B 토큰으로 학습한 아키텍처의 다운스트림 성능 평가로, 가장 좋은 결과는 굵은 글씨, 두번째로 좋은 결과는 밑줄로 표시했습니다.
주요 특징
-
무제한 컨텍스트 길이: Samba는 무제한 컨텍스트 길이를 지원하며, 선형 복잡도를 유지합니다.
-
하이브리드 아키텍처: Mamba, MLP, 슬라이딩 윈도우 어텐션, MLP 스태킹을 결합하여 효율적인 모델 구조를 제공합니다.
-
우수한 벤치마크 성능: MMLU, GSM8K, HumanEval 등 다양한 벤치마크에서 뛰어난 성과를 보여줍니다.
-
장기 컨텍스트 검색: 최소한의 인스트럭션 튜닝으로도 완벽한 장기 컨텍스트 검색 능력을 발휘합니다.
 Samba 논문
Samba 논문
 Samba GitHub 저장소
Samba GitHub 저장소
https://github.com/microsoft/Samba?utm_source=tldrai
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()