
Scraperr 소개
Scraperr는 개발자와 비개발자 모두를 위한 셀프 호스팅(Self-Hosted) 웹 스크래핑 플랫폼으로, “코드 한 줄 없이 웹사이트 데이터를 수집하고 관리할 수 있는 환경”을 제공합니다.
Scraperr 프로젝트는 브라우저 자동화 설정, 인증 토큰 관리, 비동기 요청 처리 등과 같은 웹 데이터 수집 과정의 복잡함을 단순화하고, FastAPI 기반 백엔드 와 Next.js 기반 프론트엔드 , MongoDB 데이터베이스 를 결합하여 완전한 웹스크래핑 생태계를 제공합니다.
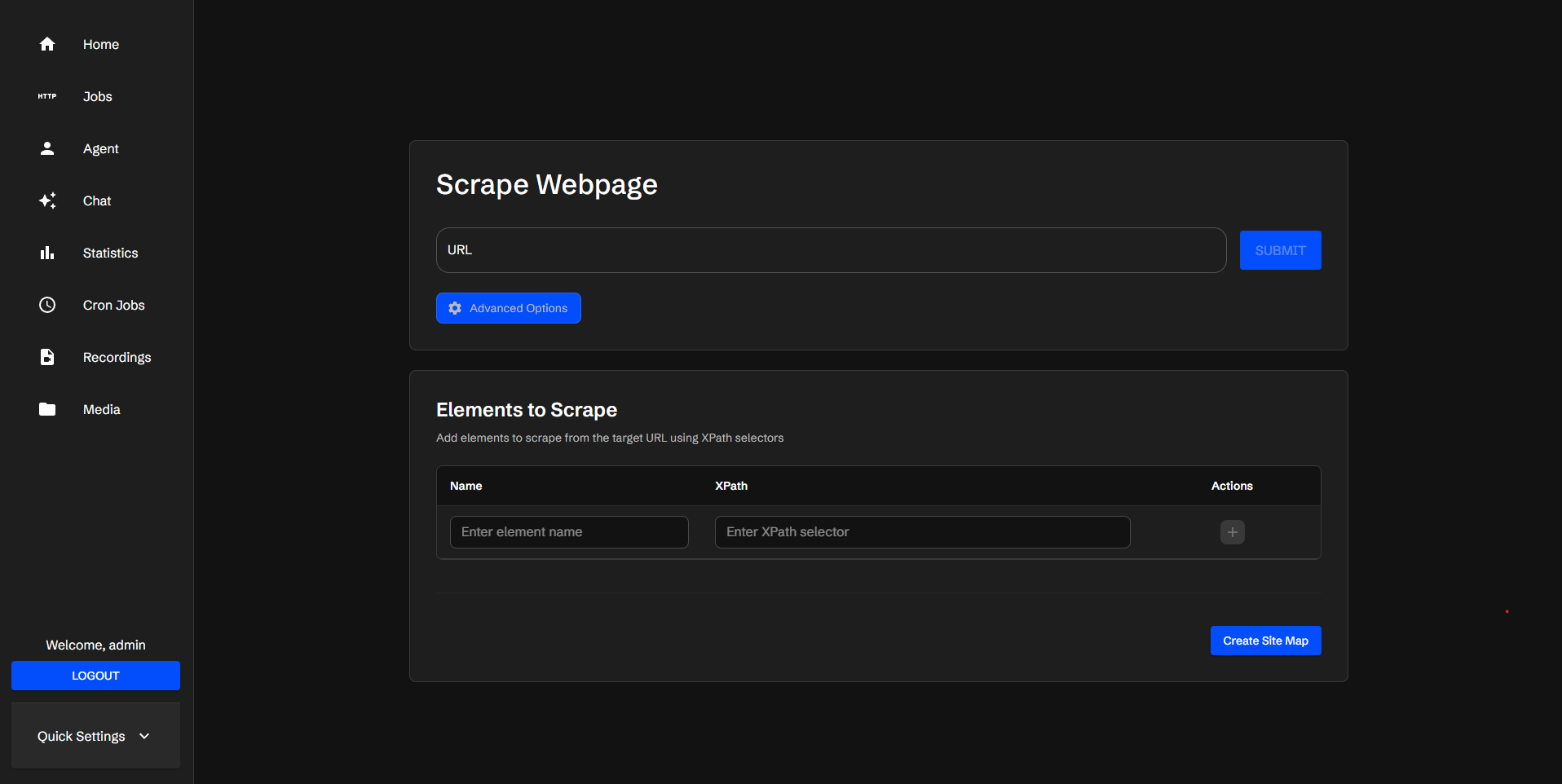
Scraperr의 가장 큰 특징은 코드를 작성하지 않고 직관적인 Web UI를 통해 클릭만으로 데이터 수집 과정을 구성할 수 있는 '시각적 관리형 스크래핑 환경'을 제공한다는 점입니다. 또한, API 중심 설계로, RESTful API를 통해 다른 애플리케이션이나 자동화 파이프라인에서도 Scraperr를 직접 호출할 수 있습니다. 즉, Scraperr는 단순한 크롤링 도구라기 보다는 데이터 수집·저장·활용을 하나로 통합한 플랫폼으로 볼 수 있습니다.
또한, Docker와 Helm 기반 배포를 지원하여, 개인 개발자나 기업이 자체 인프라 내에서 안정적으로 운영할 수 있도록 지원합니다.
XPath 개요
Scraperr는 웹 페이지에서 어떠한 데이터를 추출할지 정의하기 위해 XPath를 사용합니다. XPath (XML Path Language) 는 XML 또는 HTML 문서의 특정 요소(element)나 속성(attribute) 을 찾기 위한 경로 언어입니다. 즉, 웹페이지의 구조를 "트리(tree)" 구조로 인식하고, 그 안에서 원하는 데이터의 위치를 지정하는 방법을 제공합니다.
예를 들어, 다음과 같은 HTML 코드가 있을 때,
<div class="news">
<h2>오늘의 기술 뉴스</h2>
<p>AI 기반 개발 도구가 주목받고 있습니다.</p>
</div>
다음과 같은 XPath를 사용할 수 있습니다:
| 목적 | XPath | 결과 |
|---|---|---|
| 제목 추출 | //div[@class="news"]/h2/text() | “오늘의 기술 뉴스” |
| 본문 추출 | //div[@class="news"]/p/text() | “AI 기반 개발 도구가 주목받고 있습니다.” |
XPath는 브라우저의 개발자 도구 등을 사용하여 쉽게 추출할 수 있으며, 더 상세한 내용은 아래 링크들을 확인해주세요:
기존 웹 스크래핑 도구 대비 장점
Scraperr는 일반적인 파이썬 스크래퍼나 BeautifulSoup, Scrapy 같은 프레임워크와 달리 노코드 기반의 웹 인터페이스를 제공합니다. 즉, 코드를 작성하지 않아도 XPath 선택을 통해 데이터를 시각적으로 추출할 수 있습니다. 또한, 단일 페이지뿐만 아니라 도메인 전체를 순차적으로 크롤링(Spideing) 할 수 있는 기능이 내장되어 있어, Scrapy의 crawl 모드와 유사한 기능을 제공합니다.
다른 SaaS형 솔루션(예: Apify, Octoparse, ParseHub 등)은 클라우드 환경에서 데이터를 처리하지만, Scraperr는 셀프 호스팅(Self-hosted) 형태로 구동되기 때문에 데이터 프라이버시를 보장하며, 기업 내 폐쇄망 환경에서도 운용할 수 있습니다.
Scraperr의 주요 기능
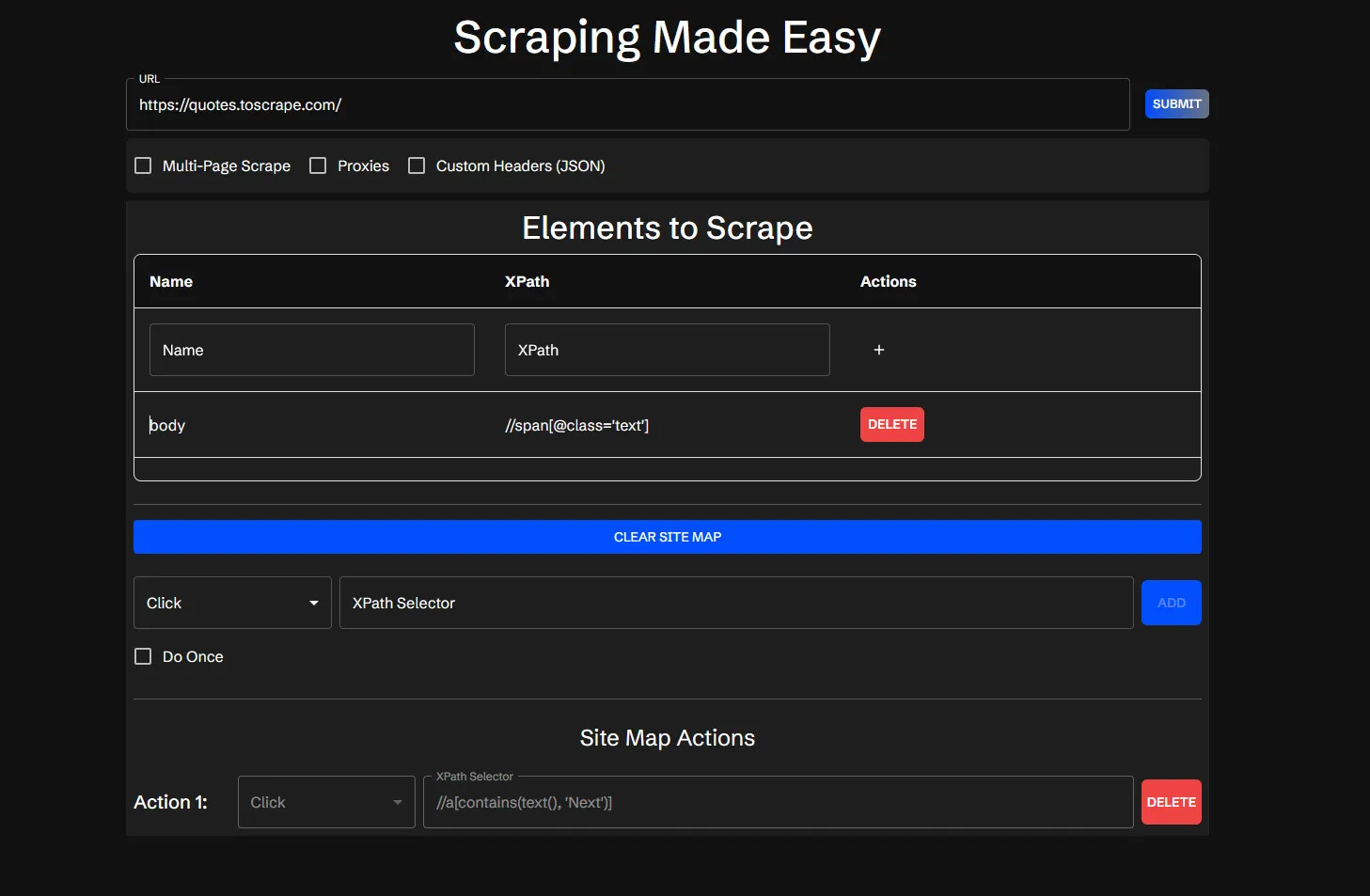
-
XPath 기반 데이터 추출: Scraperr는 XPath(경로 표현식) 기반의 데이터 추출을 지원합니다. 이를 통해 HTML 구조 내의 특정 요소를 정확하게 선택할 수 있으며, 클릭만으로 복잡한 CSS 선택자나 HTML 구조를 분석할 수 있습니다. 예를 들어, 뉴스 사이트에서 기사 제목, 날짜, 본문 등을 XPath로 선택해 구조화된 데이터로 추출할 수 있습니다.
-
큐 관리 시스템 (Queue Management): Scraperr는 여러 스크래핑 작업을 동시에 처리할 수 있도록 큐 시스템을 내장하고 있습니다. 사용자는 여러 URL을 한 번에 등록하고, 각 작업의 상태(pending, running, completed)를 대시보드에서 실시간으로 확인할 수 있습니다.
-
도메인 스파이더링 (Domain Spidering): 단일 URL만이 아니라, 동일 도메인 내의 모든 페이지를 자동으로 순회하며 데이터를 수집할 수 있습니다. 예를 들어 e-commerce 사이트의 모든 상품 페이지를 한 번에 수집하거나, 뉴스 사이트 전체를 탐색하는 데 유용합니다.
-
커스텀 요청 헤더 및 인증 지원: Scraperr는 JSON 형식으로 사용자 정의 HTTP 헤더를 설정할 수 있어, 로그인이 필요한 사이트나 인증 토큰을 사용하는 API 기반 페이지에서도 데이터를 수집할 수 있습니다.
-
미디어 자동 다운로드: Scraperr는 텍스트 데이터뿐 아니라 이미지, 동영상, PDF 등 다양한 미디어 파일을 자동으로 다운로드하고, 결과 파일과 함께 링크 및 경로 정보를 정리해 제공합니다.
-
데이터 시각화 및 내보내기: 수집된 데이터는 대시보드에서 표 형태로 시각화되며, 결과는 CSV, Markdown 형식으로 내보낼 수 있습니다. 이를 통해 데이터 분석가나 보고서 작성자는 별도의 추가 작업 없이 결과를 바로 활용할 수 있습니다.
-
알림 및 통합 기능: 작업 완료 시 이메일 또는 Discord 등 다양한 채널로 알림을 받을 수 있습니다. 또한 Scraperr의 REST API를 통해 다른 백엔드 시스템이나 AI 분석 파이프라인과 연동할 수 있습니다.
Scraperr 설치 및 시작하기
Scraperr를 설치하는 가장 쉬운 방법은 Docker를 사용하는 것입니다. 즉, Scraperr를 설치하려는 환경에는 Docker가 미리 설치 및 설정되어 있어야 합니다.
Docker가 준비되었다면, 먼저 Scraperr의 저장소를 복제(Clone)합니다:
git clone https://github.com/jaypyles/Scraperr.git
cd Scraperr
이후, Scraperr 저장소 내의 docker-compose.yml 파일을 편집하여 환경 변수들을 확인하고 수정합니다. 이 과정 없이 기본 값으로 실행도 가능하지만, 보안을 위해 SECRET_KEY는 반드시 변경할 것을 권장합니다:
scraperr:
environment:
- NEXT_PUBLIC_API_URL=http://scraperr_api:8000
- SERVER_URL=http://scraperr_api:8000
scraperr_api:
environment:
- SECRET_KEY=your_secret_key
- ALGORITHM=HS256
- ACCESS_TOKEN_EXPIRE_MINUTES=600
이제 make up 명령어를 통해 바로 실행 및 접근할 수 있습니다. 만약 로컬에서 실행했다면, http://localhost 로 접근할 수 있습니다:
make up
Scraperr는 기본적으로 make up 외 개발 환경, 배포 환경, 테스트 환경을 관리할 수 있는 다양한 명령어를 제공하며, 이에 대한 내용은 공식 문서 또는 make help 명령어를 통해 확인할 수 있습니다.
Docker Compose 설정은 프론트엔드, 백엔드, 데이터베이스를 자동으로 연결하며, Helm Chart를 이용하면 Kubernetes 환경에서도 손쉽게 배포할 수 있습니다. Helm 배포에 대한 자세한 가이드는 Helm Deployment Guide에서 확인할 수 있습니다.
스크래핑 작업 생성 과정
다음과 같은 과정을 거쳐 Scraperr에 새로운 스크래핑 작업을 생성할 수 있습니다:
-
URL 입력: 데이터를 수집하려는 웹사이트 주소를 입력합니다. Scraperr는 해당 페이지를 로드하고 데이터 구조를 분석하여 스크래핑을 준비합니다.
-
데이터 선택 (XPath 지정): 테이블 형식의 인터페이스가 나타나며, 추출할 데이터 요소와 XPath를 지정합니다.각 열은
name,xpath,type등으로 구성되며, 클릭만으로 쉽게 구성할 수 있습니다. -
작업 제출 (Job Submission): 설정이 완료되면 Submit 버튼을 클릭합니다. 작업은 큐(Queue)에 추가되며, 'Jobs Table'에서 진행 상태를 실시간으로 확인할 수 있습니다. 작업이 완료되면 [Download] 버튼을 눌러 CSV 파일로 데이터를 내려받을 수 있습니다.
-
결과 분석: 다운로드한 CSV 파일은 Excel, Google Sheets 등에서 바로 열어 확인해 볼 수 있으며, Scraperr의 AI 통합 기능을 통해 데이터 질의응답(Q&A)도 수행할 수 있습니다.
AI 통합 기능 (AI Integration)
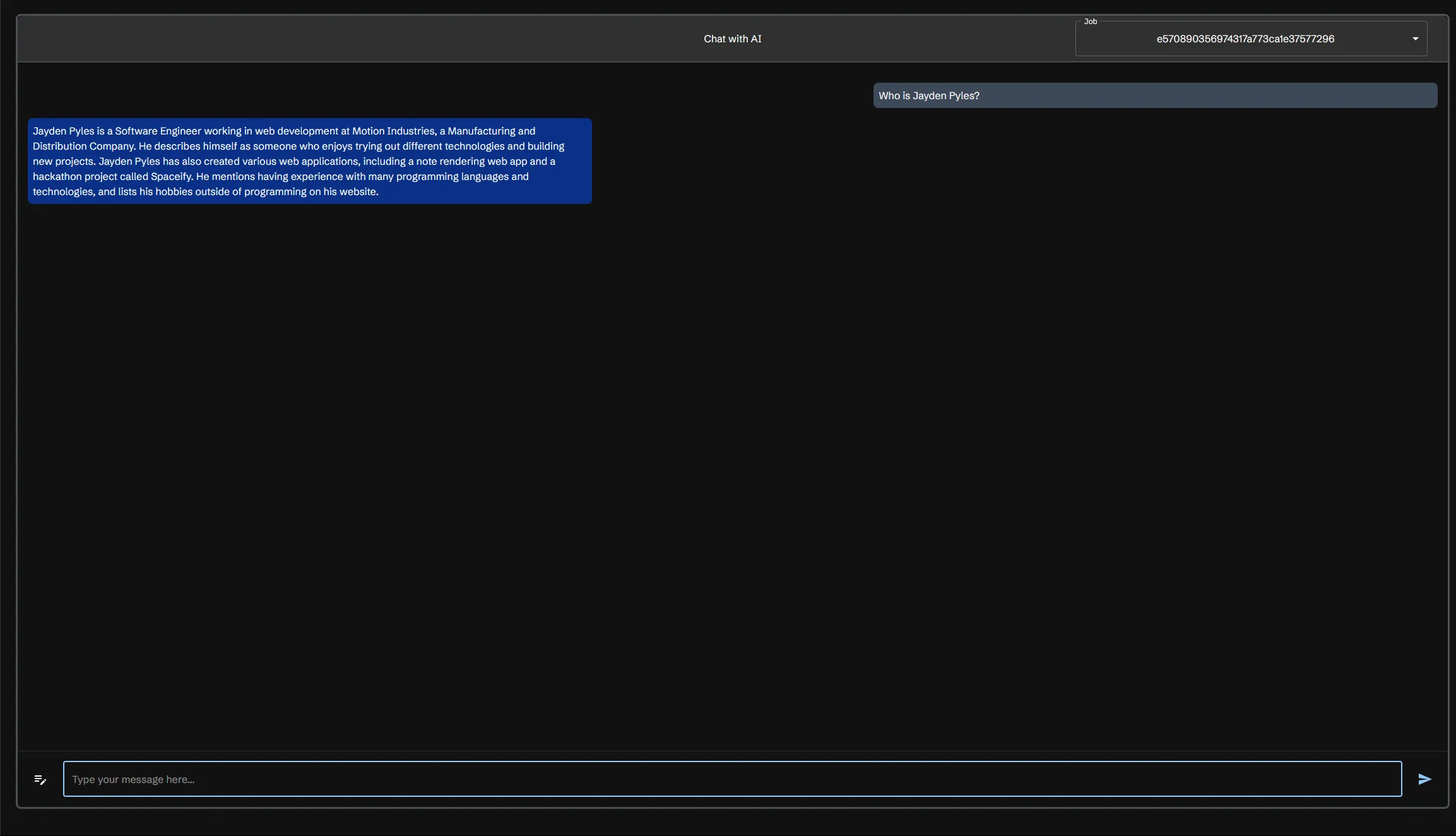
Scraperr는 단순히 데이터를 수집하는 데 그치지 않고, 수집된 데이터를 기반으로 AI 질의응답(Q&A)을 수행할 수 있는 기능을 제공합니다. 예를 들어, 스크래핑된 뉴스 데이터를 대상으로 "가장 많이 언급된 인물은 누구인가요?"와 같은 질문을 던지면 미리 설정한 외부 API 또는 로컬 모델에 질의하여 데이터를 분석하여 응답합니다.
이 기능을 사용하기 위해서는 docker-compose.yml 파일에 다음과 같은 환경 변수를 지정해야 합니다:
# OpenAI 사용 시
scraperr_api:
environment:
OPENAI_KEY: your_openai_api_key
OPENAI_MODEL: gpt-4o
# Ollama 사용 시
scraperr_api:
environment:
OLLAMA_URL: http://ollama:11434
OLLAMA_MODEL: phi3:latest
이 기능은 데이터 분석 자동화나 비즈니스 인텔리전스(BI) 시스템과의 연동에 매우 유용합니다. 설정 및 사용과 관련한 더 자세한 내용은 AI Integration Guide에서 확인할 수 있습니다.
법적·윤리적 가이드라인
Scraperr는 합법적이고 윤리적인 웹 데이터 수집을 위한 도구로, 사용자는 다음 지침을 반드시 따라야 합니다:
- robots.txt 준수: 크롤링을 하려는 대상 웹사이트의 허용 정책을 반드시 확인해야 합니다.
- 이용 약관 준수: 대상 사이트의 이용 약관(Terms of Service)을 살펴보고, 이를 위반하지 않도록 주의해야 합니다.
- 요청 제한 설정: 대상 사이트에 과도한 요청을 보내지 않도록 적절한 지연 시간(Delay)을 설정해야 합니다.
Scraperr는 이러한 원칙 하에 합법적인 데이터 자동화 환경을 구축하는 것을 목적으로 설계되었으며, Scraperr 제작자는 사용자의 오남용으로 발생한 문제에 대해 책임을 지지 않습니다.
라이선스
Scraperr 프로젝트는 MIT License 하에 배포됩니다. 상업적 사용, 수정, 재배포가 자유롭지만, 저작권 및 라이선스 명시 의무가 있습니다.
 Scraperr 공식 문서
Scraperr 공식 문서
 Scraperr 프로젝트 GitHub 저장소
Scraperr 프로젝트 GitHub 저장소
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()