
ScreenSuite 소개
최근의 멀티모달 대형 언어 모델(MLLM, Multimodal Large Language Model)의 발전은 단순 텍스트를 넘어 시각 정보를 이해하고 이를 기반으로 행동하는 능력까지 확장되고 있습니다. 이에 따라 사용자의 디지털 화면 상에서 직접적으로 동작하는 “GUI 에이전트” 기술이 주목받고 있습니다. 이러한 에이전트는 브라우저를 탐색하거나 앱을 조작하는 등 실질적인 사용자 인터페이스 상의 행동을 수행할 수 있어, RPA(Robotic Process Automation)나 디지털 어시스턴트 분야에서 활용 가능성이 큽니다.
그러나 아직까지 GUI 에이전트의 성능을 체계적으로 평가할 수 있는 공개 벤치마크는 부족한 상황이었습니다. 특히 다양한 화면 유형(웹, 모바일, 데스크탑)을 아우르고, 지각 능력부터 단일/다중 단계 행동 수행까지 포괄하는 평가 기준이 필요했습니다.
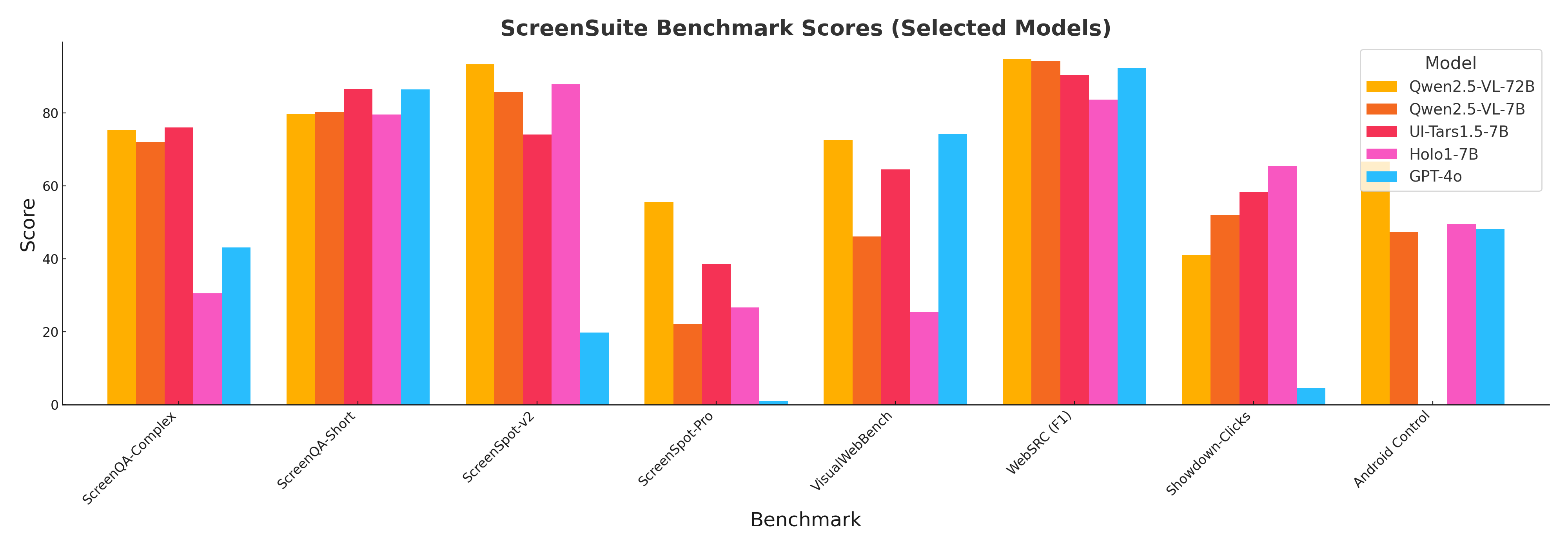
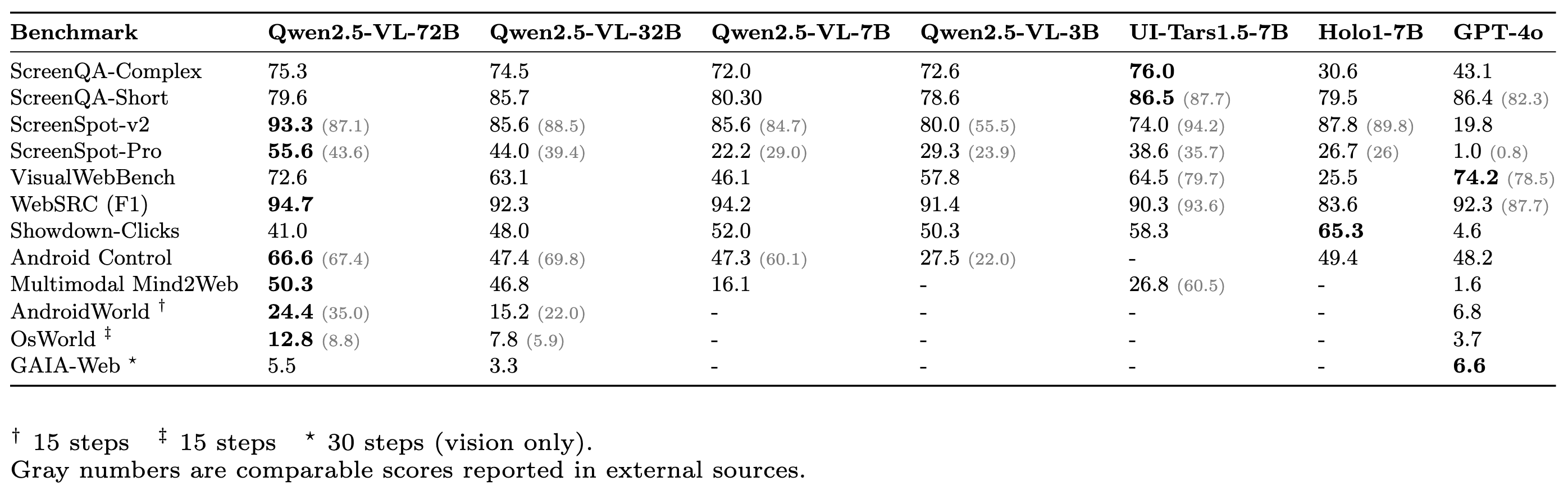
HuggingFace는 이러한 요구에 부응하여 ScreenSuite라는 통합 벤치마크 스위트를 공개했습니다. 이 프로젝트는 (GUI Agent가 아닌) GUI 에이전트를 구성하는 MLLM의 실제 능력을 평가하는 데 초점을 맞추고 있으며, 복잡한 에이전트 구현이 아니라 간단한 실행 기반으로 다양한 테스트를 수행합니다. MLLM이 얼마나 정밀하게 화면을 인식하고, 사용자 요청을 처리하며, 연속적인 상호작용을 수행할 수 있는지를 평가할 수 있는 중요한 도구입니다.
주요 벤치마크 구성
ScreenSuite는 GUI 환경에서 에이전트의 능력을 평가하기 위한 통합 벤치마크 컬렉션입니다. 평가 대상은 GUI 에이전트를 구성하는 대형 멀티모달 언어 모델이며, 단일 모델 기반 에이전트가 다양한 화면 내 작업을 수행할 수 있는지를 검증합니다. 벤치마크는 크게 세 가지 능력(지각, 단일 행동, 다중 단계 행동)에 따라 분류됩니다.
지각(Perception) 평가를 위한 벤치마크 (Grounding/Perception Benchmarks)
| Data Source | Evaluation Type | Description | Platform | Link |
|---|---|---|---|---|
| ScreenSpot | BBox + click accuracy | 웹 페이지 내에서 객체 위치 인식 및 클릭 예측 정확도 평가 | Web | HuggingFace |
| ScreenSpot v2 | BBox + click accuracy | 다양한 샘플로 인식 정확도를 높인 ScreenSpot의 후속 버전 | Web | HuggingFace |
| ScreenSpot-Pro | BBox + click accuracy | 복잡한 UI 환경에서도 클릭 예측과 객체 탐지를 수행 | Web | HuggingFace |
| Visual-WebBench | 멀티태스크 (OCR, QA 등) | 다양한 시각 인식 및 행동 태스크를 종합적으로 평가 | Web | HuggingFace |
| WebSRC | Web QA | 웹 기반 질의응답을 통해 정보 추출 능력 평가 | Web | HuggingFace |
| ScreenQA-short | Mobile QA | 모바일 UI에서 짧은 질문에 대한 정확한 응답을 요구 | Mobile | HuggingFace |
| ScreenQA-complex | Mobile QA | 더 복잡한 질문과 UI 맥락을 바탕으로 응답 정확도를 평가 | Mobile | HuggingFace |
| Showdown-Clicks | Click prediction | 클릭 위치 예측 정확도를 측정하여 시각-행동 연결 능력 검증 | Web | HuggingFace |
단일 단계 행동 평가(Single Step - Offline Agent Benchmarks)
정적인 환경에서 단 한 번의 행동으로 목표를 수행할 수 있는지를 평가합니다.
| Data Source | Evaluation Type | Description | Platform | Link |
|---|---|---|---|---|
| Multimodal-Mind2Web | Web navigation | 웹 탐색을 위한 단일 입력 기반 에이전트의 행동 정확도 평가 | Web | HuggingFace |
| AndroidControl | Mobile control | 안드로이드 환경에서의 단일 조작 테스트 | Mobile | GitHub |
다중 단계 행동 평가(Multi-step - Online Agent Benchmarks)
여러 단계를 거쳐야 하는 복잡한 작업 시나리오를 평가합니다.
| Data Source | Evaluation Type | Description | Platform | Link |
|---|---|---|---|---|
| Mind2Web-Live | URL matching | 다단계 웹 탐색 중 목표 URL 도달 여부로 모델 성능 평가 | Web | HuggingFace |
| GAIA | Exact match | 화면 상 작업을 얼마나 정확하게 수행했는지를 정답 기준으로 평가 | Web | HuggingFace |
| BrowseComp | LLM judge | 에이전트 수행 결과를 LLM이 직접 판정하여 평가 | Web | OpenAI |
| AndroidWorld | Task-specific | 모바일 앱에서 다단계 태스크를 수행하는 능력을 종합적으로 평가 | Mobile | GitHub |
| MobileMiniWob | Task-specific | 모바일 UI 상의 반복적 태스크 미니벤치마크 (AndroidWorld 포함) | Mobile | GitHub |
| OSWorld | Task-specific | 데스크탑 환경에서의 다양한 상호작용 과제 수행 능력 평가 | Desktop | GitHub |
라이선스
ScreenSuite 프로젝트는 Apache 2.0 라이선스로 공개 및 배포되고 있습니다. 상업적 사용에 제한이 없으며, 자유롭게 수정 및 재배포가 가능합니다.
 ScreenSuite GitHub 저장소
ScreenSuite GitHub 저장소
https://github.com/huggingface/screensuite
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()