- 이 글은 GPT 모델로 자동 요약한 설명으로, 잘못된 내용이 있을 수 있으니 원문을 참고해주세요!

- 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다!

세계를 더 가깝게 만드는, 멀티모달에서의 파운데이션 모델을 통한 음성 번역 (Bringing the world closer together with a foundational multimodal model for speech translation)
- 세계를 더 가깝게 연결해주는 기본 다중 모달 모델을 통한 음성 번역을 소개합니다.
개요

현대는 인터넷, 모바일 기기, 소셜 미디어 및 커뮤니케이션 플랫폼의 글로벌 확산 덕분에 이전보다 훨씬 더 연결되어 있습니다. 이러한 맥락에서 언어의 장벽 없이 정보를 소통하고 이해하는 능력은 점점 더 중요해지고 있습니다. AI 기술은 이러한 비전을 현실로 만들어 가고 있습니다.
주요 내용
SeamlessM4T 소개
Meta AI는 음성과 텍스트 간에 원활하게 번역하고 전사하는 기본 다중 언어 및 다중 작업 모델인 SeamlessM4T를 소개합니다. 이 모델은 다양한 언어에 대한 자동 음성 인식, 음성-텍스트 번역, 음성-음성 번역, 텍스트-텍스트 번역 및 텍스트-음성 번역을 지원합니다:
- 100여종의 언어에 대한 자동 음성 인식
- 100여종의 입력 및 출력 언어에 대한 음성-텍스트 번역
- 100여종의 입력 언어와 35종(+영어)의 출력 언어를 지원하는 음성 대 음성 번역
- 100여종의 언어에 대한 텍스트-텍스트 번역
- 텍스트 음성 변환, 100여종의 입력 언어와 35종(+영어)의 출력 언어 지원
- Automatic speech recognition for nearly 100 languages
- Speech-to-text translation for nearly 100 input and output languages
- Speech-to-speech translation, supporting nearly 100 input languages and 35 (+ English) output languages
- Text-to-text translation for nearly 100 languages
- Text-to-speech translation, supporting nearly 100 input languages and 35 (+ English) output languages
Open Science
Meta AI는 연구자와 개발자들이 이 작업을 기반으로 연구할 수 있도록 SeamlessM4T를 CC BY-NC 4.0으로 공개하였습니다.
또한, 총 27만 시간 분량의 음성 및 텍스트 정렬을 마이닝한 현재까지 가장 큰 개방형 멀티모달 번역 데이터셋인 SeamlessAlign의 메타데이터를 공개합니다. Lionbridge는 완벽한 음성 및 텍스트 문장 인코더 제품군인 SONAR와 멀티모달 데이터 처리 및 병렬 데이터 마이닝을 위한 라이브러리인 stopes를 통해 커뮤니티가 자체 단일 언어 데이터 세트에 대한 마이닝을 쉽게 수행할 수 있도록 지원합니다. 모든 연구 발전은 차세대 시퀀스 모델링 라이브러리인 fairseq2에 의해 지원됩니다.
도전과 성과
Meta AI의 도전은 모든 것을 할 수 있는 통합 다중 언어 모델을 만드는 것이었습니다. 이번에 소개하는 SeamlessM4T는 이 여정에서 중요한 한 걸음이라고 생각합니다. 저희의 단일 모델은 다른 언어를 사용하는 분들이 더 효과적으로 소통하실 수 있도록 온디맨드 번역을 제공합니다.
기존 연구와의 연계
Meta AI는 유니버설 번역기 SeamlessM4T를 만들기 위해 Meta 및 다른 연구자 분들의 이전 연구들을 기반으로 하였습니다. 작년에 우리는 200개 언어를 지원하는 텍스트-텍스트 기계 번역 모델인 NLLB(No Language Left Behind)를 출시했으며, 이후 위키백과에 번역 제공업체 중 하나로 통합되었습니다. 몇 달 후에는 널리 사용되는 문자 체계가 없는 호키엔(Hokkien)어를 위한 최초의 직접 음성 대 음성 번역 시스템인 유니버설 음성 번역기의 데모를 공개했습니다. 이를 통해 지도식 표현 학습의 획기적인 기술인 SpeechLASER에서 파생된 최초의 대규모 다국어 음성-음성 번역 데이터 세트인 SpeechMatrix를 개발했습니다. 올해 초에는 1,100개 이상의 언어에 대한 자동 음성 인식, 언어 식별 및 음성 합성 기술을 제공하는 대규모 다국어 음성(MMS: Massively Multilingual Speech)도 공유했습니다. SeamlessM4T는 이러한 모든 프로젝트에서 얻은 결과를 바탕으로 광범위한 음성 데이터 소스에 걸쳐 구축된 단일 모델에서 비롯된 다국어 및 다중 모드 번역 경험을 최첨단 결과와 함께 제공합니다.
저희는 이전의 모든 프로젝트에서 얻은 결과를 바탕으로 단일 모델에서의 다중 언어 및 다중 모달 번역 경험을 가능하게 하였습니다.
접근 방식
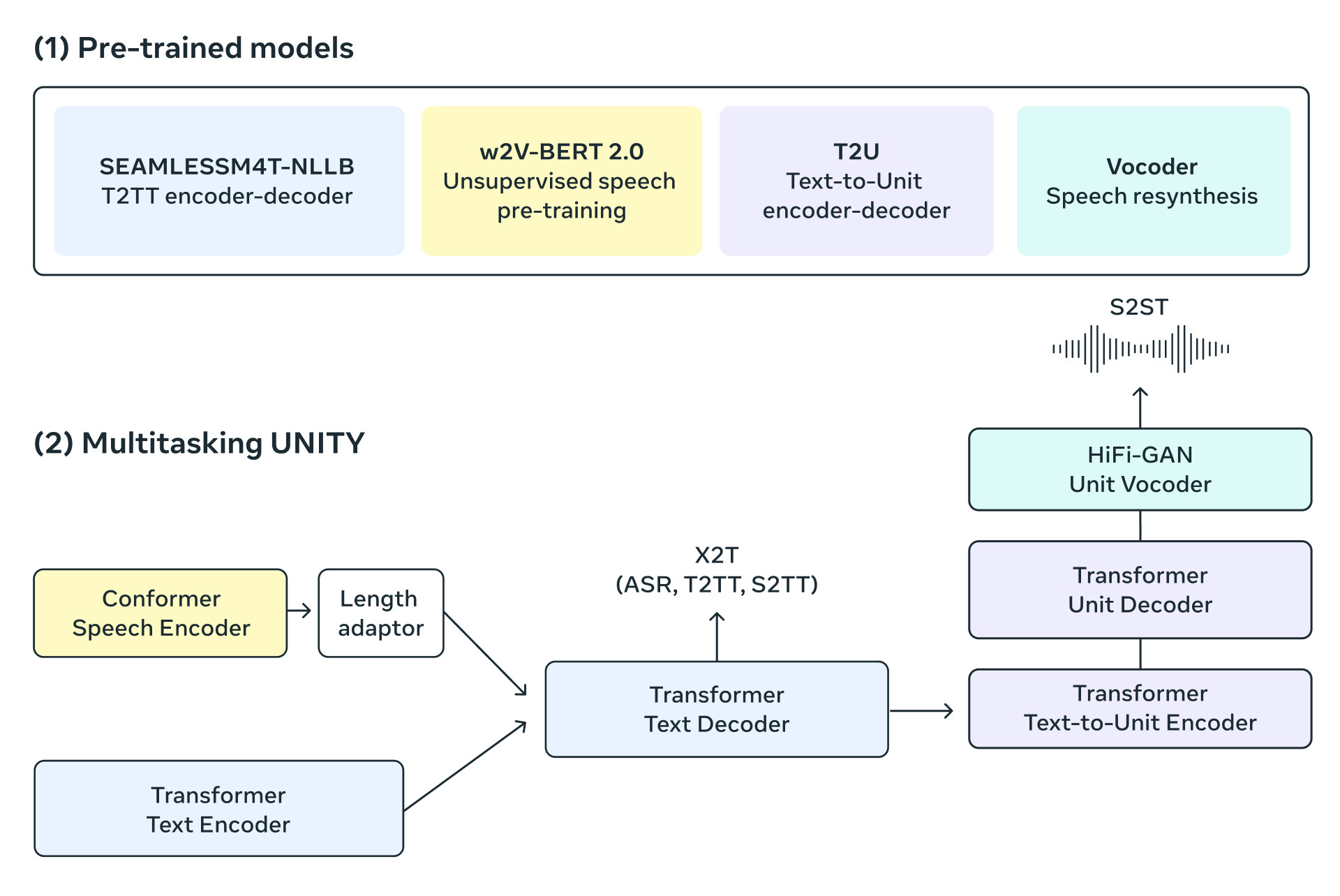
통합 모델을 구축하려면 가볍고 다른 최신 PyTorch 에코시스템 라이브러리와 쉽게 조합할 수 있는 시퀀스 모델링 툴킷이 필요합니다. 저희는 오리지널 시퀀스 모델링 툴킷인 fairseq을 재설계했습니다. 보다 효율적인 모델링 및 데이터 로더 API를 갖춘 fairseq2는 SeamlessM4T의 모델링을 강화하는 데 도움이 됩니다.
또한, 번역된 텍스트와 음성을 직접 생성할 수 있는 멀티태스크 UnitY 모델 구조를 사용합니다. 이 새로운 아키텍처는 기존의 UnitY model에서 제공하는 자동 음성 인식, 텍스트-텍스트, 텍스트-음성, 음성-텍스트, 음성-음성 번역도 지원합니다. 이러한 멀티태스크 UnitY 모델은 세 가지 주요 구성 요소로 이루어져 있습니다. 텍스트 및 음성 인코더는 100여개 언어의 음성 입력을 인식하는 작업을 수행합니다. 이후, 텍스트 디코더는 그 의미를 100여개 언어의 텍스트로 변환한 다음 텍스트-단위 모델을 통해 36개 음성 언어에 대한 개별 음향 단위로 디코딩합니다. 자체 감독 인코더, 음성-텍스트, 텍스트-텍스트 번역 구성 요소 및 텍스트-단위 모델은 모델의 품질을 개선하고 안정성을 학습하기 위해 사전 학습됩니다. 그런 다음 디코딩된 개별 단위는 다국어 HiFi-GAN 유닛 보코더를 사용하여 음성으로 변환됩니다.
성능 / 결과
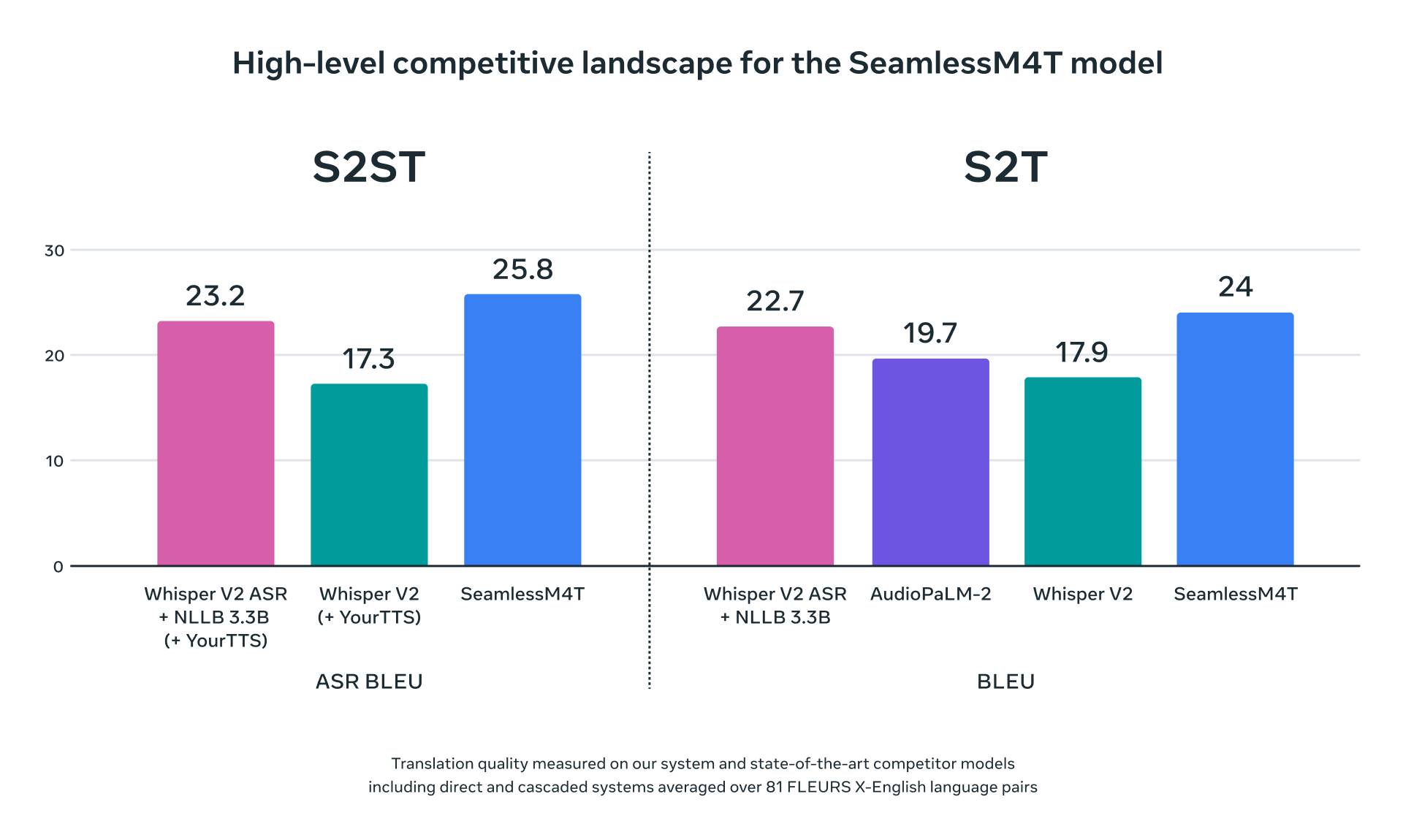
SeamlessM4T는 거의 100개의 언어에 대한 최첨단 결과를 달성하였으며, 자동 음성 인식, 음성-텍스트, 음성-음성, 텍스트-음성 및 텍스트-텍스트 번역에 대한 다중 작업 지원을 모두 단일 모델에서 제공하고 있습니다.
책임감 있는 개발
Meta의 AI 연구 개발은 책임감 있는 AI의 다섯 가지 원칙에 따라 책임감 있는 프레임워크를 따릅니다. 책임감 있는 AI에 대한 약속에 따라, 모델에서 어떤 영역이 민감할 수 있는지 이해하는 데 도움이 되는 독성 및 편향성에 대한 연구를 수행했습니다. 독성의 경우, 다국어 독성 분류기를 음성으로 확장하여 음성 입력 및 출력에서 독성 단어를 식별하는 데 도움을 주었습니다. 훈련 데이터에서 불균형한 독성을 필터링했습니다. 입력 또는 출력에 서로 다른 양의 독성이 포함된 경우 해당 훈련 쌍을 제거했습니다. 번역 시스템은 정확해야 하기에, Meta AI는 모델에서 나타날 수 있는 오류나 문제점을 줄이기 위해 이 영역에서 계속 연구하고 조치를 취하고자 합니다.
성별 편향은 결과가 특정 성별을 부당하게 선호하고 때로는 성별 고정관념을 따르는 것으로, 대규모 언어에서 평가하기 시작한 또 다른 영역입니다. 이를 위해 이전에 설계한 다국어 HolisticBias 데이터셋을 음성으로 확장하여 수십 개의 음성 번역 방향에서 성별 편향을 정량화할 수 있게 되었습니다.
이 기술에 대한 접근
논문
데모

GitHub 저장소

https://github.com/facebookresearch/seamless_communication
SeamlessM4T 모델
| Model Name | #params | checkpoint | metrics |
|---|---|---|---|
| SeamlessM4T-Large | 2.3B | metrics | |
| SeamlessM4T-Medium | 1.2B | metrics |
SeamlessAlign 데이터셋
 HuggingFace 데모
HuggingFace 데모
더 읽어보기
fairseq2
fairseq2는 연구자와 개발자에게 기계 번역, 언어 모델링 및 기타 시퀀스 생성 작업을 위한 빌딩 블록을 제공하는 차세대 시퀀스 모델링 구성 요소의 오픈 소스 라이브러리입니다.
https://github.com/facebookresearch/fairseq2
SONAR 및 BLASER 2.0
SONAR, 문장 수준의 다중모달 및 언어에 구애받지 않는 표현은 xsim 및 xsim++ 다국어 유사성 검색 작업에서 LASER3 및 LabSE와 같은 기존 문장 임베딩보다 성능이 뛰어난 새로운 다국어 및 -모달 문장 임베딩 공간입니다. SONAR는 다양한 언어에 대한 텍스트 및 음성 인코더를 제공합니다.
BLASER 2.0은 다중 모드 번역을 위한 최신 모델 기반 평가 메트릭입니다. BLASER의 확장 버전으로 음성과 텍스트를 모두 지원합니다. 소스 신호에서 직접 작동하므로 ASR-BLEU와 같은 중간 ASR 시스템이 필요하지 않습니다. 첫 번째 버전과 마찬가지로 BLASER 2.0은 입력 및 출력 문장 임베딩 간의 유사성을 활용합니다. SONAR는 BLASER 2.0의 기본 임베딩 공간입니다. 블레이저 2.0으로 평가를 실행하기 위한 스크립트는 SONAR 리포지토리에서 확인할 수 있습니다.
https://github.com/facebookresearch/SONAR
stopes
원활한 커뮤니케이션 프로젝트의 일환으로 stopes 라이브러리를 확장했습니다. 버전 1은 번역 모델을 위한 학습 데이터셋을 구축하기 위한 텍스트-텍스트 마이닝 도구를 제공했습니다. 버전 2는 대규모 음성 번역 모델 학습과 관련된 작업을 지원하기 위해 SONAR를 통해 확장되었습니다.
https://github.com/facebookresearch/stopes