연구 개요: SELECT와 ImageNet++ 소개
SELECT 소개

SELECT 프로젝트는 이미지 분류를 위한 다양한 데이터 큐레이션 전략을 체계적으로 비교하고 평가하기 위해 고안된 대규모 벤치마크입니다. 이 연구는 기존 데이터셋 ImageNet을 확장한 ImageNet++ 데이터셋을 활용해 여러 가지 큐레이션 전략의 성능을 평가하고, 데이터 수집과 구성 방법이 모델의 학습 효율성에 미치는 영향을 다각도로 분석합니다.
SELECT에서 측정하려고 하는 지표들은 다음과 같습니다:
-
기본 정확도(Base Accuracy): ImageNet 검증 데이터셋에서의 성능을 측정합니다.
-
분포 외 데이터(OOD, Out-of-Distribution) 견고성(Robustness): 모델이 새로운 환경에서 얼마나 잘 적응하는지 평가합니다.
-
전이 학습 성능: 사전 학습된 모델이 다른 다운스트림 태스크에 얼마나 잘 적응하는지 평가합니다.
-
자기 지도 학습 유용성: 자가 지도 학습에 데이터셋이 얼마나 효과적인지 측정합니다.
또한, 클래스 불균형 및 이미지 품질 같은 데이터셋의 특성을 분석하는 지표들이 추가적으로 제공됩니다.
ImageNet++ 소개

**ImageNet++**는 SELECT 벤치마크의 주요 데이터셋으로, ImageNet-1K의 다양한 변형을 포함하는 대규모 데이터셋입니다. ImageNet++는 서로 다른 큐레이션 전략으로 수집된 5개의 데이터셋 변형(shift)을 포함합니다.
- OI1000: OpenImages 데이터셋에서 군중 소싱으로 라벨링된 부분
- LA1000 (img2img): LAION 데이터셋에서 임베딩 기반 검색으로 선정된 이미지
- LA1000 (txt2img): LAION 데이터셋에서 텍스트 기반 검색으로 선정된 이미지
- SD1000 (img2img): Stable Diffusion 모델을 통해 생성된 이미지
- SD1000 (txt2img): 클래스 이름을 프롬프트로 사용해 생성된 이미지
데이터 큐레이션 전략과 주요 결과
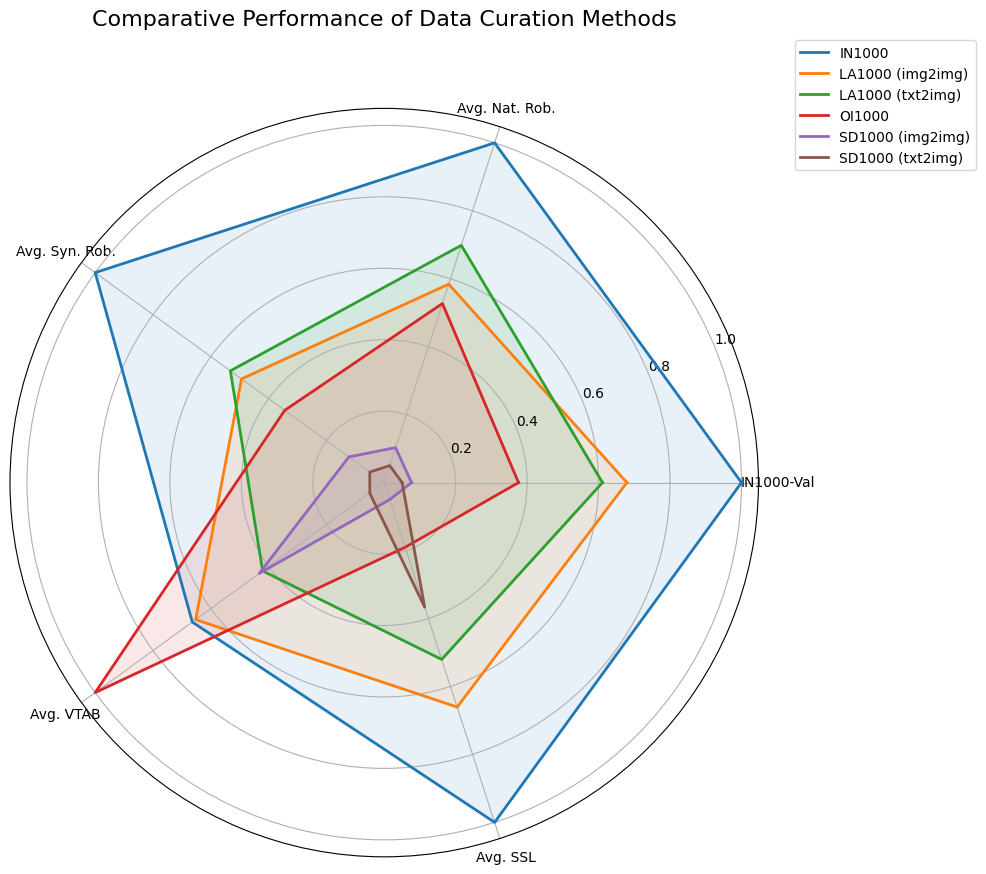
다양한 큐레이션 방법을 통해 얻은 주요 결과는 다음과 같습니다:
-
전문가 큐레이션의 성능 우수성: 최신 데이터 큐레이션 기법을 사용해도 기존 ImageNet의 전문가 큐레이션이 자동화된 방법보다 여전히 우수한 성능을 보였습니다.
-
임베딩 기반 검색의 효과: LAION 데이터셋(LA1000)의 임베딩 검색 방식이 합성 데이터 생성 방식보다 안정적으로 높은 성능을 보였습니다.
-
작은 데이터셋의 경쟁력: 데이터 크기보다는 큐레이션 품질이 모델 성능에 더 중요한 요소로 작용했으며, LA1000 (img2img)와 같은 작은 데이터셋이 종종 더 큰 데이터셋보다 나은 성능을 보였습니다. 또한, OI1000 데이터셋은 클래스 불균형 문제로 인해 자동화된 방법보다 성능이 떨어졌습니다.
-
이미지 기반 접근법의 우수성: 이미지 중심의 큐레이션 방법이 텍스트 기반 큐레이션 방법보다 일관되게 더 나은 성능을 보였습니다.
실험 결과와 분석
130개 이상의 모델을 사용해 다양한 큐레이션 전략을 실험한 결과는 다음과 같습니다:
-
고비용 큐레이션을 대체하는 저비용 방법의 한계: 자동화된 저비용 큐레이션 전략은 ImageNet-1K의 전문가 큐레이션을 능가하지 못했습니다.
-
라벨 불균형의 문제: 군중 소싱 방식으로 라벨링된 OI1000 데이터셋은 다른 방법에 비해 성능이 낮았으며, 이는 클래스 불균형 문제와 관련이 있었습니다.
-
임베딩 기반 검색의 잠재력: 임베딩 기반 검색은 비용 대비 효율적인 방법으로, 합성 데이터 생성보다 안정적이었습니다.
-
크기와 품질의 상관관계: 작은 데이터셋이더라도 큐레이션 품질이 높을 경우 더 큰 데이터셋을 능가할 수 있음을 보여줍니다.
향후 연구 방향 및 제한사항
이 연구는 데이터 큐레이션 방법에 대한 초기 분석을 제시하며, 향후 개선 방향으로 다음을 제안합니다:
-
저비용 큐레이션 기법의 개선: 전문가 큐레이션에 필적할 수 있는 효율적인 저비용 큐레이션 방법의 개발 필요성.
-
클래스 불균형 해결: 라벨 불균형이 모델 성능에 미치는 영향을 해결하기 위한 개선된 큐레이션 기법 개발.
-
이미지 및 라벨 품질 지표 개선: 현재의 이미지와 라벨 품질 지표가 실제 모델 성능과 큰 상관이 없다는 점을 개선해야 할 필요성.
 SELECT 프로젝트 홈페이지
SELECT 프로젝트 홈페이지
 SELECT 논문
SELECT 논문
 SELECT GitHub 저장소
SELECT GitHub 저장소
https://github.com/jimmyxu123/SELECT
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()