
Seoul World Model 소개
최근 인공지능 분야에서는 텍스트나 이미지를 기반으로 동적인 가상 세계를 생성하는 월드 모델(World Model) 연구가 활발히 진행되고 있습니다. 기존의 생성형 월드 모델들은 물리 법칙을 모사하고 객체와 상호작용이 가능한 환경을 만들어내지만, 그 배경이 되는 공간 자체는 모델이 전적으로 상상해 낸 인공적인 가상 환경이라는 근본적인 한계를 지니고 있었습니다. 즉, 주어진 초기 시작 이미지 너머에 존재하는 거리나 건물 등의 기하학적 구조는 모두 AI가 자체적인 추론만으로 무작위로 지어낸 결과물이었습니다.
이러한 배경 속에서 네이버 AI 랩(NAVER AI Lab), 카이스트(KAIST), 서울대학교(SNU) 연구진은 완전히 새로운 접근 방식을 제시하며 실제 존재하는 도시 환경에 기반한 비디오 시뮬레이션 모델을 개발했습니다. 이들이 발표한 Seoul World Model은 상상 속의 공간이 아닌, 우리에게 친숙한 현실 속 서울의 거리를 있는 그대로 렌더링하고 탐험할 수 있게 해주는 혁신적인 시스템입니다.
Seoul World Model은 단순히 짧은 영상을 단편적으로 생성하는 것을 넘어, 수 킬로미터에 달하는 실제 도시의 궤적을 따라 일관된 비디오를 매끄럽게 생성할 수 있는 능력을 자랑합니다. 연구진은 수백만 장에 달하는 서울의 스트리트 뷰(Street-View) 이미지 데이터베이스에 최근 AI 업계의 핵심 기술로 자리 잡은 검색 증강 생성(Retrieval-Augmented Generation, RAG) 방식을 접목하여 이 난제를 해결했습니다.
사용자가 지도상에서 특정 지리적 위치와 카메라 이동 경로를 지정하면, 모델이 해당 위치 주변의 스트리트 뷰 이미지를 실시간으로 검색하고 이를 바탕으로 시각적, 기하학적 일관성을 엄격히 유지하며 영상을 생성합니다. 이를 통해 누적되는 렌더링 오류나 배경의 무너짐 없이 긴 시간 동안 고품질의 영상을 생성하는 것이 가능해졌으며, 단순한 전진 주행뿐만 아니라 인도 걷기, 모퉁이 돌기, 고속도로 주행 등 자유로운 형태의 내비게이션을 지원하여 마치 오픈 월드 비디오 게임을 하듯 도시를 탐험하는 경험을 제공합니다.
뿐만 아니라, 이 모델은 텍스트 프롬프트를 통한 정교한 시나리오 제어 기능까지 갖추어 개발자와 영상 창작자들에게 무한한 활용 가능성을 열어주고 있습니다. 사용자는 익숙한 서울의 실제 거리를 배경으로 '거대한 파도가 도로를 덮치는 모습'이나 '고층 빌딩 사이에 고질라가 나타난 상황' 등 원하는 모든 상상 속 이벤트를 텍스트 입력만으로 현실의 맵 위에 자연스럽게 구현해 낼 수 있습니다.
엔비디아(NVIDIA)의 Cosmos Predict 2.5를 기반으로 파인튜닝된 이 시스템은 실제 수집된 자율주행 데이터와 언리얼 엔진(Unreal Engine) 기반의 합성 데이터를 함께 학습하여 카메라 움직임의 제약을 크게 극복했습니다. 실세계 기반의 정밀한 렌더링 기술과 텍스트 제어의 유연성을 동시에 확보한 Seoul World Model은 향후 자율주행 시뮬레이션, 메타버스 구축, 차세대 영상 콘텐츠 제작 등 다양한 IT 및 AI 산업 생태계에서 매우 중요한 기반 기술로 활약할 것으로 기대됩니다.
기존 생성형 월드 모델과의 비교
기존의 생성형 비디오 월드 모델들은 객체의 역동적인 움직임이나 날씨 변화 등 상호작용이 가능한 환경을 시뮬레이션하는 데에는 뛰어난 성능을 보였습니다. 그러나 이러한 선행 모델들은 본질적으로 시각적 그럴싸함을 추구할 뿐, 모든 콘텐츠를 전적으로 '상상'하여 채워 넣는 인공적인 가상 환경 내에서만 동작합니다. 출발선에 해당하는 초기 이미지가 주어졌을 때, 그 너머에 있는 보이지 않는 거리의 구조나 먼 배경은 전적으로 모델의 자율적인 추론에 의존하여 생성되므로 실제 물리적 공간의 구조와는 전혀 무관한 결과물을 내놓게 됩니다.

반면, Seoul World Model은 '실제 존재하는 물리적 환경'인 서울에 시뮬레이션의 기반을 단단히 고정시킨다는 점에서 결정적인 차별성을 가집니다. 지리적 좌표와 카메라 액션을 바탕으로 수백만 장 규모의 실제 스트리트 뷰 데이터베이스에서 인접한 이미지를 검색하여 비디오 생성 과정에 개입시키는 검색 증강 생성(RAG) 아키텍처를 도입했습니다. 이를 통해 모델이 임의로 배경의 레이아웃을 지어내는 현상을 차단하고, 실제 해당 위치의 외관과 뼈대에 생성되는 비디오 청크(Chunk)를 앵커링(Anchoring) 시킵니다. 그 결과, 공간적으로 매우 충실하며 수백 미터에서 수 킬로미터에 이르는 긴 궤적에서도 오류의 누적 없이 놀라운 일관성을 유지할 수 있게 되었습니다.
Seoul World Model 핵심 기술 및 아키텍처
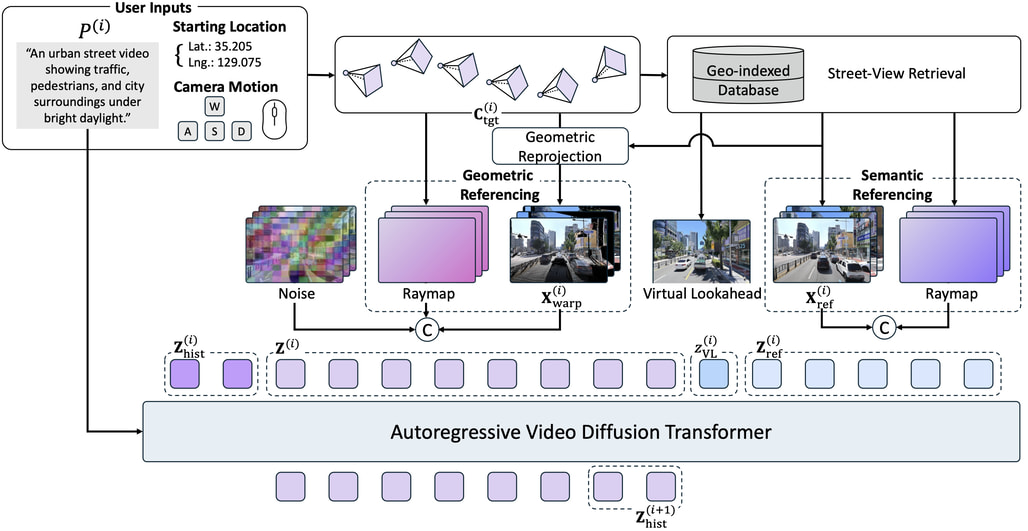
스트리트 뷰 데이터베이스 기반의 월드 모델 RAG
Seoul World Model의 아키텍처를 관통하는 가장 핵심적인 특징은 검색 증강 생성(RAG) 파이프라인의 도입입니다. 비디오의 특정 구간을 생성할 때 사용자의 지리적 좌표, 카메라 액션, 그리고 텍스트 프롬프트가 주어지면, 시스템은 지리 정보가 색인된 대규모 스트리트 뷰 데이터베이스에서 가장 가까운 이미지들을 신속하게 검색합니다.
이렇게 검색된 참조 이미지들은 다음과 같은 두 가지 상호 보완적인 경로를 통해 모델의 비디오 생성 조건으로 작동합니다:
-
기하학적 참조 (Geometric Referencing): 깊이(Depth) 기반 투영 필터링과 스플래팅(Splatting) 기법을 활용하여 가장 가까운 참조 이미지를 사용자가 위치한 목표 시점(Target Viewpoint)으로 변환시킵니다. 이는 생성될 도시 공간의 전반적인 기하학적 레이아웃 단서를 제공하는 역할을 합니다.
-
의미론적 참조 (Semantic Referencing): 원본 참조 이미지를 트랜스포머(Transformer)의 잠재(Latent) 시퀀스에 직접 주입합니다. 이를 통해 모델은 생성 과정에서 여러 참조 이미지 전반에 걸친 세밀한 외관 디테일과 텍스처에 주의(Attention)를 기울일 수 있게 됩니다.
학습 데이터의 구성과 교차 시간 페어링 (Cross-Temporal Pairing)
Seoul World Model은 서울 전역에서 수집된 120만 장의 실제 파노라마 이미지와 언리얼 엔진 기반 CARLA 시뮬레이터에서 추출한 431,500m² 규모의 도시 1만 개 합성 비디오 데이터쌍을 결합하여 정교하게 학습되었습니다.

특히, 학습 과정에서 동일한 시점의 이미지만을 사용할 경우 발생할 수 있는 '동적 객체(예: 지나가는 차량, 보행자)의 시각적 유출 현상'을 방지하기 위해 교차 시간 페어링(Cross-Temporal Pairing) 기법을 활용했습니다.
이는 생성해야 할 타겟 영상과 서로 다른 시간대에 촬영된 참조용 스트리트 뷰 이미지를 의도적으로 짝지어 모델을 학습시키는 방식입니다. 시간적 분리를 강제함으로써 모델은 일시적으로 머무는 객체들을 무시하고, 도로망이나 건물 같은 영구적이고 변하지 않는 공간의 기하학적 구조에만 온전히 집중하도록 유도됩니다.
카메라 궤적 한계 극복을 위한 뷰 보간 및 합성 데이터 활용
일반적으로 주행 차량에 장착된 카메라로 수집된 스트리트 뷰 데이터는 보통 5~20미터 간격으로 희소하게(Sparse) 수집되며, 그 궤적 또한 도로 중앙으로만 제한된다는 뚜렷한 한계가 있습니다.

연구진은 이를 두 가지 방법으로 해결했습니다.
-
스트리트 뷰 보간 (View Interpolation 파이프라인): 띄엄띄엄 존재하는 스트리트 뷰 키프레임들 사이의 빈틈을 부드럽게 연결하기 위해, 3D VAE의 시간적 보폭(Temporal Stride)에 맞춘 '간헐적 정지 프레임(Intermittent Freeze-Frame)' 전략을 사용하여 매끄럽게 이어지는 연속적인 학습 비디오를 합성해 냈습니다.
-
다양한 카메라 경로를 위한 합성 데이터: 오직 자동차 전진 주행 데이터에만 모델이 과적합되는 것을 막기 위해 CARLA 시뮬레이터를 적극 활용했습니다. 보행자 시점(인도, 횡단보도), 차량 시점(고속도로, 도심), 그리고 충돌 없는 자유 카메라 시점 등 3가지 궤적 유형의 합성 데이터를 추가했습니다. 그 결과, 추론 시 어떤 형태의 임의의 카메라 움직임이 주어지더라도 안정적으로 비디오를 생성해 낼 수 있는 강력한 일반화 능력을 확보했습니다.
긴 궤적 생성을 안정화하는 가상 룩어헤드 싱크 (Virtual Lookahead Sink)
기존의 자기회귀(Autoregressive) 방식 비디오 생성 모델들은 생성 궤적이 길어질수록 오류가 점진적으로 누적되어 품질이 무너지는 고질적인 약점을 안고 있었습니다. 특히 초기 프레임에 고정된 정적 어텐션 싱크(Static Attention Sink)를 사용하는 기존 방식들은 카메라가 출발 지점에서 멀리 이동할수록 그 가이드 영향력이 현저히 약해졌습니다.
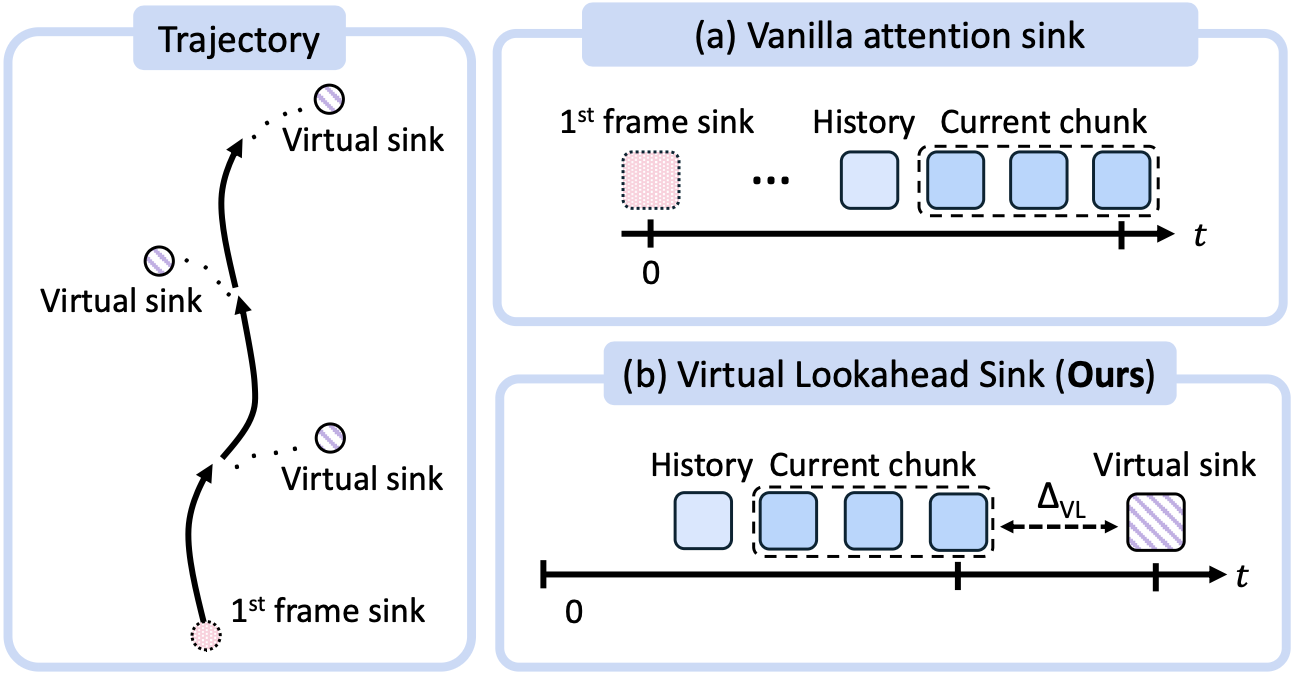
연구진은 이를 해결하기 위해 **가상 룩어헤드 싱크(Virtual Lookahead Sink)**라는 새로운 동적 메커니즘을 제안했습니다. 이 시스템은 카메라가 향후 이동하게 될 미래 목적지에 위치한 가장 가까운 스트리트 뷰 이미지를 동적으로 검색하여, 이를 깨끗하고 오류가 없는 가상의 미래 '앵커(Anchor)'로 지정합니다.
각 비디오 청크를 새롭게 생성할 때마다 이 미래 위치의 앵커 이미지에 지속적으로 재고정(Re-grounding)시킴으로써, 수백 미터 이상 뻗어 나가는 긴 궤적에서도 화질 저하나 물리적 구조의 붕괴 없이 비디오 품질을 안정적으로 견인해 냅니다.
라이선스
현재 Seoul World Model 프로젝트의 소스 코드 및 모델 가중치(Weights)는 내부 검토 및 정리 중으로 아직 공식적인 라이선스 조항이 명시되지 않았으나, 향후 공식 GitHub 저장소를 통해 순차적으로 공개될 예정입니다.
 Seoul World Model 프로젝트 홈페이지
Seoul World Model 프로젝트 홈페이지
 Seoul World Model 관련 논문
Seoul World Model 관련 논문
 Seoul World Model 프로젝트 GitHub 저장소 (공개 예정)
Seoul World Model 프로젝트 GitHub 저장소 (공개 예정)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()