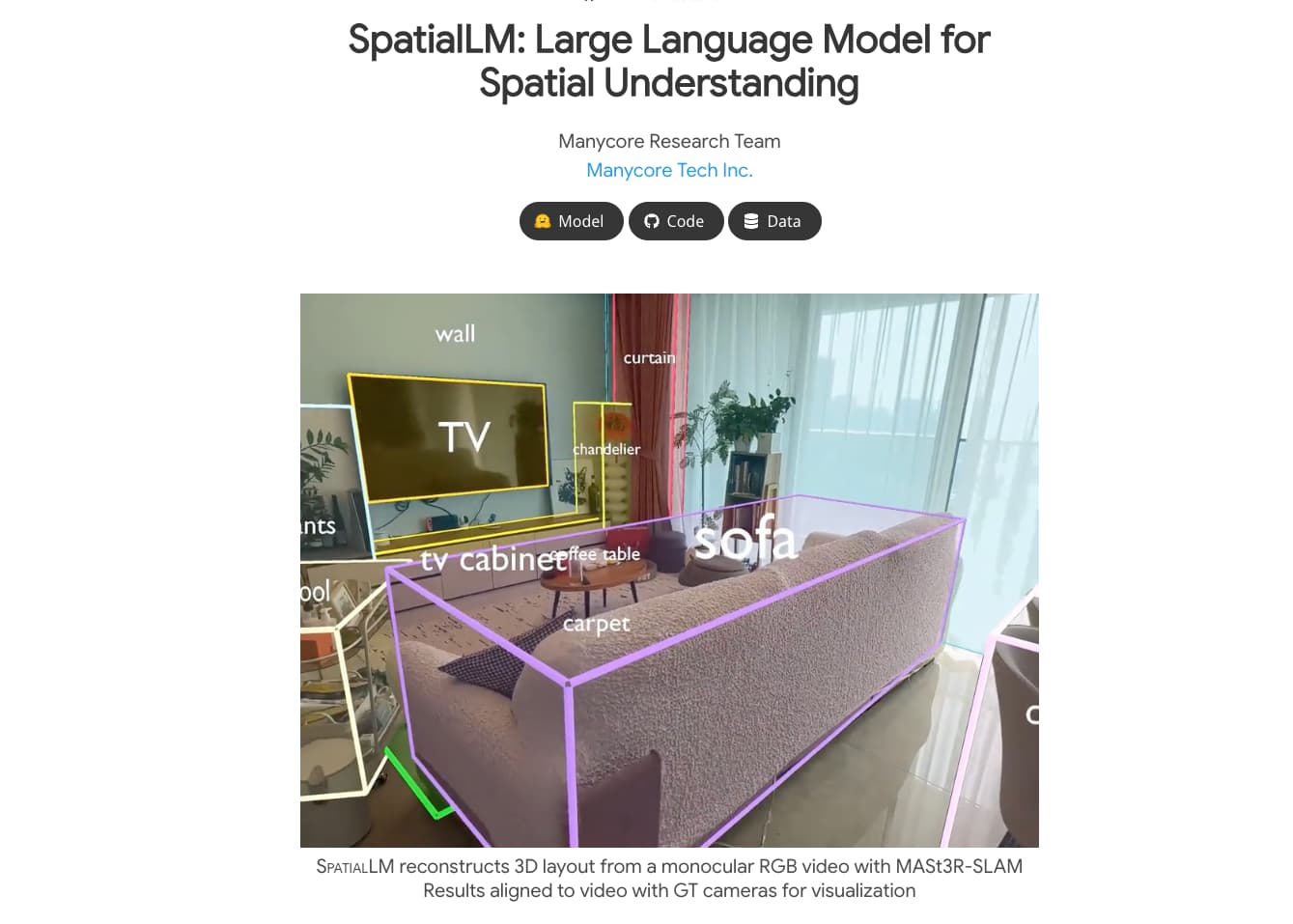
SpatialLM 소개
SpatialLM은 3D 포인트 클라우드를 입력받아 구조화된 3D 장면 정보를 출력할 수 있는 대규모 언어 모델(LLM) 기반 시스템입니다. 벽, 문, 창문, 가구 등 다양한 구조 요소를 인식하고, 이들의 공간 위치와 방향까지 파악할 수 있도록 설계되었습니다.
기존의 3D 데이터 처리 모델은 고가의 센서나 특정 포맷의 입력 데이터를 요구하는 경우가 많았지만, SpatialLM은 RGB 비디오, RGBD 이미지, LiDAR 등 다양한 입력 소스를 지원합니다. 이러한 멀티모달 아키텍처는 복잡하고 비정형적인 3D 데이터를 고수준의 의미 기반 구조로 변환해주는 강력한 프레임워크를 제공합니다.
SpatialLM의 주요 특징
-
다양한 입력 포맷 지원: 단일 RGB 비디오, RGBD 이미지, LiDAR 등
-
구조화된 3D 출력: 3D 오리엔티드 바운딩 박스, 2D 평면도, IFC 포맷 등
-
포인트 클라우드 인코딩 + LLM 디코딩 구조
-
현실적인 학습 데이터 기반: 실제와 유사한 대규모 포토리얼리즘 데이터셋 활용
-
확장 가능성: 향후 인간과의 상호작용, 복잡한 환경 내 embodied agent 지원 등으로 확장 예정
SpatialLM 동작 파이프라인
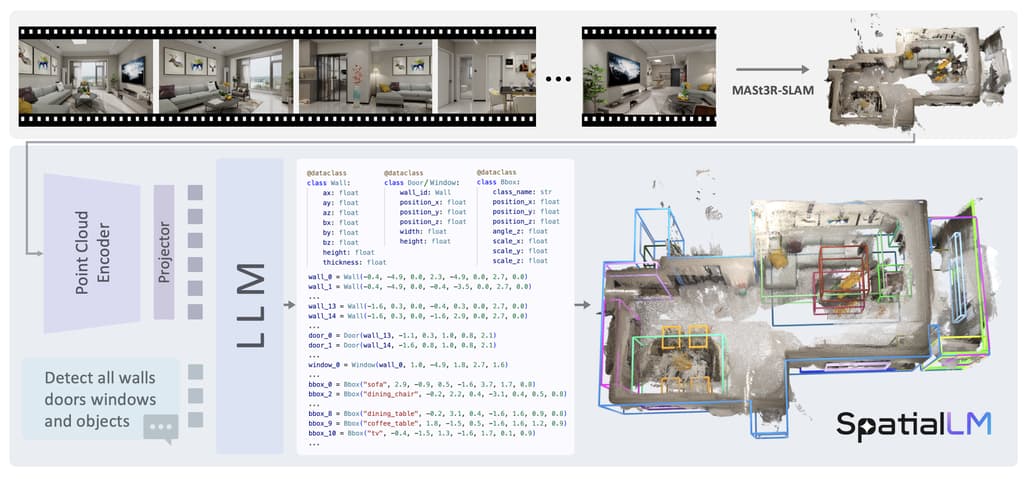
SpatialLM의 파이프라인은 다음과 같습니다:
-
입력 영상 처리: RGB 영상 → MASt3R-SLAM을 통해 포인트 클라우드 복원
-
포인트 클라우드 인코딩: 3D 포인트를 compact한 특징 벡터로 압축
-
LLM 디코딩: 장면을 설명하는 “scene code”를 생성
-
구조 정보로 변환: 생성된 scene code → 3D 레이아웃 및 구조 요소로 변환
이를 통해 단일 RGB 영상만으로도 고정밀의 3D 공간 구조를 이해할 수 있게 됩니다.
 SpatialLM 프로젝트 홈페이지
SpatialLM 프로젝트 홈페이지
https://manycore-research.github.io/SpatialLM/
 SpatialLM GitHub 저장소
SpatialLM GitHub 저장소
 SpatialLM 모델 다운로드
SpatialLM 모델 다운로드
SpatialLM-Llama-1B
SpatialLM-Qwen-0.5B
 SpatialLM 학습 데이터셋
SpatialLM 학습 데이터셋
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()