
SpikingBrain 모델 소개
대규모 언어 모델(LLM)은 최근 인공지능 연구와 산업 응용에서 핵심적인 역할을 하고 있지만, 동시에 막대한 연산량과 메모리 사용량 문제를 안고 있습니다. 현재 LLM에서 주로 채택하는 Transformer 아키텍처는 입력 길이가 늘어날수록 셀프-어텐션(Self-Attention) 연산의 복잡도가 제곱(O(n^2))으로 증가하고, 추론 과정에서 메모리 사용량이 선형적으로 늘어나기 때문에 수백만 토큰 단위의 긴 문맥을 다루는 데 한계를 가집니다. 또한, NVIDIA GPU에 종속된 생태계로 인해 학습 및 배포에 있어서 제한적인 부분이 많습니다.

SpikingBrain은 이러한 문제를 해결하기 위해 제안된 모델로, 뇌 신경 과학의 메커니즘을 차용하여 새로운 구조적 혁신을 도입했습니다. 즉, 하이브리드 어텐션(Hybrid Attention), 적응형 스파이킹 뉴런(Adaptive-Threshold Spiking Neuron), 스파이크 코딩(Spike Coding), MoE(Mixture of Experts) 등을 결합하여, 기존 LLM 대비 연산 자원과 데이터 사용량을 획기적으로 줄이면서도 성능을 유지합니다. 또한 적은 데이터와 연산 자원으로도 높은 성능을 달성하며, 향후 뉴로모픽 하드웨어에 적합한 구조를 갖추고 있다는 점에서 주목받고 있습니다.
SpikingBrain 구조를 채택하여 학습한 SpikingBrain-7B 및 SpikingBrain-76B-A12B 모델은 각각 다른 아키텍처 전략을 통해 효율성과 확장성을 보여주고 있습니다. SpikingBrain-7B 모델은 4M 토큰 길이의 입력에서도 기존 Transformer 대비 100배 이상의 빠른 TTFT(Time to First Token)를 기록했으며, 메모리 사용량 또한 선형적 혹은 상수에 가까운 수준으로 유지합니다. 이러한 성능 덕분에 SpikingBrain은 단순한 또 하나의 LLM이 아니라, 장기적으로 뉴로모픽 하드웨어에 최적화된 모델로 발전할 수 있는 잠재력을 가지고 있습니다.
기존의 LLM과의 비교
전통적인 LLM은 대부분 소프트맥스(Softmax) 기반의 셀프-어텐션(Self-Attention)을 사용하기 때문에 입력 길이에 따라 연산량이 제곱(O(n^2))으로 증가합니다. 이 방식은 대규모 데이터와 고성능 GPU 클러스터가 있을 때 뛰어난 성능을 발휘하지만, 효율성과 확장성에서 한계를 드러냅니다. SpikingBrain은 이러한 문제를 해결하기 위해 선형 어텐션(Linear Attention)과 슬라이딩 윈도우 어텐션(Sliding Window Attention)을 교대로 배치하는 레이어간 하이브리드 구조(Inter-Layer Hybrid Architecture) 를 채택했습니다. 이를 통해 장기 문맥을 효율적으로 요약하면서도 지역적 패턴을 잃지 않고 유지할 수 있습니다.
또한, SpikingBrain-7B는 Qwen2.5-7B와 같은 비슷한 규모의 모델 대비, 훨씬 적은 데이터로 학습하면서도, CMMLU, C-Eval과 같은 벤치마크에서 경쟁력 있는 성능을 달성합니다. 즉, 성능을 약간 희생하는 대신 연산 자원과 데이터 사용량을 대폭 절감하는 전략을 취하고 있습니다.
뇌 신경 메커니즘과 모델 설계의 연결

SpikingBrain은 이름처럼 뇌의 뉴런 발화(spiking) 원리를 직접 모델 구조에 반영합니다. 생물학적 뉴런은 지속적으로 신호를 전달하지 않고, 일정한 전위가 임계값(threshold)을 넘을 때만 순간적인 전기적 신호인 스파이크(Spike)를 발생시킵니다. 이를 통해 불필요한 에너지를 절약하고 중요한 정보만 전달할 수 있습니다.
SpikingBrain의 적응형 스파이킹 뉴런(Adaptive-Threshold Spiking Neuron) 은 이러한 뇌의 발화 원리를 모사합니다. 활성화 값이 주어지면 입력 분포에 따라 동적으로 변하는 임계값을 설정하고, 이를 넘어서는 부분만 정수 스파이크 카운트(Integer Spike Count)로 변환합니다. 이 과정은 GPU 학습에도 적합하도록 단순화되어 있으며, 약 69% 이상의 희소성(sparsity)을 확보합니다.
또한, 단기 기억과 장기 기억이 협력하여 작동하는 뇌의 기억 체계도 벤치마킹하였습니다. SpikingBrain은 이를 어텐션 모듈(Attention Module)에서 구현했습니다. 슬라이딩 윈도우 어텐션(Sliding Window Attention)은 단기 기억처럼 최근 정보를 집중적으로 다루고, 선형 어텐션(Linear Attention)은 장기 기억처럼 요약된 상태를 유지합니다. 소프트맥스 어텐션(Softmax Attention)은 전체적인 맥락을 통합적으로 이해합니다.
마지막으로, 뇌가 특정 기능을 담당하는 영역만 활성화하는 모듈화된 처리 방식은 SpikingBrain의 MoE (Mixture-of-Experts) 구조로 반영하였습니다. 모든 전문가가 항상 계산에 참여하는 것이 아니라, 입력 토큰마다 일부 전문가만 활성화되어 효율적이면서도 표현력을 유지할 수 있습니다.
SpikingBrain 모델의 구조 및 특장점

-
하이브리드 어텐션(Hybrid Attention) 구조: SpikingBrain는 소프트맥스 어텐션(Softmax Attention), 슬라이딩 윈도우 어텐션(Sliding Window Attention), 그리고 선형 어텐션(Linear Attention)을 혼합하는 방식을 사용합니다. 각 어텐션들의 특징들을 정리하면 다음과 같습니다:
-
슬라이딩 윈도우 어텐션(Sliding Window Attention, SWA): 주변 토큰(Local Context)에 집중하여 뇌의 '단기 기억'과 같이 최근 정보를 집중적으로 다루고, 연산 비용을 O(n) 으로 줄입니다.
-
선형 어텐션(Linear Attention): 과거 정보를 재귀적 상태(Recurrent State)로 요약하여 장기 의존성을 처리하며 뇌의 '장기 기억'과 같이 요약된 정보를 유지하고 처리합니다. 특히, 메모리 사용량을 시퀀스 길이에 독립적으로 유지합니다.
-
소프트맥스 어텐션(Softmax Attention): 전역(Global) 문맥을 통합적으로 이해하는데 강점을 갖지만, 연산 비용이 크기 때문에 이전의 두가지 어텐션을 통합적으로 활용하는데 사용됩니다.
이러한 세 가지 방식의 어텐션을 레이어 간(Inter-layer) 방식으로 배치함으로써, 모델은 장기 문맥 처리와 지역적인 패턴 학습을 동시에 달성할 수 있습니다.
-
-
적응형 스파이킹 뉴런(Adaptive-Threshold Spiking Neuron): SpikingBrain의 또 다른 핵심은 적응형 임계값 뉴런(Adaptive-Threshold Neuron) 입니다. 기존의 LIF(Leaky Integrate-and-Fire) 뉴런은 대규모 모델에서 적합하지 않았지만, SpikingBrain은 입력 분포에 따라 동적으로 변하는 임계값(Adaptive-Threshold)을 도입하여 뉴런의 발화 빈도를 제어합니다. 입력 활성 값이 이러한 동적 임계값을 초과하는 경우 해당 값을 정수 스파이크 카운트로 변환하며, 이 과정은 GPU에서 단일 연산으로 수행될 수 있습니다.
이렇게 변환된 스파이크는 희소성을 가지므로 전체 연산량을 줄일 수 있으며, 이는 뇌가 중요하지 않은 신호는 억제하고 의미 있는 신호만 발화하는 방식과 동일합니다.


-
스파이크 코딩(Spike Coding): 뇌는 정보를 연속적인 값으로 표현하지 않고, 시간에 따른 스파이크 패턴(Spike Train)으로 나타냅니다. SpikingBrain 모델은 추론 단계에서는 정수 스파이크 카운트를 실제 시간 축으로 확장해 이벤트 기반 계산을 수행하는 방식으로 동작합니다. 이를 위해 Binary, Ternary, Bitwise 세 가지 코딩 방식이 지원되며 각각은 다음과 같습니다:
-
Binary Coding: 단순한 발화 여부(0/1)를 표현합니다.
-
Ternary Coding: 흥분(+1)과 억제(-1)를 동시에 표현할 수 있어, 억제성 뉴런과 흥분성 뉴런의 상호작용을 반영합니다.
-
Bitwise Coding: 정수 스파이크 카운트를 비트 단위로 확장하여 시간 차원에 배치합니다. 이는 실제 뇌에서 발화 빈도가 정보의 강도를 나타내는 방식과 유사합니다.
특히 Ternary Coding 방식이 발화율을 절반 이상 줄여 효율성을 높이고, Bitwise Coding은 스파이크 수를 8배 가량 감소시켜 메모리와 연산량을 크게 줄입니다. 그 결과 FP16 연산 대비 97% 이상의 에너지를 절약할 수 있습니다. 이러한 시도는 향후 뉴로모픽 칩(Neuromorphic Chip)에서 이벤트 기반(Event-Driven) 방식으로 활용될 수 있는 가능성을 보여줍니다.
-
-
MoE와 다중 희소성: 뇌는 모든 영역이 항상 동시에 활성화되지 않고, 상황에 따라 특정 영역만 동원됩니다. 이를 모사하여 SpikingBran은 76B-A12B 모델에서 MoE(Mixture-of-Experts) 구조를 채택하였습니다. (단, Spiking-7B 모델은 FFN을 기존과 같은 구조(Dense)로 유지합니다.) 이를 통해 입력 토큰마다 소수의 전문가만 활성화하여, 연산 자원 사용량은 줄이고 모델 용량(capacity)은 유지할 수 있습니다.
이와 같은 구조는 뇌의 특화된 영역 모듈화와 유사하며, 뉴런 단위의 스파이킹 희소성과 결합해 다중 스케일의 희소성을 제공합니다. 이러한 구조를 통해 SpikingBrain 모델은 효율성과 성능 간의 균형을 맞출 수 있습니다.
SpikingBrain 모델의 학습 전략
어텐션 맵 대응(Attention Map Correspondence) 전략
Transformer 기반 LLM의 핵심은 소프트맥스 어텐션(Softmax Attention) 입니다. 이 구조에서는 쿼리(Query)와 키(Key)의 내적(Inner Product)을 지수 함수에 통과시켜 확률 분포 형태의 어텐션 맵(Attention Map, A) 을 생성합니다. 이를 수식으로 살펴보면 다음과 같습니다:
여기서 Q, K 는 각각 쿼리(Query)와 키(Key) 행렬이고, M 은 인과성 마스크(Causal Mask)입니다. 이 어텐션 맵(A)은 n \times n 크기로, 각 입력 토큰이 다른 모든 토큰들과 맺는 상호작용의 강도를 나타내며, 결과적으로 모델은 문맥 전체를 고려한 표현을 얻게 됩니다. 하지만 이러한 소프트맥스 어텐션은 연산량이 O(n^2) 로 증가하기 때문에, 입력 길이가 수백만 토큰에 이르면 사실상 연산이 불가능에 가까워집니다.
SpikingBrain은 이러한 계산량 문제를 해결하기 위해 소프트맥스 어텐션을 선형 어텐션(Linear Attention) 및 슬라이딩 윈도우 어텐션(Sliding-Window Attention, SWA) 으로 변환하여 활용합니다. 그런데 단순히 구조만 바꿔치기하면 기존 Transformer가 학습한 지식이 무너질 위험이 있습니다. 이를 막기 위해 도입된 개념이 어텐션 맵 대응(Attention Map Correspondence) 입니다. 즉, 변환 과정에서 새로운 어텐션 구조가 만들어내는 어텐션 맵이 기존 소프트맥스 어텐션 맵과 최대한 유사해지도록 강제하는 것입니다 .
먼저 슬라이딩 윈도우 어텐션과 선형 어텐션을 살펴보겠습니다:
-
슬라이딩 윈도우 어텐션(Sliding Window Attention, SWA): 슬라이딩 윈도우 어텐션은 소프트맥스 어텐션의 계산량을 O(n^2) 에서 O(n) 으로 줄이기 위해, 각 쿼리 토큰이 고정된 크기 w 의 로컬 윈도우 내의 키 토큰하고만 상호작용하도록 제한합니다. 이는 기존 소프트맥스 어텐션 맵을 희소화(Sparsified) 한 형태로 볼 수 있으며, 강력한 최근성 편향(Recency Bias)을 가집니다. 슬라이딩 윈도우 어텐션(SWA)의 어텐션 맵 A_{SWA} 는 다음과 같이 표현할 수 있습니다:
A_{SWA} = softmax(Q K^\intercal \odot M') \in R^{n \times n}여기서 M' 은 윈도우형 인과성 마스크(Windowed Causal Mask)로 i - w + 1 \leq j \leq i 일 때만 M'_{ij} = 1 이고, 그 외에는 M'_{ij} = - \infty (또는 Softmax 이후 0)입니다. 이 마스크는 어텐션 계산 범위가 현재 토큰 i 와 그로부터 w-1 개 이전 토큰까지만 허용되도록 합니다.
슬라이딩 윈도우 어텐션 맵 A_{SWA} 는 기존 소프트맥스 어텐션 A 의 로컬 및 희소화된 버전입니다. 즉, 대부분의 토큰 쌍에 대한 상호작용은 고려하지 않고, 인접한 토큰들 사이의 상호작용만 집중적으로 나타내는 어텐션 맵입니다. 어텐션 맵 대응(Attention Map Correspondence) 관점에서, 슬라이딩 윈도우 어텐션은 기존 소프트맥스 어텐션 맵에서 로컬 상호작용 패턴을 추출하고 보존하는 역할을 합니다.
-
선형 어텐션(Linear Attention)" 선형 어텐션은 소프트맥스 함수를 제거하여 연산 복잡도를 O(n^2) 에서 O(n) 으로 줄입니다. 이 방식은 상태 기반 선형 재귀(State-based Liniear Recurrence)로 재구성할 수 있어 장기 정보 압축에 효과적입니다. 선형 어텐션의 어텐션 맵 A_{Linear} 는 다음과 같이 표현할 수 있습니다:
A_{Linear} = Q K^\intercal \odot M' \in R^{n \times n}여기서 M 은 일반적인 인과성 마스크(Causal Mask)로, i \geq j 일 때 M_{ij} = 1 이고, i < j 일 때 M_{ij} = 0 입니다. 소프트맥스 함수가 없기 때문에 선형 어텐션의 어텐션 맵은 확률 분포가 아닌 단순한 유사도 행렬이 됩니다.
이 때, 선형 어텐션의 출력 O 는 O = (QK^\intercal \odot M)V 와 같이 재구성할 수 있으며, 이 때 각 시점 t 에서의 출력 o_t 는 다음과 같이 재귀적으로 정의할 수 있습니다:
o_t = \Sigma^t_{s=1} (q_t k^\intercal_{s})v_s = q_t \Sigma^t_{s=1}(q_tS_t), where S_t = S_{t-1} + k^\intercal_t v_t이 때 S_t 는 고정된 크기의 상태(Fixed-Size State)로, Key와 Value의 정보를 압축하여 지속적으로 업데이트하는 메모리의 역할을 합니다. 즉, 선형 어텐션 맵 A_{Linear} 은 소프트맥스 어텐션 맵 A 의 저랭크 근사(Low-rank Approximation)로 간주할 수 있습니다. 랭크 d 를 갖는 QK^\intercal 행렬은 Softmax 함수가 적용되기 전의 유사도 맵을 직접적으로 모델링하고 있기 때문에, 장거리 정보가 효율적으로 압축됩니다. 어텐션 맵 대응(Attention Map Correspondence) 관점에서, 선형 어텐션은 기존 소프트맥스 어텐션 맵에서 저랭크 형태의 글로벌 상호작용 패턴을 포착하고 보존하는 역할을 합니다.
SpikingBrain이 사용하는 "어텐션 맵 대응"은 위에서 살펴본 SWA(A_{SWA})와 선형 어텐션(A_{Linear})의 어텐션 맵이 기존 소프트맥스 어텐션 맵(A)과 구조적 및 기능적으로 유사성을 가진다는 점을 활용합니다. (SWA의 경우에는 소프트맥스 어텐션 맵에서 로컬 영역만 잘라내어 사용하는 것과 같으므로, 그 지식은 어느 정도 보존됩니다. 선형 어텐션의 경우에는 소프트맥스 어텐션 맵의 저랭크 근사라는 점에서, 전체적인 경향성과 중요한 장거리 상호작용을 압축된 형태로 유지할 수 있습니다.)
이러한 어텐션 맵들 간의 대응 관계를 활용하여, 기존 Transformer의 QKV 프로젝션 파라매터를 직접적으로 재사용하여 초기화할 수 있습니다. 그리고 이러한 초기화된 모델을 적은 데이터로 경량 학습(Lightweight Training)하여 새로운 구조에 맞게 미세조정(Adaptation)할 수 있습니다. 이 때 소프트맥스 어텐션에서 얻은 확률 분포와, 선형 어텐션 혹은 SWA에서 얻은 유사도 분포 간의 차이를 최소화하도록 손실 함수(Loss Function) 를 추가하여 지도학습을 하게 되면, 변환된 모델이 새로운 구조를 사용하더라도, 여전히 원래 모델이 배운 “문맥적 상호작용 패턴”을 보존할 수 있습니다. 간단히 말해, 어텐션 맵 대응(Attention Map Correspondence)이란 “모델의 구조는 바뀌지만 행동은 최대한 유지되도록” 하는 일종의 교량(bridge) 과 같은 역할을 합니다.
결론적으로, SpikingBrain은 효율적인 선형 및 하이브리드 선형 아키텍처를 도입하면서도, 단순히 구조를 변경하는 것을 넘어 수학적인 어텐션 맵 대응 원리를 통해 기존 Transformer 모델이 학습한 방대한 언어 지식과 문맥적 상호작용 능력을 효과적으로 전이(Transfer)하고 보존합니다. 이는 마치 낡은 건물의 기둥은 그대로 두고 내부 구조만 효율적으로 리모델링하는 것과 유사하며, 결과적으로 적은 자원으로도 강력한 성능을 내는 모델을 만들 수 있게 합니다.
또한, 이러한 접근은 이후 살펴볼 전환 파이프라인(Conversion Pipeline)의 점진적 확장 전략과 결합하여 효과를 극대화합니다. 모델은 처음에는 짧은 문맥(예: 8k)에서 어텐션 맵 대응 전략을 통해 안정적으로 변환되고, 이후 더 긴 문맥(32k, 128k)으로 확장되면서도 소프트맥스 어텐션의 지식을 유지한 채 새로운 구조에 적응합니다. 그 결과 SpikingBrain은 적은 데이터와 적은 연산량으로도 기존 Transformer에 필적하는 성능을 보여줍니다.
전환-기반 학습(Conversion-Based Training): 소량 데이터로 효율적 학습
SpikingBrain의 학습 전략은 기존 대규모 LLM이 사용하는 수조 단위 토큰 데이터와는 전혀 다른 길을 걷습니다. 논문에서는 이를 전환-기반 학습(Conversion-Based Training) 이라고 부르는데, 핵심 아이디어는 이미 학습된 Transformer 모델을 새로운 아키텍처(선형 어텐션, SWA, MoE 등)로 변환한 뒤, 소량의 데이터로 보정 학습을 진행하는 것입니다. 이를 통해 학습 비용을 획기적으로 줄이고도, 기존 모델의 성능을 상당 부분 계승할 수 있습니다. 전체적으로는 Multi-stage Conversion Pipeline과 MoE Upcycling의 두 가지 주요 단계로 나눌 수 있습니다.
다단계 전환 파이프라인(Multi-stage Conversion Pipeline)
전환 파이프라인(Conversion Pipeline)의 핵심은 기존 Transformer의 어텐션 맵(Attention Map) 을 다양한 변형 형태(선형, 국소적, 하이브리드)로 전환하면서도, 원래 학습된 지식을 보존하는 것입니다. Transformer의 어텐션은 소프트맥스 기반으로 전역적인 상호작용을 모델링하지만, SpikingBrain은 이를 슬라이딩 윈도우 어텐션(SWA) 및 선형 어텐션(Linear Attention) 으로 변환합니다. 이때 기존 모델의 QKV 프로젝션 가중치를 그대로 재사용하여, 변환 과정에서도 모델이 이미 학습한 “유사도 구조” 를 보존할 수 있습니다 .
이 변환 과정은 단일 단계가 아니라, 세 단계의 연속적인 학습 절차(Continual Pre-Training, CPT) 를 거칩니다. (1) 첫 번째 단계에서는 상대적으로 짧은 시퀀스 길이(8k)를 사용하여 모델을 약 100B 토큰으로 학습시키면서, 소프트맥스 어텐션을 SWA와 선형 어텐션으로 대체합니다. 이 과정에서 앞에서 살펴본 어텐션 맵 대응(Attention Map Correspondence) 전략을 통해 안정적으로 변환할 수 있습니다. (2) 이후 두 번째 단계에서는 시퀀스 길이를 32k로 확장하고 20 ~ 30B 토큰으로 학습합니다. (3) 마지막으로, 세 번째 단계에서는 128k 길이로 확장하여 다시 20 ~ 30B 토큰으로 학습합니다.
이러한 3단계의 연속적인 학습 절차(CPT) 과정에서 약 150B 규모의 토큰만 사용하며, 이는 전통적인 LLM이 처음부터(from-scratch) 학습을 하는 약 10T 토큰의 2% 수준에 불과합니다. 그럼에도 불구하고 모델은 장기 문맥 처리 능력을 안정적으로 확보하며, Qwen2.5와 같은 대규모 모델의 성능을 상당 부분 계승합니다 .
이러한 파이프라인은 단순히 데이터 효율성을 높이는 것에 그치지 않습니다. Transformer 모델을 그대로 학습시키는 대신, 효율적인 어텐션 구조로 변환하면서 점진적으로 문맥 창(Context Windows)을 확장하기 때문에, 결과적으로 SpikingBrain은 긴 입력 문맥에서도 일정한 메모리 사용량을 유지하고 매우 빠른 TTFT(Time to First Token)를 달성합니다. 특히 SpikingBrain-7B는 4M 토큰 입력에서 기존 모델 대비 100배 이상 빠른 첫 토큰 생성 속도를 기록했습니다. 이는 전환 파이프라인(Conversion Pipeline)이 단순한 학습 데이터 절약이 아니라, 근본적인 아키텍처 효율성 향상으로 이어진다는 사실을 보여줍니다.
MoE 업사이클링(MoE Upcycling)
SpikingBrain의 대규모 모델인 SpikingBrain-76B-A12B 모델은 단순히 FFN(Feed-Forward Network)을 늘려서 성능을 개선하는 대신, Mixture of Experts(MoE) 구조를 도입했습니다. 하지만 이러한 MoE 모델을 처음부터 학습하는 것은 막대한 자원과 시간이 소요됩니다. 이를 해결하기 위해 SpikingBrain은 MoE 업사이클링(MoE Upcycling) 이라는 방법을 제안합니다.
MoE 업사이클링은 기존의 Dense FFN을 여러 전문가(Experts)로 복제하는 방식으로 시작합니다. 예를 들어, Dense FFN의 가중치를 N개의 전문가에게 동일하게 복제하면, 초기 단계에서 MoE 모델은 Dense 모델과 동일한 출력을 내게 됩니다. 이후 학습 과정에서 라우터(Router)가 각 토큰에 대해 일부 전문가만 선택하여 활성화하게 되는데, 데이터 노이즈와 확률적 라우팅 덕분에 각 전문가가 점차 특화되고, 결과적으로 Dense 모델보다 더 높은 표현력을 지닌 MoE 모델로 진화합니다.
이러한 MoE 업사이클링 과정에서 중요한 점은, 단순히 여러 전문가를 활성화하면 출력 값이 커져 모델의 안정성이 무너질 수 있다는 것입니다. 이를 방지하기 위해 SpikingBrain은 전문가 출력에 스케일링 인자(Scaling Factor)를 곱하는 방식을 사용합니다. 이 때 사용하는 스케일링 인자는 다음과 같습니다:
이 때, S 는 공유 전문가(Shared Expert)의 수, k 는 활성화한 전문가의 수, N 은 전체 전문가의 수로, 학습 초기에는 Dense 모델과 동등한 수준의 출력을 보장하도록 설계했습니다. 이렇게 하면 학습 초기에 모델이 불안정해지지 않고, 점차적으로 전문가들이 차별화된 기능을 습득할 수 있습니다.
MoE 업사이클링을 사용함으로써, Dense 모델 대비 연산량은 거의 늘리지 않으면서도, 모델 용량(capacity)을 크게 확장할 수 있습니다. 실제로 SpikingBrain-76B는 16명의 라우팅 전문가와 1명의 공유 전문가를 포함하는 MoE 구조를 사용했는데, 이때 토큰당 실제로 활성화되는 파라미터는 전체의 약 15%에 불과했습니다. 그럼에도 불구하고 모델은 Llama2-70B, Mixtral-8×7B 같은 최신 모델과 경쟁하거나 일부 태스크에서는 더 나은 성능을 보였습니다 .
실험 결과

SpikingBrain은 전체 데이터의 2% 이하인 약 1500억 토큰으로 학습되었음에도 불구하고, 기존 오픈소스 LLM과 유사한 성능을 기록했습니다. 특히, 긴 문맥 입력에서 큰 강점을 보여, 400만 토큰 입력에서 Time to First Token(TTFT)을 기존 대비 100배 이상 향상시키면서도 추론 시 메모리 사용량도 일정하게 유지됩니다.
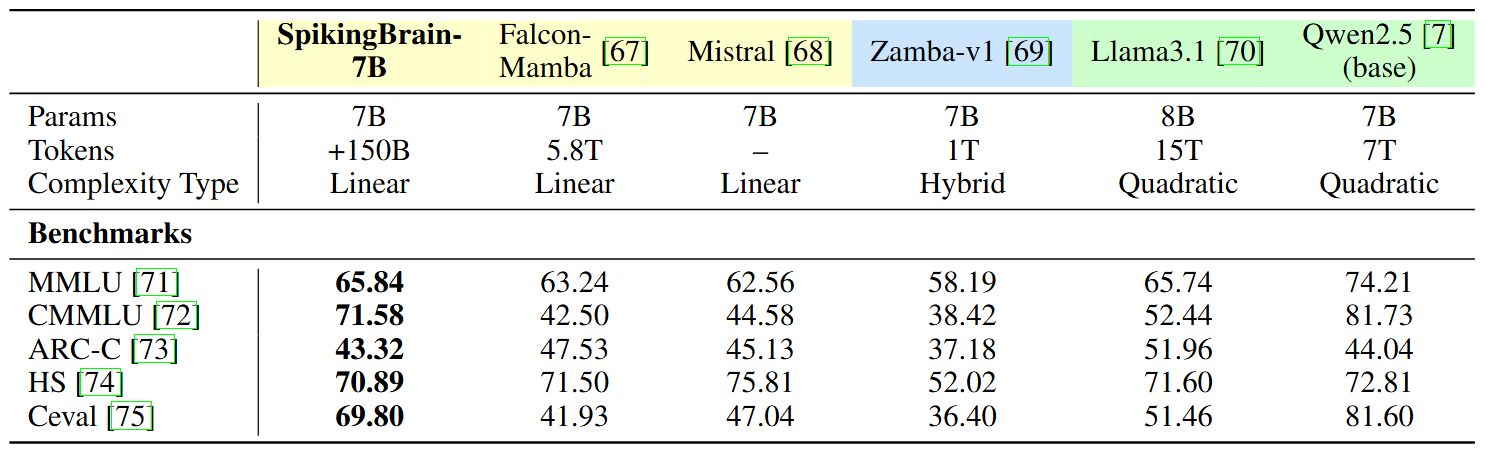
구체적으로 SpikingBrain-7B 모델의 성능을 평가해보면, HuggingFace 프레임워크 상에서 평가되었으며, Qwen2.5와 같은 최신 모델과 비교했을 때도 의미 있는 성능을 보였습니다. 특히 CMMLU(중국어 다영역 학습 벤치마크)와 C-Eval(중국어 시험 문제 기반 평가)에서, Qwen2.5를 제외한 다른 모델들은 제한된 중국어 데이터로 학습되었기 때문에 성능이 낮았습니다. SpikingBrain-7B는 상대적으로 적은 학습 데이터(150B 토큰 이하)를 사용했음에도 불구하고, 주요 벤치마크에서 기존 모델들과 비슷하거나 더 나은 결과를 달성했습니다. 즉, SpikingBrain-7B는 데이터 효율성(Data Efficiency) 측면에서 강점을 입증한 모델입니다.

SpikingBrain-76B는 더 큰 규모(76B 파라미터)를 가지며, vLLM 프레임워크를 사용해 평가되었습니다. 결과적으로 76B 모델은 7B 대비 전반적으로 더 높은 성능을 보여주었으며, 특히 장문맥(long-context) 처리 및 **중국어 벤치마크(CMMLU, C-Eval)**에서 경쟁력이 두드러졌습니다. Qwen2.5와 비교했을 때도 비슷한 수준에 도달하거나 특정 태스크에서는 근소한 우위를 보였습니다. 이는 레이어 내부(Intra-Layer) 하이브리드 어텐션 구조와 MoE(Mixture of Experts) 도입으로 인해 모델 용량(Capacity)을 확장하면서도 효율성을 유지한 결과라고 볼 수 있습니다.

또한, NVIDIA 환경에만 최적화된 기존 모델과 달리, MetaX GPU 클러스터와 같은 NVIDIA가 아닌 하드웨어 환경에서도 안정적인 학습과 추론을 지원하도록 설계되었습니다. 이는 특정 하드웨어 종속성을 벗어나 다양한 플랫폼에서 대규모 모델을 실행할 수 있는 가능성을 제시합니다.
뇌과학적 해석과 뉴로모픽 확장성
SpikingBrain의 구조는 단순한 공학적 최적화가 아니라 뇌의 신경 메커니즘을 직접 반영한 설계입니다. 슬라이딩 윈도우 어텐션(Sliding Window Attention)은 단기 기억(Working Memory), 선형 어텐션(Linear Attention)은 장기 기억(Long-Term Memory), MoE(Mixture-of-Experts)는 기능 단위 모듈화(Functional Modularity), 적응형 임계값 뉴런(Adaptive-Threshold Neuron)은 뉴런 발화 메커니즘, Spike Coding은 이벤트 기반 신호 표현과 각각 대응됩니다.
이렇듯 SpikingBrain은 뇌의 계산 원리를 기계 학습 구조로 치환한 사례로, 뉴로모픽 칩(Neuromorphic chip) 같은 차세대 하드웨어에서 진정한 효과를 발휘할 수 있습니다. 현재는 모사 스파이킹(Pseudo-Spiking) 방식을 통해 GPU 환경에서 근사하지만, 향후 비동기 이벤트 기반 하드웨어와 결합할 경우 뇌 모사형 인공지능 모델로서의 잠재력이 더욱 커질 것입니다.
 SpikingBrain 기술 문서: Spiking Brain-inspired Large Models
SpikingBrain 기술 문서: Spiking Brain-inspired Large Models
 SpikingBrain 모델 코드
SpikingBrain 모델 코드
 SpikingBrain-7B 모델 다운로드
SpikingBrain-7B 모델 다운로드
현재 SpikingBrain-7B 모델은 ModelScope에서만 다운로드 가능합니다:
- Pre-trained model (7B): SpikingBrain-7B pre-trained
- Chat model (7B-SFT): SpikingBrain-7B chat
- Quantized weights (7B-W8ASpike): SpikingBrain-7B-W8ASpike
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()