SpreadsheetLLM 소개
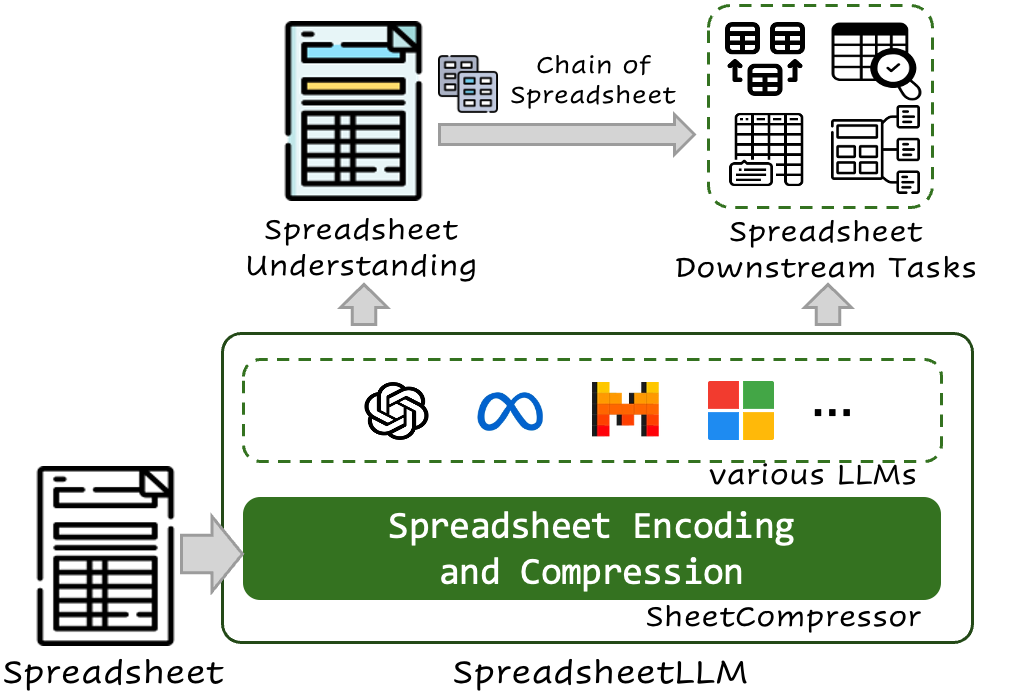
스프레드시트(Spreadsheet)는 데이터 관리와 분석에 널리 사용되며, Microsoft Excel 및 Google Sheets와 같은 플랫폼에서 광범위하게 사용됩니다. 이러한 스프레드시트는 종종 방대한 2차원 그리드를 가지고 있어 대규모 언어 모델(LLM)이 이를 효과적으로 이해하고 처리하는 데 어려움을 겪습니다. 특히 셀 주소, 값 및 형식을 포함한 데이터는 LLM의 토큰 한계를 초과할 수 있습니다. 이러한 문제를 해결하기 위해, 저자들은 SpreadsheetLLM이라는 새로운 프레임워크를 제안합니다. 이는 LLM이 스프레드시트를 효율적으로 이해하고 추론할 수 있도록 돕는 혁신적인 인코딩 방법입니다.
기존의 직렬화(Serialization) 접근 방식은 셀 주소, 값 및 형식을 포함하여 데이터를 순차적으로 인코딩하지만, 이는 LLM의 토큰 제한으로 인해 대규모 스프레드시트를 처리하는 데 한계가 있습니다. 이를 보완하기 위해 저자들은 SheetCompressor라는 새로운 인코딩 프레임워크를 개발했습니다. 이 프레임워크는 구조적 앵커 기반 압축, 역색인 번역 및 데이터 형식 인식 집계를 포함한 세 가지 주요 모듈로 구성됩니다. 이러한 모듈들은 스프레드시트 데이터를 효율적으로 압축하여 LLM이 더 적은 토큰으로 더 많은 정보를 처리할 수 있도록 합니다.
더 나아가, 저자들은 스프레드시트 이해의 하위 작업을 위해 Chain of Spreadsheet(CoS)를 제안합니다. 이는 테이블 감지, 경계 감지 및 응답 생성을 포함한 여러 단계를 통해 스프레드시트 데이터를 체계적으로 분석합니다. 이러한 접근 방식은 스프레드시트 질의 응답(QA) 작업에서 매우 유용하며, LLM이 복잡한 스프레드시트를 효과적으로 처리하고 사용자 질의에 정확하게 응답할 수 있도록 합니다.
SpreadsheetLLM를 위한 프레임워크: SheetCompressor
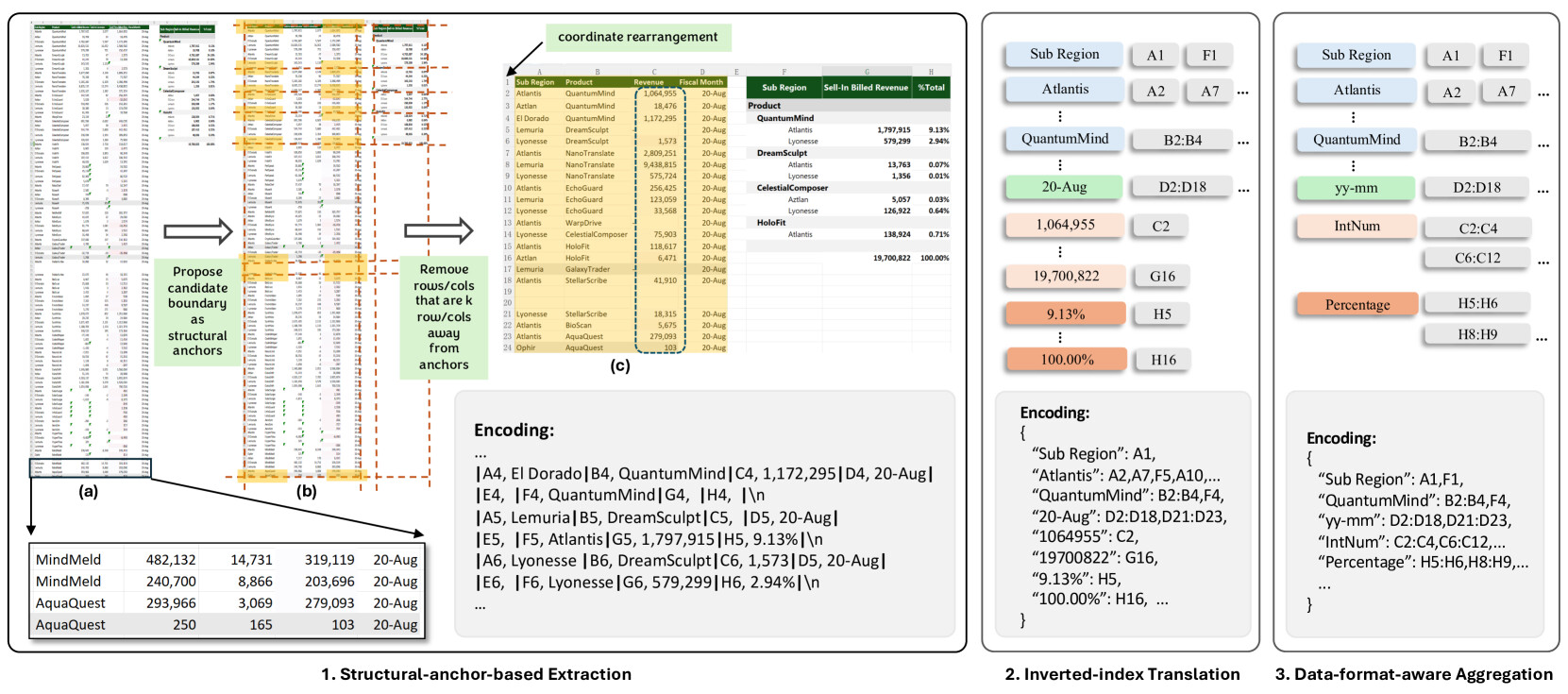
SpreadsheetLLM은 스프레드시트를 LLM에 효율적으로 인코딩하기 위한 혁신적인 프레임워크인 SheetCompressor를 소개합니다. 이 프레임워크는 1) 구조적 앵커 기반 압축(Structural-anchor-based Extraction), 2) 역 인덱스 번역(Inverted-index Translation) 및 3) 데이터 형식을 인식한 집계(Data-format-aware Aggregation)를 포함한 세 가지 모듈로 구성됩니다. 이 모듈들은 함께 작동하여 LLM이 크고 복잡한 스프레드시트를 효율적으로 처리할 수 있도록 합니다. 기존의 인코딩 방식과 SheetCompressor에서 사용하는 방법들은 다음과 같습니다:
- 바닐라 인코딩(Vanilla Spreadsheet Encoding with Cell Value, Address, and Format): 초기 단계에서는 스프레드시트가 셀 주소, 값 및 선택적 형식을 시퀀스에 포함하는 바닐라 방법으로 직렬화됩니다. 예를 들어, 셀 A1의 값이 100이고 형식이 숫자인 경우, 이를 "A1:100 (숫자)"로 인코딩합니다. 이 방법은 직관적이지만, LLM의 토큰 제한에 빠르게 도달하여 더 효율적인 인코딩 기술의 필요성을 촉발합니다.
-
구조적 앵커 기반 추출(Structural-anchor-based Extraction): 대형 스프레드시트는 종종 많은 동질적 행이나 열을 포함합니다. 이 방법은 테이블 경계에서 이질적인 행과 열(구조적 앵커)을 식별하고 먼 동질적 데이터를 제거합니다. 추출된 "스켈레톤(Skeleton)" 버전의 스프레드시트는 중요한 구조 정보를 유지하여 더 효율적인 인코딩을 가능하게 합니다.
-
역 인덱스 번역(Inverted-index Translation): 전통적인 행별 직렬화는 반복적인 값과 빈 셀 때문에 많은 토큰을 소비합니다. 역 인덱스 번역은 비어 있지 않은 셀 텍스트의 사전을 만들어 동일한 내용의 주소를 병합합니다. 이 방법은 데이터 무결성을 유지하면서 토큰 사용을 최적화합니다. 이 방법은 모든 스프레드시트 이해 작업에 일반적으로 적용되며, 압축 비율을 크게 증가시켜 SheetCompressor 프레임워크의 중요한 구성 요소로 만듭니다.
-
데이터 형식에 따른 집계(Data-format-aware Aggregation): 인접한 셀은 종종 유사한 형식을 공유합니다. 이 방법은 숫자 형식 문자열과 데이터 유형을 추출하여 동일한 형식을 가진 인접한 셀을 클러스터링합니다. 예를 들어, 날짜 열은 "yyyy-mm-dd" 형식 문자열로, 숫자 값은 "FloatNum"으로 나타낼 수 있습니다. 이 접근 방식은 토큰 사용을 줄이면서 데이터의 의미론적 의미를 유지합니다. 형식 문자열로 클러스터를 나타내어 스프레드시트의 구조와 데이터 분포를 과도한 토큰 소비 없이 이해할 수 있도록 합니다.
위 3가지 모듈과 함께, 마지막으로 SpreadsheetLLM의 적용 가능성을 확장하기 위해 스프레드시트 체인(CoS, Chain of Spreadsheet) 방법을 도입하였습니다. 이 방법은 테이블 식별 및 경계 감지, 응답 생성의 두 단계로 구성됩니다. 첫 번째 단계에서는 구조적 앵커와 형식 문자열을 사용하여 스프레드시트 내의 테이블을 식별하고 구분합니다. 두 번째 단계에서는 압축된 구조화된 데이터를 활용하여 정확하고 맥락에 맞는 응답을 생성합니다. 이 두 단계 접근 방식은 모델이 복잡한 스프레드시트를 정확하고 맥락에 맞게 처리할 수 있도록 합니다.
예시를 통한 SpreadsheetLLM의 동작 방식
SpreadsheetLLM이 어떻게 작동하는지 예시를 통해 설명하겠습니다. 예를들어, 대형 소매 회사의 판매 데이터를 포함하는 큰 스프레드시트를 사용해 보겠습니다. 이 스프레드시트에는 판매 수치, 날짜, 제품 카테고리 및 지역 데이터를 포함한 여러 테이블이 포함되어 있으며, 다양한 형식 스타일로 구성되어 있습니다:
-
구조적 앵커 기반 압축: 첫 번째 단계는 구조적 앵커 기반 압축입니다. 이 방법은 테이블 경계를 나타내는 이질적인 행과 열과 같은 주요 구조적 요소를 식별합니다. 예를 들어, 이 방법은 헤더와 하위 헤더를 감지하여 서로 다른 테이블을 구분합니다. 먼 동질적 행과 열을 제거하여 스프레드시트의 "스켈레톤" 버전을 생성합니다. 이 스켈레톤은 중요한 구조 정보를 보존하면서도 인코딩에 필요한 토큰 수를 크게 줄입니다.
-
역 인덱스 번역: 다음 단계는 역 인덱스 번역으로, 남은 데이터를 사전 형식으로 변환합니다. 예를 들어, 이 방법은 고유한 판매 수치, 제품 카테고리 및 지역 데이터를 키로 사용하여 주소를 인덱싱합니다. 동일한 값을 가진 셀은 병합되어 토큰 사용이 최적화됩니다. 예를 들어, "$1000"이라는 판매 수치가 스프레드시트에 여러 번 나타나는 경우, 한 번만 인덱싱되고 해당하는 모든 주소가 병합되어 전체 토큰 수가 줄어듭니다.
-
데이터 형식 인식 집계: 세 번째 단계는 데이터 형식 인식 집계로, 인접한 셀의 유사한 형식을 클러스터링합니다. 예를 들어, 판매 데이터 열의 모든 날짜는 개별적으로 인코딩되는 대신, 단일 형식 문자열 "yyyy-mm-dd"로 나타낼 수 있습니다. 이 접근 방식은 토큰 사용을 줄이면서 데이터의 의미론적 의미를 유지합니다. 예를 들어, 숫자 판매 수치는 "FloatNum"으로 클러스터링되어 스프레드시트의 구조와 데이터 분포를 과도한 토큰 소비 없이 이해할 수 있습니다.
마지막으로, **스프레드시트 체인(CoS, Chain-of-Spreadsheets)**을 적용하여 압축된 데이터를 하위 작업에 적용할 수 있게 합니다. 첫 번째 단계에서는 구조적 앵커와 형식 문자열을 사용하여 스프레드시트 내의 테이블을 식별하고 구분합니다. 두 번째 단계에서는 압축된 구조화된 데이터를 활용하여 정확하고 맥락에 맞는 응답을 생성합니다. 예를 들어, 사용자가 특정 지역의 총 판매량을 문의하면, 모델은 관련 데이터를 정확하게 식별하고 집계하여 정확하고 맥락에 맞는 응답을 제공합니다.
SpreadsheetLLM의 성능 분석
SpreadsheetLLM은 LLM이 스프레드시트 데이터를 처리하고 이해하는 능력을 크게 향상시킵니다. 주요 결과는 다음과 같습니다:
-
향상된 스프레드시트 테이블 감지: 이 방법은 전통적인 접근 방식을 능가하며, 문맥 내 학습 설정에서 25.6%의 향상을 달성하고, F1 점수에서 기존 모델을 12.3% 초과한 78.9%를 기록했습니다. 이는 프레임워크의 복잡한 스프레드시트 내에서 테이블을 식별하고 구분하는 능력을 입증합니다.
-
효과적인 압축: SheetCompressor 프레임워크는 평균 25배의 압축 비율을 달성하여 토큰 사용을 96% 줄이고 대형 스프레드시트를 효율적으로 처리할 수 있게 합니다. 이 결과는 프레임워크가 LLM의 토큰 제한을 초과하지 않고 광범위한 데이터를 처리할 수 있음을 강조합니다.
-
향상된 스프레드시트 질문 응답: 스프레드시트 체인(CoS) 방법은 스프레드시트 질문 응답 작업에서 우수한 성능을 발휘하며, 스프레드시트의 고유한 레이아웃과 구조를 활용하여 정확하고 문맥에 맞는 응답을 제공합니다. 이 개선은 데이터 분석 및 관리 작업에서 스프레드시트와의 지능형 사용자 상호 작용을 향상시키는 프레임워크의 잠재력을 보여줍니다.
 SpreadsheetLLM 논문
SpreadsheetLLM 논문
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()