![소프트웨어정책연구소(SPRi)가 발간한 인공지능 혁명의 숨은 동력, 소프트웨어의 역할과 함의에 대한 보고서 [국문/PDF/43p]](https://discuss.pytorch.kr/uploads/default/original/2X/b/b44670f2ce160ee0f71c4c40b3482891446b657e.png)
인공지능 시대를 견인하는 보이지 않는 손, 소프트웨어
최근 몇 년 사이 인공지능 기술은 전례 없는 속도로 발전하며 전 세계의 경제와 산업, 그리고 우리의 일상 사회 전반을 송두리째 재편하고 있습니다. 특히 2022년 챗GPT의 등장 이후 촉발된 글로벌 인공지능 열풍은 소위 '매그니피센트 7(Magnificent 7)'이라 불리는 미국의 빅테크 기업들이 주도하고 있으며, 이들 기업은 세계 주식 시장의 상단을 차지하며 막대한 자본을 인공지능 분야에 쏟아붓고 있습니다. 현재의 인공지능 경쟁력은 흔히 엔비디아의 GPU와 같은 고성능 컴퓨팅 인프라나 데이터 센터의 규모, 또는 학습 데이터의 방대한 양에 의해 결정되는 것으로 여겨지곤 합니다. 실제로 오픈AI의 연구 결과에 따르면 인공지능 모델의 성능은 파라미터 수, 데이터 양, 컴퓨팅 자원의 규모에 비례한다는 '스케일링 법칙(Scaling Law)'이 확인되었기 때문에, 자본력을 갖춘 기업들의 하드웨어 투자는 필연적인 흐름이기도 합니다.
하지만 이러한 거대한 하드웨어와 데이터의 이면에는 인공지능 혁신을 실질적으로 가능하게 만드는 '숨은 동력'인 소프트웨어가 존재합니다. 소프트웨어는 단순히 복잡한 알고리즘을 코드로 옮기는 차원을 넘어, 인공지능 기술의 효율성과 확장성, 그리고 접근성을 결정짓는 가장 기초적인 기반입니다. 고급 소프트웨어 프레임워크와 프로그래밍 언어 덕분에 연구자들은 복잡한 모델을 신속하게 설계하고 배포할 수 있으며, 최적화 소프트웨어는 막대한 연산 비용을 획기적으로 절감시켜 줍니다4. 결국 인공지능 모델, 인프라의 최적 운영, 그리고 서비스 구현 등 현재의 인공지능을 가능하게 한 것은 끊임없이 고도화되어 온 '실현 기술(Enabling Technology)'로서의 소프트웨어이며, 향후 인공지능의 경쟁력은 하드웨어와 소프트웨어의 상보적 관계를 얼마나 효과적으로 구축하느냐에 달려 있다고 해도 과언이 아닙니다.
AI와 SW: 포함 관계와 상호 발전의 역학

흔히 "소프트웨어가 세상을 집어삼키고 있다"거나 반대로 "인공지능이 소프트웨어를 집어삼키고 있다"는 표현이 혼용되면서 두 개념의 경계가 모호해지는 경향이 있습니다. 하지만 엄밀히 정의하자면 인공지능과 소프트웨어는 서로 다른 층위의 개념이면서 동시에 포함 관계에 있습니다. 일반적인 소프트웨어(SW)는 컴퓨터 프로그램 코드, 절차, 그리고 관련 데이터와 문서를 포괄하는 집합을 의미합니다. 반면, 인공지능(AI) 시스템은 기계가 명시적 혹은 암묵적인 목적을 위해 데이터를 기반으로 추론, 예측, 판단을 수행하도록 만드는 시스템을 말하며, 이는 인간 지능의 요소를 소프트웨어 형태로 실현한 것입니다.
따라서 최근 주목받는 인공지능 모델이나 시스템은 그 자체로 소프트웨어의 범주에 포함되거나, 소프트웨어를 핵심 요소로 수반하는 개념으로 이해해야 합니다. 인공지능 모델은 데이터 학습을 통해 얻어진 파라미터(가중치)와 아키텍처를 핵심으로 하지만, 이를 실행하고 제어하기 위해서는 반드시 코드가 필요하기 때문입니다. 즉, 소프트웨어가 인공지능을 만들고, 만들어진 인공지능은 다시 소프트웨어의 기능과 가치를 고도화하는 동반 성장의 과정이 현재 진행되고 있는 것입니다.
인공지능 개발 생애주기(Lifecycle)와 단계별 핵심 소프트웨어

인공지능 시스템이 하나의 완성된 서비스로서 사용자에게 도달하기까지는 데이터 수집부터 애플리케이션 통합에 이르는 긴 생애주기(Lifecycle)를 거치게 됩니다. 이 보고서에서는 OECD가 정의한 AI 시스템 생애주기를 바탕으로, 각 단계에서 필수적인 역할을 수행하는 소프트웨어 기술과 구체적인 사례들을 심층적으로 분석하고 있습니다.
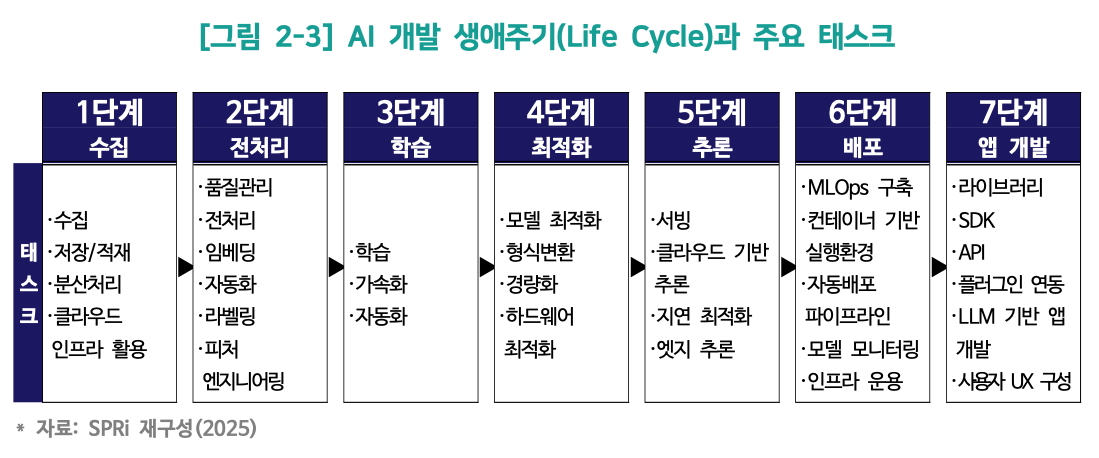
데이터의 획득과 저장: 수집 및 분산 처리 소프트웨어
인공지능 개발의 첫 단추는 학습에 필요한 양질의 데이터를 확보하는 것입니다. 이 단계에서 소프트웨어는 웹, 센서, 로그 파일 등 다양한 소스로부터 이종의 데이터를 수집하고 이를 저장소에 적재하는 과정을 자동화합니다. 예를 들어 Scrapy와 같은 크롤링(Crawling) 도구를 사용해 웹상의 방대한 텍스트와 이미지를 수집하거나, Apache Kafka 나 Apache NiFi 같은 스트리밍 플랫폼을 통해 IoT 센서나 소셜 미디어 피드에서 쏟아지는 실시간 데이터를 끊김 없이 받아냅니다.
수집된 데이터는 그 특성에 따라 적합한 데이터베이스에 저장됩니다. 전통적인 정형 데이터는 오라클(Oracle)이나 MySQL 같은 관계형 데이터베이스(RDBMS)에 저장되지만, 최근에는 비정형 데이터의 비중이 늘어나면서 MongoDB와 같은 NoSQL의 활용이 보편화되었습니다. 특히 생성형 AI의 부상으로 인해 텍스트나 이미지를 벡터(Vector) 형태로 변환하여 저장하고 검색하는 기술이 중요해졌는데, 이를 지원하는 Pinecone, Weaviate, Qdrant와 같은 벡터 데이터베이스(Vector DB) 시장이 급성장하고 있습니다. 또한, 테라바이트(TB) 급 이상의 대규모 데이터를 처리하기 위해 Apache Hadoop 이나 Apache Spark 와 같은 분산 처리 프레임워크가 필수적으로 사용되며, 클라우드 환경에서는 AWS S3와 같은 오브젝트 스토리지(Object Storage)가 데이터레이크(Datalake)의 중심 저장소 역할을 수행합니다. 자율주행차 분야에서는 AWS IoT FleetWise와 같은 소프트웨어를 통해 차량의 센서 데이터를 실시간으로 수집하고 클라우드로 전송하여 학습 데이터로 활용하는 사례도 찾아볼 수 있습니다.
데이터 가공의 미학: 전처리 및 특성 공학 도구
수집된 원시 데이터(Raw Data)는 바로 학습에 사용할 수 없으며, 품질을 높이고 모델이 이해할 수 있는 형태로 변환하는 전처리 과정을 거쳐야 합니다. 이 과정에서 개발자들은 Pandas 나 NumPy 와 같은 파이썬 라이브러리를 활용하여 데이터의 결측치를 처리하고 형식을 변환합니다. 데이터 품질 관리(DQ, Data Quality) 소프트웨어는 데이터베이스를 프로파일링하여 오류를 식별하고 정제하는 작업을 지원합니다. 텍스트 데이터의 경우 BeautifulSoup으로 HTML 태그를 제거하거나, NLTK, spaCy 라이브러리를 통해 문장을 토큰화하고 불용어를 제거하는 등 자연어 처리에 특화된 전처리 파이프라인을 거치게 됩니다.
모델의 성능을 높이기 위해 데이터에서 유의미한 입력 변수를 추출하는 '특성 공학(Feature Engineering)' 단계에서도 소프트웨어의 역할은 지대합니다. 최근에는 한 번 가공된 특성(Feature)을 여러 모델에서 재사용하고 일관성 있게 관리하기 위해 피처 스토어(Feature Store) 를 구축하는 기업이 늘고 있습니다. 대표적으로 우버(Uber)는 머신러닝 플랫폼 '미켈란젤로' 내에 피처 스토어를 구축하여 데이터 처리의 효율성을 크게 높였습니다. 또한, 이미지나 영상 같은 비정형 데이터에 정답(Label)을 부여하는 라벨링 작업의 경우, Label Studio 나 CVAT 같은 도구를 활용하여 자동화하거나 협업 효율을 극대화하고 있습니다.
인공지능의 두뇌 완성: 딥러닝 프레임워크와 가속화 기술
모델 개발 및 학습 단계는 인공지능 시스템의 핵심 로직을 구현하는 과정입니다. 오늘날 대부분의 AI 개발은 Google의 TensorFlow![]() 나 PyTorch 재단의 PyTorch
나 PyTorch 재단의 PyTorch![]() 와 같은 딥러닝 프레임워크 위에서 이루어집니다. 이들 프레임워크는 복잡한 신경망 구조를 직관적인 코드로 정의할 수 있게 해주며, 자동 미분 기능을 통해 모델 학습을 용이하게 만듭니다. 특히, PyTorch는 직관적인 코드 스타일과 유연성 덕분에 연구 및 프로토타이핑 단계에서 널리 사용되고 있으며, TensorFlow는 TFX(TensorFlow Extended)를 통해 파이프라인 관리 등 엔드투엔드 솔루션을 제공하는 강점이 있습니다.
와 같은 딥러닝 프레임워크 위에서 이루어집니다. 이들 프레임워크는 복잡한 신경망 구조를 직관적인 코드로 정의할 수 있게 해주며, 자동 미분 기능을 통해 모델 학습을 용이하게 만듭니다. 특히, PyTorch는 직관적인 코드 스타일과 유연성 덕분에 연구 및 프로토타이핑 단계에서 널리 사용되고 있으며, TensorFlow는 TFX(TensorFlow Extended)를 통해 파이프라인 관리 등 엔드투엔드 솔루션을 제공하는 강점이 있습니다.
이 단계에서 소프트웨어가 기여하는 또 다른 핵심 가치는 바로 '하드웨어 가속'입니다. 2012년 딥러닝의 부흥을 알린 AlexNet이 게이밍 GPU를 활용해 학습될 수 있었던 배경에는 엔비디아의 CUDA라는 병렬 컴퓨팅 플랫폼이 있었습니다. CUDA와 딥러닝 전용 라이브러리인 cuDNN은 GPU의 수천 개 코어를 제어하여 행렬 연산 속도를 CPU 대비 수십 배 이상 향상시켰고, 이는 딥러닝 훈련의 사실상 표준 가속 엔진으로 자리 잡았습니다. 더 나아가 AutoML 소프트웨어는 모델 구조 설계나 하이퍼파라미터 최적화 과정을 자동화하여 사람의 개입을 최소화하면서도 최적의 모델을 탐색할 수 있도록 돕습니다. 허깅페이스(Hugging Face)의 Transformers 라이브러리는 전 세계에 공개된 사전 학습 모델을 단 몇 줄의 코드로 불러와 미세 조정(Fine-tuning)할 수 있게 함으로써 AI 개발의 진입 장벽을 획기적으로 낮추었습니다.
실용성을 위한 다이어트: 모델 최적화 및 경량화
학습이 완료된 모델은 그대로 서비스에 투입하기에는 크기가 너무 크거나 연산 속도가 느린 경우가 많습니다. 따라서 배포 전에 모델을 경량화하고 최적화하는 과정이 필수적입니다. 이를 위해 모델의 가중치를 표현하는 정밀도를 32비트 부동소수점에서 8비트 정수 등으로 줄이는 '양자화(Quantization)', 중요도가 낮은 파라미터를 제거하는 '가지치기(Pruning)', 거대 모델의 지식을 작은 모델에 전수하는 '지식 증류(Knowledge Distillation)' 등의 기법이 소프트웨어를 통해 적용됩니다.
또한, 다양한 하드웨어 및 운영체제 환경에서 모델이 원활하게 작동할 수 있도록 형식을 변환하는 과정도 중요합니다. ONNX(Open Neural Network eXchange)는 특정 프레임워크에 종속되지 않는 표준화된 모델 형식을 제공하여, PyTorch로 만든 모델을 TensorFlow 환경이나 모바일 기기에서 구동할 수 있도록 상호운용성을 보장합니다. 하드웨어 제조사들은 자사 칩셋의 성능을 극대화하기 위해 전용 최적화 도구를 제공하는데, 엔비디아의 TensorRT나 인텔의 OpenVINO가 대표적인 사례입니다. 실제로 메타(Meta)는 이미지 분할 모델인 SAM(Segment Anything Model)을 모바일 기기에 맞게 경량화하고 ONNX로 변환하여, 추론 속도를 56배 개선하고 파이프라인 크기를 100배 이상 줄이는 성과를 거두기도 했습니다.
서비스의 접점: 모델 추론과 서빙
최적화된 모델은 실제 사용자 요청을 받아 결과를 반환하는 추론(Inference) 단계로 넘어갑니다. 이때 사용되는 것이 모델 서빙(Serving) 소프트웨어입니다. 구글의 TensorFlow Serving, PyTorch 모델을 위한 TorchServe, 그리고 엔비디아의 Triton Inference Server 등은 학습된 모델을 서버에 로드하고 다수의 요청을 효율적으로 처리할 수 있는 환경을 제공합니다. 클라우드 환경에서는 AWS SageMaker나 Google Vertex AI와 같은 관리형 서비스가 서버리스(Serverless) 형태로 추론 환경을 제공하여, 트래픽에 따라 인프라를 자동으로 확장하거나 축소하며 안정적인 서비스를 보장합니다.
데이터 센터가 아닌 스마트폰이나 IoT 기기 자체에서 AI를 구동하는 '온디바이스 AI' 혹은 '엣지 AI' 수요가 증가함에 따라, TensorFlow Lite나 애플의 Core ML과 같은 경량 추론 엔진의 중요성도 커지고 있습니다. 이러한 소프트웨어들은 네트워크 연결 없이도 기기 내부의 자원만으로 음성 인식이나 이미지 처리를 가능하게 하며, 지연 시간을 최소화하여 사용자 경험을 향상시킵니다. 서빙 시스템은 여러 요청을 묶어서 처리하는 배치(Batch) 추론이나 캐싱 기법을 통해 하드웨어 활용도를 극대화하는 방향으로 튜닝되기도 합니다.
지속 가능한 운영: MLOps와 파이프라인 자동화
인공지능 서비스는 한 번의 배포로 끝나지 않으며, 지속적인 데이터 업데이트와 모델 재학습이 필요합니다. 이러한 전체 과정을 효율적으로 관리하기 위해 소프트웨어 엔지니어링의 DevOps 개념을 도입한 MLOps(Machine Learning Operations) 가 등장했습니다. Docker와 같은 컨테이너 기술은 모델 실행 환경을 패키징하여 개발 환경과 운영 환경의 차이로 인한 오류를 방지하며, Kubernetes는 이러한 컨테이너를 대규모 클러스터 상에서 자동으로 관리하고 배포하는 오케스트레이션 역할을 수행합니다.
MLflow나 Kubeflow 같은 도구는 모델의 실험 이력을 추적하고, 새로운 데이터가 들어왔을 때 자동으로 재학습 및 배포를 수행하는 CI/CD 파이프라인을 구축하는 데 사용됩니다. 운영 단계에서는 실제 서비스 데이터가 학습 데이터와 달라지며 성능이 저하되는 '데이터 드리프트(Data Drift)' 현상을 감지하기 위해 Evidently.ai나 AWS SageMaker Model Monitor 같은 모니터링 소프트웨어가 활용됩니다. SK브로드밴드는 이러한 MLOps 파이프라인을 구축하여 영상 추천 서비스 모델의 개발부터 배포까지의 과정을 자동화하고 운영 효율을 높인 대표적인 사례입니다.
최종 가치 전달: 애플리케이션 개발과 통합
마지막으로, 준비된 AI 모델은 애플리케이션에 통합되어 최종 사용자에게 서비스로 제공됩니다. 개발자들은 모델을 직접 구현하기보다 Hugging Face Transformers 와 같은 라이브러리나 OpenCV 등을 활용하여 손쉽게 기능을 내장합니다. 또한, OpenAI API나 Google Cloud Vision API처럼 클라우드 기반의 API를 호출하는 방식은 복잡한 백엔드 인프라 없이도 강력한 AI 기능을 앱에 탑재할 수 있게 하여 AI 기술의 민주화에 기여하고 있습니다.
최근에는 거대언어모델(LLM)을 활용한 애플리케이션 개발이 활발해지면서, LangChain과 같은 오케스트레이션 프레임워크가 필수 도구로 자리 잡았습니다. LangChain은 프롬프트 관리, 외부 데이터 연동, 메모리 기능 등을 체인 형태로 연결하여 복잡한 로직의 LLM 애플리케이션을 효율적으로 구현할 수 있도록 지원합니다. 이 밖에도 MS Word나 Photoshop 같은 기존 상용 소프트웨어들이 플러그인 형태로 AI 기능을 내장하면서, 사용자 경험(UX)을 극대화하는 소프트웨어 공학적 설계가 더욱 중요해지고 있습니다.
요약 및 정책적 시사점: 소프트웨어 생태계가 곧 AI 경쟁력
본 보고서의 분석에 따르면, 인공지능 혁명의 실질적인 동력은 단순히 하드웨어의 성능 향상에만 있는 것이 아니라, 전 생애주기에 걸쳐 축적된 소프트웨어 기술의 역량에 있습니다. 무어의 법칙보다 AI 비용이 더 빠르게 감소하는 현상은 하드웨어의 발전과 더불어 소프트웨어적 최적화와 혁신이 결합되었기에 가능한 일이었습니다. 일례로 최근 등장한 딥시크(DeepSeek)와 같은 모델은 소프트웨어 기술을 적극 활용하여 기존 모델 대비 획기적으로 낮은 비용으로 동등한 성능을 구현해냈습니다.
따라서 AI 강국으로 도약하기 위해서는 하드웨어 인프라 확보에 그치지 않고, 견실한 소프트웨어 생태계를 조성하는 전략이 필수적입니다. 보고서는 이를 위해 AI 개발 전 주기를 아우르는 SW 툴체인과 플랫폼을 강화하고, 공공 및 민간에서 재사용 가능한 표준형 아키텍처를 확산해야 한다고 제언합니다. 또한, 글로벌 AI 기술의 중심이 되고 있는 오픈소스 생태계에 적극적으로 참여하여 기술력을 축적하고, 단순히 AI 모델을 만드는 것을 넘어 전체 시스템을 설계하고 운영할 수 있는 'AI 시스템 엔지니어링' 관점의 통합적 인재 양성이 시급합니다. 결국, 소프트웨어 생태계의 경쟁력이 곧 AI 경쟁력이라는 인식의 전환과 함께, 소프트웨어와 인공지능의 상보적 동반 성장을 지원하는 정책이 마련되어야 할 것입니다.
라이선스
'인공지능 혁명의 숨은 동력, 소프트웨어의 역할과 함의'에 대한 보고서는 공공누리 제4유형(출처표시-상업적이용금지-변경금지) 조건에 따라 이용할 수 있습니다.
 인공지능 혁명의 숨은 동력, 소프트웨어의 역할과 함의 보고서 원문
인공지능 혁명의 숨은 동력, 소프트웨어의 역할과 함의 보고서 원문
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()