Stable LM Zephyr 3B 소개: Stable LM에 새롭게 추기된, 엣지 디바이스에 탑재할 수 있는 강력한 LLM 어시스턴트 모델 / Introducing Stable LM Zephyr 3B: A New Addition to Stable LM, Bringing Powerful LLM Assistants to Edge Devices
주요 내용 / Key Takeaways:
- Stable LM Zephyr 3B는 7B 모델보다 60% 더 작은, 30억개의 파라매터를 가진 대형 언어 모델(LLM)로, 고사양 하드웨어 없이도 정확하고 반응성 있는 출력을 다양한 디바이스에서 가능하게 합니다.
- 모델 가중치(weight)는 여기에서 다운로드 받으실 수 있습니다.
- 이 모델의 속도 최적화 방법에 대한 예제 노트북은 여기에서 확인하실 수 있습니다.
- 이 모델은 비상업적인 용도로 사용할 수 있는 비상업용 라이선스로 배포됩니다.
- Stable LM Zephyr 3B is a 3 billion parameter Large Language Model (LLM), 60% smaller than 7B models, allowing accurate, and responsive output on a variety of devices without requiring high-end hardware.
- Download the model weights here.
- See an example notebook for how to optimize speed for this model here.
- This model is being released under a non-commercial license that permits non-commercial use.

경량 LLM 시리즈의 최신 모델인 Stable LM Zephyr 3B 모델을 공개합니다. 이 대화형(chat) 모델은 지시(instruction) 및 질의 응답(Q&A) 유형 작업에 적합하게 튜닝되었습니다. 기존의 Stable LM 3B-4e1t 모델을 기반으로 하며 HuggingFace에 공개한 Zephyr 7B 모델에서 영감을 받아 만들어졌습니다. 30억 개의 파라매터를 가진 Stable LM Zephyr 3B 모델은 간단한 질의부터 엣지 디바이스에서의 복잡한 지시 문맥(complex instructional context)에 이르기까지 다양한 텍스트 생성 요구를 효율적으로 처리할 수 있습니다.
Today, we are releasing Stable LM Zephyr 3B: a new chat model representing the latest iteration in our series of lightweight LLMs, preference tuned for instruction following and Q&A-type tasks. This model is an extension of the pre-existing Stable LM 3B-4e1t model and is inspired by the Zephyr 7B model from HuggingFace. With Stable LM Zephyr's 3 billion parameters, this model efficiently caters to a wide range of text generation needs, from simple queries to complex instructional contexts on edge devices.
학습 인사이트 / Training Insights
Stable LM Zephyr 3B 모델은 텍스트 생성 시 사람의 선호(preference)를 반영하고, 좋은 성능을 보이도록 개발하는데 초점을 맞추었습니다. Zephyr 7B 모델에서 영감을 받아 학습 파이프라인을 조정하였습니다. 첫 번째 단계로는 UltraChat, MetaMathQA, Evol Wizard Dataset, Capybara Dataset을 포함한 여러 지시형 데이터셋에 대해 지도학습(supervised fine-tuning)을 수행했습니다. 두 번째 단계에서는 UltraFeedback 데이터셋을 활용하여 Direct Preference Optimization(DPO; 직접 선호도 최적화) 알고리즘을 적용했습니다. OpenBMB 연구 그룹에서 제공하는 UltraFeedback 데이터셋은 64,000개의 프롬프트(prompt)와 해당 모델의 응답(response)을 포함하고 있습니다. 최근에 공개된 Zephyr-7B, Neural-Chat-7B, Tulu-2-DPO-70B와 같은 모델들은 모두 Direct Preference Optimization(DPO)를 사용하여 좋은 성능을 보여주었습니다. 하지만 3B 파라매터의 효율적인 크기를 갖춘 모델은 Stable Zephyr가 최초입니다.
The development of Stable LM Zephyr 3B focused on creating a model that performs well in text generation and aligns human preferences. Inspired by Zephyr 7B, we adapted its training pipeline, with the first step being supervised fine-tuning on multiple instruction datasets, including UltraChat, MetaMathQA, Evol Wizard Dataset, & Capybara Dataset. In the second step, we aligned the model with the Direct Preference Optimization (DPO) algorithm utilizing the UltraFeedback dataset. This dataset is from the OpenBMB research group and comprises 64,000 prompts and corresponding model responses. Recently released models, such as Zephyr-7B, Neural-Chat-7B, and Tulu-2-DPO-70B, successfully used Direct Preference Optimization (DPO). However, Stable Zephyr is one of the first models of this type yet with the efficient size of 3B parameters.
모델 성능 / Model Performance
MT Bench 및 AlpacaEval과 같은 플랫폼에서의 벤치마크 결과, Stable LM Zephyr 3B는 문맥적으로 연관성(relevant)과 일관성(coherent)이 있으며, 언어적으로 정확한 텍스트를 생성하는 우수한 성능을 보여주었습니다.
Benchmarked on platforms such as MT Bench and AlpacaEval, Stable LM Zephyr 3B demonstrates superior capabilities in generating contextually relevant, coherent, and linguistically accurate text.
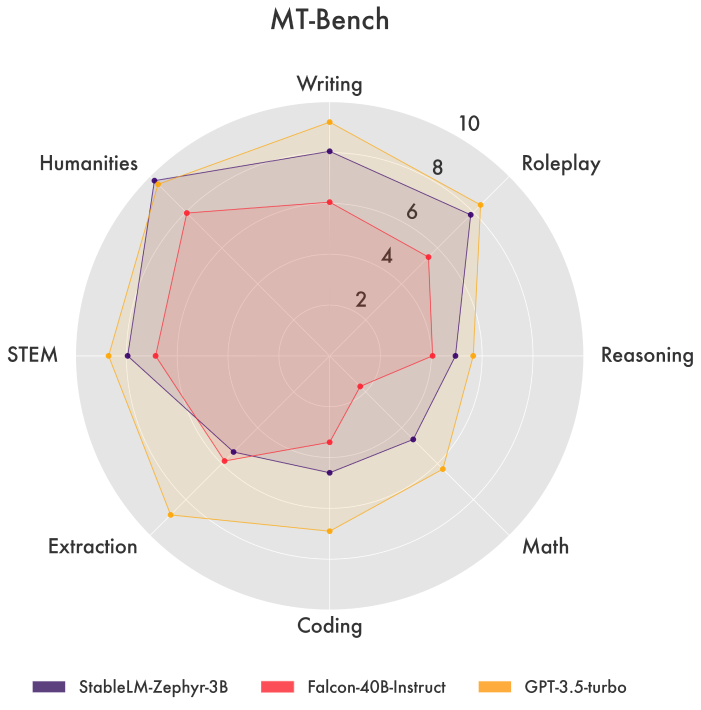
이러한 테스트에서 Stable LM Zephyr 3B의 성능은 Falcon-4b-Instruct, WizardLM-13B-v1, Llama-2-70b-chat, Claude-V1과 같은 더 큰 모델들과 비교했을 때에도 경쟁력이 있음을 확인할 수 있었습니다.
In these tests, Stable LM Zephyr 3B’s performance was found to be competitive with several larger sized models, such as Falcon-4b-Instruct, WizardLM-13B-v1, Llama-2-70b-chat, and Claude-V1.
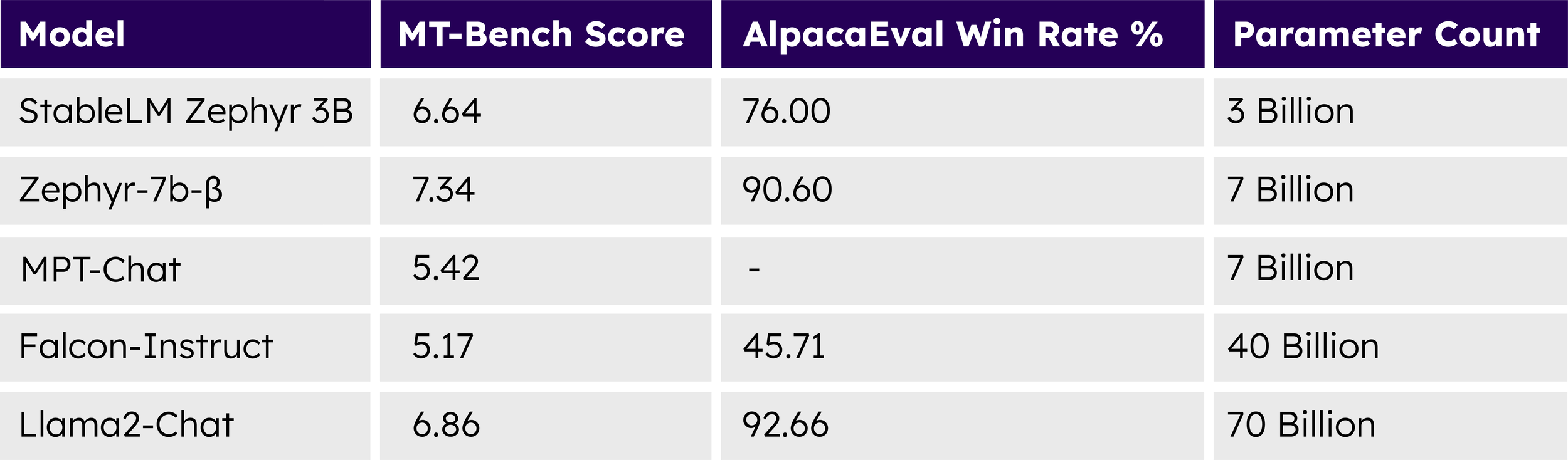
MT-Bench 점수는 개방형 질문에 대한 LLM 모델의 성능 평가에, AlpacaEval은 일반적인 사용자 지시에 따라 작동하는 능력에 초점을 맞춥니다.
MT-Bench Score is calculated using LLMs to evaluate models on open-ended questions & AlpacaEval focuses on a model’s ability to follow general user instructions.
테스트 및 데이터셋, 안전성(safety)에 대한 자세한 내용은 모델 카드에서 확인하실 수 있습니다. 요약하면, 성능 테스트 결과 Stable LM Zephyr 3B가 유사한 사용 사례에 맞춰 조정된 더 큰 모델들을 능가할 수 있는 능력을 보여줌을 확인하였으며, 새로운 모델에 내재된 강력함과 효율성을 확인할 수 있었습니다.
More details on our testing, datasets, and safety can be found in our model card. In summary, our performance tests have shown that Stable LM Zephyr 3B is capable of surpassing models of larger size tailored for similar use cases, showcasing the power and efficiency inherent in this new model.
다양한 애플리케이션 지원 / Enabling Diverse Applications
Stable LM Zephyr 3B는 가벼우면서도 정확한 모델로, 다양한 언어적 작업을 효율적이고 정확하게 처리할 수 있습니다. 이 모델은 지시형 작업(instructional task)과 질의 응답(Q&A) 유형 작업에 특화(strengthen)되어 있습니다. 이 모델은 광고 문구 작성(copywriting)과 같은 창의적인 콘텐츠 작성부터 콘텐츠 개인화나 지시문 설계에 이르기까지 다양한 복잡한 작업(application)들에 적합합니다. 또한 입력 데이터에 기반하여 강력하고 통찰력 있는 분석을 제공하기도 합니다.
이 모든 것이 7B 모델보다 60%나 더 작은 30억개의 파라매터 크기의 모델에서 가능하게 되어, 고사양 하드웨어가 없는 디바이스에서도 사용할 수 있음을 의미합니다.
Stable LM Zephyr 3B is a lightweight yet accurate model equipped to handle multiple linguistic tasks efficiently and accurately. The model has been strengthened to assist in instructional and Q&A-type tasks. It's versatile enough for various complex applications, from crafting creative content like copywriting and summarization to aiding in developing instructional design and content personalization. Additionally, it offers a powerful and insightful analysis based on the input data. All this is accomplished while retaining its efficient 3 billion parameter size, 60% smaller than 7b models, enabling use on devices lacking the computational power of dedicated high-end systems.
상업적 사용 / Commercial Applications
상업용 제품 및 목적으로 이 모델을 사용하시려면 여기로 문의하여 자세히 알아보세요.
If you want to use this model for your commercial products or purposes, please contact us here to learn more.
또한 뉴스레터를 구독하시거나 Twitter, Instagram, LinkedIn을 팔로우하시거나 Discord 커뮤니티에 가입하여 Stable AI의 최신 소식을 받아보실 수 있습니다.
You can also stay updated on our progress by signing up for our newsletter, following us on Twitter, Instagram, LinkedIn, and joining our Discord Community.