
Step-Audio-R1 모델 소개
Step-Audio-R1 은 StepFun Audio 팀이 2025년 11월 26일에 공개한 대규모 오디오 언어 모델(Audio Large Language Model)로, 오디오 데이터 처리 분야에서 오랫동안 난제로 여겨졌던 추론(Reasoning) 능력의 한계를 극복한 모델입니다. 기존의 멀티모달 모델들이 이미지를 보고 복잡한 수학 문제를 풀거나 코드를 짤 수 있었던 것과 달리, 오디오 모델들은 단순히 음성을 텍스트로 받아적거나(ASR), 간단한 분류 작업을 수행하는 데 그쳤습니다.
StepFun Audio 팀은 이번에 공개한 Step-Audio-R1 모델을 통해 텍스트 및 비전 모델에서 그 효용성이 증명된 CoT(Chain-of-Thought) 기법을 오디오 도메인에 성공적으로 이식했습니다. 즉, 이 모델은 단순히 소리를 단어로 변환하는 것을 넘어, 화자의 미세한 떨림, 배경 음악의 조성(Key), 주변의 환경 소음 등을 종합적으로 분석하여 논리적인 결론을 도출합니다. 특히 32B(320억 개) 파라미터 규모의 이 모델은 구글의 Gemini 2.5 Pro를 능가하고 최신 모델인 Gemini 3 Pro와 대등한 성능을 보여주고 있어, 향후 오디오 인공지능이 나아가야 할 방향을 제시하고 있습니다.
최근 화두인 대규모 언어 모델(LLM) 및 영상-언어 모델(VLM)의 경우에는 답변 품질을 향상시키기 위해 추가적으로 생각하는 시간(Test-time compute scaling)을 가지도록 설계하고 있습니다. 하지만 이러한 추론 시 연산 시간 확장 기법을 오디오 모델에 적용할 때에는 정반대로 모델이 길게 생각할수록 성능이 오히려 떨어지는 기이한 현상인 역전된 확장(Inverted Scaling) 문제가 발생해 왔습니다. StepFun Audio 연구팀은 이러한 문제가 모델이 소리를 직접 듣지 않고 텍스트 자막에만 의존하는 잘못된 학습 방식에서 기인했음을 밝혀내고, 이를 해결할 수 있는 새로운 기법인 MGRD(Modality-Grounded Reasoning Distillation) 프레임워크를 개발 및 적용하여 추론 능력을 극대화하였습니다.
오디오 인식 분야에서의 추론 시 연산 시간 확장(Test-Time Compute Scaling)의 딜레마
테스트 시간 확장이란 모델이 답변을 바로 생성하지 않고, 내부적으로 문제를 단계별로 분석하고 검토하는 과정(Chain-of-Thought)을 거치게 함으로써 성능을 높이는 기술입니다. 텍스트나 수학 문제에서는 이 과정이 길어질수록 정답률이 올라가는 것이 일반적입니다.
하지만 오디오 모델에서는 사고 과정을 길게 유도할수록 오히려 엉뚱한 대답을 하는 현상이 관찰되었습니다. 연구진의 분석 결과, 기존 모델들은 '소리' 그 자체를 추론의 근거로 삼는 것이 아니라, 오디오를 텍스트로 변환한 전사(Transcript) 내용에만 의존하여 추론을 진행하고 있었습니다. StepFun Audio 연구진들은 이러한 현상을 텍스트 대리 추론(Textual Surrogate Reasoning) 이라고 명명하였습니다.
예를 들어, 슬픈 멜로디의 곡을 들려주더라도, 기존 모델은 가사에 '슬픔'과 같은 단어가 없으면 곡의 분위기를 파악하지 못하거나, 가사의 내용만으로 잘못된 추론을 펼쳤습니다. 이렇게 모델이 텍스트 정보에 의존하는 경향(Semantic-based Text Think)을 보이는 원인은 기존의 오디오 모델들이 SFT(지도 미세 조정) 단계에서 텍스트 모델의 데이터를 그대로 사용하여 학습되었기 때문입니다. 이렇게 학습한 모델들은 오디오 문제를 풀 때도 소리를 듣는 대신, 전사된 텍스트(transcript)를 읽고 판단하는 언어적 추상화(Textual Abstraction) 방식에 갇혀 있었습니다.
Step-Audio-R1은 가사가 없더라도 MGRD(Modality-Grounded Reasoning Distillation)라고 하는 학습 기법을 도입하여 이러한 문제를 해결하였습니다. 이는 모델이 받아쓰기된 텍스트 대신, 오디오 신호(Acoustic Features)를 직접적으로 추론의 근거로 삼도록 학습시키는 방식입니다. MGRD 기법을 통해 Step-Audio-R1 모델은 위 예시와 같은 상황에서 '단조(Minor key)의 진행과 하강하는 멜로디 라인'이라는 음향적 특성을 근거로 슬픈 곡임을 추론해낼 수 있게 되었습니다.
Step-Audio-R1의 모델 구조
Step-Audio-R1의 모델 구조는 오디오 기반의 복합 추론을 수행하기 위해 정교하게 설계되었으며, 크게 오디오 인코더(Audio Encoder), 오디오 어댑터(Audio Adaptor), 그리고 LLM 디코더(LLM Decoder)의 세 가지 핵심 모듈로 구성되어 있습니다:
-
오디오 인코더(Audio Encoder): 첫번째 단계인 오디오 인코더는 입력된 소리 신호를 분석하여 의미 있는 특징을 추출하는 역할을 담당하며, 이를 위해 다양한 음성 및 오디오 이해 작업으로 사전 학습된 Qwen2 오디오 인코더를 채택하였습니다. 이 인코더는 25Hz의 프레임 레이트로 오디오 출력을 생성하는데, Step-Audio-R1의 전체 학습 과정 동안 파라미터가 업데이트되지 않고 고정(Frozen)된 상태를 유지한다는 점이 특징입니다. 이는 이미 강력한 오디오 이해 능력을 갖춘 인코더의 성능을 그대로 활용하면서, 후속 모듈들이 추론 능력 향상에 집중할 수 있도록 돕는 효율적인 전략입니다.
-
오디오 어댑터(Audio Adaptor): 오디오 어댑터는 오디오 인코더와 거대 언어 모델 사이를 연결하는 오디오 어댑터는 데이터의 효율적인 전송과 처리를 돕는 중요한 가교 역할을 수행합니다. Step-Audio-R1은 이전 세대의 모델인 Step-Audio 2와 동일한 구조의 어댑터를 사용하여 안정성을 확보하였으며, 이 어댑터는 인코더에서 나온 데이터를 다운샘플링(Downsampling)하여 처리합니다. 구체적으로 다운샘플링 비율을 2로 설정하여, 인코더에서 출력된 25Hz의 프레임 레이트를 12.5Hz로 줄여서 LLM 디코더에 전달합니다. 이러한 압축 과정은 오디오 신호의 핵심적인 정보는 유지하면서도, 뒤이어 연결된 거대 언어 모델이 처리해야 할 시퀀스의 길이를 줄여주어 연산 효율성을 크게 높여줍니다. 결과적으로 이 어댑터는 고해상도의 오디오 특징을 언어 모델이 이해하고 처리할 수 있는 최적의 잠재 특징(Latent features)으로 변환해 줍니다.
-
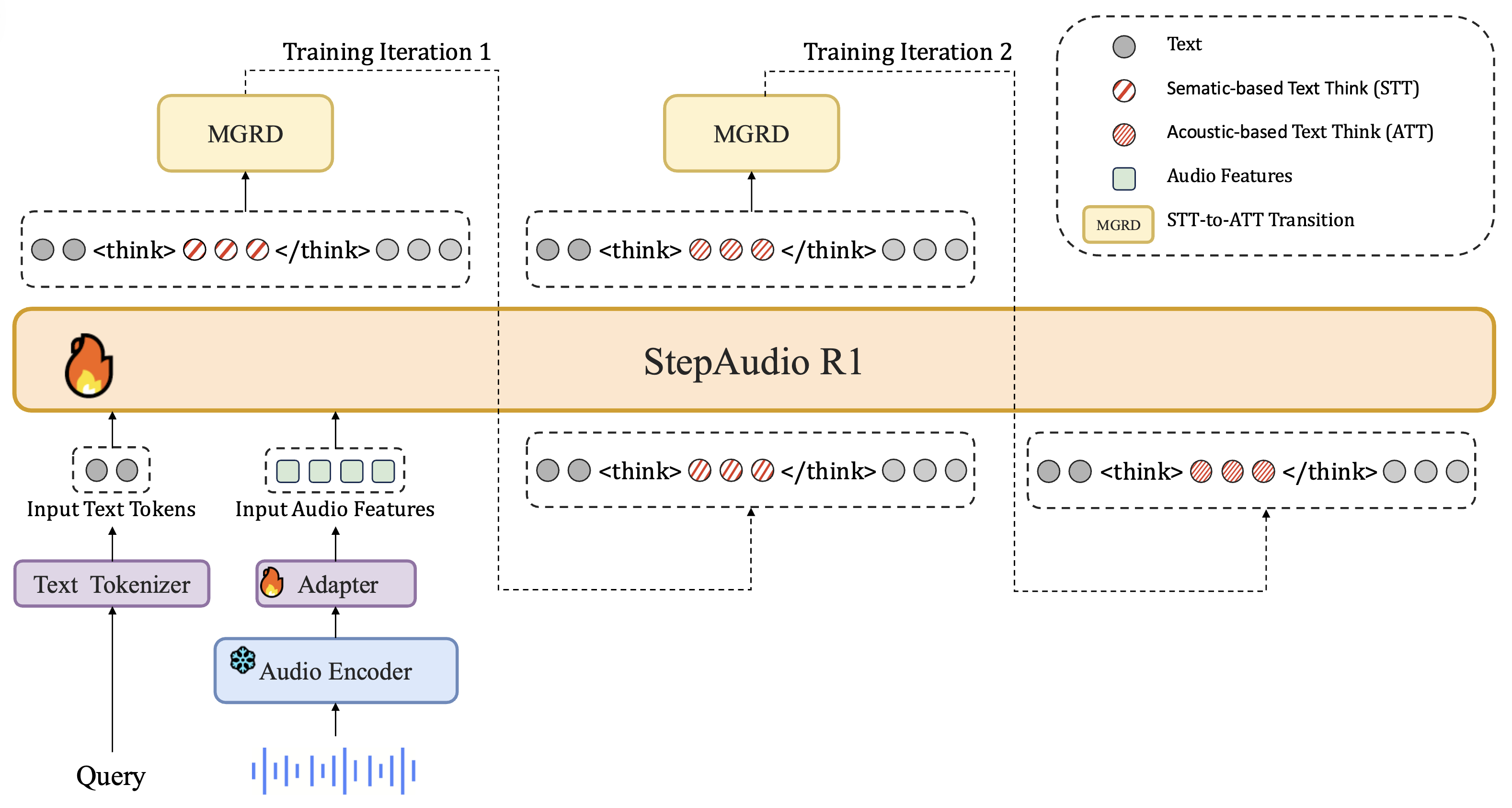
LLM 디코더(LLM Decoder): 마지막으로 시스템의 두뇌에 해당하는 LLM 디코더는 Qwen2.5-32B 모델을 기반으로 구축되어, 고차원적인 추론과 텍스트 생성을 담당합니다. 이 디코더는 오디오 어댑터를 통해 변환된 잠재 오디오 특징을 직접적인 입력으로 받아들이며, 이를 바탕으로 순수 텍스트 형태의 출력을 생성합니다. Step-Audio-R1의 구조적 혁신은 출력 방식에 있는데, 모델은 사용자의 질문에 대해 즉시 답변하는 대신 먼저
<think>태그 내에 추론 과정(Reasoning content)을 생성하고, 그 뒤에 최종 답변(Final reply)을 생성하도록 설계되었습니다. 이러한 구조는 MGRD(Modality-Grounded Reasoning Distillation) 훈련 방식과 결합되어, 모델이 텍스트 전사 내용에만 의존하지 않고 오디오의 음향적 뉘앙스에 깊이 기반한 사고 과정을 거치도록 유도합니다.
Step-Audio-R1의 사후 학습 과정 (Post-Training Recipes)
Step-Audio-R1의 핵심 경쟁력은 모델이 단순히 데이터를 암기하는 것이 아니라, 오디오 신호를 기반으로 논리적인 사고 과정을 거치도록 유도하는 사후 학습(Post-Training) 단계에 있습니다. 이 과정은 크게 초기 능력을 배양하는 '콜드 스타트', 핵심적인 추론 능력을 완성하는 'MGRD', 그리고 올바른 자기 인식을 확립하는 '교정 단계'의 3단계로 나뉘어져 있으며, 정교한 손실 함수(Loss Function)와 보상 함수(Reward Function)를 통해 모델의 행동을 제어합니다:
기초 학습: 추론 능력 초기화 및 형식 정렬 (Reasoning Initialization)
먼저 텍스트와 오디오 양쪽에서 기초적인 추론 능력을 갖추도록 하는 것을 목표로 초기 학습을 진행합니다. 이 초기 학습 단계는 1) 지도 학습 기반의 CoT 초기화(Chain-of-Thought Initialization)와 2) 검증 가능한 보상을 통한 강화학습(RLVR) 단계로 나뉘어져 있습니다:
- 지도 학습 기반의 사고 사슬 초기화 (CoT Initialization): 먼저 초기 오디오-언어 모델(Audio Language Model) \pi_{\theta_0} 에 3종류의 학습 데이터를 사용하여 학습합니다. 각각은 (1) 추론 단계가 있는 질문/답변 데이터 (q, r, a), (2) 맥락이 포함된 대화 데이터 (c, r, s), (3) 오디오 질문에 대한 직접적인 답변 데이터 (x_{audio}, q, a) 이며, 오디오 데이터의 경우에는 형식을 유지하기 위해 빈 추론 마커(예:
<think>\n\n</think>\n)를 사용합니다. 3종류의 데이터는 다음의 통합된 손실 함수를 최소화하는 방향으로 학습합니다:
이 단계에서 모델은 논리적인 사고의 흐름(r)과 함께, 오디오 신호(x_{audio})에 대해 올바른 답변을 하는 멀티모달 이해력 유지에 집중하게 됩니다.
- 검증 가능한 보상을 통한 강화 학습 (RLVR): 위와 같이 기초 학습을 완료한 모델은 RLVR(Reinforcement Learning with Verified Rewards) 기법으로 추가 학습을 수행하며 정답을 맞히는 능력을 강화합니다. 수학이나 코딩 문제에서 모델이 생성한 추론(r)과 답(a)에 대해 정답이 맞거나 틀렸을 경우에 대해 1과 0의 이진 보상(Binary Reward)을 부여합니다.
이 때, 모델은 PPO(Proximal Policy Optimization) 알고리즘을 통해 기대 보상(Expected Reward)을 최대화하는 방향으로 업데이트됩니다:
이 과정에서는 모델이 기존의 학습 분포에 갇히지 않고 자유롭게 추론 전략을 탐색할 수 있도록 KL 패널티(KL Penalty) 제약 조건을 제거하여 최적화합니다.
MGRD (Modality-Grounded Reasoning Distillation) 기반 학습
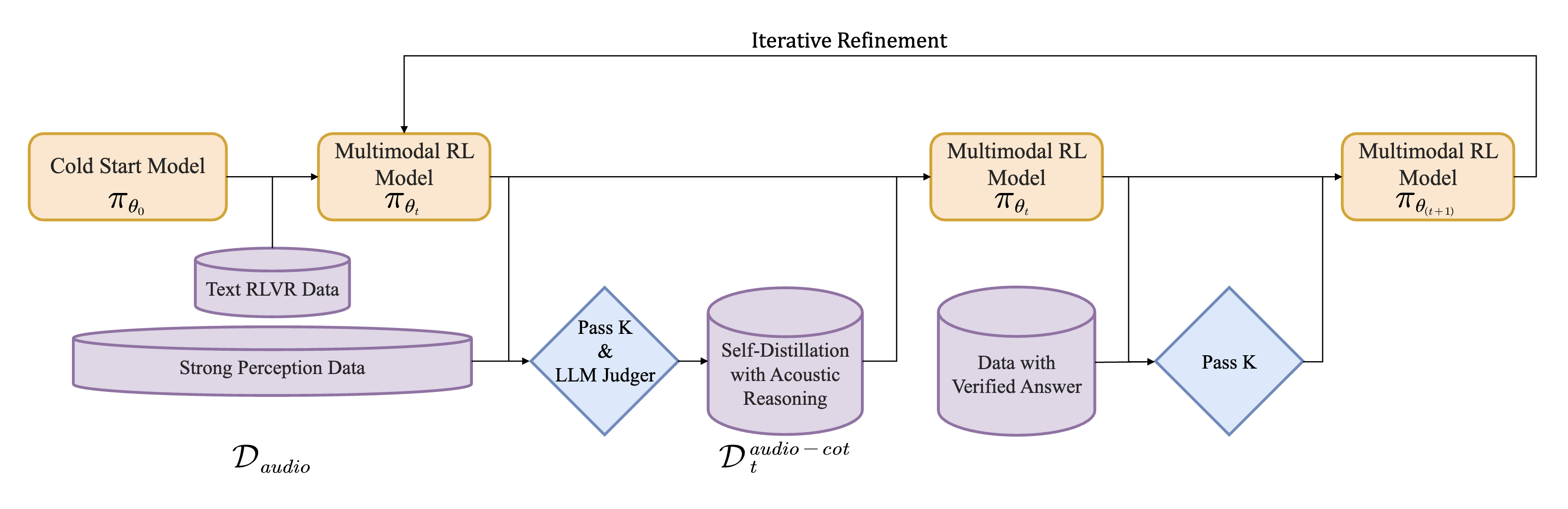
Modality-Grounded Reasoning Distillation (MGRD) 프레임워크는 Step-Audio-R1 모델이 가진 기술적 혁신의 정점으로, 오디오 언어 모델이 단순히 텍스트를 읽는 수준을 넘어 소리의 물리적 특성을 깊이 있게 분석하고 추론하도록 훈련시키는 핵심 방법론입니다. 기존의 오디오 모델들은 추론 시간을 늘릴수록 성능이 오히려 떨어지는 '역전된 확장(Inverted Scaling)' 현상을 겪었는데, 이는 모델이 오디오 신호 자체보다는 전사된 텍스트나 캡션에 의존하는 텍스트 대리 추론(Textual Surrogate Reasoning)을 수행했기 때문입니다. MGRD는 이러한 한계를 극복하기 위해 모델의 추론 기반을 텍스트적 추상화에서 오디오의 실제 음향적 속성으로 전환하여, 진정한 의미의 심층적인 사고(Deliberate Thinking)가 가능하도록 설계되었습니다.
본격적인 MGRD 학습에 앞서, 모델은 이전에 설명한 초기 추론 능력 설정(Cold-Start Phase) 단계를 거쳐야 합니다. 이 과정은 아무것도 모르는 상태에서 바로 오디오 추론을 가르치는 것이 아니라, 먼저 지도 미세 조정(SFT) 및 검증된 보상을 활용한 강화 학습(RLVR) 을 통해 기초적인 추론의 틀을 잡는 선행 작업입니다. 모델은 수학이나 코딩 같은 텍스트 데이터와 ASR(음성 인식) 같은 오디오 데이터를 함께 학습하며 기본적인 멀티모달 능력을 배양합니다. 다만, 이 단계의 모델은 추론의 형식은 갖추었을지라도 그 내용은 여전히 텍스트 중심적 사고에 머물러 있어, 소리의 깊은 뉘앙스까지는 파악하지 못하는 한계가 있습니다.
이러한 기초 위에 반복적 자기 증류 및 정제(Iterative Self-Distillation and Refinement) 과정이 수행됩니다. 이 과정의 첫 단추는 음향 기반 추론을 위한 자기 증류(Self-Distillation) 입니다. 연구팀은 오디오 데이터셋에서 단순히 의미를 묻는 질문이 아니라, 음색, 피치, 리듬 등 직접적인 음향 특징을 분석해야만 풀 수 있는 질문들을 엄선합니다. 그리고 현재 모델에게 이 질문들에 대해 음향적 근거를 명시적으로 언급하며 추론하도록 유도합니다. 이렇게 생성된 수많은 답변 후보들은 엄격한 필터링 과정을 거치는데, 텍스트 설명이 아닌 실제 소리의 특징을 근거로 들었는지, 논리가 타당한지, 그리고 정답을 맞혔는지를 모두 만족하는 답변만이 고품질 데이터셋(\mathcal{D}_{audio-cot}^{t})으로 선별됩니다.
선별된 고품질 데이터는 다중 모드 지도 정제(Multimodal Supervised Refinement) 단계에서 모델을 미세 조정하는 데 사용됩니다. 이때 중요한 것은 모델이 새로운 오디오 추론 능력을 배우는 동안 기존에 가지고 있던 텍스트 사고력을 잃어버리지 않도록 하는 것입니다. 이를 위해 연구팀은 선별된 오디오 추론 데이터와 기존의 텍스트 추론 데이터(\mathcal{D}_{task})를 함께 학습시키는 공동 학습(Joint Training) 전략을 취했습니다. 이에 따른 학습 목적 함수는 다음과 같이 오디오와 텍스트에 대한 로그 우도(Log-likelihood)의 합으로 정의됩니다:
마지막으로, 모델이 올바른 추론 습관을 완전히 내재화하도록 멀티모달 강화 학습(Multimodal Reinforcement Learning) 을 수행하였습니다. 이 단계의 핵심은 학습 데이터의 선별과 보상 함수의 설계에 있습니다. 연구팀은 모든 데이터를 무작위로 사용하는 대신, 모델이 8번 시도했을 때 3~6번 정도 정답을 맞힐 수 있을 정도의 적당히 어려운 문제(Pass@8 \in [3, 6]) 들을 선별하여 학습 효율을 극대화했습니다. 또한, 모델이 정답을 맞히기 위해 추론 과정을 생략하는 추론 붕괴(Reasoning Collapse)를 방지하기 위해 복합 보상 구조를 도입했습니다. 텍스트 질문에는 단순한 정답 여부만을 평가하지만, 오디오 질문에 대해서는 정답 정확도에 0.8점, 추론 과정의 존재 여부에 0.2점을 부여하여 '생각하는 과정' 자체에 인센티브를 제공합니다:
모델은 PPO(Proximal Policy Optimization) 알고리즘을 통해 이러한 보상의 총합을 최대화하는 방향으로 최적화되며, 이때 KL 페널티(KL-Penalty) 계수를 0으로 설정하여 모델이 자유롭게 새로운 추론 전략을 탐색할 수 있도록 했습니다:
결과적으로 MGRD의 반복적인 학습 과정을 거친 Step-Audio-R1은 "가사에 슬픔이 언급되어 슬프다"는 식의 일차원적인 해석에서 벗어나, "단조 진행과 하강하는 멜로디 윤곽이 느껴진다"는 식의 진정한 음향 분석(Genuine Acoustic Analysis) 을 수행하게 됩니다. 이는 오디오 모델에서도 추론 시간을 늘릴수록 성능이 향상되는 추론 시점의 연산 스케일링(Test-Time Compute Scaling) 효과를 이끌어내며, 오디오 지능의 새로운 지평을 열었습니다.
Step-Audio-R1 성능 평가 및 심층 분석 (Evaluation & Empirical Analysis)
Step-Audio-R1의 진가는 엄격한 성능 평가와 그 내부 작동 원리를 규명하는 실증적 연구(Empirical Study)를 통해 더욱 명확히 드러납니다. 연구팀은 단순히 모델의 우수성을 주장하는 데 그치지 않고, 텍스트-음성 변환(Speech-to-Text) 및 음성-음성 대화(Speech-to-Speech) 벤치마크를 통해 객관적인 수치를 제시했습니다. 또한, 학습 과정에서 발견한 보상 함수의 역할이나 데이터 선별의 중요성 등에 대한 통찰들을 분석하여 오디오 모델 연구에 중요한 이정표를 남겼습니다.
Speech-to-Text 벤치마크 평가: 글로벌 SOTA 모델과의 경쟁
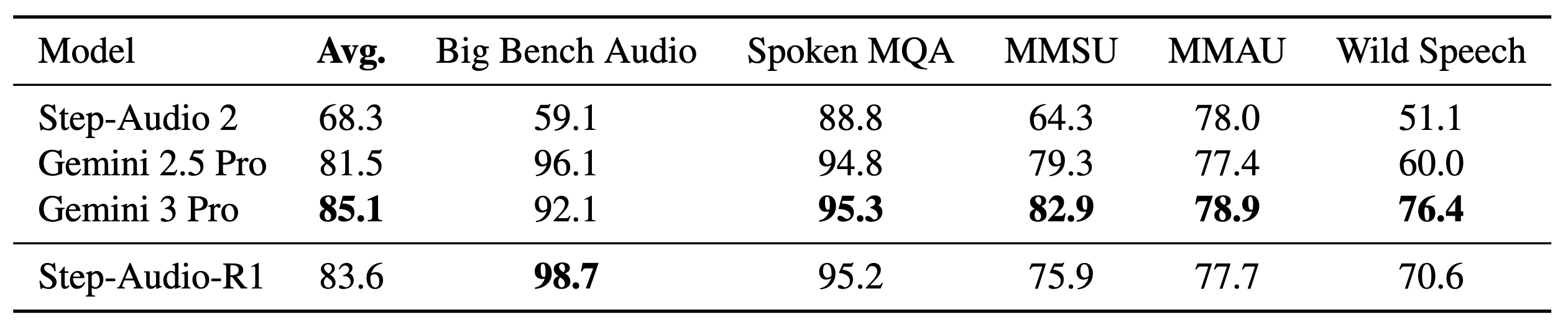
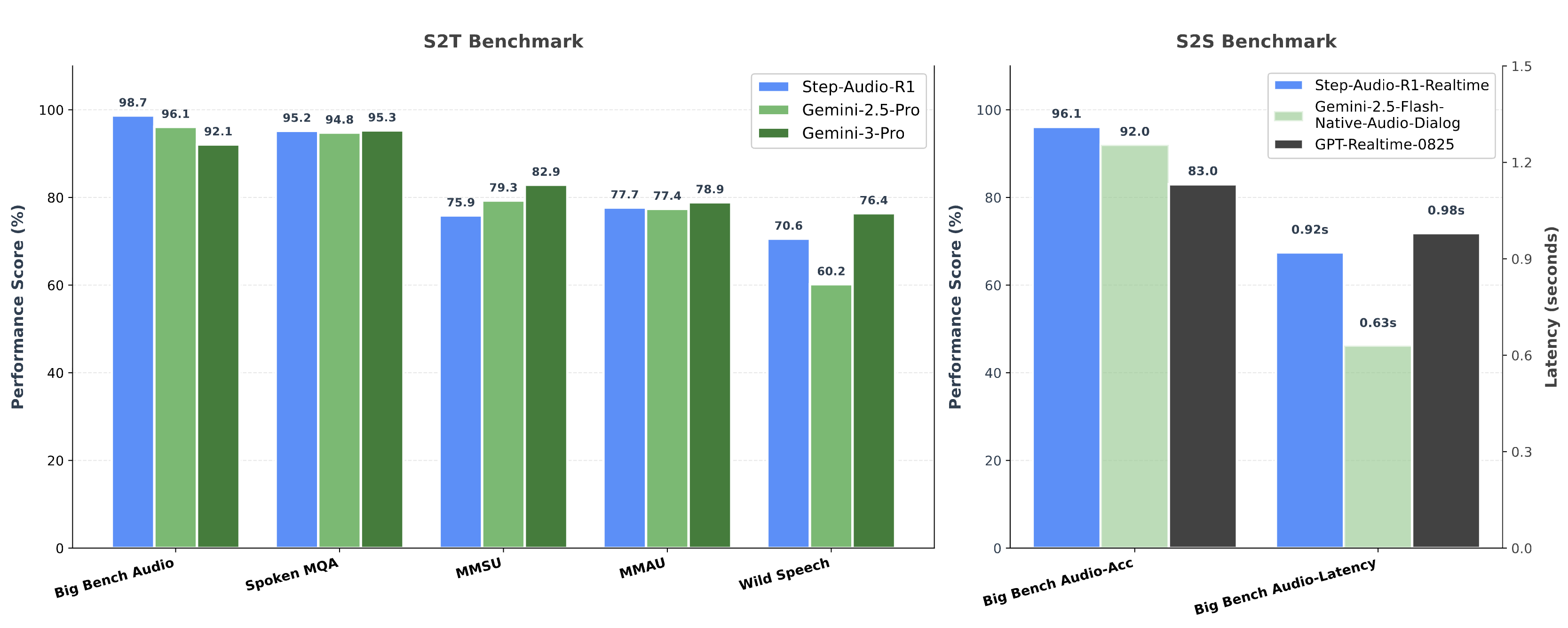
StepFun AI 연구팀은 Step-Audio-R1의 성능을 객관적으로 검증하기 위해 복합적인 오디오 이해 능력을 요구하는 5가지 주요 벤치마크에서 평가를 진행했습니다. 비교 대상으로는 자사의 이전 모델인 Step-Audio 2뿐만 아니라, 구글의 최신 모델인 Gemini 2.5 Pro와 Gemini 3 Pro를 선정하여 체급이 다른 거대 모델들과 직접 경쟁했습니다. 평가에 사용된 벤치마크는 전문가 수준의 오디오 이해를 묻는 MMSU와 MMAU, 다단계 논리 추론이 필요한 Big Bench Audio, 수학적 추론을 구두로 수행하는 Spoken MQA, 그리고 자연스러운 대화형 음성을 다루는 Wild Speech로 구성되었습니다.
평가 결과, Step-Audio-R1은 이들 벤치마크에서 평균 83.6%의 점수를 기록하며 놀라운 성과를 보였습니다. 이는 강력한 경쟁자인 Gemini 2.5 Pro의 평균 점수 81.5%를 명확히 앞서는 수치이며, 현존하는 최고 성능의 모델 중 하나인 Gemini 3 Pro(85.1%)와 비교해도 크게 뒤처지지 않는 수준입니다. 특히 주목할 점은, Step-Audio-R1이 Gemini 시리즈에 비해 상대적으로 작은 32B 파라미터 규모를 가졌음에도 불구하고, 오디오 신호에 기반한 깊이 있는 추론(MGRD)을 통해 대규모 모델들과 대등한 경쟁을 펼쳤다는 사실입니다. 이는 MGRD 프레임워크가 모델의 체급 차이를 극복할 만큼 효율적인 오디오 이해 도구임을 방증합니다.
Speech-to-Speech 벤치마크 평가: 실시간성과 추론의 양립

단순히 녹음된 파일을 분석하는 것을 넘어, 사용자와 실시간으로 대화하며 추론하는 능력은 실제 서비스 적용에 있어 필수적입니다. 연구팀은 이를 평가하기 위해 'Big Bench Audio speech-to-speech' 벤치마크를 활용하였으며, 두 가지 핵심 지표인 음성 추론 점수(Speech Reasoning Performance Score) 및 대화의 유창성을 나타내는 지연 시간(Latency)을 측정했습니다. 평가를 위해 Step-Audio-R1을 실시간 처리에 최적화한 Step-Audio-R1 Realtime 모델을 별도로 구축했습니다.
결과는 매우 고무적이었습니다. Step-Audio-R1 Realtime 모델은 96.1%라는 압도적인 음성 추론 점수를 기록하며, GPT-4o mini Realtime(69%)이나 Gemini 2.5 Flash Native Audio(92%)와 같은 타사의 실시간 모델들을 모두 제쳤습니다. 더욱 인상적인 것은 이러한 높은 정확도를 유지하면서도 0.92초의 첫 패킷 지연 시간(First-packet Latency)을 달성했다는 점입니다. 통상적으로 1초 미만의 지연 시간은 사용자가 대화의 끊김을 거의 느끼지 못하는 수준으로 간주됩니다. 즉, Step-Audio-R1 Realtime은 "깊이 생각하는 능력"과 "즉각 반응하는 속도"라는, 상충하기 쉬운 두 가지 목표를 동시에 달성하며 차세대 대화형 AI로서의 가능성을 입증했습니다.
심층 분석: 오디오 추론을 완성하는 결정적 요인들
연구팀은 단순히 결과만 제시한 것이 아니라, 모델의 성능을 결정짓는 몇 가지 핵심 요인들에 대한 심층 분석(Ablation Study) 결과도 공개했습니다.
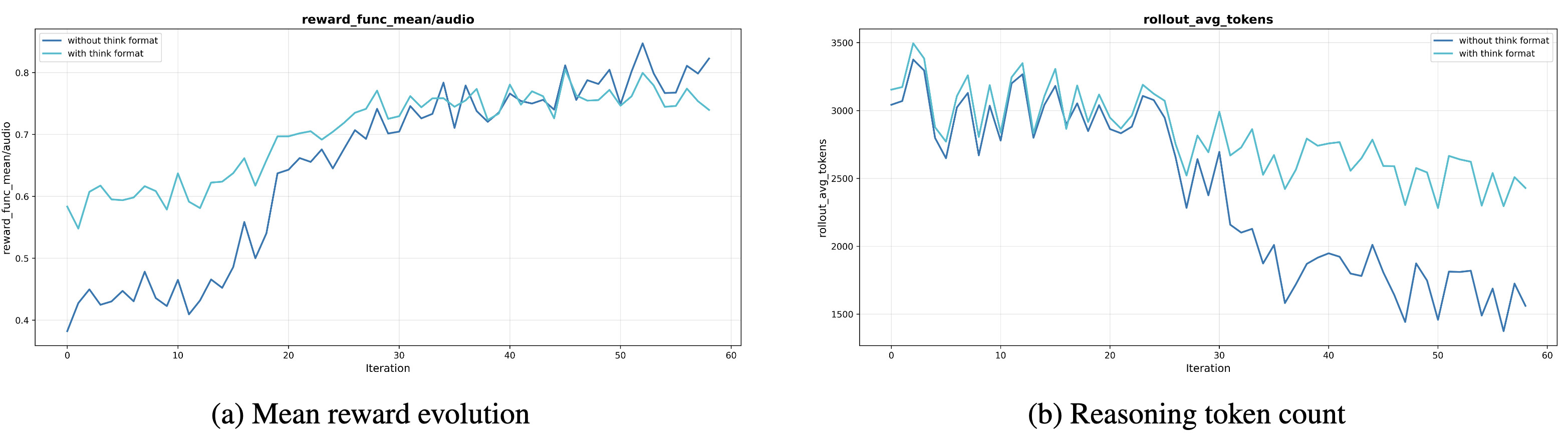
추론 붕괴 방지를 위한 형식 보상(Format Reward)의 필요성: 앞서 설명한 MGRD의 강화 학습 단계에서 형식 보상(Format Rewards, 0.2점)을 도입한 것이 실제로 어떤 효과를 냈는지를 검증했습니다. 연구팀은 형식 보상 없이 정답 여부(1.0점)만으로 모델을 훈련시키는 비교 실험을 진행했습니다. 실험 결과는 충격적이었습니다. 형식 보상이 없는 모델(파란색 선)은 훈련이 진행될수록 추론의 길이가 급격히 짧아지는 현상을 보였습니다. 초기에는 3,000토큰 수준이었던 추론 길이가 60번의 반복(Iteration) 후에는 1,500토큰 미만으로 떨어지며 추론 붕괴(Reasoning Collapse) 가 발생했습니다. 반면, 형식 보상을 적용한 모델(청록색 선)은 2,300~2,800토큰 수준의 긴 추론 과정을 끝까지 유지했습니다.
이러한 현상이 발생하는 이유는 강화 학습의 본질적인 특성 때문입니다. 모델은 보상을 최대화하기 위해 가장 효율적인 경로를 찾으려 하는데, 형식에 대한 제약이 없으면 '골치 아프게 생각하지 않고 그냥 답만 맞히는 방향'으로 최적화되기 십상입니다. 형식 보상(Format Reward)은 모델에게 '생각하는 과정 그 자체도 중요하다'는 신호를 줌으로써, 모델이 효율성의 함정에 빠지지 않고 끈기 있게 오디오를 분석하도록 강제하는 안전장치 역할을 수행했습니다.
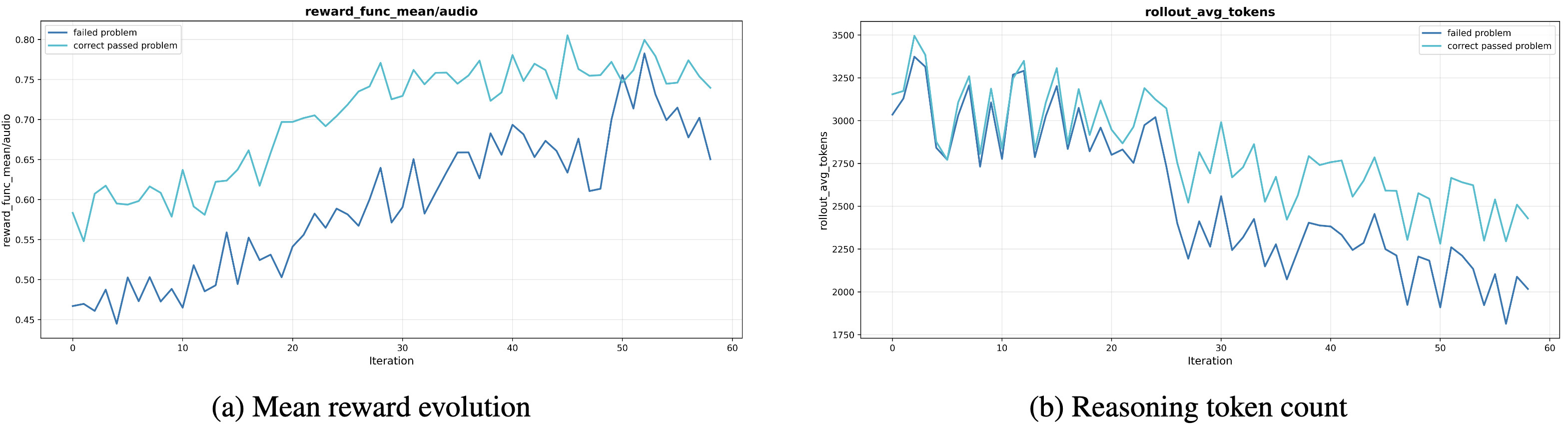
데이터 선별의 중요성 - 양보다 질 (Quality Over Quantity): "데이터는 많을수록 좋은가?"라는 통념에 대해 StepFun Audio 연구팀은 "아니오"라고 답합니다. 연구팀은 강화 학습 단계에서 어떤 데이터를 사용할지에 대해 세 가지 전략을 비교했습니다. (1) 모델이 계속 틀리는 어려운 문제, (2) 8번 중 3~6번 정도 맞히는 적당히 어려운 문제, (3) 난이도 상관없이 데이터를 20만 개로 늘린 경우입니다.
실험 결과, '적당히 어려운 문제'를 사용했을 때의 결과가 가장 좋았습니다. 계속 틀리는 문제만 모아서 학습시킨 경우, 모델은 정답으로 가는 길을 찾지 못해 헤매다가 결국 추론 능력이 퇴보하고 말았습니다. 이는 오디오 정보 자체가 불명확하여 아무리 들어도 답을 알 수 없는 '노이즈' 데이터가 섞여 있었기 때문입니다. 반면, 적당히 어려운 문제는 모델에게 "성공의 경험"과 "실패의 교훈"을 동시에 제공하여 학습 효율을 극대화했습니다. 놀라운 점은 데이터를 20만 개로 무작정 늘렸을 때도 성능 향상이 전혀 없었다는 것입니다. 이는 오디오 추론 학습에서 데이터의 큐레이션 전략이 단순한 물량 공세보다 훨씬 중요하다는 사실을 시사합니다.
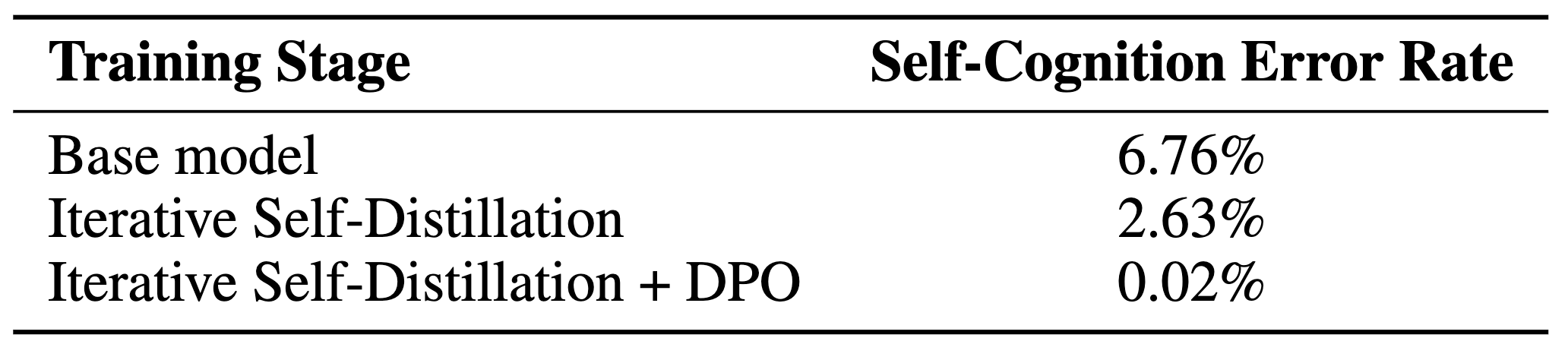
환각 제거를 위한 자기 인식의 교정: 마지막으로, 텍스트 데이터로 학습된 거대 언어 모델이 흔히 겪는 자기 인식 오류(Self-Cognition Error) 문제를 다뤘습니다. 학습 초기, 베이스 모델은 오디오를 입력받아도 "저는 텍스트 모델이라 소리를 들을 수 없습니다"라고 대답하는 비율이 6.76%나 되었습니다. StepFun Audio 연구팀은 이를 해결하기 위해 두 단계의 교정 과정을 거쳤습니다. (1) 먼저 자기 증류(Self-Distillation) 과정을 통해 오류율을 2.63%로 낮추었고, 이후 8,000쌍의 선호도 데이터(Preference Pair)를 활용한 DPO(Direct Preference Optimization) 를 적용하여 오류율을 0.02%까지 획기적으로 줄였습니다. 이는 모델의 잘못된 편향(Bias)은 적절한 데이터와 훈련 방식만 있다면 완벽에 가깝게 교정할 수 있음을 보여주는 사례입니다.
결론 (Conclusion)
Step-Audio-R1 모델은 오랜시간 오디오 언어 모델들이 겪어왔던 역전된 확장(Inverted Scaling) 문제의 근본 원인이 텍스트 대리 추론(Textual Surrogate Reasoning) 에 있음을 규명하고, 이를 해결하기 위한 MGRD(Modality-Grounded Reasoning Distillation) 프레임워크를 제안했습니다. Step-Audio-R1은 MGRD를 통해 오디오의 물리적 특성에 기반한 진정한 추론 능력을 확보함으로써, 오디오 도메인에서도 "깊이 생각할수록 더 똑똑해지는(Test-time compute scaling)" 모델을 만들 수 있음을 세계 최초로 증명했습니다. 특히, Gemini 3 Pro와 같은 최신 모델과 어깨를 나란히 하는 성능은, 향후 멀티모달 AI가 나아가야 할 방향이 각 모달리티의 고유한 특성에 기반한 Grounded Reasoning 영역에 있음을 강력하게 시사합니다.
 Step-Audio-R1 프로젝트 홈페이지
Step-Audio-R1 프로젝트 홈페이지
 Step-Audio-R1 데모 사용해보기 (Hugging Face Space)
Step-Audio-R1 데모 사용해보기 (Hugging Face Space)
 Step-Audio-R1 기술 문서 (Technical Paper)
Step-Audio-R1 기술 문서 (Technical Paper)
 Step-Audio-R1 모델 GitHub 저장소
Step-Audio-R1 모델 GitHub 저장소
 Step-Audio-R1 모델 다운로드
Step-Audio-R1 모델 다운로드
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()