
Step-Audio 소개
Step-Audio는 이해와 생성 기능을 통합한 최초의 오픈소스 프레임워크로, 다국어 대화(중국어, 영어, 일본어 등), 감정 표현(기쁨, 슬픔 등), 지역 방언(광둥어, 사천어 등), 조절 가능한 말하기 속도, 그리고 랩과 같은 다양한 운율 스타일을 지원합니다. 특히 130B(1300억) 파라미터를 갖춘 멀티모달 모델을 기반으로 음성 인식, 의미 이해, 음성 합성, 음성 복제 등 다양한 기능을 수행할 수 있습니다.
Step-Audio는 기존 TTS(Text-to-Speech) 시스템의 한계를 극복하기 위해 개발된 차세대 음성 AI 프레임워크입니다. 기존 TTS 모델들은 대량의 수동 데이터 수집이 필수적이었지만, Step-Audio는 “생성형 데이터 엔진(Generative Data Engine)” 을 활용해 고품질 음성 데이터를 자동으로 생성합니다. 이를 통해 더 적은 자원으로도 높은 품질의 음성 합성이 가능합니다.
Step-Audio의 주요 특징들은 다음과 같습니다:
-
130B 파라미터 멀티모달 모델: 음성 인식, 의미 이해, 대화, 음성 복제 및 음성 합성을 통합한 대규모 모델.
-
생성형 데이터 엔진: 수동 데이터 없이도 자체적으로 음성 데이터를 생성하여 더 효율적인 학습 가능.
-
세밀한 음성 제어: 감정(기쁨, 분노, 슬픔), 방언(광둥어, 사천어 등), 스타일(랩, 허밍) 등의 세부 조절 지원.
-
고급 지능 탑재: 도구 호출 기능(ToolCall)과 롤플레잉 기법을 활용하여 복잡한 작업 수행 가능.
이러한 특징을 통해 Step-Audio는 단순한 음성 합성 기술을 넘어 더욱 자연스러운 인간-컴퓨터 인터랙션을 가능하게 하는 것을 목표로 합니다.
Step-Audio 모델 구조 및 개요
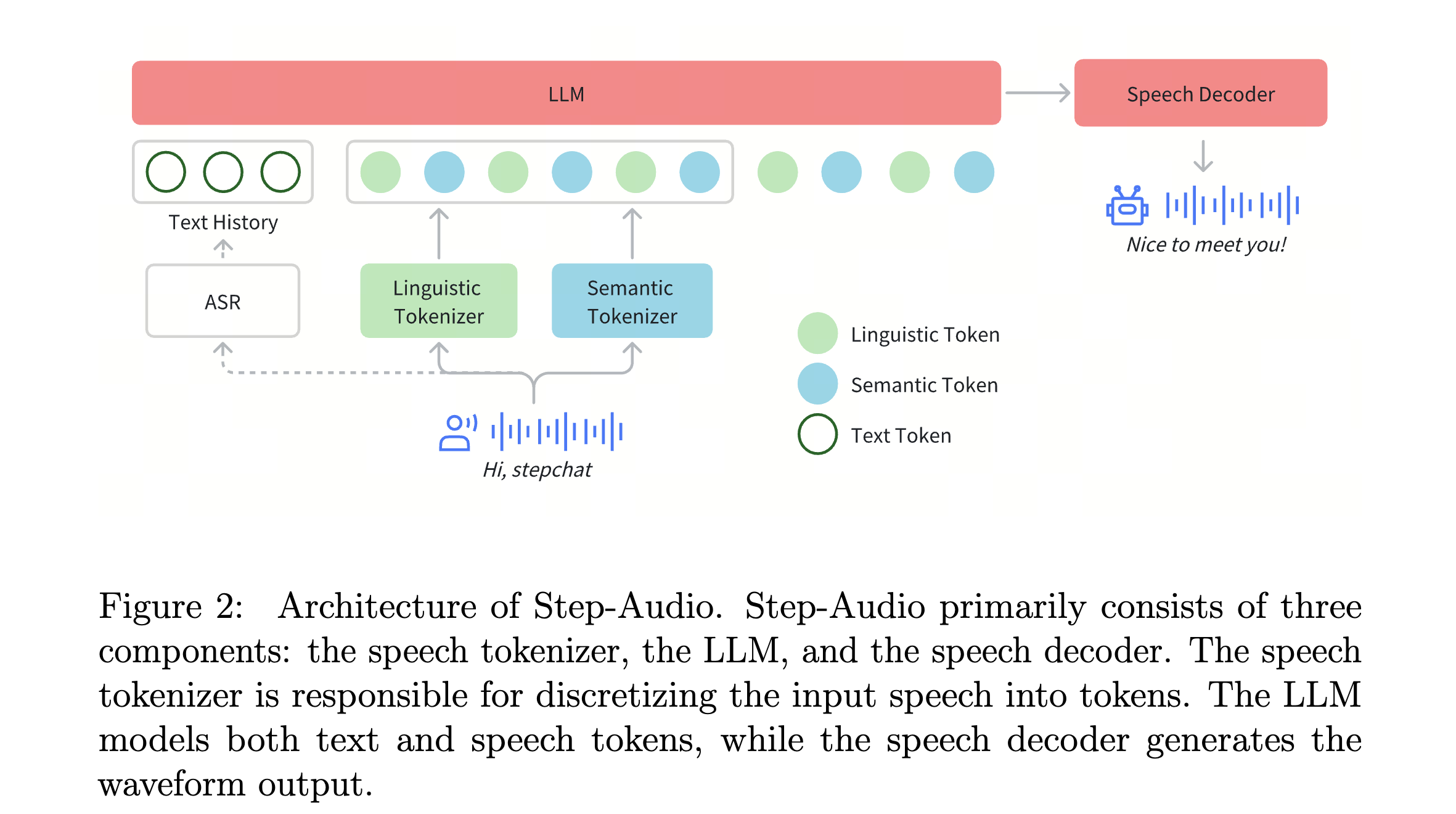
Step-Audio는 듀얼 코드북(Dual-Codebook) 프레임워크 를 활용하여 오디오 스트림을 토크나이징합니다. 이는 병렬 의미 토크나이저(16.7Hz, 1024개 코드북 엔트리) 와 음향 토크나이저(25Hz, 4096개 코드북 엔트리) 를 결합하고, 2:3 비율의 시간 인터리빙(temporal interleaving) 을 적용하여 더욱 정밀한 음성 처리를 가능하게 합니다.
130B(1300억) 파라미터 규모의 대형 언어 모델(LLM) 기반(Step-1) 으로, 오디오 문맥을 반영한 지속적 프리트레이닝(continual pretraining) 및 작업별 후처리 학습(post-training) 을 통해 강력한 크로스-모달 음성 이해(cross-modal speech understanding)를 제공합니다. 또한, Flow Matching과 신경망 보코딩(Neural Vocoding) 을 결합한 하이브리드 음성 디코더(hybrid speech decoder) 를 탑재하여 실시간 음성 파형 생성을 최적화하였습니다.
추가적으로, Step-Audio는 스트리밍 대응 아키텍처(streaming-aware architecture) 를 갖추고 있으며, 사전 응답 생성(speculative response generation, 40% commit rate) 과 텍스트 기반 문맥 관리(text-based context management, 14:1 압축률) 기능을 통해 효율적인 크로스모달 정렬을 지원합니다.
토크나이저(Tokenization)
Step-Audio는 음성을 의미적 토큰(semantic token)과 음향적 토큰(acoustic token)의 이중 코드북(Dual-Codebook)으로 분리하여 처리합니다:
- 의미 토큰(Semantic Token): 1024개 코드북 을 사용하며 16.7Hz 속도로 처리
- 음향 토큰(Acoustic Token): 4096개 코드북 을 사용하며 25Hz 속도로 처리
- 2:3 비율로 두 토큰을 정렬 하여 보다 자연스러운 음성 생성이 가능
대형 언어 모델 (LLM) 기반 음성 처리
Step-Audio는 130B 파라미터 규모의 LLM 을 기반으로 음성을 이해하고 생성합니다:
- Step-1이라는 사전 학습된 대형 LLM을 활용하여 음성-텍스트 정렬 학습 진행
- 추가적으로 오디오 컨텍스트를 반영한 지속적인 프리트레이닝 적용
- 이를 통해 더 정교한 음성 인식 및 합성이 가능
고급 음성 디코더(Speech Decoder)
- Step-Audio의 음성 디코더는 흐름 정합 모델(Flow Matching)과 멜-투-웨이브(Mel-to-Wave) 보코더를 결합 하여 고품질 음성을 생성.
- 이중 코드 인터리빙(Dual-Code Interleaving) 기법 을 통해 의미적/음향적 특성을 자연스럽게 결합.
실시간 추론(Real-time Inference)
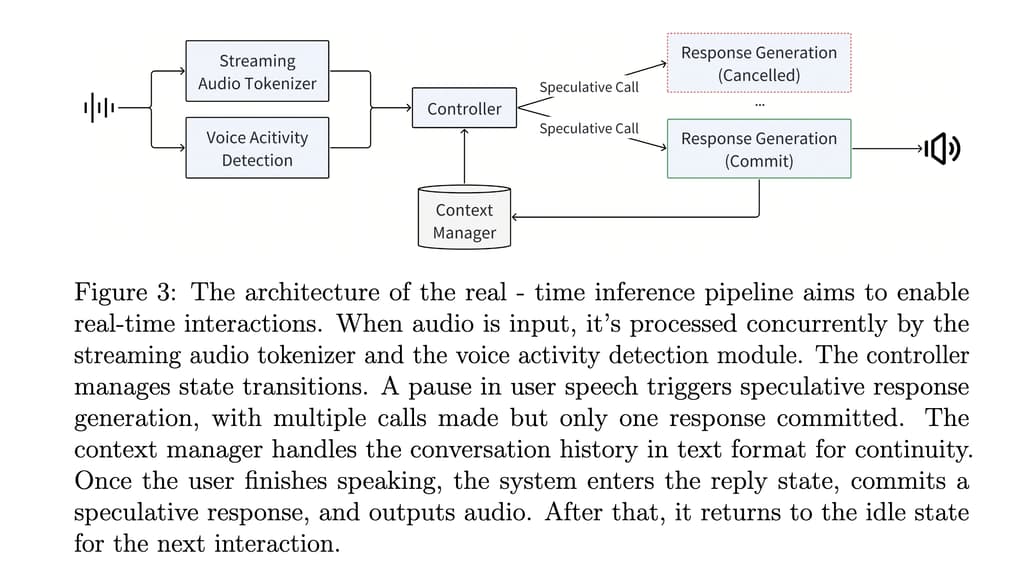
Step-Audio는 실시간 대화 를 가능하게 하기 위해 최적화된 추론 파이프라인을 설계하였습니다. 이 파이프라인의 핵심은 Controller 모듈 로, 상태 전환을 관리하고 사전 응답 생성(speculative response generation) 을 조율하며 각 하위 시스템을 원활하게 연동합니다:
- Voice Activity Detection (VAD): 사용자의 음성을 실시간으로 감지하여 대화의 시작과 끝을 파악
- Streaming Audio Tokenizer: 입력 음성을 빠르게 처리하여 토큰화, 실시간 응답을 위한 핵심 요소
- Step-Audio 언어 모델: 음성을 이해하고 텍스트 기반 응답을 생성하는 핵심 AI 모델
- Speech Decoder: 생성된 텍스트를 자연스러운 음성으로 변환하여 사용자에게 출력
- Context Manager: 대화의 흐름을 유지하여 맥락을 반영한 자연스러운 대화 가능
특히 사전 응답 생성(Speculative Response Generation) 기능을 도입하여, 40%의 확률로 미리 응답을 생성하여 속도를 최적화하였습니다. 또한, 텍스트 기반 문맥 관리(Text-based Context Management) 를 활용하여 최대 14:1의 압축 비율 로 메모리 사용을 최적화하였습니다.
후처리 및 강화 학습
Step-Audio는 기본 모델 학습 이후 특정 작업에 맞춰 추가적인 후처리 학습(Post-training)을 진행합니다:
-
지도 학습 기반 미세 조정 (Supervised Fine-Tuning, SFT):
- 자동 음성 인식(ASR, Automatic Speech Recognition) 및 음성 합성(TTS, Text-to-Speech) 성능 향상을 위해 SFT 적용.
- 다양한 고품질 데이터셋을 활용하여 모델의 일반화 성능을 극대화.
-
강화 학습 (Reinforcement Learning from Human Feedback, RLHF)
- 사용자 피드백을 활용한 RLHF 기법을 적용하여 응답 품질을 지속적으로 개선.
- 감정 표현, 말하기 속도, 방언, 운율(Prosody) 등을 세밀하게 조절 할 수 있도록 모델을 최적화.
이러한 후처리 과정을 통해 더욱 자연스럽고 직관적인 음성 인터랙션 이 가능하며, 사용자 맞춤형 음성 합성을 구현할 수 있습니다.
라이선스
Step-Audio 프로젝트 코드는 Apache-2.0 라이선스로 공개되어 있습니다.
 Step-Audio 논문
Step-Audio 논문
 Step-Audio GitHub 저장소
Step-Audio GitHub 저장소
https://github.com/stepfun-ai/Step-Audio
 Step-Audio 모델 다운로드 링크
Step-Audio 모델 다운로드 링크
| Models | Hugging Face | ModelScope |
|---|---|---|
| Step-Audio-Tokenizer | ||
| Step-Audio-Chat | ||
| Step-Audio-TTS-3B |
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()