Taalas의 첫 번째 제품, HC1: 하드웨어로 구현된 Llama 3.1 8B

압도적인 성능의 HC1 보드
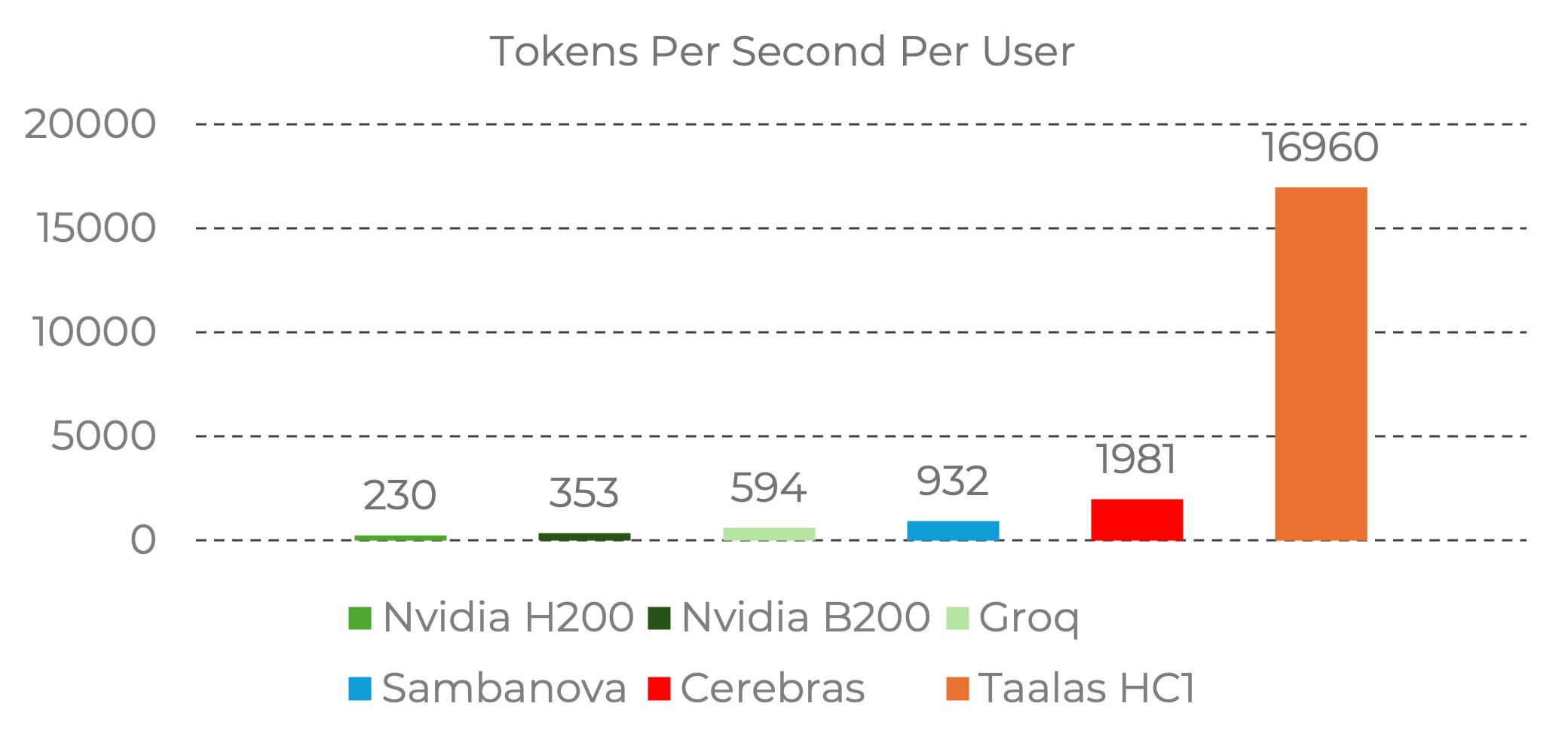
Taalas가 자사의 철학을 바탕으로 선보인 첫 번째 제품은 Llama 3.1 8B 모델을 하드웨어로 직접 구워낸(Hard-wired) HC1 보드입니다. 현재 챗봇 데모 및 추론 API 서비스 형태로 제공되는 이 제품은 사용자당 초당 17,000 토큰(17K tokens/sec/user)이라는 경이로운 처리 속도를 기록했습니다. 이는 Nvidia의 H200 및 B200, 그리고 Groq, Cerebras 등 현존하는 최고 수준의 경쟁 기술과 비교해도 무려 10배 가까이 빠른 수치입니다. 더 놀라운 것은 이러한 성능을 내면서도 구축 비용은 20배 저렴하고, 전력 소비는 10배 적다는 점입니다.
하드와이어링의 유연성과 양자화(Quantization) 타협점
속도를 극대화하기 위해 모델을 하드웨어에 고정했음에도 불구하고, Taalas의 Llama는 실용적인 유연성을 잃지 않았습니다. 컨텍스트 윈도우(Context Window) 크기를 사용자가 설정할 수 있으며, LoRA(Low-Rank Adapters)를 통한 파인튜닝(Fine-tuning) 기능도 완벽히 지원합니다. 다만 초기 1세대 칩셋을 설계할 당시에는 저정밀도 파라미터 포맷이 표준화되지 않았기에, 자체적인 3-bit 기본 데이터 유형을 사용했습니다. 이로 인해 3-bit와 6-bit 파라미터를 결합한 공격적인 양자화가 적용되어 GPU 벤치마크 대비 약간의 품질 저하가 존재합니다. 하지만 곧 도입될 2세대 실리콘에서는 표준 4-bit 부동소수점 포맷을 채택하여 속도를 유지하면서도 이 문제를 완전히 해결할 예정입니다.
Taalas 소개
현재 인공지능(AI)은 특정 도메인에서 이미 인간의 성능을 능가하며, 인류의 창의성과 생산성을 전례 없는 수준으로 증폭시키는 도구로 자리 잡았습니다. 하지만 이러한 AI가 우리 일상과 모든 산업 전반에 널리 채택되기 위해서는 높은 지연 시간(Latency)과 천문학적인 비용이라는 두 가지 거대한 장벽을 넘어야만 합니다. 언어 모델과의 상호작용은 인간의 인지 속도에 비해 한참 뒤처져 있으며, 코딩 어시스턴트가 답변을 생성하기 위해 몇 분씩 고민하는 현상은 개발자의 몰입을 방해합니다. 나아가 밀리초(ms) 단위의 반응 속도가 필수적인 자율 에이전트 AI 애플리케이션의 경우, 지금의 지연 시간으로는 정상적인 서비스 구현이 불가능에 가깝습니다.
또한 최신 AI 모델을 배포하기 위해서는 엄청난 규모의 엔지니어링 역량과 자본이 요구됩니다. 수백 킬로와트의 전력을 소비하는 방 크기의 슈퍼컴퓨터, 정교한 액체 냉각 시스템, 고급 패키징 기술, 적층형 메모리(HBM) 및 수 마일에 달하는 케이블이 필요하며, 이는 곧 도시 크기의 데이터 센터 인프라와 막대한 운영 비용으로 직결됩니다. 과거 컴퓨팅의 역사를 돌아보면, 초기에는 진공관과 케이블로 가득 찬 거대하고 느린 ENIAC이 컴퓨팅의 마법을 선보였지만, 결국 이를 대체하고 컴퓨팅의 대중화를 이끈 것은 작고 효율적인 트랜지스터였습니다. 오늘날의 AI 역시 범용 컴퓨팅이 그랬던 것처럼, 누구나 구축하기 쉽고 빠르며 저렴해지는 과정을 거쳐야만 합니다.
약 2년 반 전에 설립된 Taalas는 이러한 문제를 근본적으로 해결하기 위해, 어떠한 AI 모델이든 맞춤형 실리콘(Custom Silicon)으로 변환할 수 있는 혁신적인 플랫폼을 개발했습니다. 이들은 이전에 본 적 없는 새로운 모델을 전달받더라도 단 2개월 만에 이를 실제 하드웨어로 구현해 냅니다. 이렇게 탄생한 하드코어 모델(Hardcore Models)은 기존 소프트웨어 및 GPU 기반의 구현 방식과 비교할 때 속도, 비용, 전력 소모 등 모든 면에서 자릿수가 다른 차원의 혁신적인 성능을 제공하며 AI의 진정한 대중화를 앞당기고 있습니다.
기존 AI 하드웨어 아키텍처와 비교
기존의 범용 GPU 기반 AI 인프라는 근본적으로 '메모리 장벽(Memory Wall)'이라는 구조적 한계를 안고 있습니다. 데이터를 저장하는 메모리(DRAM)와 이를 처리하는 연산 장치가 물리적으로 분리되어 있어, 각기 다른 속도로 작동하는 과정에서 엄청난 병목 현상이 발생합니다. 이로 인해 GPU 제조사들은 HBM(High Bandwidth Memory)과 같은 고가의 3D 적층 메모리와 고급 패키징 기술, 그리고 막대한 I/O 대역폭을 강제적으로 도입해야만 했습니다. 결과적으로 칩당 전력 소비가 급증하고 액체 냉각 시스템이 필수가 되는 악순환이 발생합니다.
반면 Taalas의 아키텍처는 메모리와 연산의 경계를 완전히 허무는 접근 방식을 취합니다. 단일 칩 내에 DRAM 수준의 밀도로 저장소와 컴퓨팅을 통합함으로써, 기존 아키텍처에서 필수적이었던 HBM, 3D 패키징, 초고속 I/O 및 액체 냉각 기술을 모두 제거했습니다. 이처럼 모델에 완벽히 맞춰진 특화 실리콘을 통해 하드웨어 스택 전체를 첫 원리(First Principles)에서부터 재설계하여, 기존 시스템 대비 전체 구축 비용과 전력을 획기적으로 낮추면서도 비교할 수 없는 속도를 달성했습니다.
Taalas의 핵심 철학과 아키텍처
완전한 전문화 (Total Specialization)
컴퓨팅의 역사에서 핵심 워크로드를 처리할 때 가장 확실한 효율성 확보 방법은 언제나 '깊은 수준의 전문화'였습니다. Taalas는 AI 추론(Inference)이야말로 인류가 직면한 가장 중요한 연산 워크로드이며, 전문화를 통해 얻을 수 있는 이득이 가장 크다고 판단했습니다. 따라서 이들은 범용 하드웨어를 사용하는 대신, 각각의 개별 AI 모델에 최적화된 맞춤형 실리콘을 생산하는 완전한 전문화 전략을 채택했습니다.
저장소와 연산의 통합 (Merging Storage and Computation)
현대 추론 하드웨어를 괴롭히는 가장 큰 문제는 고밀도의 저렴한 외부 DRAM과 고속의 온칩(On-chip) 메모리 간의 속도 차이입니다. 오프칩 DRAM에 접근하는 것은 온칩 메모리보다 수천 배 느리기 때문에 병목이 발생합니다. Taalas는 이러한 한계를 극복하기 위해 저장소와 연산을 단일 칩에 통합했습니다. DRAM 수준의 데이터 밀도를 유지하면서도 컴퓨팅 장치를 결합하여 기존에 불가능했던 수준의 대역폭과 효율성을 달성했습니다.
극단적인 단순화 (Radical Simplification)
특정 모델에 맞춰 실리콘을 설계하고 메모리와 연산의 경계를 없앰으로써, Taalas는 불필요한 하드웨어의 복잡성을 완전히 덜어냈습니다. HBM이나 첨단 패키징, 수냉식 쿨링 등 다루기 어렵고 값비싼 이색적인 기술들에 의존할 필요가 없어졌습니다. 이러한 엔지니어링적 단순화는 시스템 총 비용(TCO)을 이전 세대 대비 10분의 1 수준으로 절감하는 핵심 비결이 되었습니다.
Taalas의 향후 로드맵과 팀 철학
다가오는 차세대 모델과 HC2 아키텍처
Taalas의 두 번째 모델 역시 1세대 실리콘 플랫폼인 HC1을 기반으로 하며, 중간 크기의 추론 특화 LLM으로 올봄 연구실 테스트를 거쳐 곧바로 API 서비스에 통합될 예정입니다. 나아가 올겨울에는 2세대 실리콘 플랫폼인 HC2를 기반으로 제작된 프론티어급 LLM(Frontier LLM)을 배포할 계획입니다. HC2 아키텍처는 1세대 대비 훨씬 높은 회로 밀도와 한층 더 빠른 실행 속도를 제공하여 더욱 복잡한 모델을 완벽하게 소화해 낼 것입니다.
소수 정예 팀이 만들어낸 막대한 효율성
Taalas는 20년 이상 호흡을 맞춰온 소규모 핵심 인력들을 중심으로 운영되며, 현재 규모에 집착하기보다 기술적 장인정신과 엄격함을 중시합니다. 벤처 자금을 쏟아붓고 수많은 인력을 투입하는 일반적인 딥테크 스타트업들과 달리, Taalas의 첫 번째 제품은 불과 24명의 팀원이 개발해 냈습니다. 또한 유치한 2억 달러 이상의 자금 중 단 3,000만 달러만 사용하여 이 모든 성과를 이룩함으로써, 명확히 정의된 목표와 엄격한 집중력이 무조건적인 자본 동원(Brute force)보다 우월하다는 것을 증명하고 있습니다.
 Taalas 공식 홈페이지
Taalas 공식 홈페이지
 Taalas의 HC1 기반 챗봇 데모
Taalas의 HC1 기반 챗봇 데모
 Taalas 관련 문서/블로그
Taalas 관련 문서/블로그
 Taalas의 추론 API 신청 양식
Taalas의 추론 API 신청 양식
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()