
Tensorlake 소개
Tensorlake는 비정형 문서에서 구조화된 데이터를 추출하고, 이를 기반으로 서버리스 방식의 데이터 처리 및 오케스트레이션 API를 구축할 수 있는 플랫폼입니다. 이 프로젝트는 특히 대규모 문서 처리가 필요한 기업 환경에서 활용도를 높일 수 있으며, 단순한 OCR 도구를 넘어서 다양한 문서 유형(PDF, Word, Excel, 이미지 등)을 마크다운이나 스키마 기반 구조화 데이터로 변환하는 기능을 제공합니다.
Tensorlake의 가장 큰 장점은 "서버리스(Serverless)" 아키텍처 기반이라는 점입니다. Python으로 작성된 Durable Function 기반의 워크플로우를 정의하고, 이를 클라우드 상에 배포함으로써 복잡한 데이터 파이프라인을 코드로 정의하고 관리할 수 있습니다. 덕분에 개발자는 인프라에 대한 고민 없이 문서 파싱과 데이터 처리 로직에만 집중할 수 있습니다.
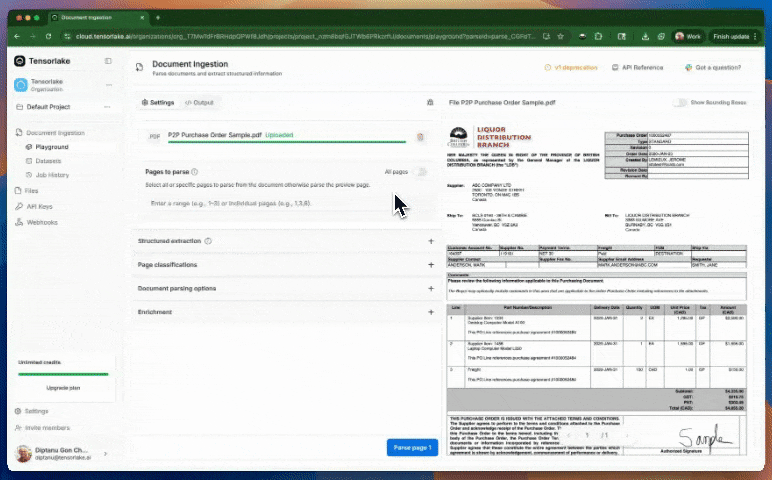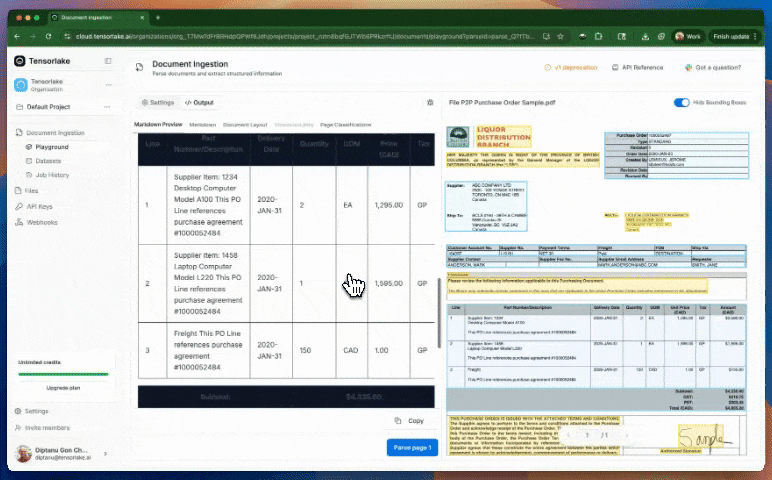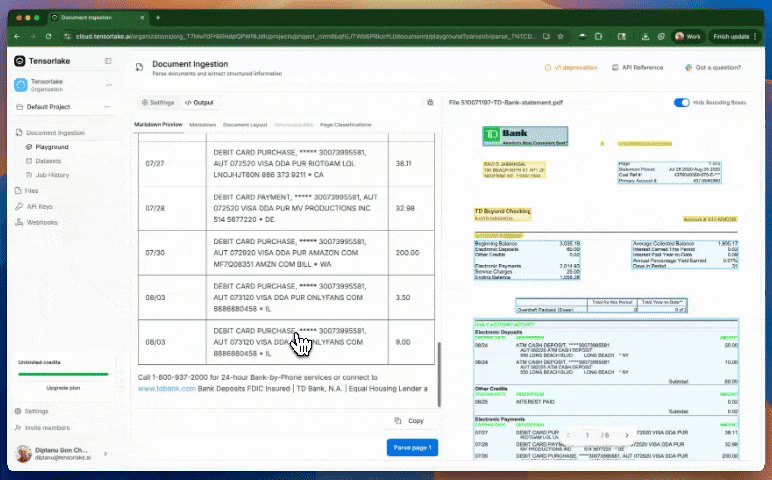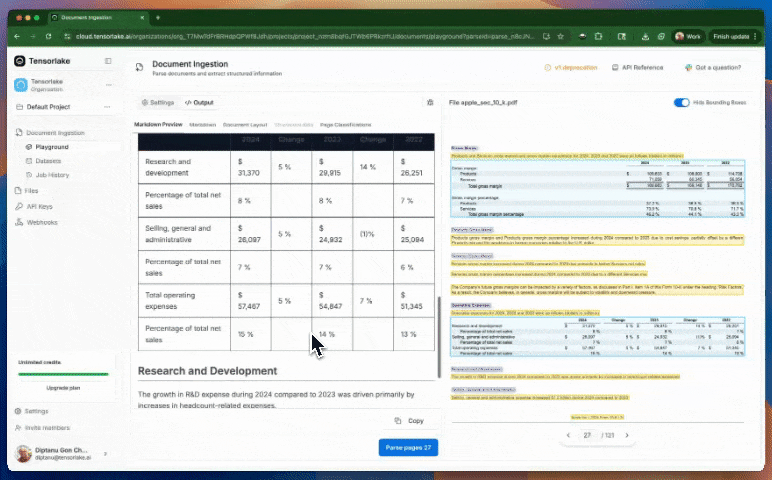
또한 이 플랫폼은 자체 개발한 레이아웃 인식 및 테이블 추출 모델을 활용하여 문서 내의 복잡한 구조도 정교하게 인식할 수 있습니다. 단순히 텍스트를 OCR로 추출하는 수준을 넘어, 시각적 구조나 의미 단위로 문서를 나누는 기능까지 지원합니다. 이러한 기능은 금융, 법률, 의료, 공공 데이터 등에서 대규모 문서 데이터를 자동으로 처리해야 하는 상황에서 유용하게 사용할 수 있을 것으로 보입니다.
Tensorlake는 문서 OCR 및 AI 기반 데이터 추출 영역에서 경쟁자라 할 수 있는 Amazon Textract, Google Document AI, Azure Form Recognizer 등과 유사한 기능을 제공합니다. 그러나 주된 차별점은 다음과 같습니다:
-
워크플로우 기반의 서버리스 API: Tensorlake는 문서 처리 로직을 워크플로우 형태로 조합할 수 있도록 지원합니다. 이는 단순한 추출을 넘어 문서 인식 → 구조화 추출 → 후처리 → 저장/분석까지 파이프라인 전체를 Python 함수 형태로 정의/구성하고 자동화할 수 있습니다.
-
로컬 및 클라우드 실행 모두 지원: 워크플로우를 로컬에서 개발하고 테스트한 후, Tensorlake 클라우드에 배포하여 확장성 있는 형태로 운영할 수 있습니다.
-
JSON Schema와 Pydantic 모델 기반의 구조화 추출: 사용자는 추출하고자 하는 데이터를 스키마로 명시하여 정형화된 형태의 데이터를 추출할 수 있습니다. 이를 통해 기존 데이터 관리 시스템과 통합할 수 있으며, 결과물의 신뢰도를 높일 수 있습니다.
-
파이썬 친화적인 API 디자인: 모든 기능은 Python SDK를 통해 손쉽게 호출 가능하며, 예제도 매우 직관적으로 구성되어 있어 개발자의 학습 곡선을 낮춰줍니다.
Tensorlake의 주요 기능
문서 파싱 및 적재 (Document Ingestion)
Tensorlake는 다양한 문서 형식을 지원하며, 이를 마크다운 또는 구조화된 형태로 파싱합니다. 이를 위해 DocumentAI 클래스를 사용하며, 사용자는 다음 과정을 거치게 됩니다:
- API Key 발급 및 SDK 설치
- 문서 업로드 (
upload) - 파싱 요청 (
parse) - 완료 대기 및 결과 수신 (
wait_for_completion)
기본 파싱 외에도 다음과 같은 세부 기능 조정이 가능합니다:
- 구역 나누기(chunking): 문서를 의미 단위로 분할
- 서명 인식(signature detection): 서명 영역 자동 감지
- 테이블 포맷 지정: 테이블 데이터를 HTML 등으로 반환
- 테이블/이미지 요약: 시각 요소를 요약된 형태로 추출
구조화 데이터 추출 (Structured Extraction)
파싱된 데이터에서 특정 항목만 추출하고 싶은 경우, Tensorlake는 두 가지 방식의 구조화 추출을 지원합니다:
- Pydantic 모델 기반: Python 코드 내에서 데이터 구조 정의
- JSON Schema 기반: 표준 JSON 형식으로 스키마 정의
이를 통해 예를 들어, 인보이스 문서에서 invoice_number, total_amount, due_date 등의 항목을 명시적으로 추출할 수 있습니다. 이는 다양한 기업 시스템과의 연계에 필수적인 기능입니다.
서버리스 워크플로우 구성 (Serverless Data Workflows)
Tensorlake의 워크플로우는 Python 함수로 구성된 DAG 형태로 정의됩니다. 이때 각 함수는 @tensorlake_function() 데코레이터를 통해 명시되며, Graph 객체를 이용해 함수 간 연결을 설정합니다.
예를 들어, 다음과 같은 방식으로 동작하는 워크플로우를 생각해볼 수 있습니다:
- 숫자 시퀀스를 생성하고,
- 각 숫자를 제곱한 후,
- 합산하고,
- 웹 서비스에 전송
이러한 데이터 흐름을 통해 추출된 데이터를 후속 시스템으로 연결하거나, 복잡한 후처리 파이프라인을 구성할 수 있습니다.
워크플로우는 로컬 실행 및 Tensorlake 클라우드 배포가 모두 가능하며, RemoteGraph 클래스를 통해 클라우드 상에서 실행 결과를 관리할 수 있습니다.
Tensorlake 사용 예시: 이미지에서 구조화된 데이터 추출하기
Tensorlake는 단순한 문서 처리뿐 아니라 이미지에서도 정보를 추출해 구조화된 데이터로 전환할 수 있는 기능을 제공합니다. 다음 예시는 운전면허증 이미지에서 개인 정보를 추출하는 애플리케이션을 Tensorlake 서버리스 환경에 배포하고 실행하는 전 과정을 보여줍니다.
구조화 데이터 모델 정의 및 함수 작성
먼저 필요한 라이브러리를 불러오고, 구조화된 데이터 모델과 추출에 사용할 함수 등을 정의한 structured_extraction.py 파일을 작성합니다:
# structured_extraction.py
import os
import base64
import requests
from pydantic import BaseModel
from tensorlake.applications import application, function, Image, RequestError
# 추가 패키지 설치 포함된 커스텀 이미지 정의
image = Image().run("pip install openai pydantic requests")
# 시크릿 키 등록 (OPENAI API 키 등)
secrets = ["OPENAI_API_KEY"]
# 추출할 데이터 구조 정의
class DrivingLicense(BaseModel):
name: str
date_of_birth: str
address: str
license_number: str
license_expiration_date: str
# 추출 함수 정의
@application()
@function(image=image, secrets=secrets)
def extract_driving_license_data(url: str) -> DrivingLicense:
from openai import OpenAI
response = requests.get(url)
response.raise_for_status()
image_base64 = base64.b64encode(response.content).decode("utf-8")
content_type = response.headers.get("content-type", "")
if "jpeg" in content_type or "jpg" in content_type:
image_format = "jpeg"
elif "png" in content_type:
image_format = "png"
else:
image_format = "jpeg"
openai = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
response = openai.beta.chat.completions.parse(
model="gpt-4o-mini",
messages=[
{
"role": "system",
"content": "Extract the personal information from the driving license image.",
},
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": f"data:image/{image_format};base64,{image_base64}"
},
}
],
},
],
response_format=DrivingLicense,
)
return response.choices[0].message.parsed
비밀 정보 등록 (Secrets)
이후, OpenAI API Key와 같은 주요 환경변수들을 Secrets로 등록하여 관리합니다:
tensorlake secrets set OPENAI_API_KEY=<YOUR_OPENAI_API_KEY>
Tensorlake는 이렇게 등록된 Secrets를 실행 시점에 환경변수로 함수에 주입합니다.
애플리케이션 배포
다음과 같은 명령어를 사용하여 위에서 작성한 structured_extraction.py를 배포합니다:
tensorlake deploy structured_extraction.py
Tensorlake는 이 과정에서 위 코드를 포함한 커스텀 이미지를 빌드하고 함수 코드 전체를 클라우드에 배포합니다.
애플리케이션 호출/사용
curl -N -X POST https://api.tensorlake.ai/applications/driving_license_extractor \
-H "Authorization: Bearer $TENSORLAKE_API_KEY" \
-H "Content-Type: application/json" \
-H "Accept: application/json" \
-d '"https://tlake.link/dl"'
요청 시에는 추출할 예시 운전면허증 이미지의 URL을 JSON 문자열로 전달합니다.
처리 후 DrivingLicense 클래스 형태의 구조화된 JSON 데이터가 응답으로 반환됩니다.
라이선스
Tensorlake 프로젝트는 MIT 라이선스로 공개 및 배포 되고 있습니다. 상업적 사용에 제한이 없습니다.
 Tensorlake 공식 홈페이지
Tensorlake 공식 홈페이지
 Tensorlake 문서 사이트
Tensorlake 문서 사이트
 Tensorlake 프로젝트 GitHub 저장소
Tensorlake 프로젝트 GitHub 저장소
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()