The LLM Evaluation Guidebook / LLM 평가 가이드북
-
저자 / Authors: Clémentine Fourrier, Thibaud Frere, Guilherme Penedo, Thomas Wolf
-
발행일 / Published: 2025년 12월 3일
서론: LLM 평가의 본질과 목적
대규모 언어 모델(LLM)의 세계를 항해하다 보면, 모델을 직접 학습하든, 미세 조정(Fine-tuning)하든, 혹은 단순히 애플리케이션에 적용할 모델을 선택하든 필연적으로 "어떤 모델이 좋은 모델인가?"라는 질문에 봉착하게 됩니다. 이 질문에 대한 답은 여러분이 '모델 빌더(Model Builder)'인가 혹은 '모델 사용자(Model User)'인가에 따라 근본적으로 달라집니다 .
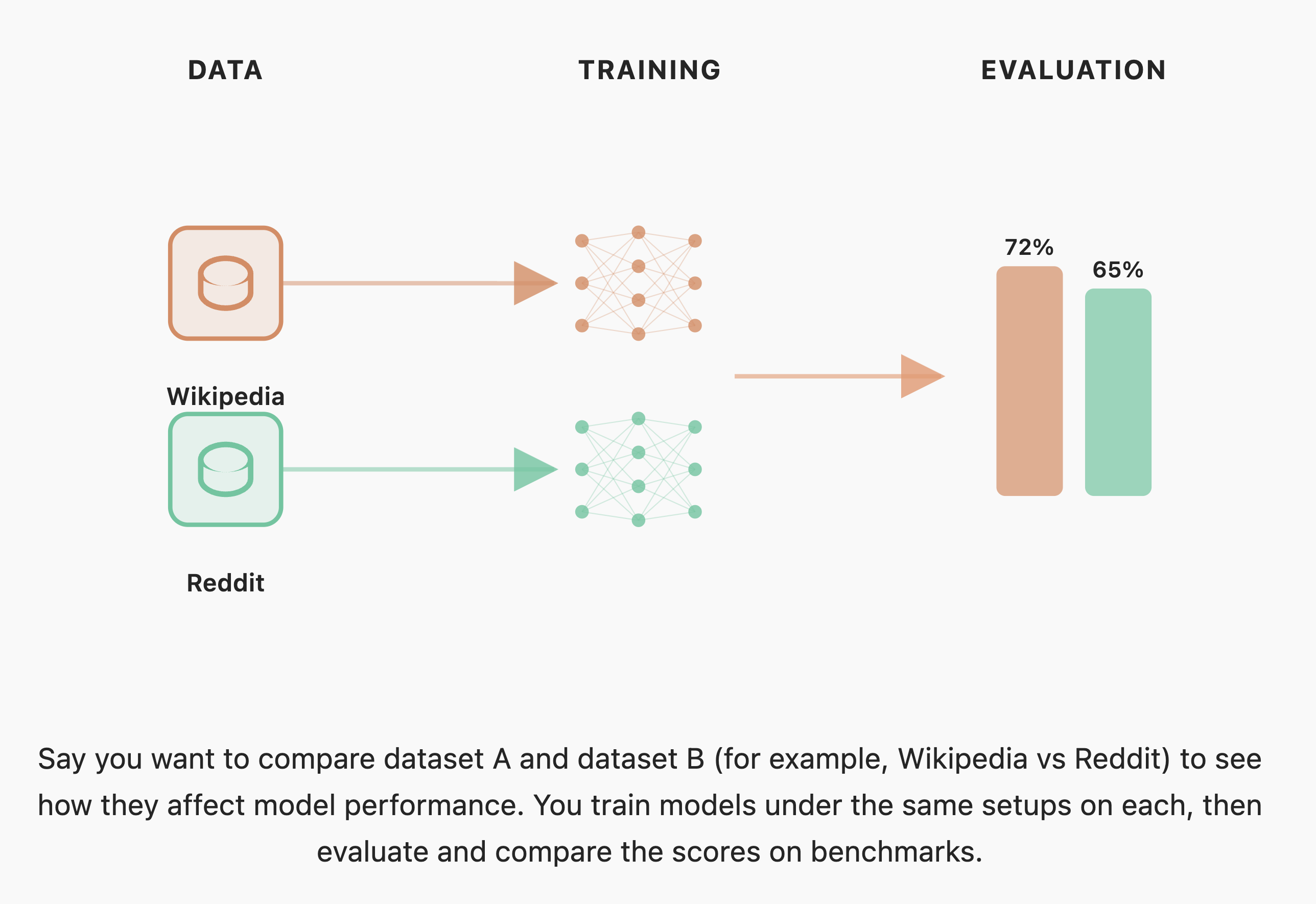
모델 빌더의 관점에서 평가는 개발 과정의 이정표와 같습니다. 연구자나 엔지니어는 베이스 모델을 학습하거나 새로운 아키텍처, 데이터 혼합 비율, 학습 레시피 등을 실험할 때, 이러한 변경 사항이 모델의 전반적인 성능을 향상시켰는지 확인해야 합니다. 이때 수행하는 것이 바로 '어블레이션(Ablation)' 실험입니다. 어블레이션은 특정 변수를 조작한 모델과 베이스라인 모델을 동일한 과제 세트에서 평가하여 비교하는 과정입니다. 따라서 모델 빌더에게는 반복적인 실험을 위해 빠르고 저렴하게 실행될 수 있으면서도, 미세한 성능 변화를 명확한 신호(Signal)로 포착할 수 있는 벤치마크가 필요합니다 .
반면, 모델 사용자의 관점은 다릅니다. 사용자는 추가적인 학습 없이 특정 목적에 바로 사용할 수 있는 최적의 모델을 찾습니다. 수학이나 코딩 같은 일반적인 영역이라면 리더보드 상위권 모델을 테스트하는 것으로 충분할 수 있습니다. 하지만 특수한 도메인의 경우, 일반적인 벤치마크 점수가 실제 업무 효율성과 직결되지 않는 경우가 많습니다. 따라서 모델 사용자는 자신의 구체적인 사용 사례(Use Case)와 데이터에 부합하는 맞춤형 평가를 설계해야 하며, 이는 모델 빌더의 평가 방식보다 훨씬 더 구체적이고 실질적이어야 합니다 .
최근 업계에서는 AGI(인공 일반 지능) 측정을 목표로 삼는 경향이 있지만, 이는 기술적으로나 철학적으로 매우 난해한 문제입니다. 지능의 정의는 인간이나 동물 연구에서도 합의되지 않은 '움직이는 목표(Moving target)'이며, 기계가 인간 고유의 영역이라 여겨졌던 능력을 달성할 때마다 그 정의가 재설정되곤 합니다. 따라서 막연히 지능을 측정하려 하기보다는, 회계 처리, 보고서 요약, 코드 리팩토링 등 구체적이고 유용한 작업(Task) 수행 능력을 평가하는 것이 훨씬 실용적이고 타당한 접근입니다 .
LLM의 기술적 기초와 평가의 영향
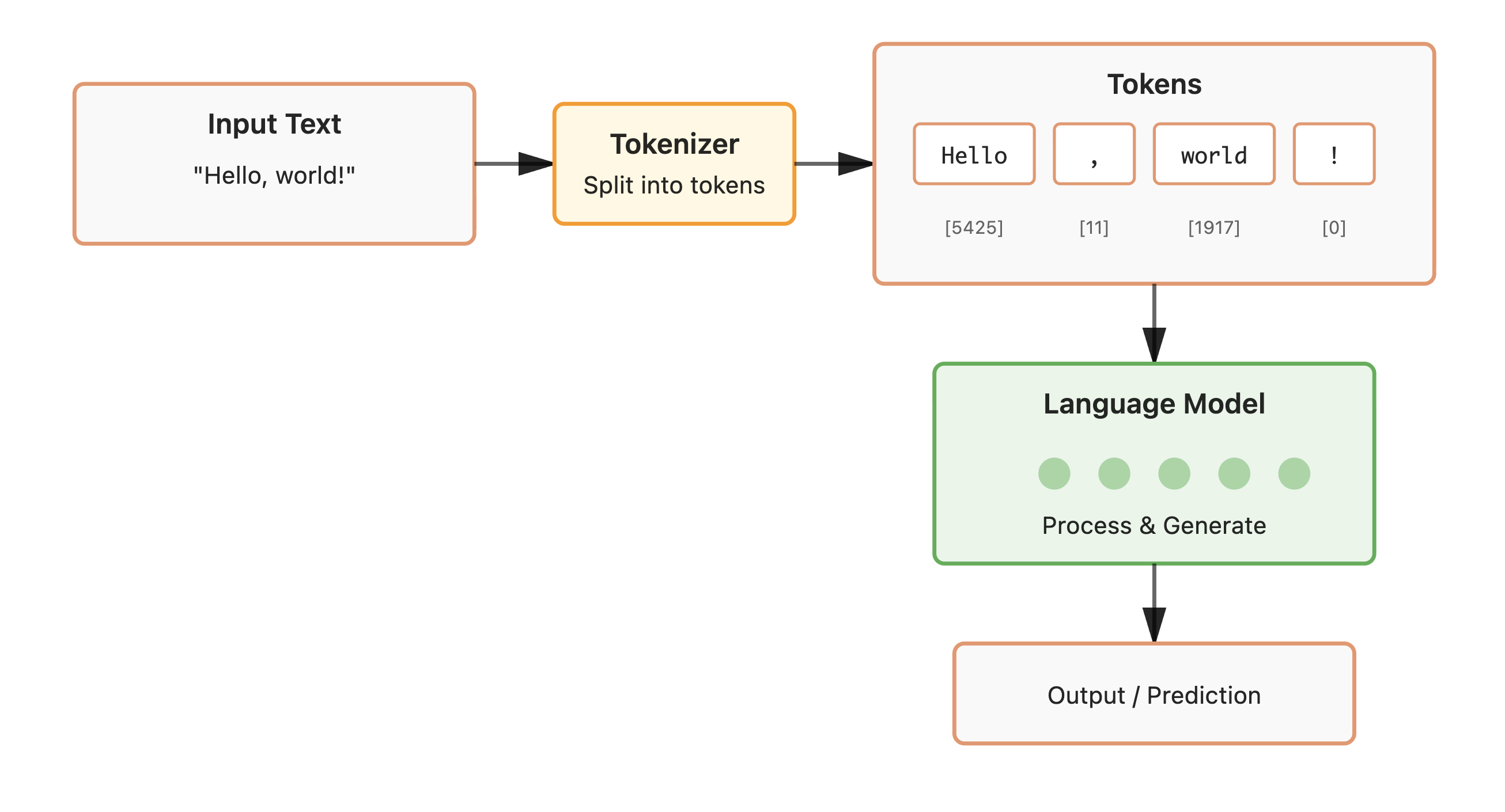
LLM이 입력을 처리하는데는 크게 2단계를 거치게됩니다. 입력을 사전 처리하여 모델에 제공하는 단계(토큰화, tokenization)과 모델이 입력을 통해 예측을 생성하는 단계(추론, ìnference)입니다. 평가 결과를 정확히 해석하기 위해서는 모델이 텍스트를 처리하는 기술적 메커니즘 중 토큰화(tokenization)와 추론 방식(inference)에 대해서 자세히 알아보겠습니다.
토큰화(Tokenization)의 미세한 차이와 파급력
LLM은 근본적으로 텍스트가 아닌 숫자를 처리하는 거대한 수학적 함수입니다. 우리가 입력하는 문장은 '토큰(Token)'이라는 작은 단위로 쪼개지고, 각 토큰은 고유한 숫자로 변환되어 모델에 입력됩니다. 과거에는 문자(Character) 단위나 띄어쓰기 기준의 단어(Word) 단위 토큰화를 시도했으나, 현재는 정보 손실을 최소화하고 효율성을 높이기 위해 BPE(Byte Pair Encoding)와 같은 서브워드(Sub-word) 방식이 표준으로 자리 잡았습니다.
평가 관점에서 토큰화는 몇 가지 심각한 문제를 내포하고 있습니다. 첫째, 숫자 처리 방식의 불일치입니다. 모델마다 숫자를 처리하는 방식이 제각각입니다. 어떤 토큰화기는 숫자 '100'을 '1', '0', '0'처럼 자릿수별로 분리하지만, 어떤 모델은 통째로 하나의 토큰으로 처리하거나, 큰 숫자를 독자적인 방식으로 압축합니다. 이러한 토큰화 방식의 차이는 모델의 산술 연산 능력 평가에 직접적인 영향을 미치며, 수학 벤치마크 점수의 변동 요인이 됩니다
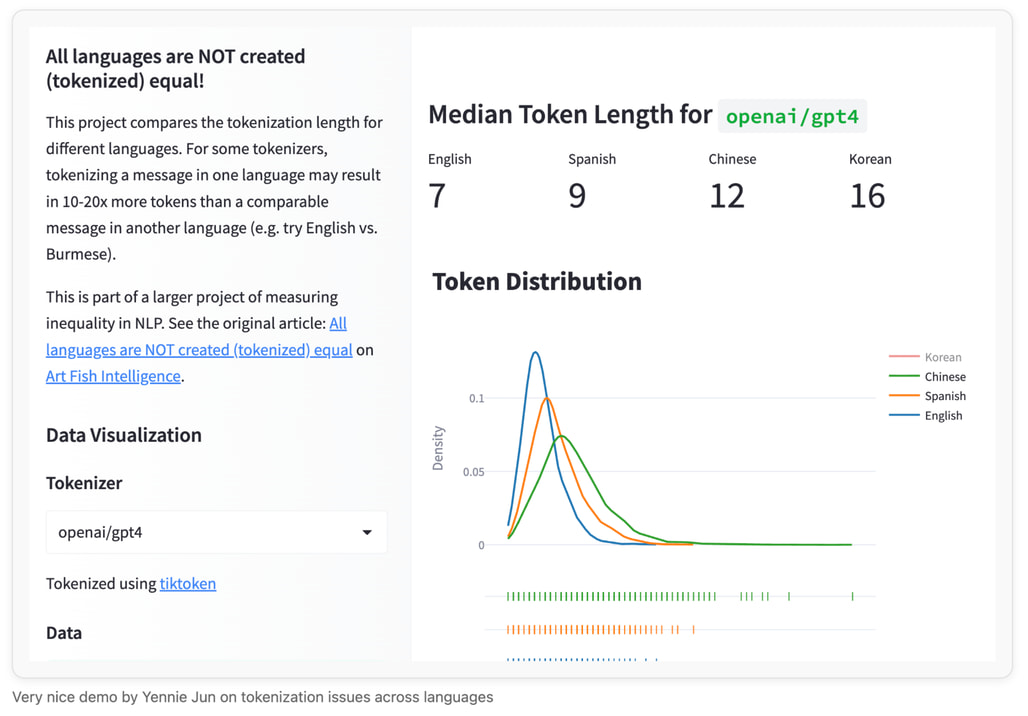
둘째, 다국어 불공정성(Multilingual Unfairness) 입니다. 대부분의 BPE 토큰화기는 영어 데이터 위주로 학습되었습니다. 그 결과 영어 문장은 단어 단위로 효율적으로 압축되는 반면, 태국어, 한국어, 버마어와 같은 언어는 글자 단위로 잘게 쪼개져 훨씬 많은 토큰을 소모하게 됩니다. 이는 비영어권 언어의 추론 비용을 증가시킬 뿐만 아니라, 생성 길이 제한이 있는 평가에서 해당 언어 모델이 답변을 끝까지 생성하지 못하고 잘리는 불이익을 받게 만듭니다.
각 주제에 대한 더 상세한 내용에 대해서는 다음의 추가 문서들을 참고하시는 것을 권장합니다:
심화 학습: 토큰화 이해

NLP 과정의 다양한 토큰화 방법 설명 (영문)
- 토큰화(및 기타)에 대한 Jurafsky의 과정 (영문) - 2.5 및 2.6으로 건너뛰기
BPE는 현대 LLM의 기반이므로 BPE의 작동 방식에 대한 자세한 설명을 읽어보시기를 강력히 권장합니다.
문장의 토큰화 비교(Compare tokenization of sentences)섹션을 참고하세요.
대화 템플릿(Chat Templates)과 시스템 프롬프트
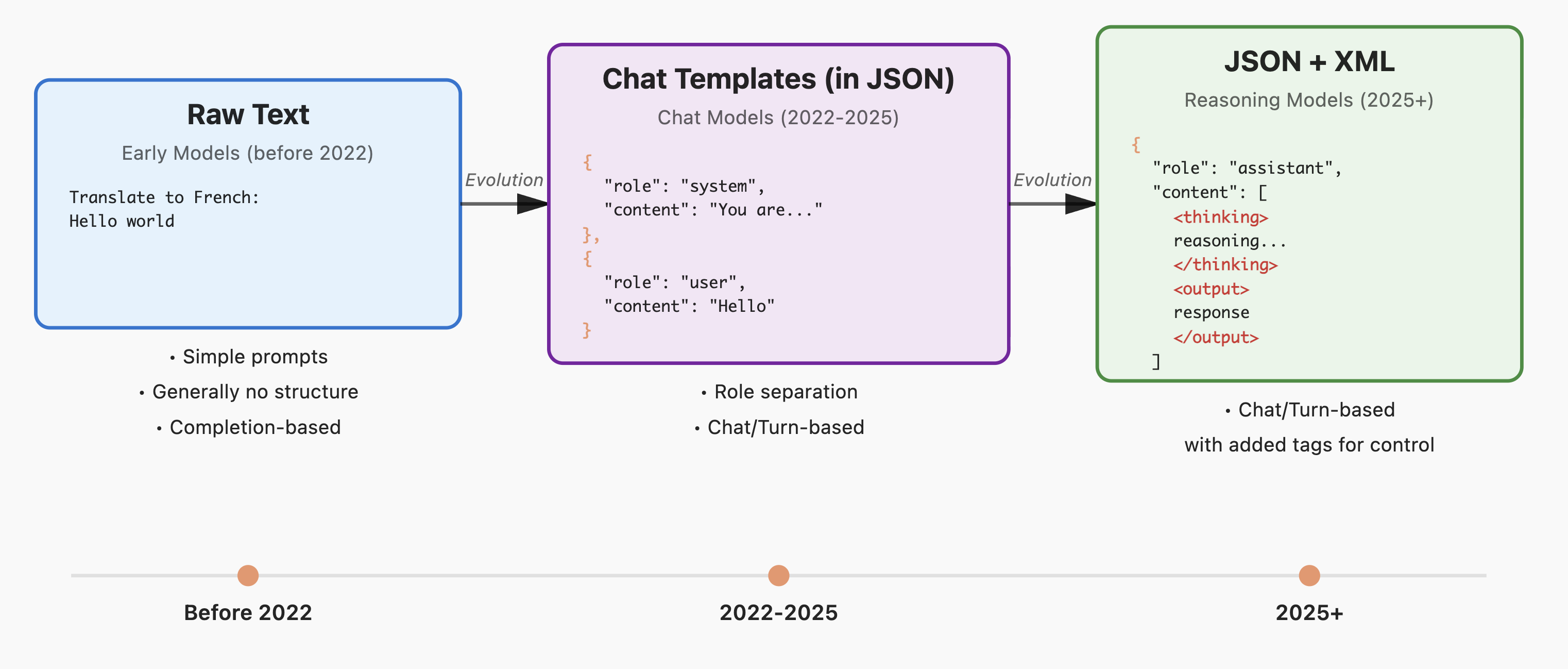
2022년 이전의 초기 모델들은 단순히 입력된 텍스트의 뒷부분을 이어 쓰는 '텍스트 완성(Completion)' 방식이었습니다. 그러나 지시 이행(Instruction Tuning) 및 대화형 모델이 주류가 되면서, 모델은 복잡한 구조를 이해해야 하게 되었습니다. 최신 모델은 System, User, Assistant와 같은 역할(Role) 구분과 이를 명시하는 특수 태그를 포함한 대화 템플릿(Chat Template) 을 엄격히 준수해야 합니다. 템플릿을 지키지 않으면 모델은 자신이 대화 중이라는 맥락을 파악하지 못해 성능이 급격히 저하됩니다.

특히 2025년에 등장한 추론 모델(Reasoning Models) 은 <thinking>과 같은 태그를 통해 내부 사고 과정을 기술합니다. 이러한 모델을 평가할 때는 <thinking> 태그 내부의 내용을 정규표현식(RegEx; Regular Expression) 등을 이용해 제거하고, 최종 답변만을 추출해야 정확한 평가가 가능합니다. 또한, 시스템 프롬프트의 유무와 내용에 따라 모델의 페르소나와 응답 스타일이 완전히 달라지므로, 평가 시 이를 일관되게 유지하는 것이 재현성의 핵심입니다.
추론(Inference) 방식: 로그 우도(Log-likelihood)와 생성형 평가(Generative Evaluation)
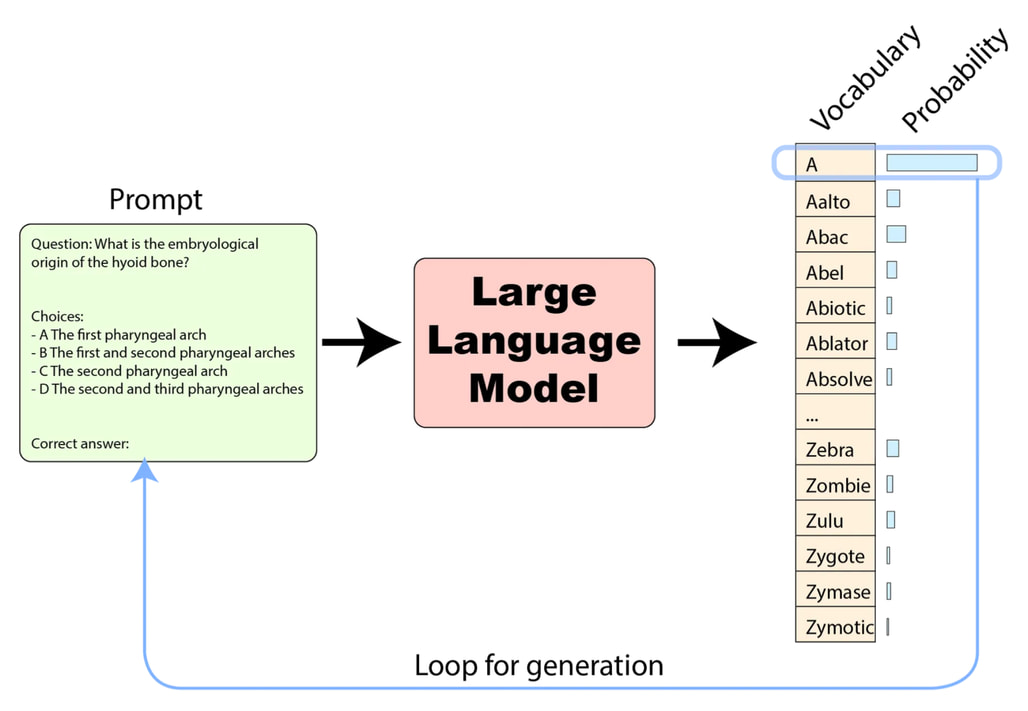
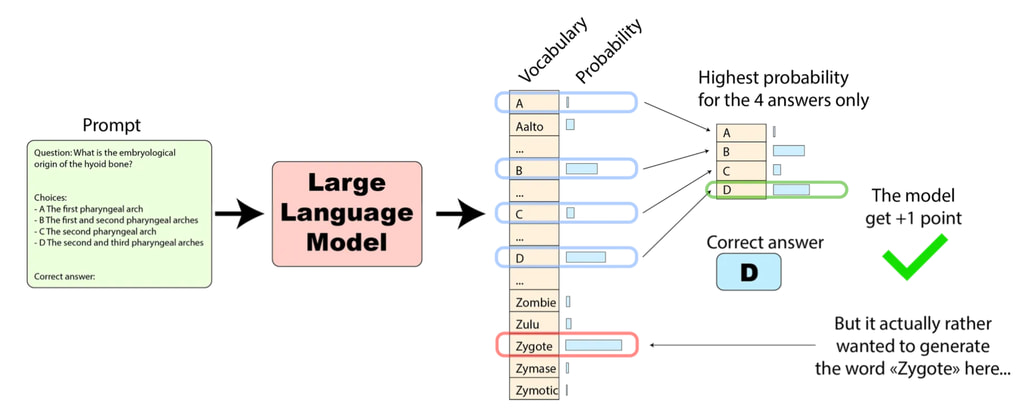
모델을 평가하는 기술적 접근법은 크게 두 가지로 나뉩니다: 첫 번째는 로그 우도(Log-likelihood) 평가입니다. 이 방식은 모델에게 질문과 함께 정답 후보(예: A, B, C, D)를 입력하고, 모델이 각 정답 후보에 해당하는 토큰에 부여한 조건부 확률(Logits)을 계산하여 비교합니다. 주로 객관식 문제(MCQA, Multiple Choice Question Answers) 평가에 사용되며, 모델이 실제로 텍스트를 생성할 필요가 없으므로 빠르고 비용 효율적입니다. 또한 모델이 정답에 대해 얼마나 확신하는지(Calibration)를 확인할 수 있다는 장점이 있습니다 .
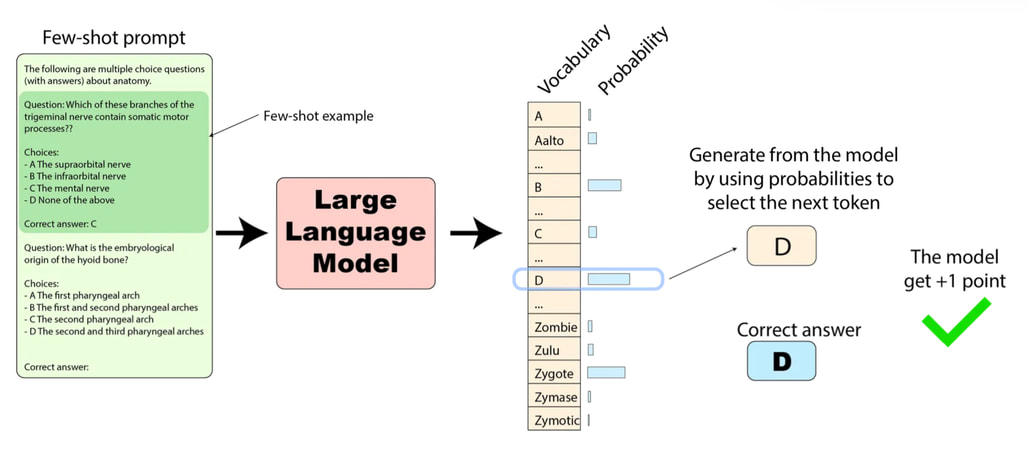
두 번째는 생성형(Generative) 평가입니다. 모델에게 프롬프트만 제공하고 실제로 텍스트를 생성하게 한 뒤, 그 결과를 정답과 비교합니다. 이는 사용자가 챗봇을 사용하는 실제 환경과 가장 유사하므로, 유창성, 논리적 흐름, 창의성 등을 평가하는 데 적합합니다. 하지만 생성된 자유 형식의 텍스트를 채점하는 과정이 복잡하고, API 비용이나 계산 리소스가 많이 소모된다는 단점이 있습니다. 최근의 모델들은 로그 확률에 접근할 수 없는 API 형태로 제공되는 경우가 많아 생성형 평가가 필수적으로 사용되는 추세입니다 .
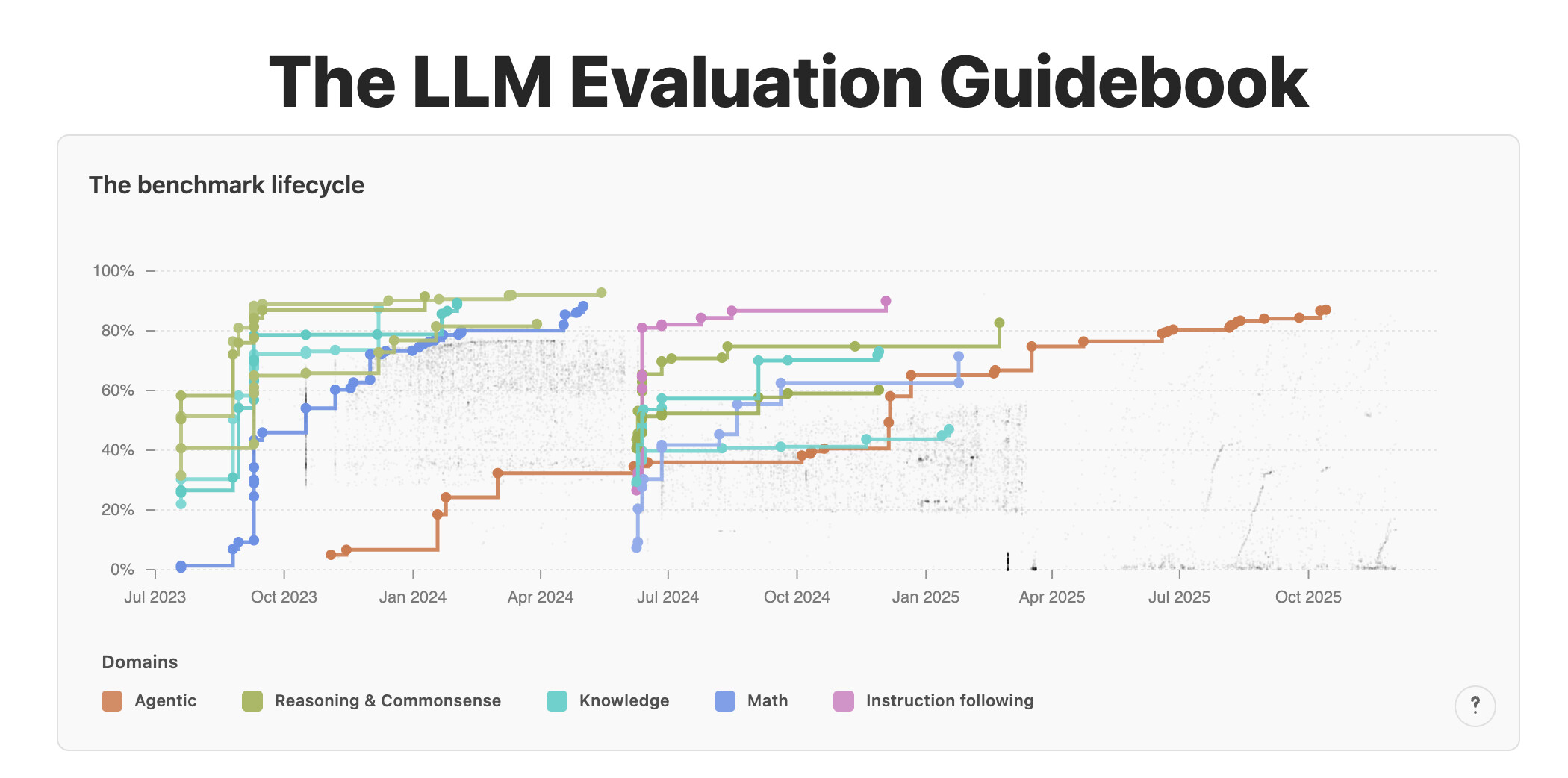
2025년 벤치마크 생태계 심층 분석
벤치마크 데이터셋은 모델의 발전 속도에 따라 수명 주기(Lifecycle)를 가집니다. 특정 벤치마크가 모델들에게 너무 쉬워져서 대부분의 모델이 인간 수준 이상의 고득점을 기록하게 되면, 그 벤치마크는 변별력을 상실하고 '포화(Saturation)' 되었다고 합니다. 또한, 벤치마크 데이터가 인터넷에 공개되어 모델의 학습 데이터에 포함되면, 모델이 답을 외워서 맞히는 '오염(Contamination)' 문제가 발생합니다 . 2025년 현재, 각 영역별로 이러한 문제를 극복하기 위해 어떤 새로운 벤치마크들이 등장했는지 살펴보겠습니다.
중요 개념
이 섹션에서는 오염(Contamination)과 포화(Saturation)라는 두 가지 개념이 자주 언급됩니다:
포화(Saturation): 벤치마크에서 모델 성능이 사람의 성능을 넘어선 경우입니다. 더 일반적으로, 이 용어는 모델 간의 판별력을 잃어 더 이상 유용하지 않다고 간주되는 데이터 세트를 지칭하는 데 사용됩니다.
모든 모델이 평가에서 가능한 가장 높은 점수에 가까운 점수를 받았다면, 더 이상 판별 벤치마크가 아닙니다. 이는 유치원 문제를 풀고 있는 고등학생을 평가하는 것과 비슷합니다. 성공은 아무런 의미가 없습니다(하지만 실패는 지표가 될 수 있습니다).
오염(Contamination): 평가 데이터 세트가 모델의 학습 데이터 세트에 포함되는 경우입니다. 이 경우 모델의 성능이 인위적으로 부풀려져 실제 작업 성능을 반영하지 못합니다.
이미 알고 있는 문제에 대해 학생을 평가하는 것과 비슷합니다.
추론 및 상식 (Reasoning & Commonsense)
초기 LLM 평가를 주도했던 ARC(2018)는(최근의 ARC-AGI와 다릅니다) 인간의 시험 문제로 구성된 초등학교 수준의 과학 객관식(MCQA) 데이터셋입니다. 당시의 단어 동시 출현(Word Co-occurrence) 기반 시스템을 속이기 위해 선택지가 적대적으로 구성되었으며, 이 중 고품질인 'Challenge' 서브셋은 여전히 사전 학습 평가에 사용되고 있습니다 . WinoGrande(2019)는 크라우드소싱으로 구축된 대명사 해결 및 빈칸 채우기 데이터셋으로, 모델을 속이기 위한 적대적 쌍(Adversarial pairs)을 사용하여 2022~2023년까지 모델들에게 상당히 어려운 과제로 꼽혔습니다 .
또한 상식적 이해와 그라운딩(Grounding)을 평가하기 위한 역사적인 데이터셋들도 다수 존재합니다. HellaSwag(2019)는 위키하우(Wikihow) 튜토리얼이나 ActivityNet의 캡션을 바탕으로 이어질 올바른 문장을 고르는 과제이며, 해결을 위해 물리적인 상식 이해를 요구합니다 . 같은 맥락에서 CommonsenseQA(2018)는 ConceptNet을 기반으로 구축된 상식 객관식 데이터셋으로, 개념적으로 유사한 오답(Distractors)을 배치하여 난이도를 높였습니다. PIQA(2019)는 Instructables.com의 예시를 활용해 물리적 상식에 특화된 질문을 던지며, 의미적 변형을 통해 적대적인 선택지를 구성했습니다. OpenBookQA(2018)는 참고할 수 있는 팩트를 제공하는 오픈 북 형태이지만, 정답을 맞히기 위해서는 여전히 내재된 상식(Latent commonsense)이 필요합니다.
이러한 벤치마크들은 과거에는 도전적이었으나, 현재 최신 모델들에게는 너무 쉬워졌거나(포화), 학습 데이터에 포함되어 오염되었을 가능성이 높습니다. 따라서 현재는 주로 소규모 모델의 어블레이션 실험이나 사전 학습(Pre-training) 단계의 성능을 점검하는 용도로만 제한적으로 사용됩니다.
따라서 이러한 한계를 극복하기 위해 Zebra Logic과 같은 새로운 벤치마크가 주목받고 있습니다. Zebra Logic은 논리 퍼즐을 기반으로 하는데, 핵심은 문제의 구조(Template)만 유지한 채 알고리즘적으로 무한히 새로운 문제를 생성할 수 있다는 점입니다. 이는 모델이 특정 데이터를 암기하여 문제를 푸는 오염 문제를 원천적으로 차단하며, 순수한 논리적 추론 능력을 측정하는 데 효과적입니다 .
지식 (Knowledge)
오랫동안 지식 평가의 표준 데이터셋은 MMLU(2020)였습니다. 그러나 이 데이터셋은 포화(Saturation) 및 오염(Contamination) 상태에 도달했으며, 심층 분석 결과 누락된 문서를 참조하거나, 정답이 틀리고, 질문이 모호하며, 주제 선정에 있어 노골적인 미국 중심주의가 반영되었다는 문제점들이 발견되었습니다. 이에 따라 데이터셋을 정제한 MMLU-Redux(2024), 더 복잡한 질문과 답변을 추가하여 현재 커뮤니티의 주류 대체재가 된 MMLU-Pro(2024), 그리고 문화적 편향을 해결하기 위해 번역 및 주석 작업을 거친 Global-MMLU(2024)가 등장했습니다. 이들은 주로 사전 학습(Pre-training) 단계의 평가나 어블레이션(Ablation)에 사용됩니다.
사후 학습(Post-training) 단계에서는 더 어렵고 품질이 높은 지식 데이터셋이 요구됩니다. GPQA(2023)는 생물학, 화학, 물리학 분야의 박사급 질문들로 구성되어 있으며, 해당 분야의 박사 과정 학생들만 답할 수 있도록 설계되었습니다. 가장 많이 사용되는 서브셋은 diamond이지만, 2023년 공개 이후 이 또한 오염(Contamination)되기 시작했습니다.
마지막으로, 거창한 이름이지만 매우 높은 품질을 자랑하는 Humanity’s Last Exam(2024, HLE)이 있습니다. 이 데이터셋은 각 분야의 전문가들이 크라우드소싱으로 만든 2,500개의 질문으로 구성되어 있으며, 복잡한 지식과 추론을 동시에 요구합니다. 대부분 비공개 상태이며 아직 정복되지 않은 훌륭한 데이터셋입니다. 유일한 문제는 모델 점수를 빠르게 확인할 방법이 없어, 정답(Ground truth)과 대조하는 대신 LLM 평가자(LLM-as-a-Judge)을 사용해 평가해야 한다는 점입니다. 이로 인해 실제 환경에서는 비교 불가능한 결과가 나올 수 있습니다.
과거에는 모델의 잠재적 지식(Latent knowledge) 품질을 테스트하는 것이 의미가 있었지만(MMLU-Pro나 GPQA/HLE 등은 여전히 유효합니다), 향후 몇 년 안에 이러한 유형의 벤치마크는 서서히 사라질 것으로 예상됩니다. 그 이유는 다음과 같은 두 가지입니다:
-
난해함: 질문이 너무 복잡해져서 비전문가는 성능의 의미를 이해하기 어렵고, 데이터셋 자체의 오류를 검증하기도 불가능에 가까워졌습니다.
-
도구 사용의 보편화: 모델이 인터넷 검색 등의 도구를 사용하게 되면서, 잠재 지식 평가는 점차 웹 검색 및 검색(Retrieval) 평가로 변모하고 있습니다. 즉, 닫힌 책(Closed book) 평가에서 열린 책(Open book) 평가로 이동하고 있습니다. 이는 마치 고등학교에서는 암기 위주의 시험을 보지만, 대학에서는 데이터베이스와 인터넷 접근을 허용하고 정보 접근 능력을 바탕으로 한 추론 능력을 평가하는 것과 같습니다.
수학 (Math)
수학 평가 데이터셋은 모델이 수학 문제를 풀 수 있는지 확인하는 것을 넘어, 논리력과 추론 능력의 대리 지표(Proxy)로 사용되어 왔습니다. 참조용 수학 데이터셋의 양대 산맥은 초등학교 수준의 수학 문제를 담은 GSM8K(2021)와 웹상의 올림피아드 문제들을 모은 MATH(2021)였습니다. 그러나 이들은 최근 몇 년간 포화되거나 오염되었습니다. GSM8K의 경우, 오염 여부를 테스트하기 위해 1,000개의 새로운 문제로 재생성한 GSM1K(2024), 오답 유도 선택지(Distractors)나 수치 변형 등 적대적 변경을 가한 GSM-Plus, 그리고 문제 템플릿을 만들어 무한히 새로운 문제를 생성함으로써 오염을 방지하는 흥미로운 시도인 GSM-Symbolic(2024) 등으로 확장되었습니다.
현재 커뮤니티는 다음 데이터셋들에 주목하고 있습니다:
-
MATH의 후속작: 과적합을 방지하기 위해 대표적인 500개 문제를 샘플링한 MATH-500과 가장 어려운 500개 문제만 추린 MATH-Hard.
-
AIME24 및 AIME25: 미국 고등학생 대상 올림피아드 데이터셋으로, 공개된 그대로 사용됩니다. 매년 동등한 난이도의 문제가 갱신되므로, 이전 연도 데이터셋과 결과를 비교하여 오염 여부를 테스트하기 좋습니다.
-
Math-Arena: AIME25를 포함하여 다양한 대회와 올림피아드 문제를 정기적으로 업데이트하여 모은 최신 컴필레이션입니다.
사실 GSM-Symbolic이 재귀 수준을 높여 인위적으로 난이도를 높일 수 있긴 하지만, 대부분의 데이터셋은 여전히 초등학교 수준에 머물러 있어 "그렇게 어렵지" 않습니다. 반대편 극단에는 수학자들이 평가를 위해 직접 작성한 초고난도 문제집인 FrontierMath(2024)가 있습니다. 이 데이터셋은 이론적으로 비공개였으나, 유감스럽게도 OpenAI가 일부 데이터에 접근했던 것으로 드러났습니다. 앞서 지식 섹션에서 소개한 Humanity’s Last Exam(2025) 또한 복잡한 추론(특히 정리 증명 등)을 요구하는 흥미로운 수학 문제들을 포함하고 있습니다.
개인적으로는 사전 학습 평가에는 AIME25와 MATH-500을, 사후 학습 평가에는 Math-Arena를 사용할 것을 권장합니다.
코딩 (Code)
에이전트가 도구와 상호작용하려면 코딩 능력이 필수적입니다. 코드 에이전트라면 도구를 직접 호출해야 하고, 그렇지 않더라도 문제가 발생했을 때 도구의 출력을 디버깅해야 하기 때문입니다(코드 에이전트와 JSON 에이전트의 차이는 여기를 참고해주세요). 코딩 평가셋은 추론 능력을 측정하는 좋은 대리 지표(Proxy)이기도 합니다.
역사적으로 2021년에는 1,000개의 초급 Python 문제로 구성된 크라우드소싱 데이터셋인 MBPP, 프로그래밍 인터뷰 및 공유 사이트에서 10,000개의 문제를 수집한 APPS, 그리고 Codex 모델과 함께 소개된 HumanEval이 사용되었습니다. HumanEval은 "출시를 위해 특별히 제작된" 문제들로 구성되어 당시에는 매우 획기적이었으며, 평가자 컴퓨터에서의 문제 소지를 막기 위한 샌드박스와 pass@k 추정치 개념을 도입했습니다.
이후 EvalPlus(2023) 팀은 더 많은 테스트 케이스와 입력을 추가하고 버그를 수정하여 HumanEval+와 MBPP+를 만들었습니다. EvoEval(2024)은 문제를 의미적으로 재작성하고 난이도 라벨을 추가한 변형판을 내놓았습니다.
최종 모델 평가를 위해서는 더 어렵고 오염되지 않은 문제가 필요합니다:
- LiveCodeBench(2024): LeetCode 등의 사이트에서 문제를 수집하되, 문제 출제 날짜를 저장하여 모델 훈련 종료 시점 전후의 성능을 비교합니다. 이는 오염 없는 훌륭한 벤치마크이며, 업데이트가 기대됩니다.
- AiderBench: 기존 코딩 사이트(Exercism) 데이터를 사용하지만, 단순 문제 해결을 넘어 코드 편집(Editing)과 리팩토링(Refactoring) 능력을 테스트합니다.
사후 학습 단계에서는 단순 문제 해결을 넘어선 전체론적(Holistic) 평가가 필요합니다. RepoBench(2023)는 GitHub 코드를 소스로 사용하여 Python이나 Java의 저장소(Repository) 수준 자동 완성 시스템을 테스트합니다. 더 잘 알려진 버전인 SweBench(2024) 역시 GitHub를 사용하지만, 모델이 기존 이슈(Issue) 를 해결할 수 있는지(논리 이해, 파일 간 편집 및 실행, 긴 문맥 추론 등)를 테스트합니다. CodeClash(2025)는 모델들이 서로 코드를 작성하고, 편집하고, 반복하며 경쟁하는 코딩 버전의 아레나입니다.
현시점에서는 LiveCodeBench, AiderBench, 그리고 SWE-Bench의 고품질 서브셋인 SWE-Bench verified를 따르는 것을 추천하며, 실제 코드 어시스턴트의 유용성에 대한 METR 리포트를 읽어볼 것을 권합니다.
긴 문맥 (Long Context)
사용자와의 긴 대화에서 맥락을 놓치지 않으려면 긴 문맥 관리 능력이 필수적입니다. 특히, 3년 전만 해도 2,048 토큰이 최대였는데, 지금은 128K를 넘기는 것을 생각하면 놀라운 발전입니다.
2023년 이 분야의 테스트를 시작한 것은 NIAH(Needle in a Haystack)일 것입니다. 긴 무관한 텍스트 속에 무작위 사실(바늘)을 숨겨놓고 이를 찾아내게 하는 방식입니다. 2023년에는 모델들이 이를 잘 수행하지 못했으나, 2025년 현재 이 문제는 거의 해결되었습니다.
이후 더 복잡한 확장판들이 등장했습니다. RULER(2024)는 다단계 추적(Multi-hop tracing, 변수 사슬을 따라가 정답 찾기), 단어 빈도 변화 등을 추가했지만 이 역시 거의 정복되었습니다. Michelangelo(2024, 또는 MRCR)는 모델이 문맥의 고유한 부분을 정확히 재생성하고 텍스트 수정 순서를 이해하는지 테스트하며, 이는 OpenAI MRCR(2025)로 확장되었습니다. InfinityBench(2024)는 다국어(영어, 중국어) 환경에서 10만 토큰 이상의 긴 문맥을 바탕으로 QA, 검색, 계산 등을 수행하며 여전히 유의미한 신호를 제공합니다.
HELMET(2024)는 RAG, QA(Natural Questions 등), 리콜(RULER 등), 인용 생성(ALCE), 요약, 재순위화(MS MARCO), 인컨텍스트 러닝(TREC 등) 등 기존 벤치마크들을 통합하여 더 강력한 신호를 제공하는 거대 데이터셋입니다. 단, HELMET과 InfinityBench를 모두 테스트한 뒤 결과를 합산하면 중복 평가가 될 수 있으니 주의해야 합니다. 2025년 현재 HELMET은 모델 간 변별력을 갖추고 있습니다.
개인적으로 선호하는 긴 문맥 평가는 Novel Challenge(2024)와 Kalamang translation dataset(2024)입니다. 전자는 최근 출판된 소설책 전체를 읽고 이해해야 답할 수 있는 1,000개의 진위 판별 문제이며, 후자는 문법책 하나만 읽고 영어를 칼라망어(화자가 200명뿐이라 온라인 데이터가 없는 언어)로 번역하게 하는 과제입니다.
지시 이행 (Instruction Following)
지시 이행 평가의 양대 산맥은 IFEval(2023)과 그 확장판인 IFBench(2025)입니다. IFEval은 최근 몇 년간 가장 영리한 평가 아이디어 중 하나입니다. 모델에게 "키워드 포함", "문장 수 제한", "마크다운 포맷 사용" 등 포맷팅 지시를 따르게 하고, 이를 별도의 파서(Parser)로 검증합니다. 이는 LLM 평가자 없이도 엄격한 점수를 얻을 수 있는 드문 자유 형식 생성 평가입니다.
이러한 기능적 정확성(Functional correctness) 혹은 유닛 테스트 방식의 평가는 제가 개인적으로 가장 선호하는 방식이며, 오염 방지를 위해 재생성하거나 확장하기도 매우 쉽습니다.
추가로, CoCoNot(2024)은 모델이 불완전하거나, 답변 불가능하거나(환각 유발), 안전하지 않은 요청에 대해 "지시를 따르지 않는(Non-compliance)" 능력을 테스트합니다.
도구 호출 (Tool-calling)
도구(Tool)의 등장은 LLM을 에이전트의 영역으로 이동시킨 핵심 기능입니다. 이 분야에서는 다음과 같은 주요 벤치마크들이 존재합니다:
-
TauBench(2024): 소매 및 항공 도메인에서 사용자 쿼리를 처리하는 능력을 평가합니다. 데이터베이스는 합성을 통해 실제와 유사하게 구축되었으며, DB가 올바르게 업데이트되었는지와 사용자에게 적절히 응답했는지를 모두 확인합니다. 사용자를 LLM으로 모의(Mock-up)하여 비용이 많이 들고 오류가 발생하기 쉽지만, 실제 사용 사례를 잘 반영하여 널리 쓰입니다.
-
API 목록형: ToolBench(2023)는 다양한 API(날씨, 검색 등)를 호출하여 문제를 해결하게 하지만, 모의 API와 실제 API가 섞여 있어 불안정했습니다. 이를 개선한 StableToolBench(2025)는 가상 API 서버를 도입했으나, 평가를 위해 LLM 평가자에 의존하여 또 다른 편향을 초래했습니다.
-
BFCL(2025): 현재 v3는 도구 호출을, v4는 웹 및 검색 도구 사용을 중점적으로 테스트합니다. AST(추상 구문 트리)와 상태 매칭을 사용하여 호출의 정확성을 평가합니다.
-
MCP (Model Context Protocol) 기반: 최근 MCP의 등장으로 관련 벤치마크가 늘고 있습니다. MCPBench(2025)는 실제 MCP 서버(위키피디아, 아카이브 등)를 연결하여 다중 턴 작업을 수행하게 합니다. MCP-Universe(2025)는 11개의 MCP 서버를 사용하여 정적/동적 작업을 평가하는데, 동적 작업(예: 깃허브 스타 수 확인)의 경우 실행 기반 평가 프레임워크를 통해 최신 정답을 자동으로 가져와 비교하므로 LLM 평가자보다 훨씬 깔끔합니다. LiveMCPBench(2025)는 로컬에 배포 가능한 MCP 서버 모음을 제공하여 도구 선택 능력을 테스트합니다(최고 모델은 이미 80% 도달).
추가로 좋은 도구를 작성하는 방법에 대해 Anthropic이 작성한 훌륭한 문서 (영문)도 있으니 참고해보세요.
어시스턴트 작업 (Assistant Tasks)
가이드북의 저자들은 어시스턴트 작업이 차세대 평가의 주류가 될 것이라 믿습니다. 이는 긴 문맥, 추론, 도구 호출 등 여러 역량의 조화(Orchestration) 를 요구하며, 대중이 이해하기 쉬운 실제 업무 환경을 반영합니다.
실생활 정보 검색 분야에서는 GAIA(2023)가 도구, 추론, 검색을 결합하여 실생활 쿼리를 해결하게 함으로써 현대적 에이전트 평가(리더보드)를 시작했습니다. 이를 복제한 BrowseComp(2025) 역시 도구와 온라인 정보를 이용해 답을 찾게 합니다. GDPval(2025)는 미국 GDP에 기여하는 상위 44개 직업군의 업무 수행 능력을 평가합니다. GAIA2는 모의 모바일 환경을 사용하여 이벤트 체인과 도구 호출에 의존하는 쿼리 해결 능력을 테스트하며, 현재 고의적인 노이즈가 포함된 서브셋은 모델들에게 가장 어려운 과제 중 하나입니다.
과학 어시스턴트 분야에서는 SciCode(2024)는 과학 분야(STEM)의 실제 문제를 코드로 해결하는 능력을, PaperBench(2025)는 ICML 논문의 코드를 재구현하는 능력을 테스트합니다. DSBench(2025)는 캐글(Kaggle) 등의 데이터를 이용한 멀티모달 데이터 분석을 평가합니다. DABStep(2025)은 비공개 운영 데이터를 사용하여 다단계 추론과 문서 파싱, 데이터 조작 기술을 요하는 실제 업무를 평가하는데, 정답이 존재하여 편향 없고 비용 효율적인 훌륭한 평가입니다.
게임 기반 평가 (Game based evaluations)
게임 기반 벤치마크는 변화하는 환경에 대한 적응성(Adaptability) 과 긴 문맥 추론을 평가하며, 무엇보다 사람들이 이해하기 쉽다는 장점이 있습니다.
가장 유명한 것은 ARC-AGI로, 규칙 없이 수열의 마지막 항목을 찾는 퍼즐 형식입니다(2024년에 거의 정복됨). 최신 버전인 ARC-AGI3(2025)는 탐험, 계획, 메모리 관리가 필요한 완전히 새로운 게임들을 포함합니다. 유사하게 Baba is AI(2024)는 규칙 외삽 능력을 테스트합니다.
싱글 플레이어 게임으로는 TextQuests(2025)나 Pokemon(2024, Claude 및 Gemini 트위치 방송 참고), 마인크래프트 영감을 받은 Crafter(2021), 그리고 이들을 통합한 Balrog(2024) 등이 있으며, 장기 계획과 되추적(Backtracking) 능력을 요구합니다.
경쟁 및 블러핑 게임으로는 Poker(2025), Town of Salem(2025), Werewolf(여기/저기), Among us 등이 있어 논리와 기만(Deception) 능력을 테스트하기 좋습니다. 예를 들어 Claude Opus 4는 Town of Salem에서 농민 역할은 잘하지만 뱀파이어(기만 역할)로는 이기지 못합니다. Hanabi는 제한된 환경에서의 의사소통 능력을 테스트합니다. 게임 평가는 "이겼는가/졌는가"라는 명확한 지표가 있어 매력적입니다.
예측가 (Forecasters)
지난해에는 오염이 불가능한 새로운 범주의 작업인 예측(Forecasting) 이 등장했습니다. 이는 여러 출처의 정보를 종합하여 아직 일어나지 않은 사건을 추론해야 합니다.
FutureBench는 브라우징과 LLM을 이용해 주간 단위의 뉴스 가치가 있는 사건을 예측하는 질문을 생성합니다. 현재 모델들은 인간의 베팅보다는 못하지만 모델 생성 질문에는 꽤 높은 성공률을 보입니다. FutureX는 특정 웹사이트(예측 시장, 정부 사이트 등)를 기반으로 템플릿 질문("언제 주식이 특정 포인트에 도달할까?")을 생성합니다. Arbitrage는 2028년에 결과가 나오는 장기 시계열 사건을 다룹니다.
이외에도 모델에게 돈을 주고 금융 시장에서 거래하게하는 아레나(Alpha Arena 등)도 있지만, 비용 문제로 단일 실행에 그치는 경우가 많아 통계적 유의성을 확보하기 어렵습니다.
벤치마크 데이터 심층 분석 (Understanding what’s in there)
데이터셋을 선택한 후 가장 중요한, 그러나 종종 간과되는 단계는 데이터를 직접 들여다보는 것입니다. 벤치마크 점수는 모델 성능의 대리 지표일 뿐이며, 그 신뢰성은 전적으로 데이터의 품질에 달려 있습니다. 따라서 어떠한 벤치마크를 단순히 표준 벤치마크라는 이유만으로 맹신해서는 안 되며, 다음 요소들을 면밀히 검토해야 합니다:
-
데이터 생성 과정(Data Creation Process): 누가 데이터를 생성했는지 확인하십시오. 해당 분야의 전문가가 작성한 데이터가 가장 이상적이며, 유급 전문 어노테이터, 크라우드소싱, 합성 데이터, 그리고 아마존 메커니컬 터크(MTurk) 순으로 품질이 낮아지는 경향이 있습니다. 특히 데이터 카드(Data Card)를 통해 어노테이터의 인구통계학적 정보를 확인하는 것이 중요합니다. 이는 데이터셋의 언어적 다양성이나 잠재적인 문화적 편향을 파악하는 데 필수적입니다. 저임금의 원어민이 아닌 라벨러(Annotator)가 참여한 경우, 오타나 문법 오류, 비문이 포함될 가능성이 높아 평가의 신뢰도를 떨어뜨릴 수 있습니다.
-
샘플 직접 검사(Sample Inspection): 무작위로 50개의 샘플을 추출하여 직접 눈으로 확인하십시오. LLM에게 분석을 맡기지 말고 직접 해야 합니다. 프롬프트가 모호하지 않은지, 정답이 정확한지(예: TriviaQA는 정답 별칭이 충돌하는 경우가 있음), 정보가 누락되지 않았는지(예: MMLU의 일부 질문은 누락된 도표를 참조함) 확인해야 합니다. 또한 선택지의 개수가 일관적인지, 프롬프트 전후의 공백 처리가 통일되어 있는지 등 형식적 일관성도 점검해야 합니다. Hugging Face TB post-training-benchmarks-viewer를 통해 주요 사후 학습 벤치마크의 샘플을 직접 확인할 수 있습니다.
-
작업 및 지표(Task and Metrics): 평가에 사용되는 지표가 자동화된 방식인지, 기능적 검증인지, 혹은 모델 평가자(Model Judge)을 사용하는지 파악해야 합니다. 이는 평가 비용뿐만 아니라 결과의 재현성과 잠재적 편향의 종류를 결정짓는 핵심 요소입니다.
점수 재현이 안 되나요?
최신 모델의 기술 보고서에 나온 점수를 내 환경에서 재현하려다 실패한 경험이 있다면, 이는 당신의 잘못이 아닐 가능성이 높습니다. 평가 결과는 매우 미세한 기술적 차이에 의해 크게 달라질 수 있습니다. 예를 들어, 다음의 경우들을 고려해볼 수 있습니다:
-
코드 베이스의 차이(Different Code Base): 평가를 수행하는 코드 자체가 다르면 결과도 다릅니다. 원저자가 제공한 코드, EleutherAI의
lm_eval, Hugging Face의lighteval등 어떤 라이브러리를 사용했는지에 따라 전처리나 정규화 로직이 달라집니다. 실제로 MMLU 평가의 경우, 구현체에 따라 점수가 수 포인트 차이 날 수 있음이 밝혀졌습니다. 이와 관련된 자세한 분석은 이 블로그에서 확인할 수 있습니다. -
미묘한 구현 및 로딩 차이: 동일한 코드 베이스를 사용하더라도 랜덤 시드(Random Seed)(CUDA 연산의 비결정성), 배치 크기(Batch Size), 부동소수점 정밀도(FP16 vs FP32 vs 양자화)에 따라 수치적 결과가 달라집니다. 또한 지표의 이름이 같더라도 실제 계산 로직이 다른 경우가 많습니다. 예를 들어, 단순한 'Exact Match'라 하더라도 실제로는 구두점을 제거하는 정규화 과정을 거치거나, 접두사/접미사만 비교하는 방식일 수 있습니다. 따라서 지표의 이름만 믿지 말고 실제 코드를 확인해야 합니다.
-
프롬프트 민감성(Different Prompt): 프롬프트 포맷은 점수를 바꾸는 가장 큰 변수 중 하나입니다. 선택지를 "A"로 표기하느냐 "(A)"로 표기하느냐의 사소한 차이가 모델 성능에 큰 영향을 줄 수 있습니다. 심지어 Llama 3.1과 같은 최신 모델도 특정 벤치마크의 프롬프트 포맷에 과적합(Overfitting)되어, 의미적으로 동일한 다른 포맷에서는 성능이 급락하는 현상이 관찰되었습니다. 챗 모델이나 추론 모델의 경우, 시스템 프롬프트와 대화 템플릿(Chat Template) 을 정확히 준수하지 않으면 모델 성능이 붕괴될 수 있습니다. 관련하여 State of the Art? 논문을 참고해보세요.
학습을 위한 벤치마크 선정 - FineWeb 사례
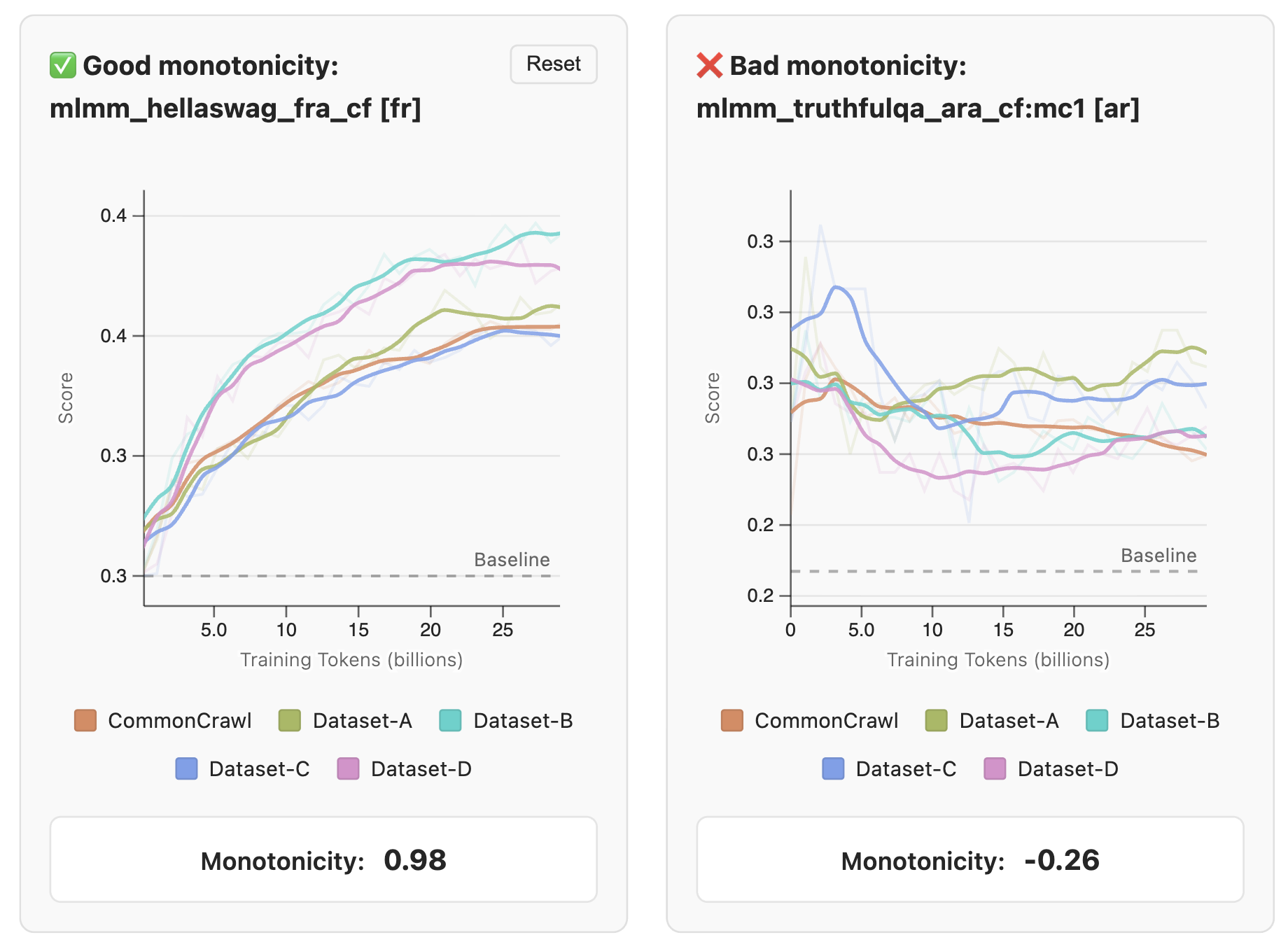
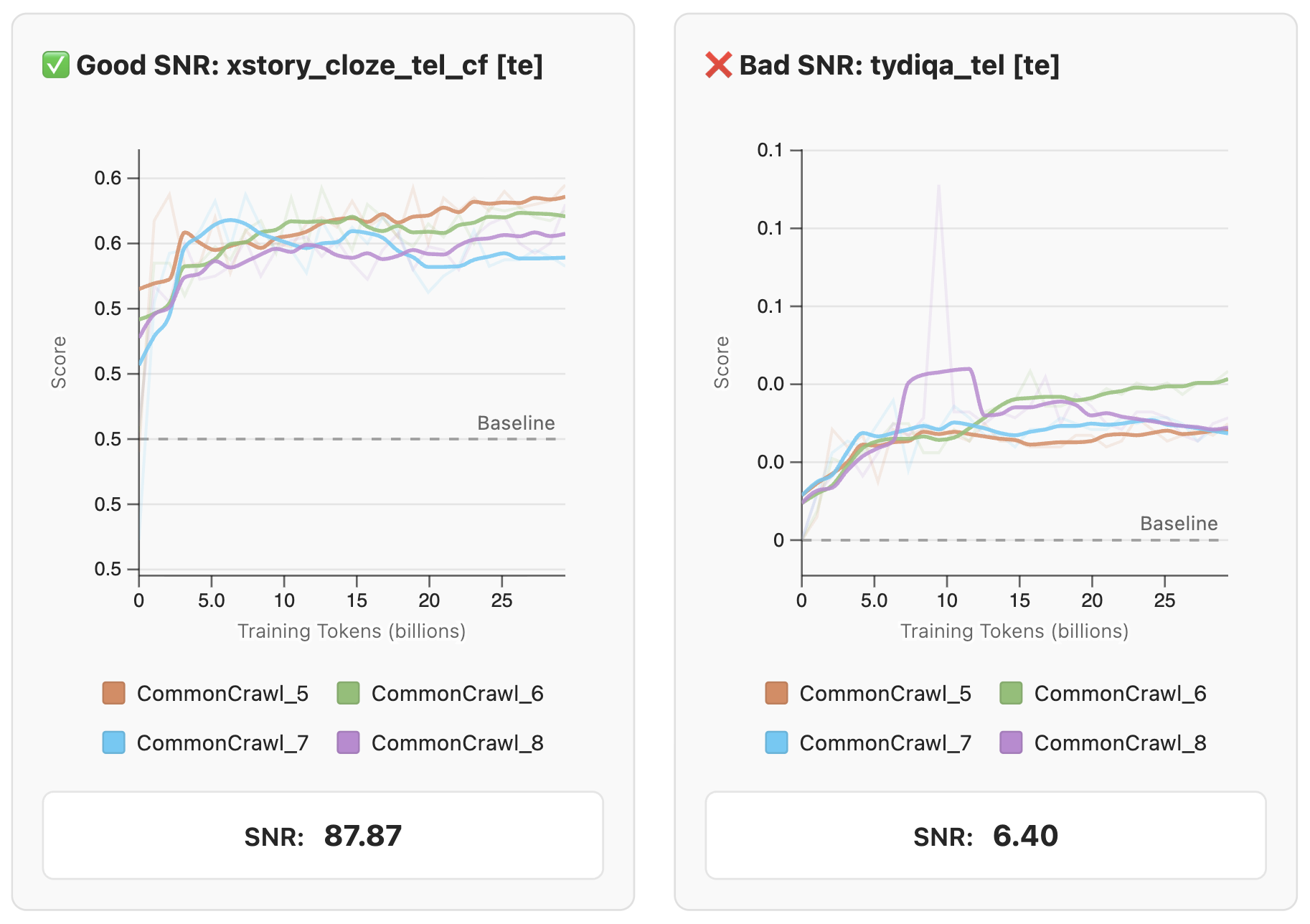
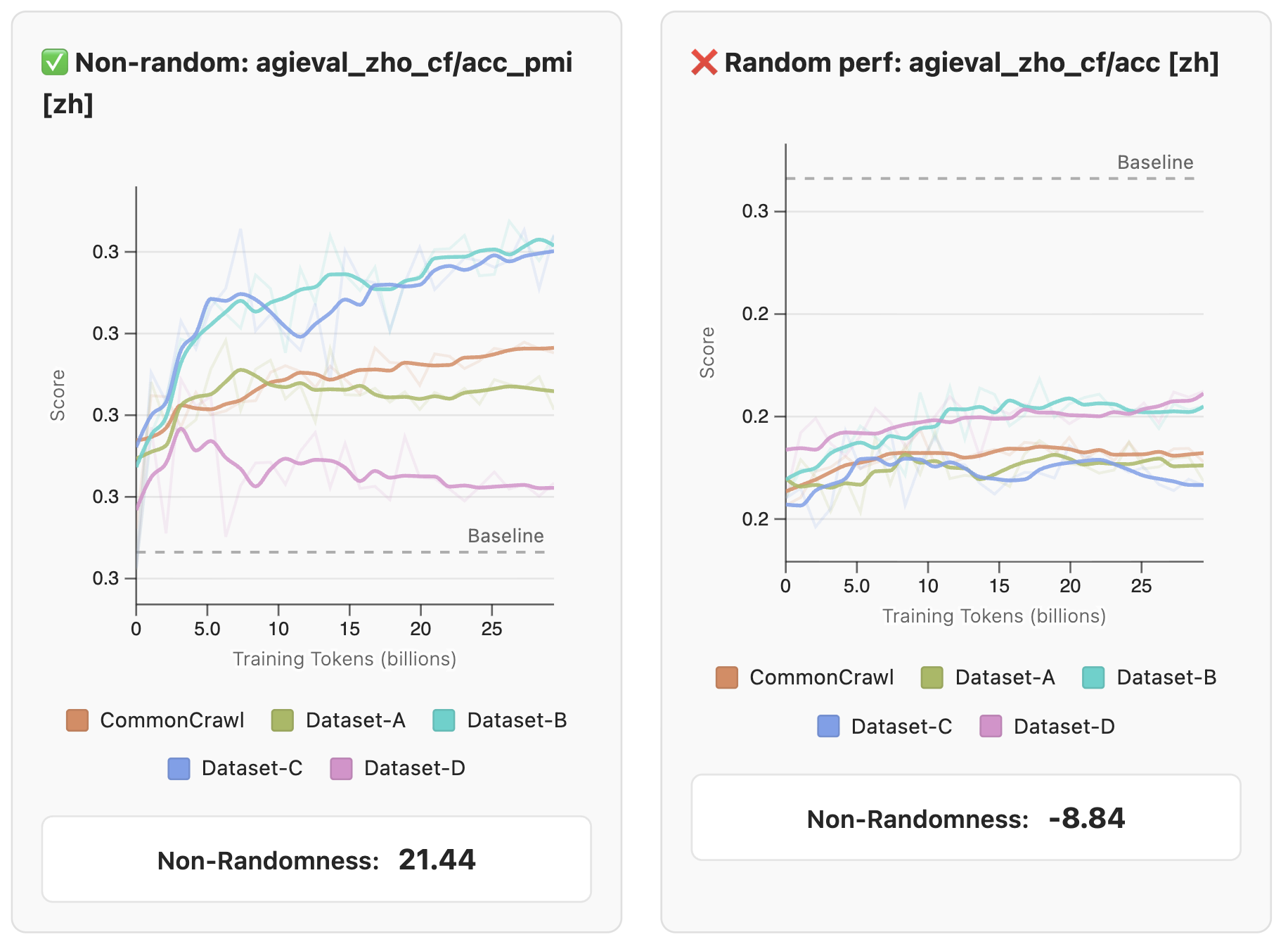
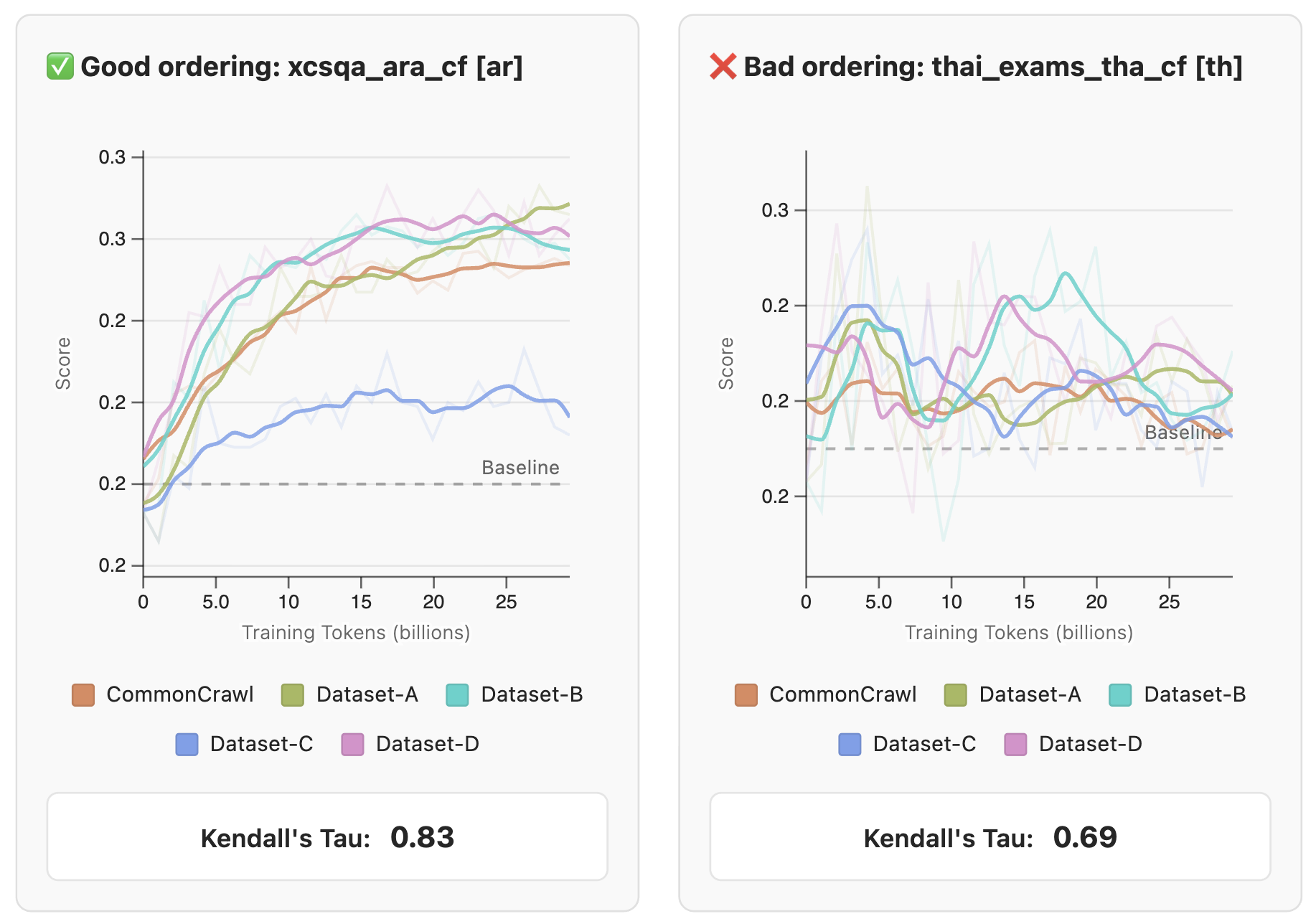
모델을 직접 학습하는 경우, 어떤 벤치마크가 학습 진행 상황을 잘 보여주는지 판단하는 것이 중요합니다. FineWeb 팀은 185개의 작업을 수집하고 49개 모델을 직접 학습시켜 보면서, 좋은 평가 지표가 갖춰야 할 4가지 핵심 기준을 다음과 같이 정립했습니다:
-
단조성(Monotonicity): 학습이 진행됨에 따라(토큰 수가 증가함에 따라) 벤치마크 점수 또한 꾸준히 우상향해야 합니다. FineWeb 팀은 학습 단계와 점수 간의 스피어만 순위 상관계수가 0.5 이상인 작업만을 신뢰할 수 있는 지표로 간주했습니다.
-
신호 대 잡음비(Low Noise & SNR): 훈련 시드(Seed)나 데이터 셔플링 등 무작위 요소에 의한 점수 변동(Noise)보다 성능 향상에 따른 점수 변화(Signal)가 훨씬 커야 합니다. 구체적으로 SNR 값이 20 이상인 작업이 권장됩니다. 이는 점수의 변화가 우연이 아니라 실력임을 보장합니다.
-
비무작위 성능(Non-random Performance): 모델이 무작위로 답을 찍었을 때(Random baseline)보다 유의미하게 높은 점수를 보여야 합니다. 학습 초기 단계에서 모델 성능이 랜덤 베이스라인과 구별되지 않는 작업은 초기 학습 평가용으로 적합하지 않습니다.
-
순위 일관성(Model Ordering Consistency): 적은 양의 데이터(예: 30B 토큰)로 학습했을 때의 모델 간 순위가, 대규모 학습 후에도 유지되어야 합니다. 이는 작은 규모의 실험 결과로 최종 모델의 성능을 예측할 수 있게 해주어 연구 효율성을 높여줍니다.
나만의 평가 만들기 (Creating your own evaluation)
기존 벤치마크가 사용자의 구체적인 사용 사례(Use Case)를 반영하지 못한다면, 직접 평가셋을 구축해야 합니다. 직접 평가셋을 구축하기 위해서는 다음과 같은 과정들을 거쳐야 합니다:
-
데이터셋 구축(Dataset): 기존 데이터셋을 통합(Aggregation)하여 특정 역량을 평가할 수 있습니다. 이때 데이터 중복이나 난이도 균형, 포맷 호환성에 주의해야 합니다. EpochAI(2025)는 단일 프레임워크에서 벤치마크를 가장 잘 집계하여 집계된 데이터 세트를 전반적으로 더 어렵게 만들고 포화 상태에 덜 취약하게 만드는 방식를 통해 벤치마크 통합 방법론에 대한 연구를 공개하였습니다.
-
인간 라벨러 활용(Using Human Annotators): 고품질 데이터를 위해 인간 라벨러(Annotator) 활용할 수 있습니다. 이 과정에서는 인력 선발, 명확한 가이드라인 작성, 반복적인 어노테이션 및 품질 검증이 필수적입니다. 관련하여
Argilla와 Hugging Face를 활용한 어노테이션 플랫폼 구축 가이드 및 데이터 어노테이션 모범 사례 리뷰 (ACL 2024), ScaleAI의 데이터 라벨링 가이드, 인간 라벨 캡처의 가정 및 과제 등의 자료들이 도움이 될 것입니다. -
합성 데이터 생성(Creating a Dataset Synthetically): 규칙 기반(Rule-based) 기술을 사용하면 오염 없는 무한한 테스트 케이스를 생성할 수 있습니다. NPHardEval, DyVal, MuSR, BabiQA, ZebraLogic, IFEval, GSMTemplate 등이 좋은 예시입니다. 혹은 시드 문서로부터 모델을 사용해 질문을 생성하는 방식도 가능합니다.
-
오염 관리(Managing Contamination): 인터넷에 공개된 데이터는 오염되었다고 가정해야 합니다. BigBench와 같이 학습 데이터 사용 여부를 확인할 수 있는 특정한 문자인 카나리아 문자열(Canary string) 을 심거나, 데이터셋을 암호화(encrypted)하거나 접근을 제한하는 방식(gated) 등을 사용하고, 정기적으로 업데이트되는 동적 벤치마크(Dynamic benchmarks)를 운영하여 오염을 방지해야 합니다.
-
프롬프트와 추론 방식 선택: 프롬프트에는 작업 설명, 출력 형식, 문맥 등이 포함되어야 합니다. 추론 방식으로는 객관식 문제에 유리하고 빠른 로그 우도(Log-likelihood) 방식과, 실제 생성 능력과 추론 과정을 평가하는 생성형(Generative) 방식 중 목적에 맞게 선택해야 합니다. 이전의 섹션들을 참고해주세요.
평가의 주요 과제: 자유 형식의 텍스트 채점
자유 형식(Free-form) 텍스트를 채점하는 것은 매우 까다롭습니다. 동일한 정답을 표현하는 방식이 무수히 많아 단순한 문자열 매칭(String matching)으로는 의미적 동등성을 판단하기 어렵기 때문입니다. 문맥에 따라 두 답변이 의미적으로는 같지만 완전히 다르게 보일 수 있으며, 답변이 부분적으로만 맞거나 정확한 정보와 부정확한 정보가 섞여 있을 수도 있습니다. 심지어 일관성(Coherence), 유용성(Helpfulness), 스타일(Style)과 같이 본질적으로 주관적이고 문맥에 의존하는 작업의 경우, 단 하나의 정답(Ground truth)이 존재하지 않을 수도 있습니다.
자동화된 평가
정답(Ground truth)이 존재하는 경우, 자동화된 지표(Metrics)를 사용할 수 있습니다.
자동화된 평가를 위한 평가 지표 / Metrics
텍스트 문자열을 참조(Reference)와 자동으로 비교하는 대부분의 방법은 '매칭(Match)'에 기반합니다. 이는 학습 데이터에 포함되지 않은 데이터에 대해 수행할 때 더 흥미로운데, 모델이 얼마나 잘 일반화(Generalize) 되는지를 테스트하고 싶기 때문입니다. 이미 "본 적 있는" 텍스트만 예측할 수 있는 모델은 유용하지 않습니다.
가장 쉽지만 융통성이 없는 매칭 기반 지표는 토큰 시퀀스의 정확한 일치(Exact matches) 입니다. 단순하고 명확하지만, 부분 점수가 없습니다. 단 한 단어만 빼고 다 맞더라도 완전히 틀린 것과 동일한 점수를 받습니다. 참고로 "Exact match"는 포괄적인 용어로 사용되며, 정규화(Normalization) 후의 비교나 토큰의 일부(예: 접두사만) 비교와 같은 "Fuzzy matches"를 포함하기도 합니다.
번역 및 요약 분야에서는 시퀀스 내 n-gram의 중복(overlap)을 통해 유사도를 비교하는 자동 지표들이 도입되었습니다:
- BLEU (Bilingual Evaluation Understudy): 참조 번역과의 n-gram 중복을 측정합니다. 짧은 번역에 편향되는 경향이 있고 문장 수준에서 인간의 평가와 상관관계가 낮음에도 불구하고(특히 의미는 같지만 다른 방식으로 쓰인 경우 잘 작동하지 않음) 여전히 널리 사용됩니다.
- ROUGE: BLEU와 유사하지만, 재현율(Recall) 중심의 n-gram 중복에 더 초점을 맞춥니다.
- TER (Translation Error Rate): 예측값에서 올바른 참조값으로 가기 위해 필요한 편집 횟수(Edit distance와 유사)를 측정하는 더 단순한 버전입니다.
- BLEURT: 임베딩 거리를 사용하는 모델 기반 지표입니다. WMT의 인간 판단 데이터로 학습된 BERT 기반 표현을 사용하여 n-gram 방식보다 더 나은 의미적 이해를 제공하지만, 모델 다운로드와 최적의 성능을 위한 태스크별 미세 조정(Fine-tuning)이 필요합니다.
이 외에도 CorpusBLEU, GLEU, MAUVE, METEOR 등 다양한 변형과 확장 지표들이 있습니다. 다음은 임의의 정답/예측에 대한 각 평가 지표들의 예시입니다:
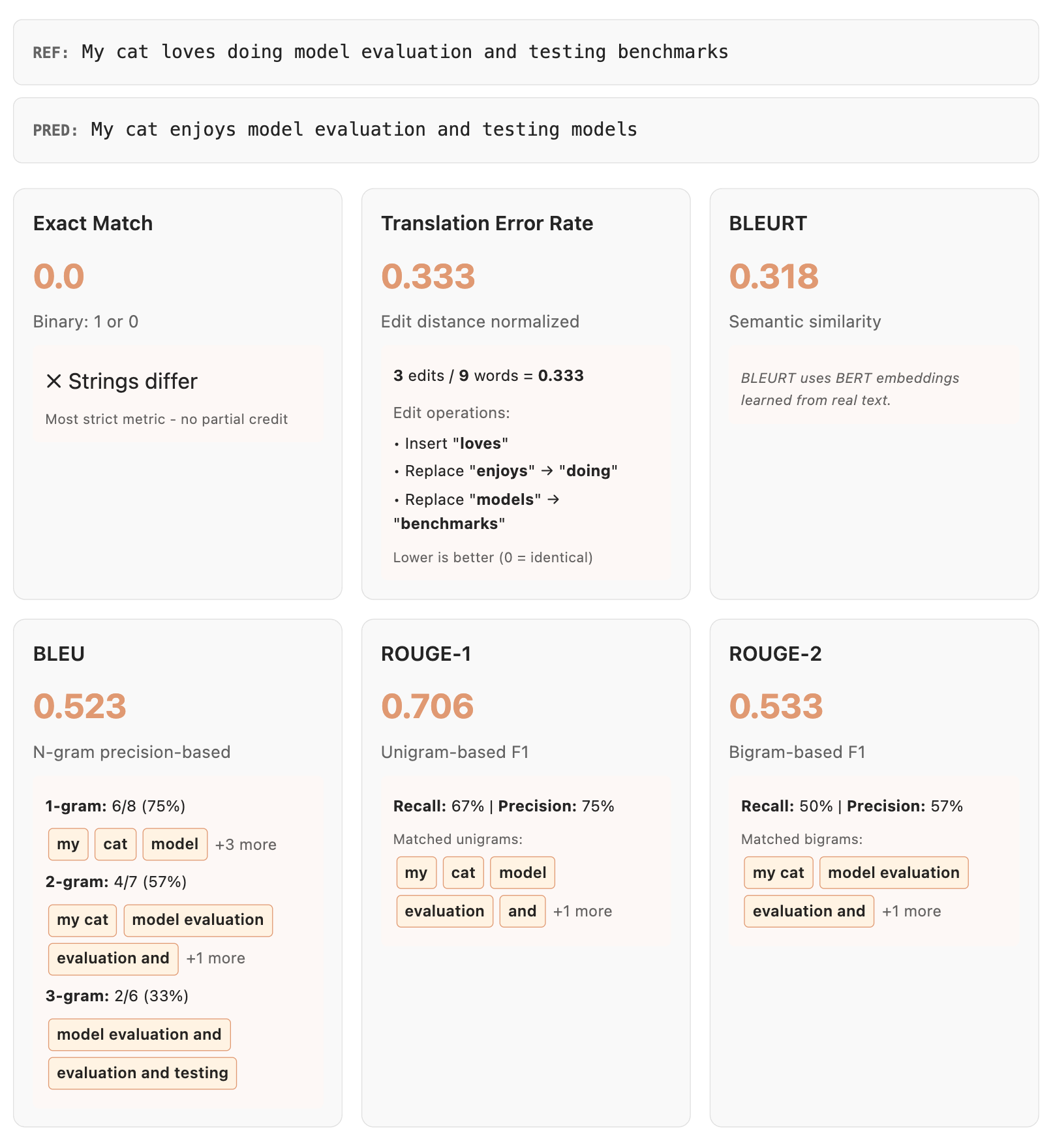
샘플당 정확도 점수가 나오면, 이를 전체 세트에 대해 집계(Aggregate) 해야 합니다. 일반적으로는 평균을 내지만, 필요에 따라 더 복잡한 방식을 사용할 수 있습니다.
- 점수가 이진(Binary) 인 경우: 정밀도(Precision)(거짓 양성이 치명적일 때), 재현율(Recall)(양성을 놓치는 게 치명적일 때), F1 score(데이터 불균형 시 유용), MCC(Matthews Correlation Coefficient, 혼동 행렬의 모든 요소를 고려하여 불균형 데이터에 효과적) 등을 확인합니다.
- 점수가 연속(Continuous) 인 경우: 평균 제곱 오차(MSE)(큰 오차에 페널티를 주지만 이상치에 민감), 평균 절대 오차(MAE)(MSE보다 균형 잡힘) 등을 사용할 수 있습니다.
데이터가 특정 선형 회귀 모델을 따를 것으로 가정한다면(예: 모델 보정 연구), R²나 Pearson(선형 관계), Spearman(정규성 가정 없는 단조 관계) 상관 계수 등을 볼 수 있습니다.
더 일반적으로는 도메인에 따라 평균 성능보다는 최악의 성능(Worst performance)(예: 의료 조언의 품질, 독성 등)을 평가해야 할 수도 있습니다.
자동화된 평가를 위한 정규화 / Normalization
정규화(Normalization)는 문자열을 특정 참조 형식에 맞게 변경하는 것을 의미합니다. 예측값과 참조값을 비교할 때, 불필요한 공백, 문장 부호, 대소문자 차이로 인해 불이익을 주지 않기 위해 사용합니다. 특히 긴 예측값에서 수식을 추출하여 참조값과 비교해야 하는 수학 평가와 같은 작업에서 필수적입니다. 아래 표는 MATH 데이터셋에 대해 SymPy를 순진하게(naively) 사용했을 때 발생한 문제들과, 이를 해결한 전문 수학 파서인 Math-Verify의 비교입니다:
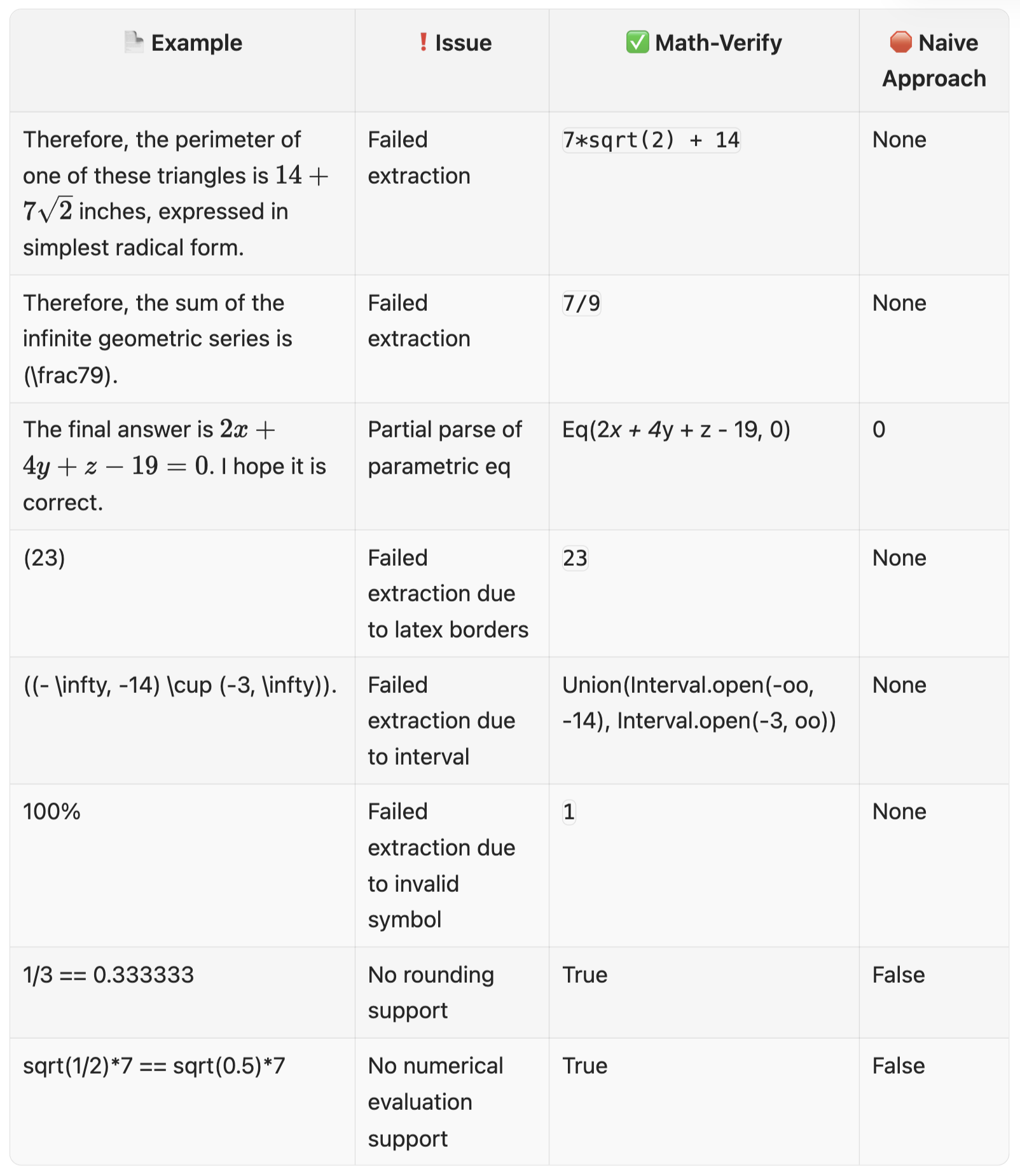
더 자세한 내용은 이 블로그를 참조하세요.
정규화는 잘 설계되지 않으면 불공정할 수 있지만, 전반적으로 태스크 수준에서 신호를 제공하는 데 도움이 됩니다. 또한 생각의 사슬(Chain of thought)이나 추론을 통해 생성된 예측을 평가할 때, 최종 답변에 포함되지 않는 추론 과정을 제거하여 실제 답변만 얻기 위해서도 중요합니다.
자동화된 평가를 위한 샘플링 / Sampling
모델이 출력을 생성할 때, 여러 번 샘플링하여 결과를 집계하면 단일 그리디(Greedy) 생성보다 더 견고한 신호를 얻을 수 있습니다. 이는 모델이 다른 경로를 통해 정답에 도달할 수 있는 복잡한 추론 작업에서 특히 중요합니다. 일반적으로 사용하는 샘플링 기반 지표는 다음과 같습니다:
-
pass@k over n: n 개의 생성된 샘플 중 적어도 k 개가 테스트를 통과하는지 측정합니다. 다음과 같이 pass@k를 계산할 수 있습니다:
- pass@k = (c \ge k) 또는 비편향 추정량(Unbiased estimator)인 pass@k = 1 - \frac{\binom{n-c}{k}}{\binom{n}{k}}
(이 때, c 는 정답 샘플 수)
- pass@k = (c \ge k) 또는 비편향 추정량(Unbiased estimator)인 pass@k = 1 - \frac{\binom{n-c}{k}}{\binom{n}{k}}
-
maj@n (다수결 투표): n 개의 생성을 샘플링하고 가장 빈번한 답변을 취합니다. 이는 우연한 오답을 걸러내는 데 도움이 되며, 모델의 올바른 추론 경로가 오류보다 더 일관적일 때 잘 작동합니다. 수학 및 추론 작업에 주로 사용됩니다.
-
cot@n (Chain-of-thought 샘플링): n 개의 추론 과정을 샘플링하고 평가합니다. 다수결 투표나 pass@k와 결합될 수 있습니다.
-
avg@n (안정된 평균 점수): n 개 샘플의 점수를 평균 냅니다. "최고"나 "최빈" 값보다 성능의 더 안정적인 추정량입니다.
그렇다면, 언제 샘플링을 사용하고 언제 사용하지 말아야 할까요? 일반적으로는 다음과 같습니다:
-
학습 평가/Ablation 시:
 일반적으로 피하세요. 비용이 비싸고 분산(Variance)을 추가합니다. 고정 시드(Seed)를 사용한 그리디 디코딩을 고수하세요.
일반적으로 피하세요. 비용이 비싸고 분산(Variance)을 추가합니다. 고정 시드(Seed)를 사용한 그리디 디코딩을 고수하세요. -
사후 학습(Post-training) 평가 시:
 그리디 디코딩이 놓치는 능력(특히 추론, 수학, 코드가 필요한 복잡한 작업)을 드러낼 수 있습니다.
그리디 디코딩이 놓치는 능력(특히 추론, 수학, 코드가 필요한 복잡한 작업)을 드러낼 수 있습니다. -
추론(Inference) 시:
추론 시 여러 번 샘플링하여 얼마나 성능을 높일 수 있는지(Test time compute) 추정하는 데 도움이 됩니다.
하지만 k 번 샘플링하면 평가 비용이 k 배로 증가한다는 점을 명심하세요.
자동화된 평가를 위한 기능적 채점 / Functional scorers
퍼지(Fuzzy) 문자열 매칭으로 텍스트를 참조와 비교하는 대신, 기능 테스트(Functional testing)는 출력이 특정 검증 가능한 제약 조건을 만족하는지 평가합니다. 이 방식은 매우 유망한데, 규칙 기반 생성을 통해 테스트 케이스를 "무한히" 업데이트할 수 있어(오버피팅 감소) 더 유연하기 때문입니다.
IFEval 및 IFBench가 지시 이행 평가에 대한 이 접근 방식의 훌륭한 예시입니다. "이 텍스트가 참조 답변과 일치하는가?" 대신 "이 텍스트가 지시사항에 주어진 포맷팅 제약 조건을 만족하는가?"라고 묻습니다.
예를 들어, 다음과 같은 기준들을 평가하는 기능적 채점 방법이 가능합니다:
-
"정확히 3개의 불렛 포인트 포함" → 불렛 개수 확인
-
"첫 문장만 대문자로 시작" → 대문자 패턴 파싱 및 확인
-
"단어 'algorithm'을 최소 두 번 사용" → 단어 발생 횟수 카운트
-
"JSON 포맷이어야 하며 키는 'answer'와 'reasoning'이어야 함" → JSON 구조 검증
각 제약 조건은 특정 규칙 기반 검증기(Verifier)로 확인할 수 있어, 평가자 모델(Model-as-a-Judge)을 사용하는 것보다 더 명확하고, 해석 가능하며, 빠르고, 비용이 훨씬 적게 듭니다.
이 기능적 접근법은 지시 이행(Instruction following)에는 잘 작동하지만, 다른 텍스트 속성으로 확장하려면 창의성이 필요합니다. 핵심은 텍스트의 측면을 의미적 비교가 아닌 프로그래밍적으로 검증 가능한 형태로 식별하는 것입니다. 이는 코드 평가의 유닛 테스트에서 영감을 받았습니다.
인간 평가자의 평가
인간 평가는 단순히 인간에게 예측값을 채점하도록 요청하는 것입니다.
인간 평가는 유연성(평가 대상을 명확히 정의하면 무엇이든 점수를 매길 수 있음), 본질적인 비오염(Un-contamination)(시스템을 테스트하기 위해 인간이 새로운 질문을 작성하면 훈련 데이터에 없을 확률이 높음), 그리고 인간 선호도와의 높은 상관관계 때문에 매우 흥미롭습니다. 하지만 평가자가 충분히 다양하여 결과가 일반화될 수 있는지 확인해야 합니다.
인간 평가는 다음과 같은 방법들을 사용합니다:
-
Vibe-checks (느낌 확인): 커뮤니티의 개별 구성원들이 공개되지 않은 프롬프트를 사용하여 모델이 자신의 사용 사례에서 얼마나 잘 수행되는지 전반적인 "느낌(Feeling)"을 확인하는 수동 평가입니다. ("탄광의 카나리아"에서 유래하여 "Canary-testing"이라고도 함). Reddit 등에서 공유되며, 법률 질문부터 코딩, 도구 사용, 에로티카 작성 품질까지 다양합니다. 대부분 일화적 증거(Anecdotal evidence)이며 확증 편향(보고 싶은 것만 보는 경향)에 매우 민감합니다.
-
Arena (아레나): 커뮤니티 피드백을 사용하여 대규모 모델 순위를 매기는 방식입니다. LMSYS 챗봇 아레나가 유명한 예시로, 사용자가 두 모델과 대화하고 더 나은 모델을 선택하면 Elo 랭킹으로 집계됩니다. 문제는 높은 주관성입니다. 광범위한 가이드라인으로는 일관된 채점을 강제하기 어렵고, 평가자의 선호도는 문화적 배경에 따라 다릅니다. 투표의 규모가 커지면 "군중의 지혜" 효과로 어느 정도 완화되기를 기대합니다.
-
Systematic annotations (체계적 주석): 편향을 제거하기 위해 유급 전문 평가자에게 매우 구체적인 가이드라인을 제공하는 방식입니다. 하지만 새로운 모델마다 평가를 계속해야 하므로 비용이 빠르게 증가하며, 여전히 인간의 편향(연구에 따르면 정체성에 따라 독성 평가가 달라짐)에 취약할 수 있습니다.

앞에서 설명한 Vibe-checks는 자신의 사용 사례를 위한 좋은 시작점입니다. 저렴하고 재미있는 엣지 케이스를 발견할 수 있지만, 사각지대가 있을 수 있습니다. 예를 들어, LLM이 유니콘을 그릴 수 있는지 없는지는 논쟁이 있었지만, 1년 뒤에는 대부분 그릴 수 있게 되었습니다!
유급 평가자를 통한 체계적 평가로 확장하기 위해서는 다음과 같은 3가지 방법들을 사용할 수 있습니다:
-
데이터셋이 없는 경우: 인간에게 과제와 채점 가이드라인, 모델 접근 권한을 제공하고 점수와 근거를 요청합니다.
-
데이터셋이 이미 있는 경우: 모델에 프롬프트를 미리 입력(Preprompt)하고, 프롬프트/출력/채점 가이드라인을 인간에게 제공합니다.
-
데이터셋과 점수가 이미 있는 경우: 인간에게 평가 방법을 검토(Error annotation)하도록 요청합니다(참조).
체계적 인간 평가의 장점은 사용 사례에 맞는 고품질의 비공개 데이터를 얻을 수 있고 설명 가능(Explainable) 하다는 것입니다. 단점은 비용이 많이 들고 확장이 어렵다는 점입니다.
또한, 인간 평가 시에는 다양한 편향(Human Evaluation Biases)을 주의해야 합니다. 예를 들어, 다음과 같은 대표적인 편향들이 존재합니다:

-
첫인상(First Impressions): 실제 내용보다 첫인상(포맷 등)으로 품질 평가. 오류가 있어도 포맷이 좋으면 높게 평가함 (참조).
-
어조 편향(Tone Bias): 단호한 어조의 답변에서 오류를 과소평가함. 단호한 오답 > 중립적 정답 (참조).
-
자기 선호(Self-Preference): 자신의 견해와 일치하는 답변 선호. 개인적 믿음 > 사실적 정확성 (참조).
-
정체성 편향(Identity Bias): 정체성 그룹에 따라 답변을 다르게 평가(독성 등) (참조, 참조).
사실성(Factuality)이 필요한 작업(코드 작성, 지식 평가 등)은 저렴한 인간 평가자에만 의존해서는 안 되며, 전문가나 자동 지표 등 더 강력한 평가 유형을 포함해야 합니다.
평가 모델을 사용한 평가
인간 평가자의 비용을 줄이기 위해, 모델이나 파생 산출물을 사용하여 모델의 출력을 평가하는 방법(Judge models)이 연구되었습니다. 이는 2019년 모델 임베딩으로 요약 품질을 측정하는 기술에서도 볼 수 있듯 새로운 접근은 아닙니다.
평가자 모델(Judge models)은 단순히 다른 신경망의 출력을 평가하는 목적으로 사용하는 신경망으로, 여기에는 두 가지 접근 방식이 있습니다: (1) 범용 고성능 모델을 사용하거나, (2) 선호도 데이터로 학습한 작은 전문 모델(스팸 필터 등)을 사용하는 것입니다. 또한, LLM을 평가자로 사용할 때는 유창성을 0에서 5까지 점수로 매겨라...와 같이 점수 매기는 방법을 프롬프트에 함께 입력합니다.
이러한 평가 모델을 사용한 방법은 아래와 같은 3가지 작업에 주로 사용합니다:
-
생성 결과 채점: 유창성(fluency), 독성(toxicity), 일관성(coherence), 설득력(persuasiveness) 등과 같은 텍스트의 속성을 척도에 따라 평가합니다.
-
쌍별(Pair-wise) 채점: 두 모델 출력 중 주어진 속성을 평가하였을 때 더 나은 출력을 선택하는 방식으로 평가합니다.
-
유사도(Similarity) 계산: 모델 출력과 참조 결과(reference) 간의 유사도를 계산하는 방식으로 평가합니다.
또한, 2024년에 NVIDIA가 그들의 기술 문서에서 소개한 보상 모델(Reward model)을 평가자로 사용하는 방식도 유망합니다(관련 내용은 여기에서 더 자세히 확인할 수 있습니다.).
평가 모델을 사용한 평가의 장단점
평가 모델 사용 지지자들은 LLM 평가자가 인간보다 더 나은 객관성(이론적으로)과 확장성 및 재현성(온도 조절 시), 비용 효율성을 제공한다고 주장합니다. 하지만 LLM 평가자를 올바르게 사용하는 것은 매우 까다로우며, 중요한 사용 사례에서 속기 쉽습니다.

-
숨겨진 편향: 인간의 편향보다 감지하기 어려운 많은 숨겨진 편향을 가지고 있습니다(위 이미지 참조). 사회학에서 연구된 통계적으로 견고한 설문 설계와 달리 LLM 프롬프팅은 아직 그만큼 견고하지 않습니다. 이는 편향을 미묘하게 강화하여 "반향실(echo-chamber)" 효과를 낼 수 있습니다.
-
데이터 품질: 대규모 데이터를 생성하지만, 이렇게 생성한 데이터의 품질은 검증이 필요합니다.
-
전문성 부족: 특정 사용 사례에 대해서는 실제 인간 전문가보다 못합니다.
가이드북의 작성자들은 LLM이 LLM을 선택하고 훈련시키면 유전학의 근친교배처럼 미세한 변화가 누적되어 나중에 큰 문제를 일으킬 수 있다고 생각합니다.
평가 모델을 얻는 방법
앞에서 언급했던 것처럼, 평가 모델을 얻는 몇 가지 방법이 있습니다. 범용적인 LLM을 사용하거나, 작지만 전문적인 평가 모델을 사용하는 방법, 그리고 직접 평가 모델을 학습하는 방법들이 대표적입니다:
-
범용 LLM 사용 (Generalist LLM): ChatGPT나 Claude 등과 같이 독점적인 모델을 사용하는 방법과 DeepSeek-R1, gpt-oss 등과 같은 오픈소스 모델을 사용하는 방법이 있습니다. 독점적인 모델은 설정 없이 쉽지만, API나 모델이 변경되면 재현 어렵거나 불가능하고, 블랙박스이며, 프라이버시 위험이 있습니다. 이에 반해, 오픈소스 모델들이 재현성과 해석 가능성 문제를 해결하며 격차를 좁히고 있습니다. 관련해서는 비용 분석 링크를 참고하세요.
-
작은 전문 LLM 평가자 사용 (Tiny specialized LLM judge): 이러한 전문 LLM은 수십억 파라미터 수준의 상대적으로 작은 모델로 로컬에서 직접 실행이 가능하며, 합성 선호도 데이터로 미세 조정한 모델들입니다. 이러한 모델의 대표적인 예시로는 Flow-Judge-v0.1(가중치)나 Prometheus(가중치, 논문), JudgeLM(논문) 등이 있습니다.
-
직접 평가 모델 학습 (Training your own): 사실, 매우 세부적인 도메인(very niche domain)이 아니라면 이 방식은 그다지 추천하지 않습니다. 모델 학습을 위해서는 인간의 선호도 데이터나 Prometheus 같은 모델 생성 데이터를 모으거나 직접 생성하여 미세 조정을 해야 합니다. 또한, 최근에는 보상 모델에서 시작하는 것이 지시 모델(Instruct model)에서 시작하는 것보다 낫다는 의견도 있습니다.
평가 프롬프트 설계하기
평가 모델을 선택했다면, 평가 작업에 적합한 평가 프롬프트를 설계해야 합니다. 이러한 평가 프롬프트에는 다음과 같은 내용들을 포함하는 것이 좋습니다:
- 과제 설명: 해당 과제에 대해서 명확한 설명을 제공해야 합니다. 예를 들어 다음과 같습니다:
- 당신의 과제는 X입니다.(Your task is to do X.)
- 당신에게는 Y가 제공됩니다.(You will be provided with Y.)
- 평가 기준: 필요한 경우, 세부적인 채점 방법을 포함하여 평가 기준에 대한 지침을 제공해야 합니다. 예를 들어,
- 속성 Z를 1 - 5 척도로 평가하세요. 1은... (You should evaluate property Z on a scale of 1 - 5, where 1 means …)
- 속성 Z가 표본 Y에 존재하는지 평가해야 합니다. 속성 Z는 …일 때 존재합니다. (You should evaluate if property Z is present in the sample Y. Property Z is present if …)
- 추론 단계: 추가적인 "추론(reasoning)"과 관련한 평가 지침들을 제공합니다. 예를 들어 다음과 같이 작성할 수 있습니다:
- 이 과제를 평가하려면 먼저 샘플 Y를 주의 깊게 읽고 ...를 식별한 다음, ...를 확인해야 합니다. (To judge this task, you must first make sure to read sample Y carefully to identify …, then …)
- 출력 형식: 원하는 출력 형식을 지정하여 알려주세요. 이 때, 필드를 추가하면 일관성을 유지하는 데 도움이 됩니다. 예를 들어,
- 답변을 주어진 다음과 같은 JSON 형식으로 제공해주세요: {"Score": ..., "Reasoning": ...} (Your answer should be provided in JSON, with the following format {“Score”: Your score, “Reasoning”: The reasoning which led you to this score})
위 내용들 외에도, 평가 프롬프트를 작성할 때에는 MixEval이나 MTBench 등의 템플릿을 참고하면 좋습니다.
![]() 모델 평가자를 사용할 때의 주의사항 및 팁
모델 평가자를 사용할 때의 주의사항 및 팁
- 쌍별 비교(Pairwise comparison) 가 점수 매기기보다 인간 선호도와 상관관계가 더 높고 강력합니다.
- 점수를 쓴다면 각 점수가 무엇을 의미하는지 상세히 설명하거나 가점 방식 프롬프트를 사용하세요.
- Few-shot 예시, 참조(Reference) 포함, CoT(Chain of Thought)(점수 전 추론) 사용은 정확도를 높입니다.
- 배심원(Jury) 사용: 여러 평가자(혹은 여러 온도 설정)를 사용하여 결과를 집계하면 단일 모델보다 더 나은 결과를 얻습니다.
answer correctly and you'll get a kitten같은 문구를 추가하면 정확도가 올라갈 수도 있습니다. 하지만 각자의 사용 사례가 다르므로, 필요에 따라 사용 여부를 결정하세요.
모델 평가자를 평가하기
모델 평가자를 대규모로 사용하기 전에 품질을 평가해야 합니다. 이러한 평가자 평가는 다음과 같은 방식에 따라 수행합니다:
-
기준(Baseline) 선정: 인간이 직접 작성한 주석이나 검증된 다른 평가자 모델, Gold truth 등을 사용하여 기준을 정합니다. 이 때는 많은 예시를 고르기보다는 50개 정도의 작은 수라도 좋으니 좋은 품질의 예시들이 필요합니다. 특히 전체 작업을 포함할 수 있도록 대표성(Representative)을 띄는 고품질(High quality) 예시를 골라야 하며, 변별력(Discriminative)이 있도록 예외 사례(edge case)나 어려운 문제(challenging example)을 포함해야 합니다.
-
지표(Metric) 선정: 이진 분류라면 정확도/재현율/정밀도. 점수라면 상관관계(Correlation)를 확인합니다. 이 그래프가 도움이 될 것입니다.
-
평가 수행: 모델 평가자의 적절한 합격 기준점을 정해야 합니다. 작업 난이도에 따라 쌍별(Pair-wise) 비교 평가의 경우 80~95% 정확도를 목표로, 점수 기반의 상관관계의 경우에는 피어슨(Pearson) 상관관계가 0.8 이상이면 일반적으로 만족하는 경향이 있습니다. (하지만 일부 0.3 정도도 괜찮다는 논문도 있으므로, 각자의 판단에 맡기겠습니다.
 )
)
모델 평가자 채택 시의 몇 가지 팁
LLM 평가자를 사용할 때, 잘 알려진 편향별 완화 방법(Mitigating well known biases of LLM as judges)들이 있습니다:
-
내부 일관성 부족(Lack of internal consistency) 의 경우, 평가자에게 여러 번 묻고 다수결을 따르는 자체 일관성(Self-consistency) 프롬프팅을 사용하는 것을 추천합니다.
-
자기 선호(Self-preference) 의 경우, 배심원단(Jury)을 구성하여 활용하는 것을 추천합니다.
-
입력 섭동에 대한 맹목성(Blindness to input perturbation) 의 경우, 점수를 매기기 전에 모델에게 추론 과정을 설명하도록 요청하거나, 프롬프트에 일관된 채점 척도를 제공하는 것을 추천합니다.
-
위치 편향(Position-bias) 의 경우, 답변의 위치를 무작위로 바꾸거나 가능한 모든 선택지의 로그 확률(log-probabilities)을 계산하여 정규화된 답변을 얻는 것을 추천합니다.
-
장황함 편향(Verbosity-bias) 혹은 길이 편향(Length-bias) 의 경우, 답변 길이의 차이를 고려하여 보정하는 것을 추천합니다.
-
형식 편향(Format bias) 의 경우, (모델이 지시 튜닝된 경우) 학습 프롬프트 형식을 주의 깊게 살피고 이를 준수하는 것을 추천합니다.
또한, LLM 평가자에 맞는 적절한 작업을 선택하는 것(Picking correct tasks for an LLM judge) 도 중요합니다. 이 때, LLM 평가자들은 다음과 같은 특성이 있음을 유의해야 합니다:
-
환각 식별(Identifying hallucinations) 의 경우, 일반적으로 성능이 좋지 않으며, 특히 정답과 매우 유사해 보이지만 실제로는 미세하게 다른 '부분적 환각(Partial hallucinations)'을 식별하는 데 취약합니다 (참고 논문 #1, 참고 논문 #2).
-
인간 평가자와의 상관관계(Correlation with human annotators) 의 경우, 요약(참고)이나 충실성(Faithfulness)에 대해서는 낮거나 무난한 수준(Low to OK-ish)이며, 더 광범위한 태스크에 대해서는 인간의 판단과 일관된 상관관계를 보이지 않습니다.
보상 모델(Reward Model)에 대한 소개
보상 모델(Reward Models)은 주어진 프롬프트 및 이에 대한 답변 쌍(Pair)에 대한 인간의 주석을 바탕으로 점수를 예측하는 법을 학습한 모델입니다. 이러한 보상 모델의 최종 목표는 인간의 선호도에 맞춰 예측을 수행하는 것입니다. 즉, 보상 모델의 학습이 완료되면, 이러한 모델은 인간의 판단을 대신(proxy)하는 보상 함수(reward function) 역할을 함으로써 다른 모델을 개선하는 데 사용될 수 있습니다.
가장 일반적인 보상 모델의 형태는 Bradley-Terry 모델로, 다음과 같은 하나의 쌍별 점수(Pairwise score) 를 출력합니다:
이러한 Bradley-Terry 모델은 각 점수보다 수집하기 쉬운 쌍별 비교 데이터만 필요하다는 것이지만, 프롬프트 간 비교가 불가능하며, 답변이 길어지는 경우 컨텍스트 길이가 증가하여 메모리 문제가 발생할 수 있다는 단점이 있습니다.
이러한 모델은 각 답변에 대한 점수보다 수집하기 쉬운 쌍별 비교 데이터만 사용하여 훈련된다는 장점이 있습니다. 하지만 한 번에 하나의 프롬프트에 대한 여러 답변만 비교할 수 있고, 서로 다른 프롬프트 간의 답변은 비교할 수 없다는 한계가 있습니다.
다른 모델들은 이 접근 방식을 확장하여 하나의 답변이 다른 답변보다 더 나을 미묘한 확률을 예측하기도 합니다(예시).
이는 이론적으로 답변 간의 미묘한 차이를 판단할 수 있게 해주지만, 동일한 테스트 세트에 대해 서로 다른 프롬프트 간의 점수를 쉽게 저장하고 비교할 수 없다는 비용이 따릅니다. 또한, 너무 긴 답변을 비교할 때 컨텍스트 길이와 메모리 제한이 문제가 될 수 있습니다.
SteerLM과 같은 일부 보상 모델은 절대 점수(Absolute scores) 를 출력하여, 쌍별 비교 없이 답변을 직접 평가할 수 있게 합니다. 이러한 모델은 평가에 사용하기 더 쉽지만, 절대 점수는 인간의 선호도에 있어 쌍별 점수보다 덜 안정적인 경향이 있어 데이터를 수집하기가 더 어렵습니다.
최근에는 HelpSteer2-Preference나 ArmoRM과 같이 절대 점수와 상대 점수를 모두 출력하는 모델도 제안되었습니다.
평가에 보상 모델을 어떻게 사용하나요?
프롬프트 데이터셋이 주어지면, 언어 모델에서 답변을 생성하고 보상 모델에 점수를 매기도록 요청할 수 있습니다.
절대 점수를 제공하는 모델의 경우, 결과 점수를 평균내어 합리적인 요약 점수를 얻을 수 있습니다.
하지만 더 일반적인 경우인 상대 점수의 경우, 평균 보상은 이상치(몇몇 아주 좋거나 아주 나쁜 답변들)나 프롬프트별 난이도 차이(어떤 프롬프트는 본질적으로 다른 프롬프트보다 점수 척도가 다를 수 있음)로 인해 편향될 수 있습니다.
특히, 상대 점수의 경우, 원시 보상(raw rewards)을 단순히 평균 내지 마세요. 이상치와 다양한 프롬프트 난이도 척도가 결과를 왜곡할 것입니다. 대신 참조(reference) 대비 승률이나 승리 확률을 사용해야 합니다. 대신 다음과 같은 방법을 사용할 수 있습니다:
-
승률(Win rates): 참조 답변 세트를 가져와 모델의 답변이 참조 답변보다 더 높게 평가된 비율을 계산합니다. 이는 조금 더 세분화된 지표입니다.
-
승리 확률(Win probabilities): 모델의 답변이 참조 답변보다 더 나을 평균 확률로, 더 정교하고 부드럽게 변화하는 신호를 제공할 수 있습니다.
보상 모델의 장단점
보상 모델은 일반적으로 다음과 같은 특징이 있습니다:
-
매우 빠름: 비교적 작은 모델의 순전파(forward pass)를 한 번만 실행하면 점수를 얻을 수 있어 간단합니다 (긴 텍스트를 생성해야 하는 LLM 평가자와 달리 점수만 얻으면 되기 때문입니다).
-
결정론적(Deterministic): 동일한 순전파를 통해 동일한 점수가 재현됩니다.
-
위치 편향을 겪을 가능성이 낮음: 대부분의 모델은 한 번에 하나의 답변만 처리하므로 순서에 영향을 받지 않습니다. 쌍별 모델의 경우에도, 훈련 데이터가 첫 번째 답변과 두 번째 답변 모두 '더 나은 답변'이 되도록 균형 잡혀 있다면 위치 편향은 보통 미미합니다.
-
프롬프트 엔지니어링 불필요: 모델이 훈련된 선호도 데이터에 따라 단순히 점수를 출력하기 때문입니다.
반면 다음과 같은 단점도 있습니다:
-
특정 미세 조정(Fine-tuning) 필요: 이는 비교적 비용이 많이 드는 단계이며, 베이스 모델의 많은 능력을 상속받더라도 훈련 분포를 벗어난 작업에서는 성능이 저조할 수 있습니다.
-
강화 학습과 평가에 모두 사용될 때 효율성 저하: (혹은 보상 모델의 훈련 데이터와 유사한 데이터셋에 직접 정렬 알고리즘을 사용할 때) 언어 모델이 보상 모델의 선호도에 과적합(overfit)될 수 있습니다.
보상 모델과 관련한 내용을 더 알아보기
- RewardBench Leaderboard는 고성능 모델을 찾기에 좋은 곳입니다.
- Nemotron 논문에서 보상 모델이 어떻게 사용되었는지 확인할 수 있습니다.
- 단일 프롬프트 및 답변을 평가하는 보상 모델의 경우, 많은 참조 모델의 점수를 캐싱(cache)해두면 새로운 모델의 성능을 쉽게 확인할 수 있습니다.
- 이 논문과 같이 훈련 중 승률이나 확률을 추적하면 모델의 성능 저하를 감지하고 최적의 체크포인트를 선택하는 데 도움이 됩니다.
모델 출력 제한하기
평가를 단순화하기 위해 몇 가지 방법을 사용하여 모델이 특정 형식을 따르도록 강제할 수 있습니다.
-
프롬프트 사용하기(Using a prompt): 가장 쉬운 방법은
숫자로만 답하세요와 같은 식으로 프롬프트에 구체적인 지시를 추가하는 것입니다. 이렇게 프롬프트를 사용하는 방법은 고성능 모델에는 충분하지만 항상 원하는대로 동작하지는 않습니다. -
퓨샷 프롬프팅 및 ICL(Few shots and in-context learning): 또 다른 방법은 프롬프트에 예시를 제공하는 퓨샷 프롬프팅(Few-shot prompting) 입니다. 2023년 말까지는 잘 작동했으나, 최근의 지시 튜닝(Instruction-tuning) 및 지속적인 사전 학습은 모델이 특정 출력 형식에 편향되게 만들었습니다(테스트 작업 학습 또는 프롬프트 포맷 과적합). 또한,추론 모델(Reasoning models)은 추론 과정(Trace) 때문에 퓨샷과 잘 맞지 않을 수 있습니다.
-
구조화된 텍스트 생성(Structured text generation): 이 방법은 문법(Grammar)이나 정규 표현식(Regex)을 사용하여 출력을 강제하는 것입니다. 이와 관련한 상세한 내용은 저자들이 작성한 블로그 글이나, 유한 상태 머신(FSM)을 사용하여 구현한
outlines라이브러리의 블로그를 참고해주세요.
이 방식은 프롬프트 분산을 줄이고 평가를 안정적으로 만들지만, 최근 연구에 따르면 구조화된 생성이 모델의 사전 확률 분포를 너무 멀리 이동시켜 추론 같은 일부 작업에서 성능을 저하시킬 수 있음을 보여줍니다.
- Outlines 동작 방식에 대한 학술적 논문 (영문)
- 인터리브 생성(Interleaved generation) (영문): JSON 생성 등을 위한 또 다른 방법.
평가 시 간과되는 요소들
통계적 타당성
평가 결과를 보고할 때는 점 추정치(Point estimates)와 함께 신뢰 구간(Confidence intervals) 을 포함하는 것이 중요합니다. 이 때, 원시 점수(Raw scores)로부터 신뢰 구간을 얻는 방법은 다음과 같습니다.
- 점수의 표준 편차를 사용하거나 부트스트래핑(Bootstrapping)을 사용할 수 있습니다.
- 자동화된 지표의 경우 이는 비교적 사소한(trivial) 문제입니다.
- 모델 평가자(Model judges)의 경우, 최근 논문에서 추정량(Estimator)을 사용한 편향 보정을 제안했습니다.
- 인간 기반 평가의 경우, 평가자 간 일치도(Agreement)를 보고해야 합니다.
또한, 동일한 질문을 약간 다르게 하거나, 동일한 샘플에 대해 다른 프롬프트 형식을 사용하여 재실행하는 등 프롬프트 변형(Prompt variations)을 통해서도 이러한 수치를 계산할 수 있습니다.
비용과 효율성
평가 결과를 설계하고 보고할 때, 우리는 모델 실행 비용에 대한 결과를 함께 보고하기 시작해야 합니다! 10 + 1을 계산하기 위해 10분의 생각 시간과 10,000 토큰을 소모하는(이진법 대 십진법 산술에 대한 전체적인 잡담을 늘어놓느라) 추론 모델은, 단 몇 개의 토큰으로 30초 만에 답하는 작은(smol) 모델보다 효율성이 상당히 떨어집니다.

{kind=link}
따라서, 다음 사항들을 포함하여 공유(report)하는 것이 필요합니다:
-
토큰 소비량(Token consumption): 평가 중 사용된 총 출력 토큰 수를 함께 정리하여 공유(report)하세요. 이는 효율성(efficiency) 을 추정하는 데 특히 중요하며, 모델을 평가자로 사용할 때의 비용에도 영향을 미칩니다. 토큰 수는 금전적 비용에 직접적인 영향을 주며, 타인이 필요한 컴퓨팅 요구 사항을 추정하는 데 도움을 줍니다. 금전적 비용(Monetary cost) 또한 효율성을 나타내는 좋은 대리 지표가 될 수 있습니다.
-
시간(Time): 모델이 평가를 완료하는 데 필요한 추론 시간 또한 함께 기록해야 합니다. 여기에는 실제 추론 시간뿐만 아니라 API 속도 제한으로 인한 오버헤드도 포함됩니다. 이는 시간에 민감한 애플리케이션(예: GAIA2와 같은 에이전트 도구 사용)에서 특히 중요합니다.
마지막으로, 지구의 자원 상태를 고려할 때 실행 중인 모델의 환경적 발자국(Environmental footprint)을 보고하는 것이 점점 더 중요해지고 있습니다. 여기에는 훈련 시의 탄소 배출량과 추론 시의 에너지 소비량이 포함되며, 이는 모델 크기, 하드웨어(알고 있는 경우), 생성된 토큰 수에 따라 달라집니다. 일부 소형 모델이나 양자화된 모델은 매우 흥미로운 '소비량 대비 성능 비율'을 보여줍니다.
마무리하며
평가는 예술이자 과학입니다. 이 글에서는 2025년의 LLM 평가 환경을 탐색해 보았습니다. 왜 모델을 평가하는지, 토큰화와 추론의 기본 메커니즘은 무엇인지부터 시작하여, 끊임없이 진화하는 벤치마크 생태계를 탐색하고, 마침내 여러분만의 사용 사례를 위한 평가를 만드는 방법까지 다루었습니다. 이제 여러분이 기억해주셨으면 하는 몇 가지 핵심 사항을 정리해보겠습니다.
무엇을 측정하고 있는지 비판적으로 생각하세요. 평가는 능력(Capabilities)에 대한 대리 지표일 뿐이므로, 벤치마크에서 높은 점수를 받았다고 해서 실제 성능을 보장하는 것은 아닙니다. 다양한 평가 접근 방식(자동 지표, 인간 평가자, 모델 평가자)은 각각 고유한 편향, 한계, 그리고 트레이드오프(Trade-offs)를 가지고 있습니다.
평가를 목표에 맞추세요. 훈련 중 제거 분석(Ablations)을 수행 중이신가요? 작은 모델에서도 강력한 신호를 주는 빠르고 신뢰할 수 있는 벤치마크를 사용하세요. 최종 선택을 위해 모델을 비교 중이신가요? 전체적인 능력을 테스트하는 더 어렵고 오염되지 않은(Uncontaminated) 데이터셋에 집중하세요. 특정 사용 사례를 위해 구축 중이신가요? 여러분의 문제와 데이터를 반영하는 맞춤형 평가를 만드세요.
재현성(Reproducibility)은 디테일에 대한 주의를 요구합니다. 프롬프트, 토큰화, 정규화, 템플릿 또는 랜덤 시드(Random seeds)의 작은 차이가 점수를 몇 점씩 흔들 수 있습니다. 결과를 보고할 때는 방법론에 대해 투명해야 합니다. 결과를 재현하려고 할 때, 모든 변수를 통제하려 시도하더라도 정확한 복제는 매우 어려울 것임을 예상해야 합니다.
해석 가능한 평가 방법을 선호하세요. 가능하다면 모델 평가자보다는 기능 테스트(Functional testing)와 규칙 기반 검증기(Rule-based verifiers)를 선택해야 합니다. 이해할 수 있고 디버깅할 수 있는 평가는 더 명확하고 실질적인 통찰력을 제공하며, 평가가 해석 가능할수록 모델을 더 잘 개선할 수 있습니다!
평가는 결코 끝나지 않습니다. 모델이 개선되면 벤치마크는 포화 상태가 됩니다. 훈련 데이터가 늘어나면 오염 가능성이 커집니다. 사용 사례가 진화하면 새로운 능력을 측정해야 합니다. 평가는 계속되는 전투와 같습니다!
정리하자면, 우리가 만드는 모델은 중요한 것을 측정하는 우리의 능력만큼만 좋아질 수 있습니다. 읽어주셔서 감사합니다!
The LLM Evaluation Guidebook 원문 블로그
 The LLM Evaluation Guidebook 원문 PDF 다운로드
The LLM Evaluation Guidebook 원문 PDF 다운로드
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()