
Tokasaurus 소개
Stanford Scaling Intelligence Lab에서 공개한 Tokasaurus는 최근 다양한 AI 모델 추론 엔진 중에서도 특히 고처리량(throughput)에 초점을 맞춘 혁신적인 프로젝트입니다. 일반적인 챗봇 서비스보다는 수천 개의 요청을 동시에 처리해야 하는 배치 중심 워크로드(batch inference)에 특화되어 있으며, 기존의 대표적인 추론 엔진인 vLLM이나 SGLang보다 2~3배 향상된 처리 성능을 기록한 바 있습니다. 특히, 샘플링 중심 파이프라인을 구축 중이거나, 합성 데이터 생성, LLM 평가 자동화 등에서 성능 병목을 해결하는데 유용합니다.

Tokasaurus는 오픈소스로 공개된 PyTorch 기반의 LLM 추론 엔진으로, 핵심 목적은 높은 처리량을 요구하는 대규모 배치 작업을 효율적으로 수행하는 것입니다. 이 엔진은 OpenAI API와 완전히 호환되는 REST 인터페이스를 제공하며, LLaMA-3 및 Qwen-2 계열 모델 등 다양한 사전 학습 모델을 손쉽게 실행할 수 있도록 구성되어 있습니다. 특히 기존 vLLM이나 SGLang과 같은 인기 추론 프레임워크들과 비교했을 때, Tokasaurus는 실행 효율성, 자원 활용도, 처리량 최적화 측면에서 뚜렷한 차별성을 보입니다.
이 프로젝트가 특히 주목받는 이유는 실행 중 자동으로 입력 시퀀스 간 prefix를 공유하여 attention 계산을 최적화하는 ‘Hydragen’ 기술과, torch.compile 및 CUDA Graphs를 활용한 엔드 투 엔드(End-to-End) 컴파일 기반 추론 최적화 덕분입니다. 여기에 더해, GPU 하드웨어 구성에 따라 적절한 병렬 전략을 선택 적용할 수 있도록 설계되었기 때문에, 다양한 하드웨어 환경에서도 최적의 성능을 달성할 수 있는 유연성을 제공합니다.
Tokasaurus 구조 및 내부 디자인
Tokasaurus는 크게 세 가지 핵심 컴포넌트로 구성됩니다. 먼저, OpenAI API 규격을 따르는 웹 서버가 있으며, 이를 통해 chat/completions/batch 요청을 받을 수 있습니다. API 요청은 중앙 매니저 프로세스로 전달되며, 이 매니저는 입력 시퀀스를 분석하여 prefix 공유 그룹을 탐지하고, GPU input queue를 관리합니다. 또한 GPU에서 사용되는 KV cache를 효율적으로 구성하고 불필요한 연산을 생략하는 역할도 담당합니다.
모델 추론을 실제로 수행하는 컴포넌트는 모델 워커(worker)입니다. 이 워커는 각 GPU에 분산되어 있으며, 병렬화 구성에 따라 데이터 병렬(DP), 파이프라인 병렬(PP), 텐서 병렬(TP) 또는 비동기 텐서 병렬(Async TP) 방식으로 작동할 수 있습니다. NVLink가 없는 환경에서는 PP를 중심으로, NVLink가 지원되는 H100이나 A100 환경에서는 Async TP를 적극 활용하는 방식으로 처리 전략을 조정할 수 있습니다.
핵심 최적화 기법
Tokasaurus의 가장 큰 기술적 특징은 prefix 공유 최적화 기능인 Hydragen입니다. 이는 여러 입력 시퀀스 간에 공통된 prefix를 자동으로 탐지하고, 이를 기반으로 attention 연산을 공유 처리하여 연산량을 줄이는 방식입니다. 일반적으로 LLM에서 attention 계산은 계산량이 많고 메모리 소모가 큰데, Hydragen을 통해 이 부분의 효율성을 극대화할 수 있습니다.
두 번째 핵심 기술은 torch.compile과 CUDA 그래프를 통한 모델 추론 최적화입니다. PyTorch 2.x 이후 지원되는 torch.compile 기능은 기존의 eager 모드 대비 GPU 성능을 보다 정적으로 사용할 수 있도록 해주며, CUDA 그래프와 조합할 경우 GPU 메모리 복사 및 커널 실행을 매우 효율적으로 구성할 수 있습니다. Tokasaurus는 초기 warm-up 동안 torch 컴파일과 메모리 사전 탐색을 수행한 후, 본격적인 추론 루프에서는 재컴파일 없이 빠르게 처리할 수 있습니다.
또한 GPU input queue의 깊이를 지속적으로 감시하며 불필요한 연산을 줄이는 비동기 CPU 매니저가 존재하여 GPU가 underutilization 상태에 빠지지 않도록 조정해줍니다. 이런 CPU-GPU 간 스케줄링 최적화 덕분에 작은 모델에서도 높은 처리량을 유지할 수 있습니다.
설치 및 사용 방법
Tokasaurus는 PyPI를 통해 손쉽게 설치(pip install tokasaurus)할 수 있으며, GitHub 저장소를 복제하여 직접 설치하는 방법도 지원합니다. Python 3.10 이상 환경이 필요하며, LLaMA나 Qwen 모델을 사용하기 위해 HuggingFace Transformers 및 CUDA 환경도 미리 준비되어야 합니다.
설치 후에는 간단한 CLI 명령으로 모델을 실행할 수 있습니다. 예를 들어, 단일 GPU에서 LLaMA-3 1B 모델을 실행하려면 toka model=meta-llama/Llama-3.2-1B-Instruct 명령을 사용할 수 있습니다. 테스트용으로는 toka-ping prompt='tell me a joke' max_tokens=256 chat=True를 통해 chat endpoint의 동작을 확인할 수 있습니다.
여러 GPU를 사용하는 경우에는 파이프라인 병렬화를 적용할 수 있으며, 예를 들어 LLaMA-3 70B 모델을 8 GPU로 실행하려면 pp_size=8과 함께 KV cache 크기 조정 옵션을 추가하여 실행할 수 있습니다. API 클라이언트는 OpenAI의 Python SDK와 호환되므로 기존 코드를 쉽게 재사용할 수 있습니다.
성능 및 벤치마크
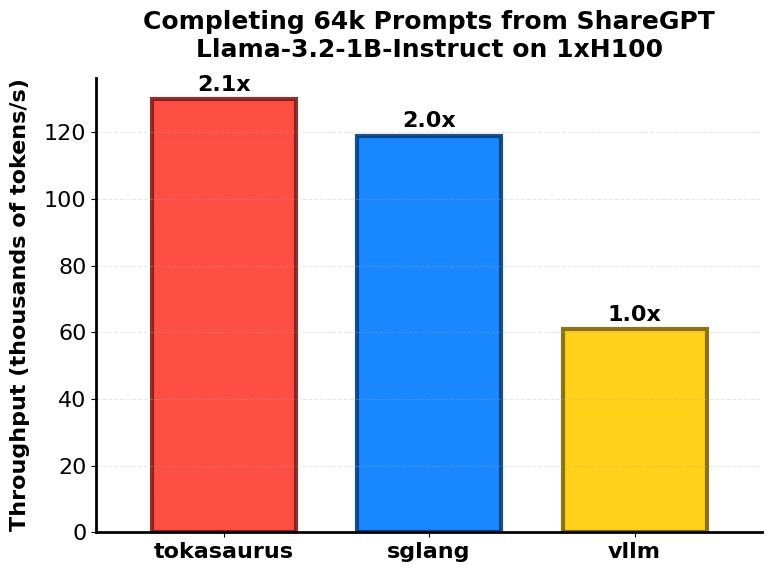
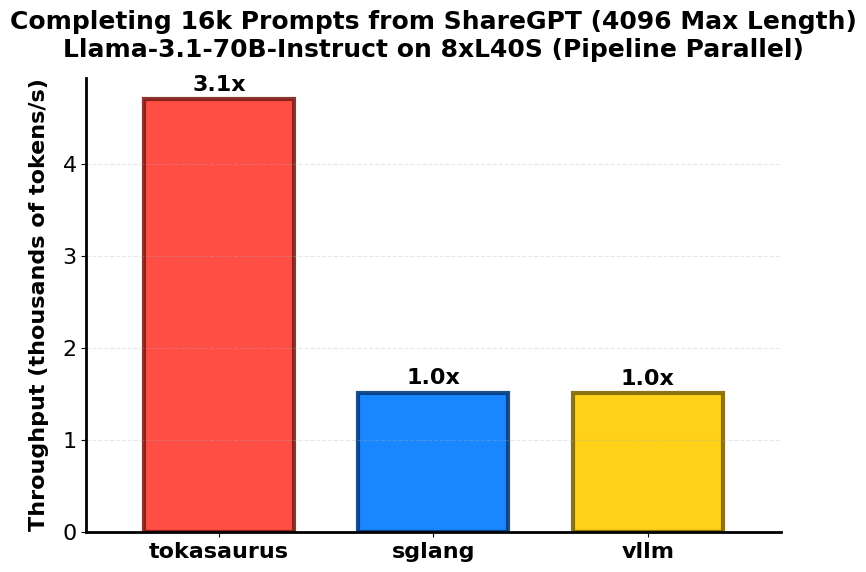
Tokasaurus 프로젝트는 다양한 벤치마크 테스트에서 기존의 추론 엔진들보다 우수한 성능을 보였습니다. 대표적으로 GSM8K 데이터셋을 기반으로 1,024개의 샘플을 샘플링한 결과, vLLM 대비 두 배 이상의 처리량을 기록했습니다. 또한 LLaMA-3 70B 모델을 L40S GPU 8장 구성으로 파이프라인 병렬 처리한 환경에서는 기존 구조보다 세 배 향상된 처리 속도를 달성했습니다.
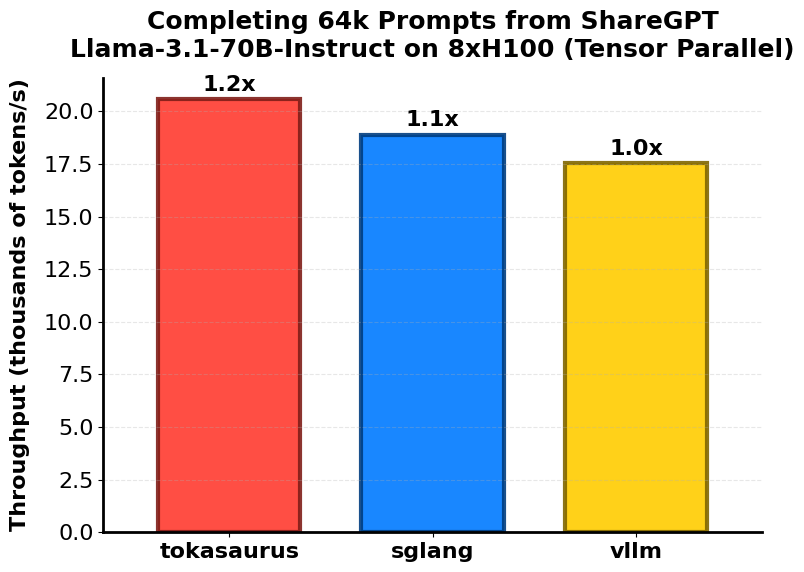
특히 NVLink 기반의 환경에서 Async-TP를 활용할 경우, 6k 이상의 토큰을 포함한 대형 배치에서도 병목 없이 빠른 처리 속도를 유지할 수 있으며, 이는 실시간 응답보다 수천 건의 질문을 일괄 처리해야 하는 평가/샘플링/합성 데이터 워크로드에서 매우 유리합니다.
벤치마크를 재현하기 위한 명령어는 GitHub 저장소의 관련 문서를 확인해주세요.
라이선스
Tokasaurus 프로젝트는 Apache-2.0 라이선스를 따르며, 상업적 용도 포함 자유로운 사용과 수정, 재배포가 가능합니다.
 Tokasaurus 공식 블로그
Tokasaurus 공식 블로그
 Tokasaurus 프로젝트 GitHub 저장소
Tokasaurus 프로젝트 GitHub 저장소
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()