Tokenflood 소개
Tokenflood는 대규모 언어 모델(LLM)을 위해 설계된 전문 부하 테스트(Load Testing)를 위한 프레임워크입니다. 개발자와 엔지니어가 실제 프롬프트 데이터셋 없이도 원하는 부하 프로필을 정의하여 LLM 엔드포인트의 성능과 안정성을 테스트할 수 있도록 돕는 도구입니다.
LLM 애플리케이션은 일반적인 웹 서비스와 달리, 요청 처리 비용보다 응답 생성(토큰 생성) 비용이 훨씬 높다는 특징이 있습니다. 단순히 초당 요청 수(RPS)만 측정하는 기존 부하 테스트 도구로는 LLM의 특성(긴 생성 시간, 막대한 연산 자원 소모)을 정확히 반영하기 어렵습니다. 또한, 악의적인 사용자가 적은 입력으로 긴 출력을 유도하여 자원을 고갈시키는 LLM DoS(서비스 거부) 공격이나 요금 폭탄(Denial of Wallet) 공격에 대한 방어책을 마련하기 위해, 사전에 이러한 시나리오를 시뮬레이션할 필요성이 커지고 있습니다.
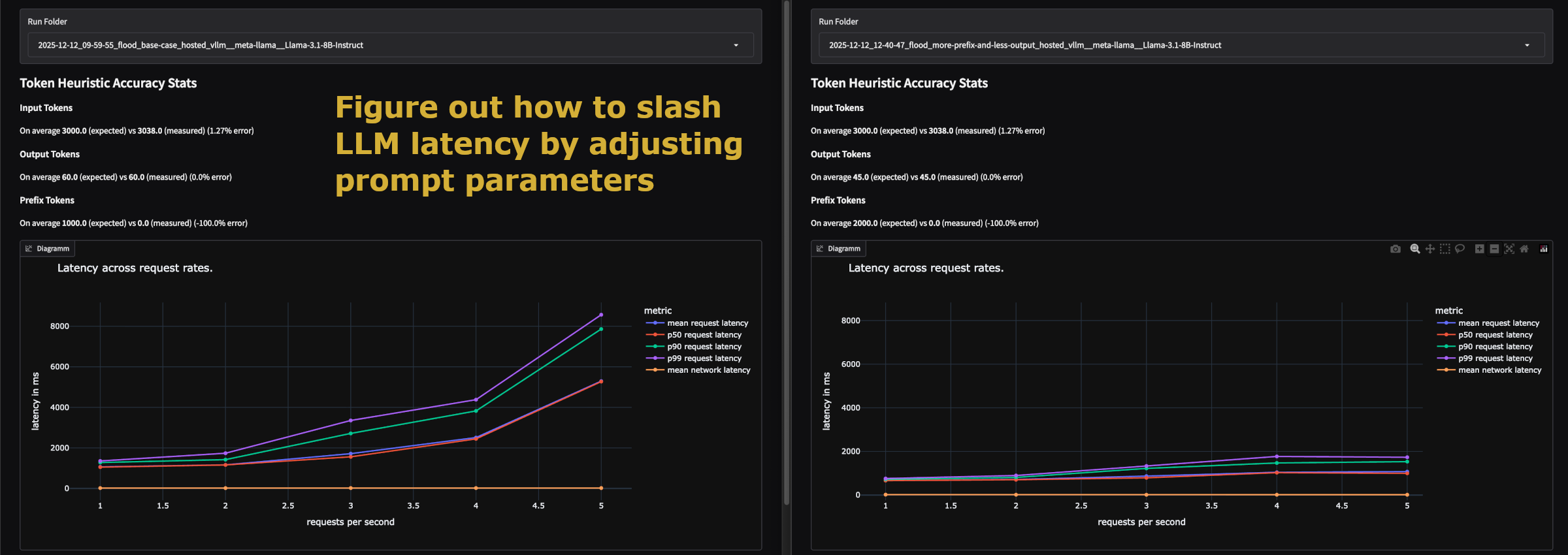
Tokenflood는 사용자가 지정한 프롬프트 길이, 출력 길이, 요청 빈도에 따라 가상의 워크로드를 생성합니다. 이를 통해 실제 사용자 데이터가 없더라도 다양한 트래픽 패턴(예: 갑작스러운 스파이크, 지속적인 고부하)을 시뮬레이션할 수 있습니다.
즉, Tokenflood는 도구는 단순히 서버를 다운시키는 것이 목적이 아니라, 다양한 공급자(OpenAI, Azure, vLLM 등) 및 하드웨어 설정에 따른 지연 시간(Latency) 변화 , 처리량(Throughput) , 그리고 비용 을 예측하는 데 최적화되어 있습니다. 프로덕션 배포 전, 시스템이 예상치 못한 트래픽 급증을 어떻게 처리하는지 검증하는 데 유용합니다.
Tokenflood와 기존의 웹 부하 테스트 도구와 비교
일반적인 HTTP 부하 테스트 도구(예: k6, JMeter, Locust)와 Tokenflood의 주요 차이점은 '토큰 생성'에 대한 인식 여부입니다.
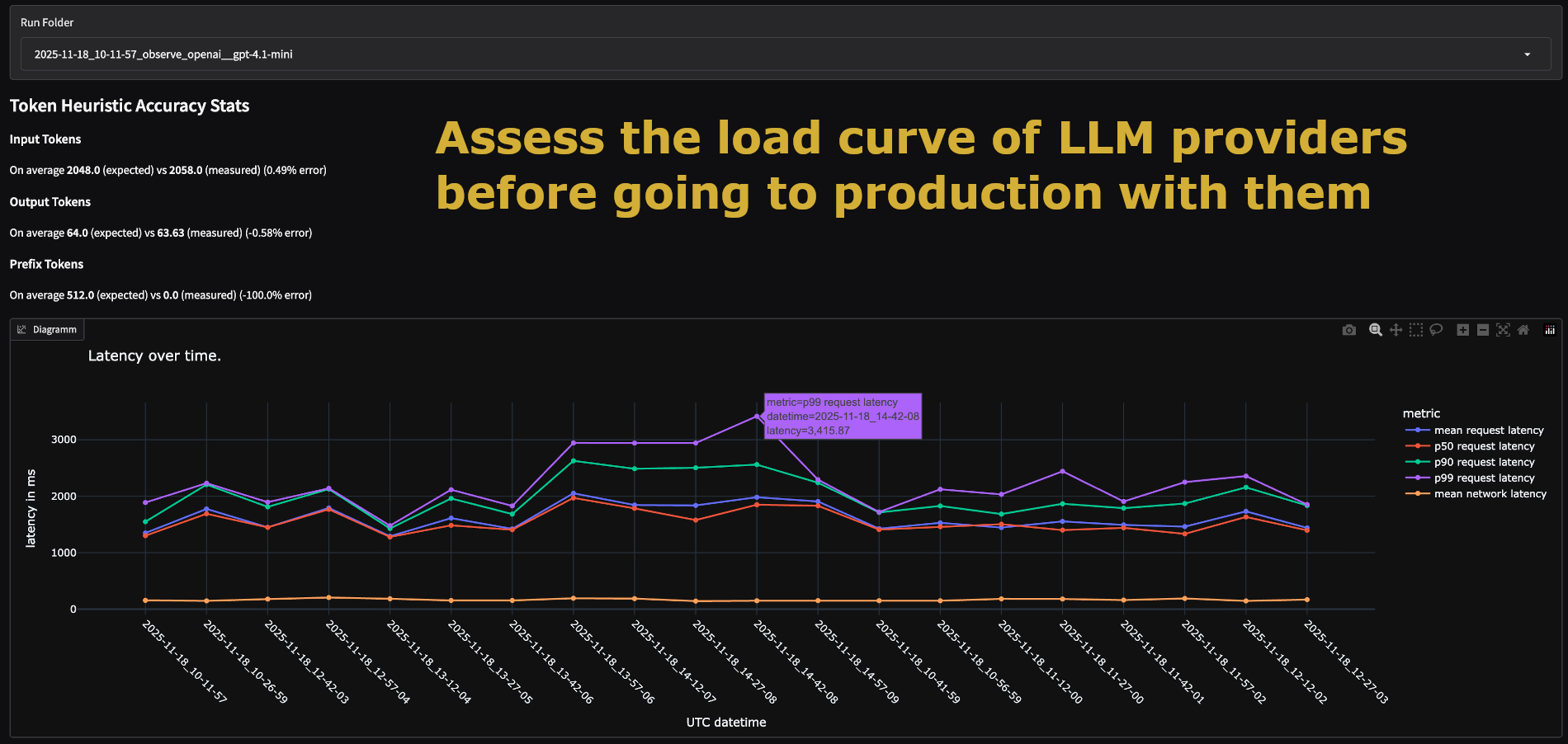
기존의 부하 테스트 도구들은 주로 네트워크 연결 수와 HTTP 요청의 성공/실패 여부에 집중합니다. 요청을 보내고 응답을 받는 시간(Round Trip Time)을 측정하지만, LLM 내부에서 벌어지는 '입력 토큰 처리'와 '출력 토큰 생성'의 부하 차이를 구분하지 못합니다.
이에 비해, Tokenflood는 LLM의 작동 방식에 맞춰 설계되었습니다. 사용자는 단순히 "요청 100개"가 아니라, 입력 500 토큰, 출력 1000 토큰을 생성하는 요청 100개와 같은 식으로 구체적인 연산 부하를 정의할 수 있습니다. 이를 통해 사용자는 TTFT(Time To First Token) 및 TPOT(Time Per Output Token) 등과 같은 LLM 특화 지표에 부하가 미치는 영향을 분석할 수 있습니다.
Tokenflood의 주요 기능
Tokenflood가 제공하는 주요 기능들은 다음과 같습니다:
-
데이터셋 없는 테스트 (No Dataset Required): 실제 사용자 대화 로그나 프롬프트 모음이 없어도 테스트가 가능합니다. Tokenflood는 설정된 길이의 토큰을 소비하고 생성하도록 유도하는 더미(Dummy) 작업을 자동으로 생성합니다.
-
광범위한 공급자 지원 (Provider Agnostic): Tokenfllod는 내부적으로
LiteLLM라이브러리를 사용하여 OpenAI, Azure, AWS Bedrock, Anthropic, Google Gemini, 그리고 자체 호스팅된 vLLM 등LiteLLM이 지원하는 거의 모든 공급자와 호환됩니다. -
휴리스틱 부하 테스트 (Heuristic Load Testing): 시스템에 가장 큰 부하를 주는 '비싼 프롬프트(Expensive Prompts)'를 자동으로 찾아내는 기능을 제공하여, 최악의 시나리오(Worst-case scenario)에 대한 방어력을 테스트할 수 있습니다.
-
관측 및 분석 (Observation Specs): 24시간 등, 장시간 동안 시스템을 모니터링하며 시간대별 지연 시간 변화를 추적할 수 있습니다. 예를 들어, "미국의 업무 시간이 시작되면 내가 사용하는 호스팅 모델의 응답 속도가 얼마나 느려지는가?"와 같은 특정 상황에서의 부하 변화를 파악할 수 있습니다.
Tokenflood 설치 및 설정
Tokenflood는 poetry나 pip와 같은 Python 패키지 관리자를 통해 쉽게 설치할 수 있습니다:
# Poetry 사용 시
poetry add tokenflood
# pip 사용 시
pip install tokenflood
실행을 위해서는 크게 두 가지 설정 파일이 필요합니다.
-
endpoint.yaml파일에서 API 키, 모델명, Base URL 등과 같은 테스트할 LLM 서버의 정보를 정의합니다. -
run_suite.yaml파일에는 동시 요청 수나 프롬프트 길이 등과 같이 수행할 테스트 시나리오를 정의합니다.
Tokenflood는 litellm 형식을 따르므로 다양한 공급자를 쉽게 설정할 수 있습니다.
예를 들어, 로컬에서 실행한 vLLM을 통해 실행되는 LLM을 가정하면, 다음과 같이 설정할 수 있습니다:
provider: hosted_vllm
model: meta-llama/Llama-3.1-8B-Instruct
base_url: http://127.0.0.1:8000/v1
또는, OpenAI를 사용하는 경우 다음과 같이 설정할 수 있습니다:
provider: openai
model: gpt-4o-mini
# 이 때, 환경 변수 OPENAI_API_KEY를 설정해야 합니다
Tokenflood를 사용한 테스트 실행 (Run Suites)
테스트 스위트(Run Suite)를 통해 부하의 강도와 기간을 설정합니다. 각 단계(Phase)별로 요청 속도(RPS)를 다르게 설정하여 점진적으로 부하를 높일 수 있습니다.
- 테스트 시나리오 구성 요소:
duration: 테스트 지속 시간rpm: 분당 요청 수 (Requests Per Minute)prompt_length: 입력 프롬프트 길이 (토큰 수)output_length: 생성할 응답 길이 (토큰 수)
주의: Claude Opus 4.5 등과 같은 유료 API를 대상으로 이 도구를 사용할 경우, 설정 실수로 인해 막대한 비용이 청구될 수 있습니다. 따라서 반드시 예산을 고려하여 테스트를 수행하고, 가급적 자체 호스팅 모델이나 비용 한도가 설정된 환경에서 테스트하는 것을 권장합니다.
라이선스
Tokenflood 프로젝트는 MIT License로 공개 및 배포되고 있습니다.
 Tokenflood 프로젝트 GitHub 저장소
Tokenflood 프로젝트 GitHub 저장소
https://github.com/twerkmeister/tokenflood
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()