<p><strong>요약</strong>: PyTorch 2.0 nightly 버전은 새로운 <code>torch.compile()</code> 컴파일러를 사용하여 생성적 디퓨전 모델의 성능을 즉시 개선하고 PyTorch 2와 통합된 멀티헤드 어텐션의 최적화된 구현을 제공합니다.</p>
TL;DR: PyTorch 2.0 nightly offers out-of-the-box performance improvement for Generative Diffusion models by using the new
torch.compile()compiler and optimized implementations of Multihead Attention integrated with PyTorch 2.
소개 / Introduction
최근 생성형 AI의 발전의 대부분은 텍스트 프롬프트에서 고품질 이미지와 동영상을 생성할 수 있는 노이즈 제거 디퓨전 모델에서 비롯되었습니다. 이 제품군에는 이미지, DALLE, 잠재 디퓨전 등이 포함됩니다. 그러나 이 제품군의 모든 모델은 공통적으로 이미지가 생성되는 샘플링 프로세스의 반복적인 특성으로 인해 생성 속도가 다소 느리다는 단점이 있습니다. 따라서 샘플링 루프 내부에서 실행되는 코드를 최적화하는 것이 중요합니다.
A large part of the recent progress in Generative AI came from denoising diffusion models, which allow producing high quality images and videos from text prompts. This family includes Imagen, DALLE, Latent Diffusion, and others. However, all models in this family share a common drawback: generation is rather slow, due to the iterative nature of the sampling process by which the images are produced. This makes it important to optimize the code running inside the sampling loop.
저희는 널리 사용되는 텍스트-이미지 디퓨전 모델의 오픈 소스 구현을 출발점으로 삼아 PyTorch 2에서 제공되는 두 가지 최적화, 즉 컴파일과 빠른 어텐션 구현을 사용하여 생성 속도를 높였습니다. 이러한 최적화는 코드의 약간의 메모리 처리 개선과 함께 GPU 아키텍처와 배치 크기에 따라 xFormers를 사용하지 않은 원래 구현에 비해 추론 속도를 최대 49%, xFormers를 사용한 원래 코드(컴파일 시간 제외)에 비해 39%까지 향상시켰습니다. 중요한 점은 이러한 속도 향상은 xFormers나 다른 추가 종속 요소를 설치하지 않고도 얻을 수 있다는 것입니다.
We took an open source implementation of a popular text-to-image diffusion model as a starting point and accelerated its generation using two optimizations available in PyTorch 2: compilation and fast attention implementation. Together with a few minor memory processing improvements in the code these optimizations give up to 49% inference speedup relative to the original implementation without xFormers, and 39% inference speedup relative to using the original code with xFormers (excluding the compilation time), depending on the GPU architecture and batch size. Importantly, the speedup comes without a need to install xFormers or any other extra dependencies.
아래 표는 xFormers를 설치한 원래 구현과 파이토치 통합 메모리 효율 어텐션(원래 xFormers 라이브러리용으로 개발되어 출시됨) 및 파이토치 컴파일이 포함된 최적화된 버전 간의 실행 시간 개선 효과를 보여줍니다. 컴파일 시간은 제외되었습니다.
The table below shows the improvement in runtime between the original implementation with xFormers installed and our optimized version with PyTorch-integrated memory efficient attention (originally developed for and released in the xFormers library) and PyTorch compilation. The compilation time is excluded.
실행 시간 개선율(%), 오리지널+xFormers 대비 / Runtime improvement in % compared to original+xFormers
절대 수치는 “벤치마킹 설정 및 결과 요약” 섹션에서 확인하세요.
See the absolute runtime numbers in section “Benchmarking setup and results summary”
GPU
Batch size 1
Batch size 2
Batch size 4
P100 (no compilation)
-3.8
0.44
5.47
T4
2.12
10.51
14.2
A10
-2.34
8.99
10.57
V100
18.63
6.39
10.43
A100
38.5
20.33
12.17
다음 사항을 확인할 수 있습니다:
- A100 및 V100과 같은 강력한 GPU에 대한 개선이 두드러집니다. 이러한 GPU의 경우 배치 크기 1에서 개선이 가장 두드러집니다.
- 성능이 낮은 GPU의 경우 속도가 더 적게 향상되거나 두 경우 모두 약간 후퇴하는 것을 관찰할 수 있습니다. 배치 크기 추세가 역전되어 배치 크기가 클수록 개선 효과가 더 큽니다.
One can notice the following:
- The improvements are significant for powerful GPUs like A100 and V100. For those GPUs the improvement is most pronounced for batch size 1
- For less powerful GPUs we observe smaller speedups (or in two cases slight regressions). The batch size trend is reversed here: improvement is larger for larger batches
다음 섹션에서는 적용된 최적화에 대해 설명하고 다양한 최적화 기능을 켜고 껐을 때의 생성 시간을 비교하는 자세한 벤치마킹 데이터를 제공합니다.
In the following sections we describe the applied optimizations and provide detailed benchmarking data, comparing the generation time with various optimization features on/off.
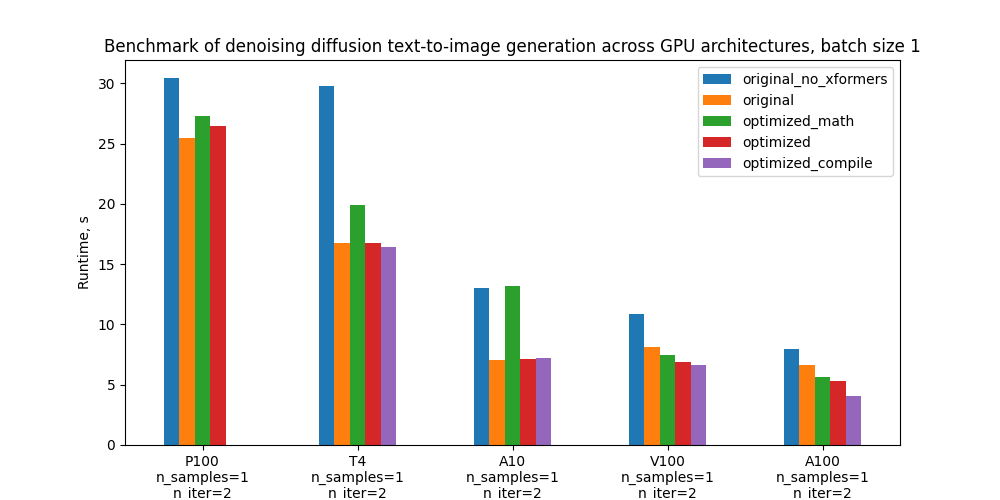
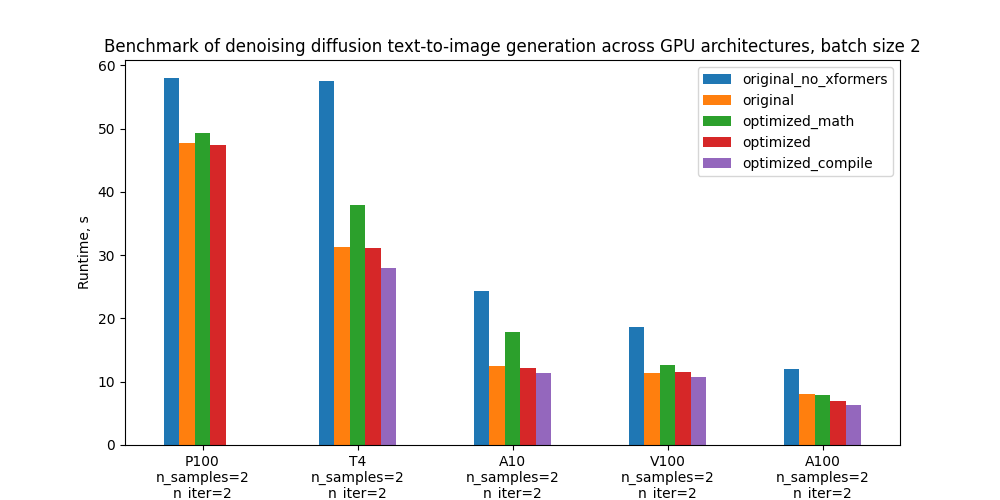
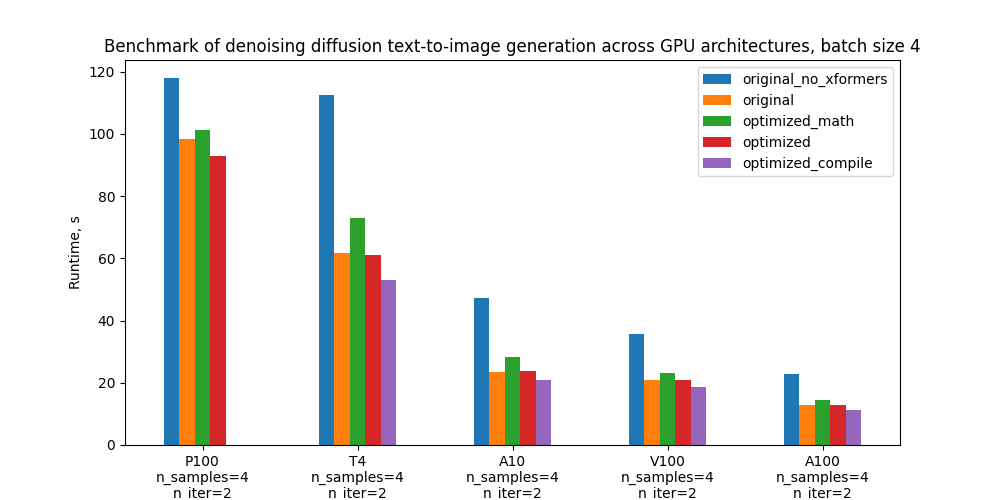
특히 5가지 구성을 벤치마킹하고 아래 도표는 다양한 GPU 및 배치 크기에 따른 절대 성능을 비교합니다. 이러한 구성에 대한 정의는 “벤치마킹 설정 및 결과” 섹션을 참조하세요.
Specifically, we benchmark 5 configurations and the plots below compare their absolute performance for different GPUs and batch sizes. For definitions of these configurations see section “Benchmarking setup and results”.
최적화 / Optimizations
여기서는 모델 코드에 도입된 최적화에 대해 자세히 살펴보겠습니다. 이러한 최적화는 최근에 출시된 PyTorch 2.0의 기능에 의존합니다.
Here we’ll go into more detail about the optimizations introduced into the model code. These optimizations rely on features of PyTorch 2.0 which has been released recently.
최적화된 어텐션 / Optimized Attention
코드에서 최적화한 부분 중 하나는 스케일링된 dot-product 어텐션입니다. 어텐션은 무거운 연산으로 알려져 있습니다. 나이브(naive)한 구현은 어텐션 행렬을 구체화하기 때문에 시퀀스 길이에 따라 시간과 메모리 복잡성이 이차적으로 증가합니다. 디퓨전 모델에서는 어텐션(CrossAttention)를 U-Net의 여러 부분에서 트랜스포머 블록의 일부로 사용하는 것이 일반적입니다. U-Net은 모든 샘플링 단계에서 실행되므로 이 부분이 최적화해야 할 중요한 지점이 됩니다. 커스텀 어텐션 구현 대신 파이토치 2에서는 최적화된 어텐션 구현이 통합되어 있는 torch.nn.MultiheadAttention을 사용할 수 있습니다. 이 최적화는 다음과 같은 의사 코드로 요약됩니다:
One part of the code which we optimized is the scaled dot-product attention. Attention is known to be a heavy operation: naive implementation materializes the attention matrix, leading to time and memory complexity quadratic in sequence length. It is common for diffusion models to use attention (
CrossAttention) as part of Transformer blocks in multiple parts of the U-Net. Since the U-Net runs at every sampling step, this becomes a critical point to optimize. Instead of custom attention implementation one can usetorch.nn.MultiheadAttention,which in PyTorch 2 has optimized attention implementation is integrated into it. This optimization schematically boils down to the following pseudocode:
class CrossAttention(nn.Module):
def __init__(self, ...):
# 행렬을 생성합니다: Q, K, V, out_proj
# Create matrices: Q, K, V, out_proj
...
def forward(self, x, context=None, mask=None):
# Compute out = SoftMax(Q*K/sqrt(d))V
# out_proj(out) 반환
# Return out_proj(out)
…
위 코드는 아래 코드로 대체됩니다
gets replaced with
class CrossAttention(nn.Module):
def __init__(self, ...):
self.mha = nn.MultiheadAttention(...)
def forward(self, x, context):
return self.mha(x, context, context)
어텐션의 최적화된 구현은 이미 파이토치 1.13부터 사용할 수 있었고(여기 참조), 널리 채택되었습니다(예: HuggingFace Transformer 라이브러리 예제 참조). 특히, xFormers의 메모리-효율적인(memory-efficient) 어텐션과 https://arxiv.org/abs/2205.14135 의 플래시(flash) 어텐션이 통합되어 있습니다. PyTorch 2.0은 이를 크로스 어텐션과 커스텀 커널과 같은 추가 어텐션 기능으로 확장하여 디퓨전 모델에 적용할 수 있도록 가속을 강화했습니다.
The optimized implementation of attention was available already in PyTorch 1.13 (see here) and widely adopted (see e.g. HuggingFace transformers library example). In particular, it integrates memory-efficient attention from the xFormers library and flash attention from https://arxiv.org/abs/2205.14135. PyTorch 2.0 expands this to additional attention functions such as cross attention and custom kernels for further acceleration, making it applicable to diffusion models.
플래시 어텐션은 컴퓨팅 성능이 SM 7.5 또는 SM 8.x인 GPU(예: 벤치마크에 포함된 T4, A10 및 A100)에서 사용할 수 있습니다(각 NVIDIA GPU의 컴퓨팅 성능은 여기에서 확인할 수 있습니다). 그러나 A100에 대한 테스트에서는 어텐션 헤드 수가 적고 배치 크기가 작기 때문에 특정 디퓨전 모델의 경우 메모리 효율적인 어텐션가 플래시 어텐션보다 더 나은 성능을 보였습니다. PyTorch는 이를 이해하고 있으며, 이 경우 두 가지 모두 사용 가능한 경우 플래시 어텐션보다 메모리 효율적인 어텐션을 선택합니다(여기의 로직 참조). 메모리 효율적인 어텐션, 플래시 어텐션, “순수한 수학” 또는 향후 어텐션 백엔드에 대한 완전한 제어를 위해 파워 유저는 컨텍스트 관리자 torch.backends.cuda.sdp_kernel를 사용하여 수동으로 활성화 및 비활성화할 수 있습니다.
Flash attention is available on GPUs with compute capability SM 7.5 or SM 8.x - for example, on T4, A10, and A100, which are included in our benchmark (you can check compute capability of each NVIDIA GPU here). However, in our tests on A100 the memory efficient attention performed better than flash attention for the particular case of diffusion models, due to the small number of attention heads and small batch size. PyTorch understands this and in this case chooses memory efficient attention over flash attention when both are available (see the logic here). For full control over the attention backends (memory-efficient attention, flash attention, “vanilla math”, or any future ones), power users can enable and disable them manually with the help of the context manager torch.backends.cuda.sdp_kernel.
컴파일 / Compilation
컴파일은 파이토치 2.0의 새로운 기능으로, 매우 간단한 사용자 경험으로 속도를 크게 높일 수 있습니다. 기본 동작을 호출하려면 파이토치 모듈이나 함수를 torch.compile로 래핑하기만 하면 됩니다:
Compilation is a new feature of PyTorch 2.0, enabling significant speedups with a very simple user experience. To invoke the default behavior, simply wrap a PyTorch module or a function into
torch.compile:
model = torch.compile(model)
그러면 PyTorch 컴파일러는 파이썬 코드를 파이썬 오버헤드 없이 효율적으로 실행할 수 있는 명령어 집합으로 변환합니다. 컴파일은 코드가 처음 실행될 때 동적으로 이루어집니다. 기본 동작으로 PyTorch는 내부적으로 TorchDynamo를 사용하여 코드를 컴파일하고 TorchInductor를 사용하여 코드를 더욱 최적화합니다. 자세한 내용은 이 튜토리얼을 참조하세요.
PyTorch compiler then turns Python code into a set of instructions which can be executed efficiently without Python overhead. The compilation happens dynamically the first time the code is executed. With the default behavior, under the hood PyTorch utilized TorchDynamo to compile the code and TorchInductor to further optimize it. See this tutorial for more details.
위의 한 줄짜리 컴파일도 충분하지만, 코드의 특정 부분을 수정하면 속도를 더 빠르게 할 수 있습니다. 특히 코드에서 파이토치가 컴파일할 수 없는 부분, 즉 소위 그래프 중단(graph break)을 피해야 합니다. 이전 PyTorch 컴파일 접근 방식(예: TorchScript)과는 달리, PyTorch 2 컴파일러는 이 경우 중단되지 않습니다. 대신 코드가 실행되기는 하지만 성능이 저하됩니다. 그래프 중단을 없애기 위해 모델 코드에 몇 가지 사소한 변경 사항을 도입했습니다. 여기에는 컴파일러에서 지원되지 않는 라이브러리(예: inspect.isfunction 및 einops.rearrange)에서 함수를 제거하는 작업이 포함되었습니다. 그래프 나누기와 그래프 나누기를 제거하는 방법에 대해 자세히 알아보려면 이 문서를 참조하세요.
Although the one-liner above is enough for compilation, certain modifications in the code can squeeze a larger speedup. In particular, one should avoid so-called graph breaks - places in the code which PyTorch can’t compile. As opposed to previous PyTorch compilation approaches (like TorchScript), PyTorch 2 compiler doesn’t break in this case. Instead it falls back on eager execution - so the code runs, but with reduced performance. We introduced a few minor changes to the model code to get rid of graph breaks. This included eliminating functions from libraries not supported by the compiler, such as
inspect.isfunctionandeinops.rearrange. See this doc to learn more about graph breaks and how to eliminate them.
이론적으로는 전체 디퓨전 샘플링 루프에 torch.compile을 적용할 수 있습니다. 그러나 실제로는 U-Net만을 컴파일하는 것으로도 충분합니다. 그 이유는 torch.compile에는 아직 루프 분석기가 없기 때문에 샘플링 루프의 각 반복에 대해 코드를 다시 컴파일해야 하기 때문입니다. 또한 컴파일된 샘플러 코드는 그래프가 끊어질 수 있으므로 컴파일된 버전에서 좋은 성능을 얻으려면 이를 조정해야 합니다.
Theoretically, one can apply
torch.compileon the whole diffusion sampling loop. However, in practice it is enough to just compile the U-Net. The reason is thattorch.compiledoesn’t yet have a loop analyzer and would recompile the code for each iteration of the sampling loop. Moreover, compiled sampler code is likely to generate graph breaks - so one would need to adjust it if one wants to get a good performance from the compiled version.
컴파일을 non-eager 모드에서 실행하려면 GPU 컴퓨팅 성능이 SM 7.0 이상이어야 합니다. 이는 P100을 제외한 벤치마크의 모든 GPU(T4, V100, A10, A100)에 적용됩니다(전체 목록 참조).
Note that compilation requires GPU compute capability >= SM 7.0 to run in non-eager mode. This covers all GPUs in our benchmarks - T4, V100, A10, A100 - except for P100 (see the full list).
기타 최적화 / Other optimizations
또한 CPU에서 텐서를 생성한 후 나중에 GPU로 이동하는 대신 GPU에서 직접 텐서를 생성하는 등 몇 가지 일반적인 함정을 제거하여 GPU 메모리 작업의 효율성을 개선했습니다. 이러한 최적화가 필요한 부분은 라인 프로파일링과 CPU/GPU 트레이스 및 플레임 그래프(Flame Graph)를 살펴봄으로써 결정했습니다.
In addition, we have improved efficiency of GPU memory operations by eliminating some common pitfalls, e.g. creating a tensor on GPU directly rather than creating it on CPU and later moving to GPU. The places where such optimizations were necessary were determined by line-profiling and looking at CPU/GPU traces and Flame Graphs.
벤치마킹 설정 및 결과 요약 / Benchmarking setup and results summary
이제 원본(original)과 최적화된(optimized) 코드 2가지 버전을 비교해보겠습니다. 이 외에도 여러 최적화 기능(xFormers, PyTorch memory efficient attention, compilation)을 켜고 끌 수 있습니다. 전반적으로 소개에서 언급했듯이 5가지 구성을 벤치마킹할 것입니다:
We have two versions of code to compare: original and optimized. On top of this, several optimization features (xFormers, PyTorch memory efficient attention, compilation) can be turned on/off. Overall, as mentioned in the introduction, we will be benchmarking 5 configurations:
- Original code without xFormers
- Original code with xFormers
- Optimized code with vanilla math attention backend and no compilation
- Optimized code with memory-efficient attention backend and no compilation
- Optimized code with memory-efficient attention backend and compilation
원본 버전(original version)은 PyTorch 1.12와 사용자 정의 어텐션 구현을 사용하는 코드 버전을 사용했습니다. 최적화된 버전(optimized version)은 CrossAttention의 nn.MultiheadAttention과 PyTorch 2.0.0.dev20230111+cu117 을 사용합니다. 또한 PyTorch 관련 코드에서 몇 가지 다른 사소한 최적화가 이루어졌습니다.
As the original version we took the version of the code which uses PyTorch 1.12 and a custom implementation of attention. The optimized version uses
nn.MultiheadAttentioninCrossAttentionand PyTorch 2.0.0.dev20230111+cu117. It also has a few other minor optimizations in PyTorch-related code.
아래 표는 각 버전의 코드 실행 시간(초)과 xFormers를 사용한 원본과 비교한 개선 비율을 보여줍니다. 컴파일 시간은 제외하였습니다.
The table below shows runtime of each version of the code in seconds, and the percentage improvement compared to the original with xFormers. The compilation time is excluded.
Runtimes for batch size 1. In parenthesis - relative improvement with respect to the “Original with xFormers” row
배치 크기 1일 때 실행 시간 / Runtimes for batch size 1. 괄호 안은 “xFormers를 사용한 원본” 행에 대한 상대적 개선도
Configuration
P100
T4
A10
V100
A100
Original without xFormers
30.4s (-19.3%)
29.8s (-77.3%)
13.0s (-83.9%)
10.9s (-33.1%)
8.0s (-19.3%)
Original with xFormers
25.5s (0.0%)
16.8s (0.0%)
7.1s (0.0%)
8.2s (0.0%)
6.7s (0.0%)
Optimized with vanilla math attention, no compilation
27.3s (-7.0%)
19.9s (-18.7%)
13.2s (-87.2%)
7.5s (8.7%)
5.7s (15.1%)
Optimized with mem. efficient attention, no compilation
26.5s (-3.8%)
16.8s (0.2%)
7.1s (-0.8%)
6.9s (16.0%)
5.3s (20.6%)
Optimized with mem. efficient attention and compilation
-
16.4s (2.1%)
7.2s (-2.3%)
6.6s (18.6%)
4.1s (38.5%)
배치 크기 2일 때 실행 시간 / Runtimes for batch size 2
Configuration
P100
T4
A10
V100
A100
Original without xFormers
58.0s (-21.6%)
57.6s (-84.0%)
24.4s (-95.2%)
18.6s (-63.0%)
12.0s (-50.6%)
Original with xFormers
47.7s (0.0%)
31.3s (0.0%)
12.5s (0.0%)
11.4s (0.0%)
8.0s (0.0%)
Optimized with vanilla math attention, no compilation
49.3s (-3.5%)
37.9s (-21.0%)
17.8s (-42.2%)
12.7s (-10.7%)
7.8s (1.8%)
Optimized with mem. efficient attention, no compilation
47.5s (0.4%)
31.2s (0.5%)
12.2s (2.6%)
11.5s (-0.7%)
7.0s (12.6%)
Optimized with mem. efficient attention and compilation
-
28.0s (10.5%)
11.4s (9.0%)
10.7s (6.4%)
6.4s (20.3%)
배치 크기 4일 때 실행 시간 / Runtimes for batch size 4
Configuration
P100
T4
A10
V100
A100
Original without xFormers
117.9s (-20.0%)
112.4s (-81.8%)
47.2s (-101.7%)
35.8s (-71.9%)
22.8s (-78.9%)
Original with xFormers
98.3s (0.0%)
61.8s (0.0%)
23.4s (0.0%)
20.8s (0.0%)
12.7s (0.0%)
Optimized with vanilla math attention, no compilation
101.1s (-2.9%)
73.0s (-18.0%)
28.3s (-21.0%)
23.3s (-11.9%)
14.5s (-13.9%)
Optimized with mem. efficient attention, no compilation
92.9s (5.5%)
61.1s (1.2%)
23.9s (-1.9%)
20.8s (-0.1%)
12.8s (-0.9%)
Optimized with mem. efficient attention and compilation
-
53.1s (14.2%)
20.9s (10.6%)
18.6s (10.4%)
11.2s (12.2%)
벤치마킹한 코드의 성능에 대한 변동과 외부 영향을 최소화하기 위해 각 버전의 코드를 차례로 실행한 다음 이 순서를 10회 반복했습니다: A, B, C, D, E, A, B, … 따라서 일반적인 실행 결과는 아래 그림과 같이 나타납니다. 서로 다른 그래프 간의 절대적인 실행 시간 비교에 의존해서는 안 되지만, 벤치마킹 설정 덕분에 한 그래프 내부의 실행 시간 비교는 꽤 신뢰할 수 있습니다.
To minimize fluctuations and external influence on the performance of the benchmarked code, we ran each version of the code one after another, and then repeated this sequence 10 times: A, B, C, D, E, A, B, … So the results of a typical run would look like the one in the picture below.. Note that one shouldn’t rely on comparison of absolute run times between different graphs, but comparison of run times inside one graph is pretty reliable, thanks to our benchmarking setup.
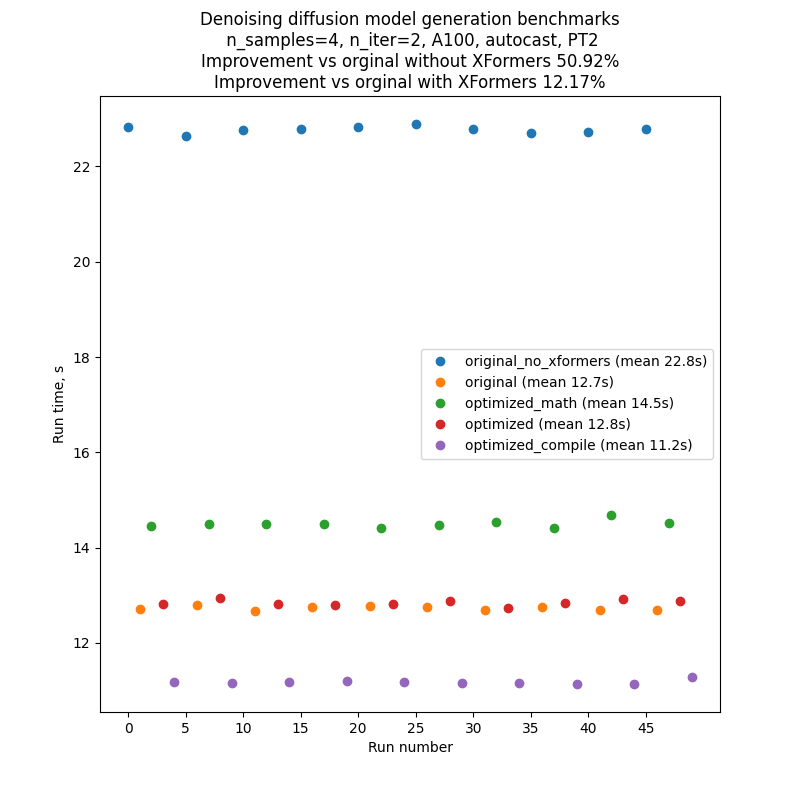
텍스트-이미지(text-to-image) 생성 스크립트를 실행할 때마다 여러 개의 배치가 생성되며, 그 수는 CLI 매개변수인 --n_iter에 의해 조절됩니다. 벤치마크에서는 n_iter = 2를 사용했지만 실행 시간에 영향을 주지 않는 추가 “워밍업” 반복을 도입했습니다. 코드가 처음 실행될 때 컴파일이 이루어지기 때문에 첫 번째 반복이 이후의 모든 반복보다 훨씬 길기 때문에 컴파일이 포함된 실행에 이 기능이 필요했습니다. 비교를 공정하게 하기 위해 다른 모든 실행에도 이 추가 “워밍업” 반복을 도입했습니다.
Each run of text-to-image generation script produces several batches, the number of which is regulated by the CLI parameter
--n_iter. In the benchmarks we usedn_iter = 2, but introduced an additional “warm-up” iteration, which doesn’t contribute to the run time. This was necessary for the runs with compilation, because compilation happens the first time the code runs, and so the first iteration is much longer than all subsequent. To make comparison fair, we also introduced this additional “warm-up” iteration to all other runs.
위 표의 숫자는 반복 횟수 2(‘워밍업 반복’ 추가), 프롬프트 ‘사진’, 시드 1, PLMS 샘플러 및 autocast가 켜진 상태입니다.
The numbers in the table above are for number of iterations 2 (plus a “warm-up one”), prompt ”A photo”, seed 1, PLMS sampler, and autocast turned on.
벤치마크는 P100, V100, A100, A10 및 T4 GPU를 사용하여 수행되었습니다. T4 벤치마크는 Google Colab Pro에서 수행되었습니다. A10 벤치마크는 GPU 1개가 장착된 g5.4xlarge AWS 인스턴스에서 수행되었습니다.
Benchmarks were done using P100, V100, A100, A10 and T4 GPUs. The T4 benchmarks were done in Google Colab Pro. The A10 benchmarks were done on g5.4xlarge AWS instances with 1 GPU.
결론 및 다음 단계 / Conclusions and next steps
파이토치 2의 새로운 기능인 컴파일러와 최적화된 어텐션 구현이 이전에는 외부 종속성(xFormers)을 설치해야 했던 것과 비슷하거나 그 이상의 성능 향상을 제공한다는 것을 보여주었습니다. 특히 파이토치는 메모리 효율이 뛰어난 xFormers의 어텐션 기능을 코드베이스에 통합함으로써 이를 달성했습니다. 최신 라이브러리인 xFormers는 많은 경우 사용자 정의 설치 프로세스와 긴 빌드가 필요하다는 점을 고려할 때 이는 사용자 경험을 크게 개선한 것입니다.
We have shown that new features of PyTorch 2 - compiler and optimized attention implementation - give performance improvements exceeding or comparable with what previously required installation of an external dependency (xFormers). PyTorch achieved this, in particular, by integrating memory efficient attention from xFormers into its codebase. This is a significant improvement for user experience, given that xFormers, being a state-of-the-art library, in many scenarios requires custom installation process and long builds.
이 작업을 계속 진행할 수 있는 몇 가지 자연스러운 방향이 있습니다:
There are a few natural directions in which this work can be continued:
- 여기서 구현하고 설명한 최적화는 지금까지 텍스트-이미지(text-to-image) 추론에 대해서만 벤치마킹한 것입니다. 이러한 최적화가 학습 성능에 어떤 영향을 미치는지 보는 것은 흥미로울 것입니다. PyTorch 컴파일을 학습에 직접 적용할 수 있으며, PyTorch에 최적화된 어텐션 학습을 가능하게 하는 것은 로드맵에 있습니다.
- 우리는 의도적으로 원본 모델 코드의 변경을 최소화했습니다. 추가 프로파일링과 최적화를 통해 더 많은 개선이 이루어질 수 있습니다.
- 현재 컴파일은 샘플러 내부의 U-Net 모델에만 적용되고 있습니다. 샘플링 루프에서 직접 연산과 같이 U-Net 외부에서 많은 일이 일어나기 때문에 전체 샘플러를 컴파일하는 것이 유리할 수 있습니다. 그러나 이를 위해서는 모든 샘플링 단계에서 재컴파일을 피하기 위해 컴파일 프로세스에 대한 분석이 필요합니다.
- 현재 코드는 PLMS 샘플러 내에서만 컴파일을 적용하지만 다른 샘플러로 확장하는 것은 간단해야 합니다.
- 디퓨전 모델은 텍스트로부터의 이미지(text-to-image) 생성 외에도 이미지와 이미지간(image-to-image) 및 인페인팅(inpainting)과 같은 다른 작업에도 적용할 수 있습니다. PyTorch 2 최적화를 통해 성능이 어떻게 향상되는지 측정하는 것은 흥미로울 것입니다.
- The optimizations we implemented and described here are only benchmarked for text-to-image inference so far. It would be interesting to see how they affect training performance. PyTorch compilation can be directly applied to training; enabling training with PyTorch optimized attention is on the roadmap
- We intentionally minimized changes to the original model code. Further profiling and optimization can probably bring more improvements
- At the moment compilation is applied only to the U-Net model inside the sampler. Since there is a lot happening outside of U-Net (e.g. operations directly in the sampling loop), it would be beneficial to compile the whole sampler. However, this would require analysis of the compilation process to avoid recompilation at every sampling step
- Current code only applies compilation within the PLMS sampler, but it should be trivial to extend it to other samplers
- Besides text-to-image generation, diffusion models are also applied to other tasks - image-to-image and inpainting. It would be interesting to measure how their performance improves from PyTorch 2 optimizations
설명한 방법을 사용하여 오픈 소스 디퓨전 모델의 성능을 향상시킬 수 있는지 확인하고 결과를 공유해주세요!
See if you can increase performance of open source diffusion models using the methods we described, and share the results!
리소스 / Resources
-
torch.compile에 대한 많은 정보가 있는 PyTorch 2.0 개요: https://pytorch.kr/get-started/pytorch-2.0 -
torch.compile에 대한 튜토리얼: https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html - 일반적인 컴파일 문제 해결: https://pytorch.org/docs/master/dynamo/troubleshooting.html
- 그래프 깨짐(graph break)에 대한 자세한 내용: https://pytorch.org/docs/master/dynamo/faq.html#identifying-the-cause-of-a-graph-break
- 가드(guard)에 대한 자세한 내용: https://pytorch.org/docs/master/dynamo/guards-overview.html
- TorchDynamo에 대한 비디오 심층 분석: https://www.youtube.com/watch?v=egZB5Uxki0I
- PyTorch 1.12의 최적화된 어텐션에 대한 튜토리얼: https://tutorials.pytorch.kr/beginner/bettertransformer_tutorial.html
- PyTorch 2.0 overview, which has a lot of information on
torch.compile:https://pytorch.org/get-started/pytorch-2.0/ - Tutorial on
torch.compile: https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html - General compilation troubleshooting: https://pytorch.org/docs/master/dynamo/troubleshooting.html
- Details on graph breaks: https://pytorch.org/docs/master/dynamo/faq.html#identifying-the-cause-of-a-graph-break
- Details on guards: https://pytorch.org/docs/master/dynamo/guards-overview.html
- Video deep dive on TorchDynamo https://www.youtube.com/watch?v=egZB5Uxki0I
- Tutorial on optimized attention in PyTorch 1.12: https://pytorch.org/tutorials/beginner/bettertransformer_tutorial.html
- PyTorch 2.0 overview, which has a lot of information on
감사의 말 / Acknowledgements
본문에 대한 귀중한 조언과 초기 피드백을 제공해 주신 Geeta Chauhan, Natalia Gimelshein, Patrick Labatut, Bert Maher, Mark Saroufim, Michael Voznesensky, Francisco Massa에게 감사의 말을 전합니다.
We would like to thank Geeta Chauhan, Natalia Gimelshein, Patrick Labatut, Bert Maher, Mark Saroufim, Michael Voznesensky and Francisco Massa for their valuable advice and early feedback on the text.
디퓨전 모델에서 PyTorch 네이티브 어텐션을 사용하는 작업을 시작한 Yudong Tao에게도 특별히 감사드립니다.
Special thanks to Yudong Tao initiating the work on using PyTorch native attention in diffusion models.
</div></div>
https://pytorch.kr/blog/2023/accelerated-generative-diffusion-models에 있는 원본 엔트리의 동반 토론 주제입니다.