resnet50 의 경우 224*224 를 image input으로 받는 것으로 알고 있는데,
모델을 제작하고 사용하다보니 448*448 이런식의 이미지도 resnet50에서 받던데 왜 그런걸까요?
그리고 transpose이용해서 resize 224한 것보다.. 448로 결과낸 것이 더 잘나오더라구요..
어디서부터 잘못된건지.. ㅠㅠ
resnet50 의 경우 224*224 를 image input으로 받는 것으로 알고 있는데,
모델을 제작하고 사용하다보니 448*448 이런식의 이미지도 resnet50에서 받던데 왜 그런걸까요?
그리고 transpose이용해서 resize 224한 것보다.. 448로 결과낸 것이 더 잘나오더라구요..
어디서부터 잘못된건지.. ㅠㅠ
안녕하세요.
resnet은 fully convolutional 구조의 feature extractor와 classifier(avg pooling, dense 레이어)로 이루어져있습니다.
torchvision의 resnet50 모델을 생성 후 출력해보시면 다음처럼 conv-bn-relu 구조 이후에 avg pool, dense 레이어가 존재합니다.
...
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=2048, out_features=1000, bias=True)
)
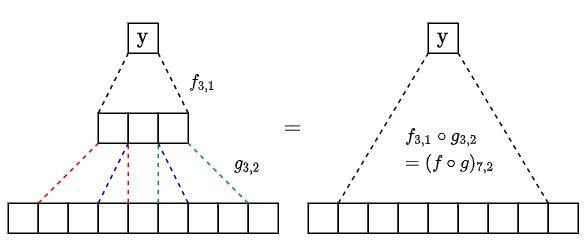
feature extractor는 모든 레이어가 conv, pooling 레이어인 fully convolutional 구조입니다. 모든 레이어가 conv, pooling 레이어라면 다음처럼 여러 층의 레이어가 하나의 레이어처럼 동작하는 것으로 생각할 수 있습니다.
(f_{i, j}, g_{i, j}: 커널 크기가 i, stride가 j 인 연산 (conv, pooling, ...))
따라서 resnet의 feature extractor는 하나의 conv 레이어처럼 입력 크기에 제한이 없고 출력 크기가 입력 크기에 비례하게 됩니다.
다음은 torcivision의 모델로 feature extractor를 생성하는 예제입니다.
(참고:pytorch.org)
import torch
from torchvision.models import resnet50
from torchvision.models.feature_extraction import get_graph_node_names
from torchvision.models.feature_extraction import create_feature_extractor
resnet = resnet50()
return_nodes = {'layer4': 'layer4'} # classifier 직전 블럭인 layer4 feature를 출력하도록 설정
feature_extractor = create_feature_extractor(resnet, return_nodes=return_nodes)
print(feature_extractor(torch.rand(1, 3, 224, 224))['layer4'].size())
# >>> torch.Size([1, 2048, 7, 7])
print(feature_extractor(torch.rand(1, 3, 448, 448))['layer4'].size())
# >>> torch.Size([1, 2048, 14, 14]) : 입력 크기 2배 -> 출력 크기 2배
위의 예제에서처럼 resnet의 feature extractor는 입력 크기에 비례하는 크기의 출력을 내놓습니다.
그리고 classifier 부분은 avg pool + dense 레이어로 구성되어있습니다.
resnet의 avg pool은 feature의 채널별로 평균값을 구하는 풀링 방식입니다.
(1, 2048, 7, 7) feature도, (1, 2048, 14, 14) feature도 avg pooling을 수행하면 2048개의 값이 되고 dense레이어는 resnet의 입력 크기에 상관없이 항상 2048개의 값을 받게 됩니다.
정리하면 (1) resnet의 feature extractor는 fully convolutional 구조로 입력 크기에 제한이 없고, (2) classifier가 avg pool 레이어와 dense 레이어로 구성되어 채널 수만 일치하면 역시 입력 크기에 제한이 없기에 448x448 입력에도 동작하게됩니다.
224x224는 resnet을 학습시킬때 사용한 입력 크기지만 제약이 되는 것은 아닙니다.
(다음은 개인적인 의견입니다. 참고만 부탁드립니다.)
224x224 이미지로 학습된 모델에 448x448 이미지를 입력하는 경우 모델이 제대로 대응하지 못할 수도 있겠으나 학습 과정에서 random scaling 등의 augmentation을 통해 오브젝트를 여러 스케일로 학습하여 대응이 가능할겁니다. 그리고 이미지가 클수록 더 디테일한 feature를 얻을 수 있어 성능이 향상되는 경향이 있습니다.
제가 멋지게 설명하고 싶은데 전문적이지는 않아서.. 대충 이런 느낌이지 않을까 싶습니다.
이 글은 마지막 댓글이 달린지 오래(30일)되어 자동으로 닫혔습니다. 댓글 대신 새로운 글을 작성해주세요! ![]()