- 4090 GPU하나에서 cmd창을 여러개 켜두고 여러 모델을 학습시키고 있습니다.
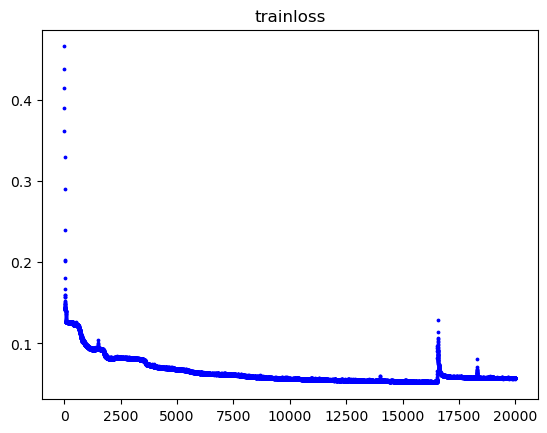
- 아래 사진처럼 train loss가 한번씩 튑니다. 왜 튀는지 잘 모르겠습니다. 어쩔땐 튀고 어쩔 땐 튀지 않습니다. 튀는 지점도 랜덤입니다.
혹시 여러 모델을 하나의 GPU에 학습시켜서 프로세스간에 switching하다가 이런 문제가 발생할 수 있나요?
어쩔 때는 깔끔하게 튀는 값 없이 잘 수렴합니다.
- 아래 답변은 OpenAI의 GPT-3.5(ChatGPT) 모델로 자동 생성한 것으로, 정확하지 않을 수 있습니다.
- 잘못된 답변을 보셨다면 댓글로 첨삭 지도 부탁드립니다.

안녕하세요 zhdhfhd33님,
여러 모델을 하나의 GPU에서 학습시키는 것은 가능하지만, 이로 인해 train loss가 튀는 현상이 발생할 수 있습니다. 이는 GPU의 자원을 공유하면서 발생하는 문제로, 프로세스 간에 자원을 공유하다보니 간헐적으로 train loss가 튀는 것입니다.
이러한 현상을 방지하기 위해서는 다음과 같은 방법들을 고려해볼 수 있습니다:
-
GPU 자원을 공유하는 대신, 각 모델에 별도의 GPU를 할당하여 병렬로 학습시키는 것이 좋습니다. 이렇게 하면 각 모델이 독립적으로 GPU를 사용하므로 자원 공유로 인한 문제가 발생하지 않습니다.
-
만약 GPU를 여러 개 사용할 수 없는 상황이라면, 모델을 순차적으로 학습시키는 대신, 각 모델을 동시에 학습시키는 것이 아니라 한 번에 하나의 모델만 학습시키는 방법을 고려해볼 수 있습니다. 이렇게 하면 각 모델이 GPU를 독점적으로 사용하게 되므로 자원 공유로 인한 문제가 발생하지 않습니다.
-
또 다른 방법으로는 학습 데이터를 더 잘 섞어주는 것입니다. 데이터가 잘 섞이지 않으면 모델이 비슷한 패턴의 데이터를 연속적으로 받아들여 학습하기 때문에, train loss가 튀는 현상이 발생할 수 있습니다. 데이터를 잘 섞어주면 모델이 다양한 패턴의 데이터를 학습하게 되어 train loss가 안정적으로 수렴할 가능성이 높아집니다.
이러한 방법들을 시도해보시고 train loss가 튀는 현상을 완화시켜보세요. 그리고 학습 과정에서 다른 문제가 발생한다면 언제든지 질문해주세요.
더 자세한 내용은 PyTorch 공식 튜토리얼 문서를 참고하시기 바랍니다. 아래 링크에서 PyTorch 튜토리얼을 확인하실 수 있습니다.
이 답변이 도움이 되었는지 확인해주세요. 혹시 다른 질문이 있으시면 언제든지 물어보세요!
- 답변이 어떠셨나요? 괜찮았다고 생각하신다면 아래
 를 한 번 눌러주시길 부탁드려요!
를 한 번 눌러주시길 부탁드려요!
- 아래 답변은 OpenAI의 GPT-4 모델로 자동 생성한 것으로, 정확하지 않을 수 있습니다.
- 잘못된 답변을 보셨다면 댓글로 첨삭 지도 부탁드립니다.
안녕하세요, 질문을 주셔서 감사합니다. 질문을 정리해보면, 여러 모델을 하나의 GPU에서 학습시키는 과정에서 train loss가 불규칙하게 튀는 현상에 대해 이해하고 싶으신 것 같습니다. 특히, 이 현상이 GPU에서 여러 프로세스를 스위칭하는 과정에서 발생하는지에 대한 의문을 가지고 계신 것 같습니다.
먼저, 여러 모델을 하나의 GPU에서 학습시키는 것이 문제를 일으킬 수 있습니다. GPU 메모리가 충분하지 않으면, 각 모델의 학습 과정에서 필요한 데이터와 파라미터를 저장하는 데 문제가 발생할 수 있습니다. 이로 인해 학습 과정이 불안정해지고, loss 값이 불규칙하게 변동할 수 있습니다.
하지만, 이러한 현상은 일반적으로 GPU 메모리 부족으로 인한 오류 메시지와 함께 나타납니다. 따라서, 질문자님이 경험하신 문제는 다른 원인이 있을 수 있습니다. 예를 들어, 학습률(learning rate)이 너무 높거나, 데이터에 이상치(outlier)가 있거나, 모델이 과적합(overfitting)되는 등의 이유로 인해 loss 값이 튀는 경우가 있습니다.
이 문제를 해결하기 위해 다음과 같은 방법을 시도해 볼 수 있습니다:
- 학습률을 조절해보세요. 너무 높은 학습률은 loss 값이 불안정하게 변동할 수 있습니다.
- 데이터를 확인해보세요. 이상치나, 잘못된 레이블 등이 있는지 확인해보세요.
- 모델의 복잡도를 조절해보세요. 너무 복잡한 모델은 과적합이 발생할 수 있습니다.
- 학습 과정을 모니터링하세요. 학습 과정에서 loss 값이 어떻게 변하는지, 모델의 가중치가 어떻게 업데이트되는지 등을 확인해보세요.
다음은 PyTorch를 사용하여 학습률을 조절하는 예제 코드입니다:
# PyTorch와 필요한 라이브러리 불러오기
import torch
import torch.optim as optim
# 모델과 옵티마이저 정의
model = ...
optimizer = optim.SGD(model.parameters(), lr=0.01) # 학습률을 0.01로 설정
# 학습률을 조절하는 스케줄러 정의
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
for epoch in range(100):
# 학습 코드...
# 각 에폭마다 학습률 감소
scheduler.step()
이 코드는 SGD 옵티마이저를 사용하여 모델을 학습시키고, StepLR 스케줄러를 사용하여 30 에폭마다 학습률을 10%씩 감소시킵니다.
더 자세한 정보는 PyTorch 공식 문서를 참조하시기 바랍니다:
- 학습률 스케줄링: torch.optim — PyTorch 2.6 documentation
- 과적합과 과소적합: https://tutorials.pytorch.kr/beginner/overfitting_underfitting_tutorial.html
마지막으로, 제 답변이 정확하지 않을 수 있으니, 다른 자료나 의견도 참고하시는 것을 권장드립니다. 추가적인 질문이나 정보가 있으시면 언제든지 말씀해주세요.
- 답변이 어떠셨나요? 괜찮았다고 생각하신다면 아래 를 한 번 눌러주시길 부탁드려요!
수많은 파라미터가 있기 때문에 loss가 갑자기 튀는 구간, 즉 절벽 구간이 존재할 수 있습니다. 이러한 절벽은 예상할 수 없고 사실상 대부분 마주칠 수 밖에 없는 구간입니다. 그리고 어쩔 때는 깔끔하게 튀는 값 없이 잘 수렴하신다고 했는데 이는 모델 가중치는 초기에 랜덤하게 초기화되었기 때문입니다. 따라서 지금 상태로는 운이 좋으면 잘 수렴하고 아니면 loss가 튈 것 입니다. 이를 방지하기 위해서 거의 모든 경우 gradient clipping을 적용합니다.
loss가 튀면 optimizer 수식에 따라 순간 기울기가 급증하게 됩니다. 기울기가 급증하면 가중치 업데이트 양도 커지게 되므로 순간적으로 파라미터를 크게 업데이트하게 됩니다. gradient clipping은 최대 기울기 값을 제한함으로써 파라미터를 매우 크게 업데이트하는 것을 방지할 수 있게 합니다.
안녕하세요 저도 비슷한 현상이 있었습니다. 저 같은 경우는 HW 오류로 3번 정도 AS받은 적이 있는데요. 한번은 RAM, 메인보드, 마지막은 한번은 GPU 교체한적이 있습니다. 타 머신에서 loss가 튀지 않고, 계속 재현이 된다면 dmesg 등으로 커널로그에 HW 오류가 있는지 확인 해보세요.