더 빠른 Transformer를 위한 Intel Extension / Intel® Extension for Transformers
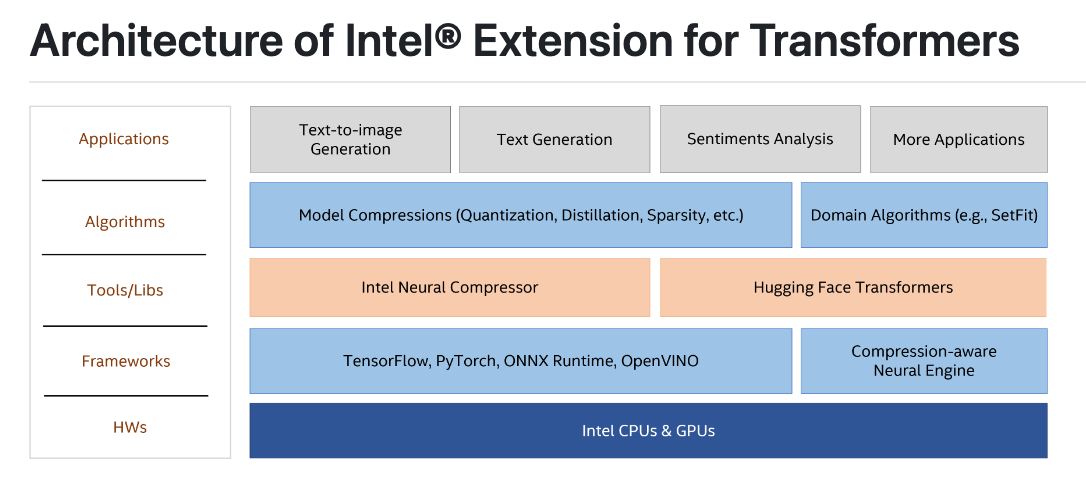
소개
Intel® Extension for Transformers는 Transformer 기반의 모델들을 인텔 플랫폼 (이라고 쓰고 Xeon 사파이어 래피즈에 최적화하여) 에서 더 빠르게 실행할 수 있게 합니다.
데모 영상
LLM Infinite Inference (up to 4M tokens)
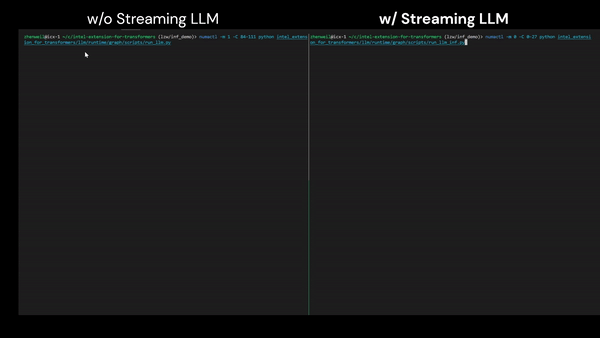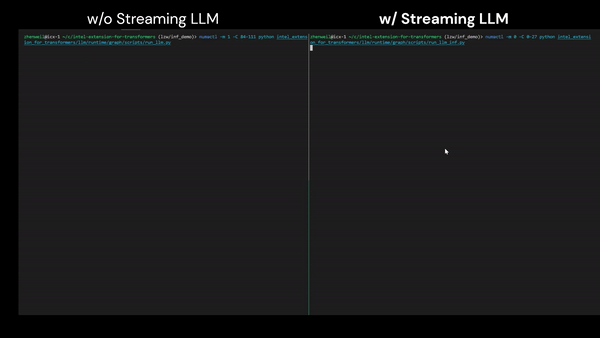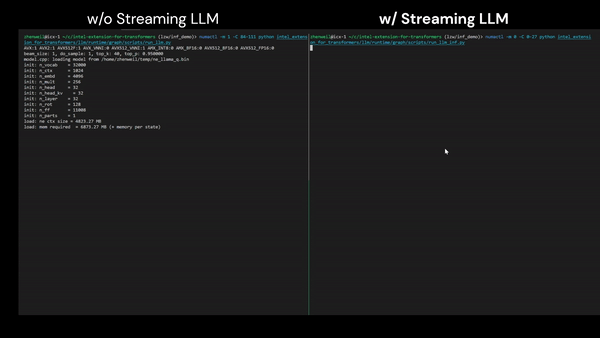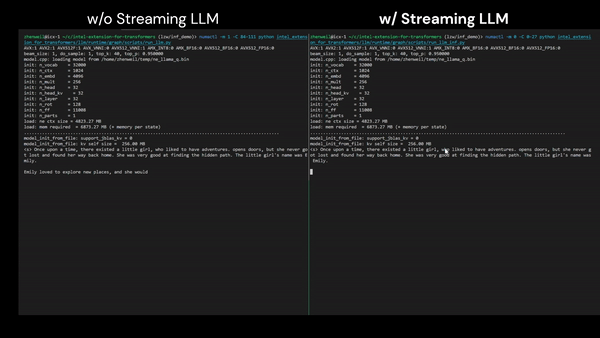
LLM QLoRA on Client CPU
주요 기능
모델 압축
Hugging Face transformers API 확장 및 인텔® 뉴럴 압축기(Intel® Neural Compressor)를 활용하여 트랜스포머(transformer) 기반 모델들의 모델 압축에 대한 원활한 사용자 경험을 제공합니다.
소프트웨어 최적화
고급 소프트웨어 최적화 및 고유한 압축 인식 런타임을 제공합니다. 이는 NeurIPS 2022의 논문 'Fast Distilbert on CPUs' 및 'QuaLA-MiniLM: a Quantized Length Adaptive MiniLM', 그리고 NeurIPS 2021의 논문 'Prune Once for All: Sparse Pre-Trained Language Models'에서 발표된 내용을 기반으로 합니다.
최적화된 모델 패키지
Stable Diffusion, GPT-J-6B, GPT-NEOX, BLOOM-176B, T5, Flan-T5 등의 모델들에 대해 최적화된 트랜스포머 기반 모델 패키지를 제공하며, SetFit 기반 텍스트 분류 및 문서 수준의 감정 분석(DLSA)과 같은 엔드-투-엔드 워크플로우도 지원합니다.
NeuralChat
NeuralChat은 커스터마이징 가능한 챗봇 프레임워크로, 지식 검색, 음성 상호작용, 쿼리 캐싱 및 보안 가드레일과 같은 풍부한 플러그인 세트를 활용하여 몇 분 내에 자체 챗봇을 만들 수 있습니다.
대규모 언어 모델(Large Language Model, LLM) 추론
GPT-NEOX, LLAMA, MPT, FALCON, BLOOM-7B, OPT, ChatGLM2-6B, GPT-J-6B, Dolly-v2-3B 등의 모델들에서 순수 C/C++의 가중치 전용 양자화 커널(weight-only quantization kernels)을 사용하여 LLM의 추론을 지원합니다. AMX, VNNI, AVX512F 및 AVX2 명령어셋을 지원합니다.
사용 예시
더 많은 챗봇 예시는 여기에서, 가중치 전용 INT4/INT8 추론 예시는 여기에서 확인할 수 있습니다.
Chatbot
# pip install intel-extension-for-transformers
from intel_extension_for_transformers.neural_chat import build_chatbot
chatbot = build_chatbot()
response = chatbot.predict("Tell me about Intel Xeon Scalable Processors.")
INT4 Inference
from transformers import AutoTokenizer, TextStreamer
from intel_extension_for_transformers.transformers import AutoModelForCausalLM
model_name = "Intel/neural-chat-7b-v1-1" # Hugging Face model_id or local model
prompt = "Once upon a time, there existed a little girl,"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
inputs = tokenizer(prompt, return_tensors="pt").input_ids
streamer = TextStreamer(tokenizer)
model = AutoModelForCausalLM.from_pretrained(model_name, load_in_4bit=True)
outputs = model.generate(inputs, streamer=streamer, max_new_tokens=300)
INT8 Inference
from transformers import AutoTokenizer, TextStreamer
from intel_extension_for_transformers.transformers import AutoModelForCausalLM
model_name = "Intel/neural-chat-7b-v1-1" # Hugging Face model_id or local model
prompt = "Once upon a time, there existed a little girl,"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
inputs = tokenizer(prompt, return_tensors="pt").input_ids
streamer = TextStreamer(tokenizer)
model = AutoModelForCausalLM.from_pretrained(model_name, load_in_8bit=True)
outputs = model.generate(inputs, streamer=streamer, max_new_tokens=300)
튜토리얼
| Feature | Task | Model | Notebook Link |
|---|---|---|---|
| Static and dynamic post training quantization | language-modeling | Bert-Base | Notebook |
| Static and dynamic post training quantization | Multiple Choice | Bert-Base | Notebook |
| Static and dynamic post training quantization | Question Answering | MiniLM (Distilled from RoBERTa Large) | Notebook |
| Static and dynamic post training quantization | Question Answering | Bert Large | Notebook |
| Dynamic post training quantization | Summarization | Bert Base | Notebook |
| Static and dynamic post training quantization | Token Classification | Distilbert Base | Notebook |
| Dynamic post training quantization | Translation | T5 small | Notebook |
| Static and dynamic post training quantization | Text Classification | Bert Base | Notebook |
| Pruning | Text Classification | Bert base | Notebook |
| Distillation | Question Answering | Specified by user | Notebook |
| Distillation | Text Classification | Specified by user | Notebook |
| Prune Once for All | Text Classification | Bert base | Notebook |
| Prune Once for All | Text Classification | Bert Mini | Notebook |
| Prune Once for ALL | Question Answering | Specified by user | Notebook |
| Prune Once for ALL | Question Answering | Bert Mini | Notebook |
| Length-Adaptive Training and post training quantization | Question Answering | MiniLM | Notebook |
| Early Exit (SWEET) | Text Classification | Bert Base | Notebook |
| Early Exit (TangoBERT) | Text Classification | Roberta Base + Bert Tiny | Notebook |
| SetFit | Text Classification | MiniLM | Notebook |
더 읽어보기
관련 논문: Efficient LLM Inference on CPUs
https://arxiv.org/pdf/2311.00502v1.pdf
GitHub 저장소
공식 문서
관련 논문들
- NeurIPS'2023 on Efficient Natural Language and Speech Processing: Efficient LLM Inference on CPUs (Nov 2023)
- NeurIPS'2023 on Diffusion Models: Effective Quantization for Diffusion Models on CPUs (Nov 2023)
- Blog published on datalearner: Analysis of the top ten popular open source LLM of HuggingFace in the fourth week of November 2023 - the explosion of multi-modal large models and small-scale models (Nov 2023)
- Blog published on zaker: With this toolkit, the inference performance of large models can be accelerated by 40 times (Nov 2023)
- Blog published on geeky-gadgets: [New Intel Neural-Chat 7B LLM tops Hugging Face leaderboard beating original Mistral 7B] (New Intel Neural-Chat 7B LLM tops Hugging Face leaderboard - Geeky Gadgets) (Nov 2023)
- Blog published on Huggingface: Intel Neural-Chat 7b: Fine-Tuning on Gaudi2 for Top LLM Performance (Nov 2023)
- Video on YouTube: Neural Chat 7B v3-1 Installation on Windows - Step by Step (Nov 2023)
- Video on YouTube: Intel's Neural-Chat 7b: Most Powerful 7B Model! Beats GPT-4!? (Nov 2023)
- Blog published on marktechpost: Intel Researchers Propose a New Artificial Intelligence Approach to Deploy LLMs on CPUs More Efficiently (Nov 2023)
- Blog published on VMware: AI without GPUs: A Technical Brief for VMware Private AI with Intel (Nov 2023)
- News releases on VMware: VMware Collaborates with Intel to Unlock Private AI Everywhere (Nov 2023)
- Video on YouTube: Build Your Own ChatBot with Neural Chat | Intel Software (Oct 2023)
- Blog published on Medium: Layer-wise Low-bit Weight Only Quantization on a Laptop (Oct 2023)
- Blog published on Medium: Intel-Optimized Llama.CPP in Intel Extension for Transformers (Oct 2023)
- Blog published on Medium: Reduce the Carbon Footprint of Large Language Models (Oct 2023)