
TranslateGemma 소개
TranslateGemma는 구글(Google)의 번역 연구팀이 야심 차게 공개한 개방형(Open) 기계 번역 모델군입니다. 이 모델은 구글의 최신 파운데이션 모델인 Gemma 3를 기반으로 설계되었으며, 단순한 텍스트 번역을 넘어 이미지 내 텍스트 번역까지 지원하는 멀티모달 능력을 갖추고 있습니다.
오늘날 대규모 언어 모델(LLM)의 발전으로 번역 품질이 비약적으로 향상되었지만, 연구자와 개발자가 자유롭게 수정하고 검증할 수 있는 '투명하고 강력한 개방형 모델'에 대한 갈증은 여전히 존재했습니다. TranslateGemma는 이러한 요구에 부응하기 위해 탄생했습니다. 특히 이 모델은 효율성에 초점을 맞추어 설계되었습니다. 방대한 매개변수를 가진 거대 모델이 아니더라도, 정교한 학습 과정을 거치면 훨씬 작은 크기의 모델로도 동급 최강의 성능을 낼 수 있음을 증명했습니다.
TranslateGemma 모델은 모바일 및 엣지 디바이스를 위한 4B, 일반 소비자용 랩톱에서도 구동 가능한 12B, 그리고 최고의 성능을 제공하는 27B의 세 가지 크기로 제공됩니다. 55개 언어 쌍에 대한 광범위한 테스트에서 TranslateGemma는 베이스라인 모델을 압도하는 성능을 보여주었으며, 이는 번역 기술의 민주화를 앞당기는 중요한 이정표가 될 것입니다.
TranslateGemma vs. Gemma 3 모델 비교
TranslateGemma는 Gemma 3를 기반으로 하지만, 번역에 특화된 미세 조정(Fine-tuning) 을 통해 완전히 다른 차원의 성능을 제공합니다. 주요한 차이점은 다음과 같습니다:
-
체급을 뛰어넘는 효율성: 가장 놀라운 점은 모델 크기 대비 성능입니다. 벤치마크 결과, 12B TranslateGemma 모델은 두 배 이상 큰 27B Gemma 3 베이스라인 모델보다 더 뛰어난 번역 품질을 보여주었습니다. 심지어 가장 작은 4B TranslateGemma 모델조차 12B Gemma 3 베이스라인과 대등한 성능을 발휘합니다. 이는 제한된 하드웨어 자원을 가진 개발자나 연구자에게 엄청난 이점을 제공합니다.
-
압도적인 번역 품질: WMT24++ 벤치마크의 자동 평가(MetricX, COMET22)에서 모든 모델 크기에 걸쳐 일관된 성능 향상이 확인되었습니다. 예를 들어, 27B 모델의 경우 MetricX 점수(낮을수록 좋음)가 4.04에서 3.09로 약 23.5% 개선되었습니다.
-
멀티모달 기능 유지: 일반적으로 특정 작업(번역)에 특화 학습을 하면 다른 기능이 저하될 수 있지만, TranslateGemma는 Gemma 3의 시각적 이해 능력을 그대로 보존했습니다. 별도의 이미지-텍스트 쌍 데이터로 학습하지 않았음에도 불구하고, 이미지 속 텍스트를 번역하는 능력 또한 베이스라인 대비 향상되었습니다.
TranslateGemma 학습 개요
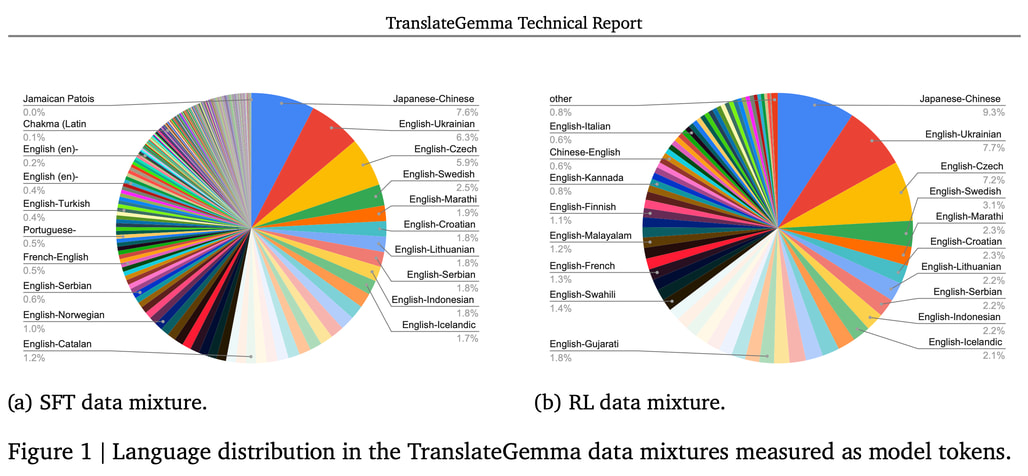
TranslateGemma의 뛰어난 성능은 단순한 데이터 추가 학습이 아닌, 정교하게 설계된 2단계 미세 조정(Two-stage fine-tuning) 파이프라인을 도입한 결과입니다. 각 단계는 지도학습 기반의 미세 조정(SFT, Supervised Fine-tuning) 및 강화학습(RL, Reinforcement Learning) 기반으로 수행되었습니다:
1단계: 지도 미세 조정 (SFT)과 합성 데이터의 마법
첫 번째 단계인 지도 미세 조정(Supervised Fine-Tuning, SFT)에서는 데이터의 양보다 질에 집중했습니다. 이를 위해 먼저 Gemini 2.5 Flash 모델을 사용하여 고품질의 합성 번역 데이터를 생성하는 전략을 택했습니다. 특히, 합성 데이터를 생성할 때에는 단순히 번역문만 생성한 것이 아니라, MetricX 24-QE라는 품질 평가 모델을 필터로 사용했습니다. 각 소스 문장에 대해 128개의 번역 후보를 생성한 뒤, 이 중 가장 품질 점수가 높은 것만을 선별하여 학습 데이터로 활용했습니다. 또한, 짧은 문장뿐만 아니라 최대 512토큰 길이의 긴 텍스트 블록도 생성하여 모델이 긴 문맥을 이해하도록 훈련했습니다.
또한 합성 데이터만으로는 부족할 수 있는 저자원 언어(Low-resource languages)나 특수 스크립트의 커버리지를 높이기 위해, 사람이 직접 번역한 고품질 병렬 데이터를 혼합했습니다. 여기에 더해, 번역에만 너무 과적합(Overfitting)되어 모델의 일반적인 추론 능력이 떨어지는 것을 방지하기 위해, 원본 Gemma 3 학습에 사용했던 일반 지시(General Instruction) 데이터의 30%를 혼합하여 학습했습니다.
2단계: 강화 학습 (RL)과 보상 모델 앙상블

SFT를 마친 모델은 강화 학습(Reinforcement Learning)을 통해 한 번 더 진화합니다. 이 과정에서 구글은 단일 보상 모델이 아닌, 서로 다른 관점을 가진 5가지 보상 모델의 앙상블(Ensemble) 을 사용하여 번역 품질을 다각도로 최적화했습니다. 사용한 보상 모델들은 다음과 같으며, 이러한 보상 모델들은 문장 수준(Sequence-level)과 토큰 수준(Token-level)의 보상을 결합하여 모델이 더 정확하고 자연스러운 번역을 생성하도록 유도합니다:
-
MetricX-24-XXL-QE은 문장 전체의 품질을 평가하는 회귀(Regression) 기반 모델입니다. 점수가 낮을수록 좋은 지표이지만, RL에서는 점수가 높을수록 보상이 커지도록 선형 변환하여 사용했습니다.
-
Gemma-AutoMQM-QE은 번역문의 특정 구간(span)에 존재하는 오류를 찾아내는 모델입니다. 오역이나 부자연스러운 표현을 정확히 집어내어 토큰 단위의 세밀한 피드백을 제공합니다.
-
Naturalness Autorater은 원어민이 쓴 글처럼 자연스러운지를 평가하는 모델입니다. "번역기 냄새"가 나는 어색한 문장을 처벌(penalize)하도록 훈련되었습니다.
-
ChrF은 참조 번역(Reference)과 생성된 번역의 문자 단위 일치도를 보는 전통적인 지표로, 기본적인 정확성을 보장합니다.
-
Generalist Reward Model은 모델이 번역 외의 기본적인 지시 따르기나 추론 능력을 잃지 않도록 돕는 일반적인 보상 모델입니다.
구글은 또한 사람이 평가하는 방식과 유사하게 학습되어 기존의 BLEU 점수보다 훨씬 정확하게 번역 품질을 측정할 수 있는 자동 번역 평가 지표인 MetricX를 개발하고, 이에 대한 내용을 GitHub 저장소에 공개했습니다:
TranslateGemma 모델의 성능 평가 결과
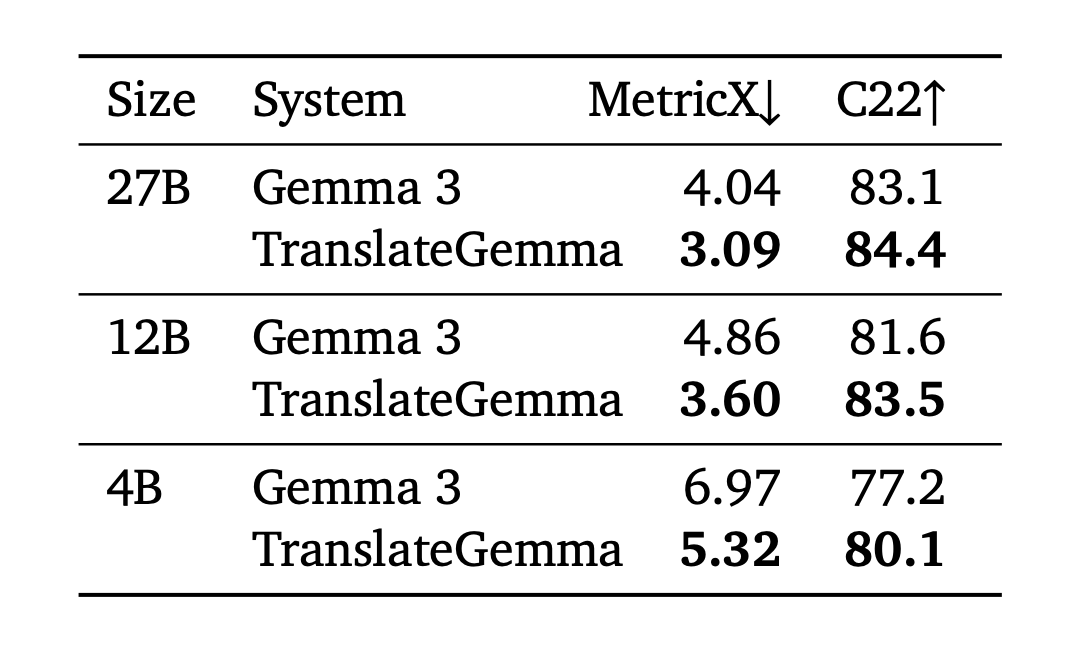
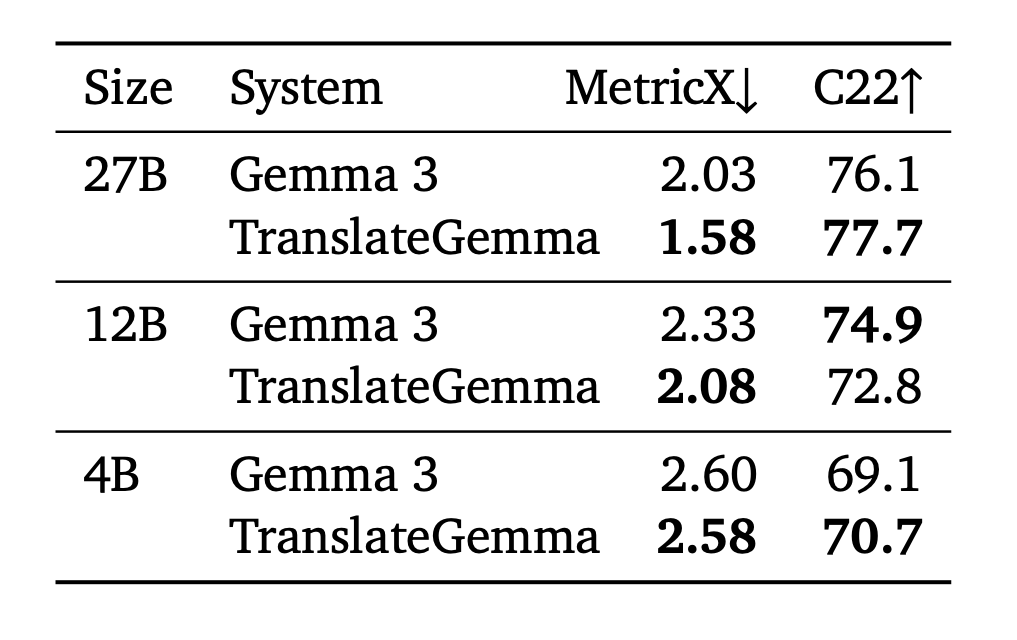
자동 평가 (WMT24++) 결과, 55개 언어 쌍에 대한 평가에서 TranslateGemma는 괄목할 만한 성과를 거두었습니다. 특히 영어→독일어(MetricX 1.63→1.19), 영어→아이슬란드어(MetricX 8.31→5.69)와 같이 고자원 언어와 저자원 언어 모두에서 오류율이 크게 감소했습니다.
그 외 이미지 번역 (Vistra Benchmark) 에서는 텍스트 번역 훈련만 수행했음에도 불구하고, 이미지 속 텍스트를 인식하고 번역하는 능력이 향상되었습니다. 27B 모델 기준으로 MetricX 점수가 약 0.5점 개선되었으며, 이는 텍스트 이해 능력의 향상이 시각적 정보 처리에도 긍정적인 영향을 미쳤음을 시사합니다.
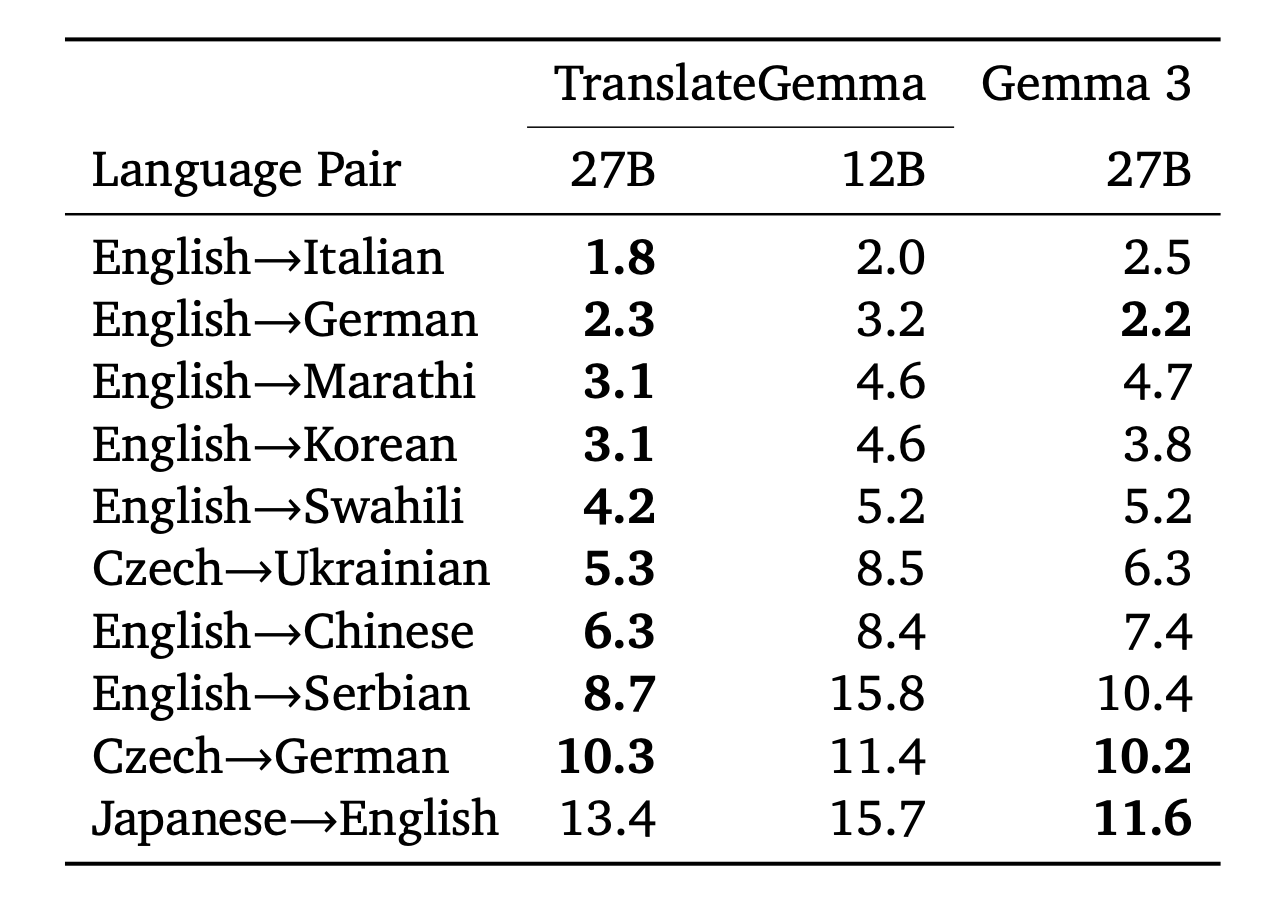
인간 평가 (Human Evaluation) 부분에서는 전문 번역가들이 참여한 MQM(Multidimensional Quality Metrics) 평가에서도 TranslateGemma의 우수성이 입증되었습니다. 특히 영어→마라티어(Marathi)나 영어→스와힐리어(Swahili) 같은 저자원 언어 번역에서 베이스라인 대비 큰 폭의 품질 향상을 기록했습니다. 다만 일본어→영어 번역에서는 고유명사 오역 문제로 인해 일부 점수 하락이 관찰되기도 했습니다.
TranslateGemma 사용 가이드
TranslateGemma는 Hugging Face의 transformers 라이브러리를 통해 쉽게 사용할 수 있습니다. 특히 이 모델은 정확한 번역을 위해 엄격한 채팅 템플릿(Strict Chat Template) 형식을 요구합니다. 이 때, TranslateGemma는 User 역할의 입력은 반드시 리스트(list) 형태여야 하며, 명시적인 언어 코드와 타입을 지정해야 합니다:
// Hugging Face User 입력 예시 구조
{
"role": "user",
"content": [
{
"type": "text", // 또는 "image"
"text": "Translate this into Korean.", // 번역할 원문
"source_lang_code": "en", // ISO 639-1 코드 (예: en, ko)
"target_lang_code": "ko"
}
]
}
만약 직접 프롬프트를 구성하여 사용하고 싶다면, TranslateGemma 기술 문서(Technical Report)에서 제안하는 아래의 형식을 따르는 것이 가장 성능이 좋습니다.

권장 프롬프트 (Text Prompt):
"You are a professional {source_lang} ({src_lang_code}) to {target_lang} ({tgt_lang_code}) translator. Your goal is to accurately convey the meaning and nuances of the original {source_lang} text while adhering to {target_lang} grammar, vocabulary, and cultural sensitivities. Produce only the {target_lang} translation, without any additional explanations or commentary. Please translate the following {source_lang} text into {target_lang}:\n\n{text}"
라이선스
TranslateGemma 모델은 Gemma 사용 약관 하에 배포되고 있습니다. 상업적 사용이 가능하나, 구체적인 사용 조건이 있으므로 라이선스 원문을 반드시 확인해야 합니다.
 TranslateGemma 공식 블로그
TranslateGemma 공식 블로그
TranslateGemma 기술 문서 (Technical Report)
 TranslateGemma 모델 다운로드
TranslateGemma 모델 다운로드
TranslateGemma 4B Model: google/translategemma-4b-it
TranslateGemma 12B Model: google/translategemma-12b-it
TranslateGemma 27B Model: google/translategemma-27b-it
 TranslateGemma 활용을 위한 예시 코드(Cookbook)
TranslateGemma 활용을 위한 예시 코드(Cookbook)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()