Trieve 소개
Trieve는 검색(Search), 추천(Recommendation) 및 RAG(Retrieval-Augmented Generation) 기능을 빠르게 구현할 수 있는 플랫폼입니다. 기존에 수개월 소요되던 작업을 간소화하여, 사용자가 자신의 데이터로 ChatGPT와 같은 경험이나 검색 엔진을 몇 시간 만에 구축하고 배포할 수 있도록 돕습니다.
Trieve는 검색, 추천, RAG(Retrieval-Augmented Generation), 및 데이터 분석을 하나의 API로 통합한 인프라를 제공합니다. Trieve는 사용자 맞춤형 검색 및 데이터 활용을 돕는 강력한 기능을 포함하고 있으며, 다양한 환경에서 자체 호스팅이 가능합니다.
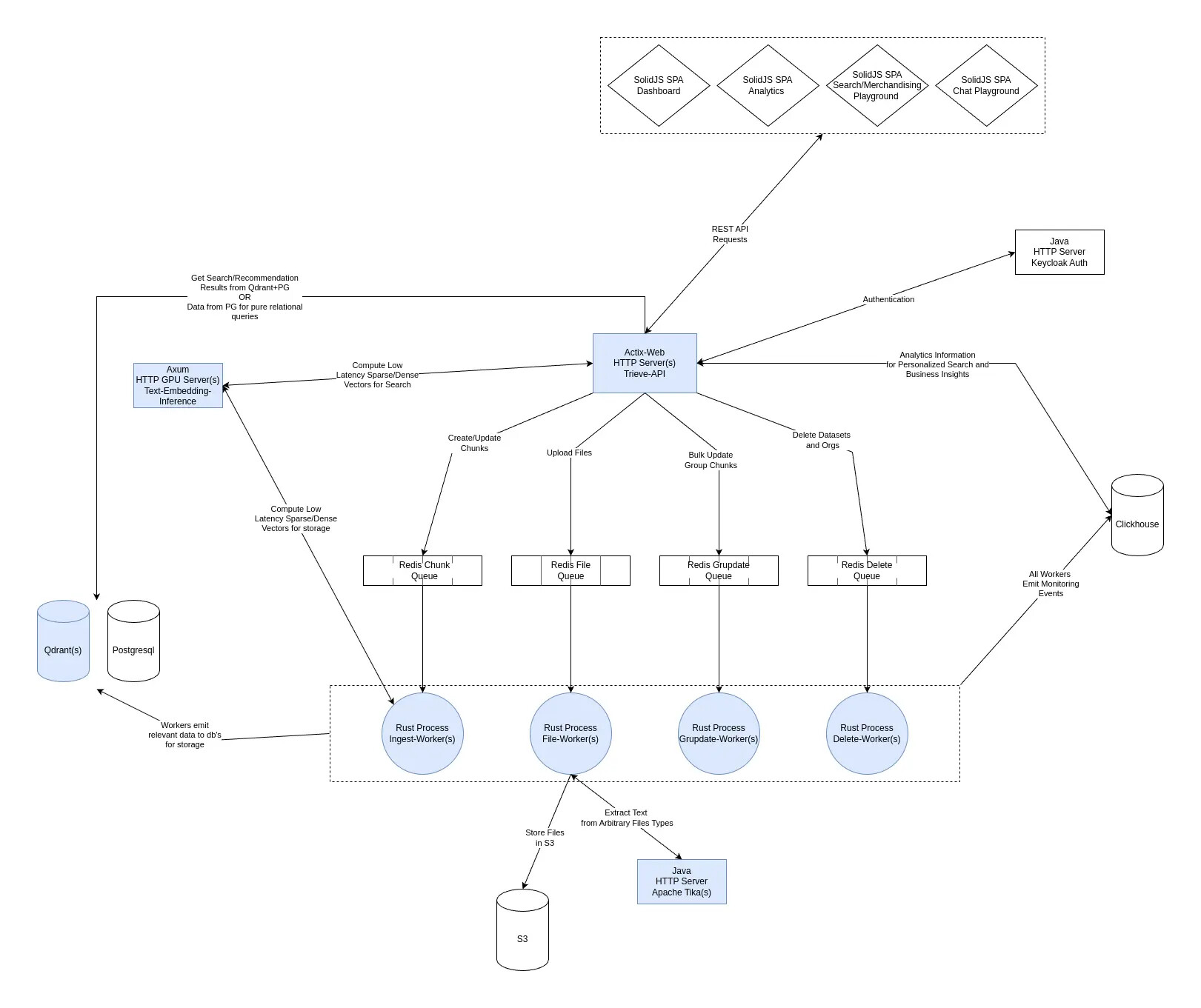
Trieve의 주요 특징은 다음과 같습니다:
- 자체 호스팅: AWS, GCP, Kubernetes 및 Docker Compose를 지원.
- 시맨틱 벡터 검색: OpenAI, Jina 모델 및 Qdrant 기반의 시맨틱 검색.
- 오류 허용 텍스트 검색: Neural Sparse Vector Search로 사용자가 입력한 검색어의 오타를 자동 교정.
- 하이라이트 기능: 검색 결과 내에서 매칭되는 텍스트를 강조 표시.
- 추천 API: 유사 콘텐츠 추천 기능 제공.
- RAG API 통합: 사용자가 선택한 컨텍스트 기반 RAG 지원.
- 모델 커스터마이징: 사용자가 자신의 텍스트 임베딩, SPLADE, 크로스 인코더를 연결 가능.
- 하이브리드 검색: 최적화를 위해 BAAI 재랭크 모델 사용.
- 시간 편향: 최신 데이터 우선 검색.
- 필터링 및 그룹화: 날짜 범위, 태그 및 특정 조건을 활용한 검색.
Trieve 활용 사례 및 데모
Trieve의 실제 사용 예시는 다음과 같습니다:
- Hacker News 검색 엔진: Trieve HN Discovery
- YCombinator 회사 디렉토리 검색: YCombinator Companies Search
- SteamDB 검색 엔진: SteamDB Search
 Trieve GitHub 저장소
Trieve GitHub 저장소
 Trieve 공식 문서 사이트
Trieve 공식 문서 사이트
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()