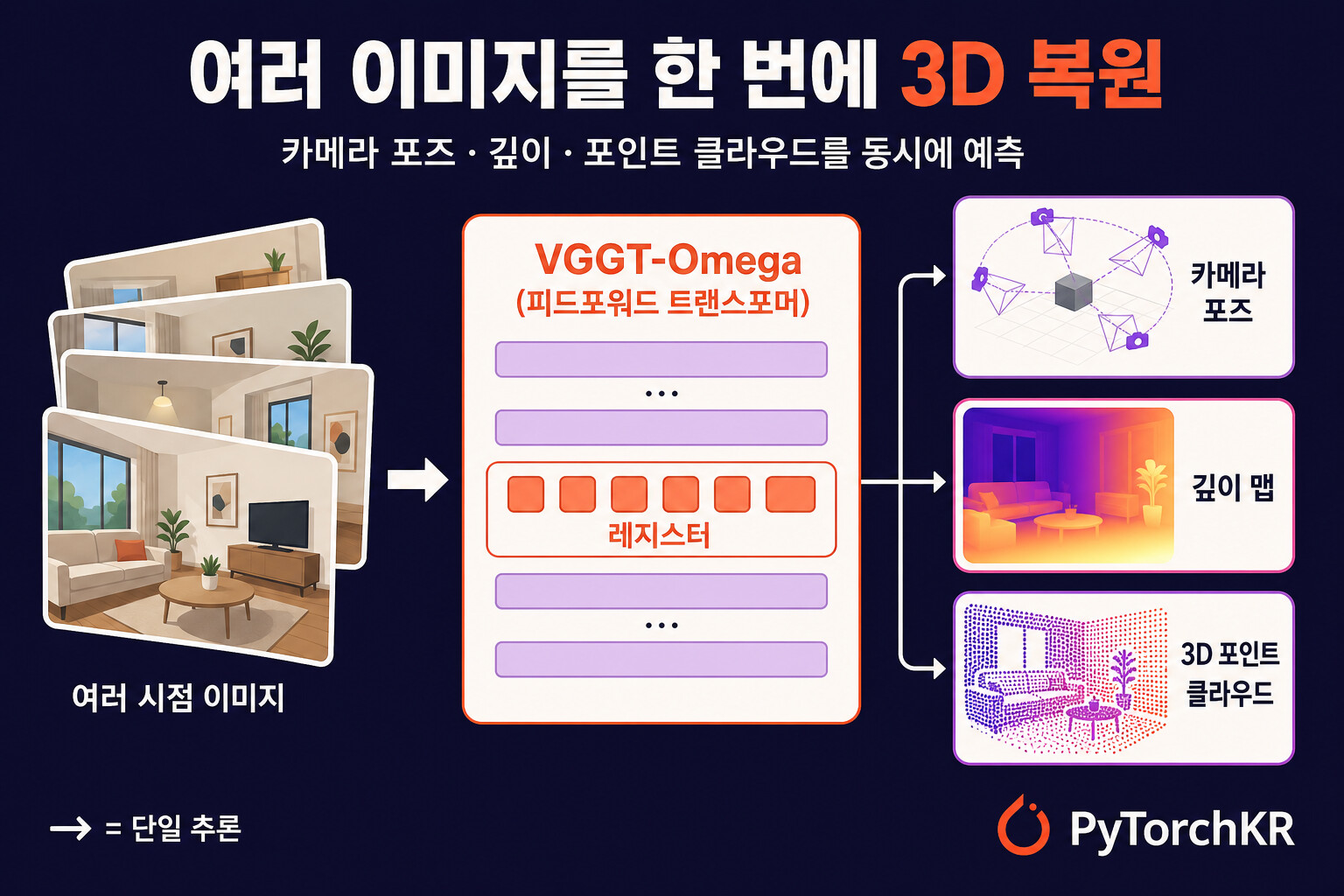
VGGT-Omega 소개
VGGT-Omega(VGGT-Ω)는 여러 시점에서 찍은 이미지를 한 번의 피드포워드(feed-forward) 추론으로 카메라 포즈, 깊이, 3D 포인트 클라우드로 복원하는 비전 모델입니다. 옥스퍼드 대학의 Visual Geometry Group과 Meta AI 연구진이 함께 발표했고 CVPR 2026 Oral에 채택되었습니다. 최적화 기반의 전통적인 복원 방식과 경쟁할 만한 품질을 내면서, 다른 작업에 쓸 수 있는 기하 인식(geometry-aware) 특징까지 제공하는 VGGT 계열을 확장한 모델입니다.
핵심 메시지는 이런 피드포워드 복원 모델의 품질이 모델과 데이터 규모에 따라 예측 가능하게 향상된다는 것입니다. VGGT-Omega는 정적 장면뿐 아니라 움직이는 객체가 있는 동적 장면(dynamic scene)에서도 복원 정확도와 효율, 표현 범위를 크게 끌어올렸습니다. 저자들은 이를 위해 학습 효율을 높이는 구조 변경, 동적 장면을 지원하는 고품질 데이터 주석 파이프라인, 자기지도 학습(self-supervised learning) 프로토콜을 함께 도입했다고 설명합니다.
모델은 두 가지 사전학습 체크포인트로 제공됩니다. 해상도 512에서 동작하는 VGGT-Omega-1B-512 와 해상도 256에서 텍스트 정렬(text alignment)을 지원하는 VGGT-Omega-1B-256-Text-Alignment 입니다. 체크포인트는 Hugging Face에서 접근 요청 후 내려받을 수 있으며(자동화된 절차로 검토), 누구나 쓸 수 있는 Hugging Face 데모도 공개되어 있습니다.

VGGT-Omega의 핵심 개선
VGGT-Omega는 학습을 전례 없는 규모로 끌어올리기 위해 구조를 단순화했습니다. 여러 개의 출력 헤드 대신 멀티태스크 지도(multi-task supervision)를 받는 단일 dense 예측 헤드 를 사용하고, 비용이 큰 고해상도 합성곱(convolution) 레이어를 제거했습니다.
또한 장면 정보를 소수의 토큰으로 압축하는 레지스터(register) 를 도입하고, 프레임 간 정보 교환을 이 레지스터로 제한하는 레지스터 어텐션(register attention)을 제안했습니다. 이는 모든 토큰이 서로를 참조하는 전역 어텐션(global attention)을 부분적으로 대체합니다. 이 설계 덕분에 학습 시 VGGT-Omega는 이전 모델 대비 약 30%의 GPU 메모리만 사용하며, 그 결과 이전 연구보다 15배 많은 지도 학습 데이터로 학습하고 레이블이 없는(unlabeled) 방대한 영상 데이터까지 활용할 수 있었습니다(논문 Abstract).
VGGT-Omega의 성능
VGGT-Omega는 여러 벤치마크에서 정적·동적 장면 복원 모두 강력한 결과를 보고합니다. 대표적으로 Sintel 벤치마크에서 카메라 추정 정확도를 이전 최고 성능 대비 77% 개선했습니다(논문 Abstract). 더 나아가 학습된 레지스터가 시각-언어-행동(vision-language-action) 모델을 개선하고 언어와의 정렬을 지원한다는 점을 보이며, 3D 복원이 공간 이해(spatial understanding)를 위한 강력하고 확장 가능한 대리 과제(proxy task)가 될 수 있음을 시사합니다.
추론 시 GPU 메모리는 입력 프레임 수에 따라 늘어납니다. 다음은 624x416 입력 이미지로 단일 NVIDIA A100에서 VGGT-Omega-1B-512 의 종단간(end-to-end) 최대 GPU 메모리를 측정한 값으로, 모델 가중치 로딩부터 순전파까지 전체 과정을 포함합니다.
| 입력 프레임 | 1 | 50 | 100 | 200 | 300 | 500 |
|---|---|---|---|---|---|---|
| 최대 메모리 (GB) | 6.02 | 9.66 | 13.37 | 20.82 | 28.26 | 43.15 |
VGGT-Omega 설치 및 사용
저장소를 클론하고 의존성을 설치한 뒤, 몇 줄의 PyTorch 코드로 모델을 사용할 수 있습니다.
git clone git@github.com:facebookresearch/vggt-omega.git
cd vggt-omega
pip install -r requirements.txt
pip install -e .
여러 이미지를 입력하면 카메라 포즈, 깊이, 깊이 신뢰도, 카메라·레지스터 토큰 등을 한 번에 예측합니다.
import torch
from vggt_omega.models import VGGTOmega
from vggt_omega.utils.load_fn import load_and_preprocess_images
from vggt_omega.utils.pose_enc import encoding_to_camera
checkpoint_path = "path/to/vggt_omega_1b_512.pt"
image_names = ["path/to/imageA.png", "path/to/imageB.png", "path/to/imageC.png"]
model = VGGTOmega().to("cuda").eval()
model.load_state_dict(torch.load(checkpoint_path, map_location="cpu"))
images = load_and_preprocess_images(image_names, image_resolution=512).to("cuda")
with torch.inference_mode():
predictions = model(images)
extrinsics, intrinsics = encoding_to_camera(
predictions["pose_enc"],
predictions["images"].shape[-2:],
)
depth = predictions["depth"]
depth_conf = predictions["depth_conf"]
텍스트 정렬 체크포인트를 쓰려면 VGGTOmega(enable_alignment=True) 를 image_resolution=256 으로 사용하고 predictions["text_alignment_embedding"] 을 읽습니다. 또한 demo_gradio.py 로 Gradio 데모를 띄우면 업로드한 이미지나 영상에 대해 카메라·깊이 추론을 수행하고, 깊이를 역투영한 포인트 클라우드와 예측된 카메라를 GLB 장면으로 시각화합니다.
VGGT-Omega의 라이선스
VGGT-Omega는 FAIR Noncommercial Research License로 공개되어 있습니다. 이름 그대로 비상업적 연구 목적 으로만 사용할 수 있는 라이선스이므로, 상업적 활용을 계획한다면 라이선스 본문과 함께 제공되는 Acceptable Use Policy를 먼저 확인해야 합니다.
 VGGT-Omega 데모
VGGT-Omega 데모
 VGGT-Omega 프로젝트 페이지
VGGT-Omega 프로젝트 페이지
 VGGT-Omega 논문
VGGT-Omega 논문
 VGGT-Omega 프로젝트 GitHub 저장소
VGGT-Omega 프로젝트 GitHub 저장소
 VGGT-Omega 모델 다운로드
VGGT-Omega 모델 다운로드
더 읽어보기
-
Splatter Image: 초고속 단일 뷰 3D 재구성 (Splatter Image: Ultra-Fast Single-View 3D Reconstruction)
-
Sapiens: 🧑🤝🧑 인간 비전 모델을 위한 파운데이션 모델 (feat. Meta Reality Labs)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다!
로 보내드립니다!
텔레그램(Telegram)이나 Slack/Discord/Teams/Dooray/GoogleChat 등으로도 새 글 알림을 받으실 수 있습니다. ![]()
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()