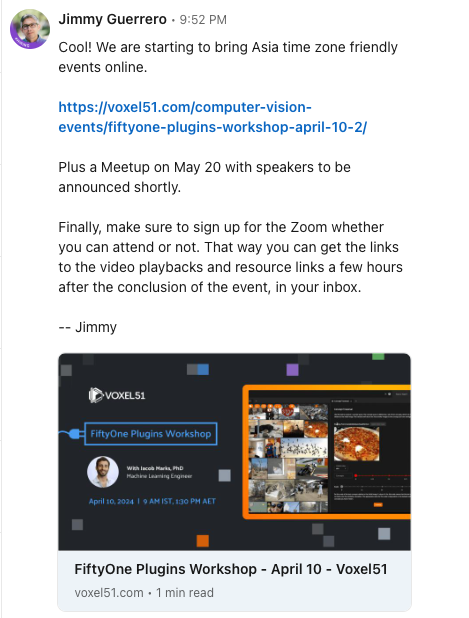
이번 모임은 2024년 4월 18일, 태평양 표준시 기준 오전 10시(UTC 17:00)에 Zoom을 통해 진행됩니다. AI, 머신 러닝, 데이터 과학에 관심 있는 12,000명 이상의 열정적인 참가자들과 함께할 수 있는 이번 행사는 AI 기술의 최신 동향과 응용에 대해 배우고 토론할 수 있는 기회로 보여 공유합니다. ![]()
진행 일시
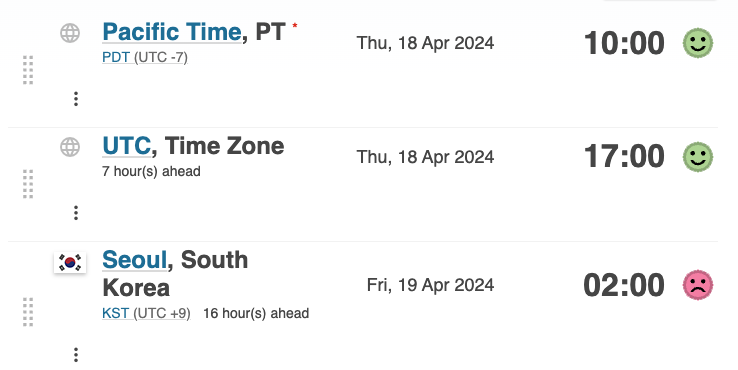
- 진행 일시: 한국시간 4월 19일(금) 오전 2시
- 4월 18일 오전 10시(Pacific Time) / 17:00 (UTC)
발표 주제
-
자원 효율적이면서 강인한 텍스트-이미지 생성 모델: 마이트레야 파텔이 소개하는 ECLIPSE 모델은 매개 변수와 데이터 효율성이 뛰어나, 높은 계산 자원을 요구하는 기존 T2I 확산 모델에 대한 해결책을 제시합니다.
-
지식 그래프를 활용한 GraphRAG: 안드레아스 콜레거는 자연어를 다양한 그래프 데이터 패턴으로 매핑하는 지식 그래프의 사용 사례를 소개합니다. 이는 GenAI 응용 프로그램에서의 지식 그래프 사용 연구를 담당하는 Neo4j의 창립 멤버입니다.
-
Voxel51과 V7 Darwin 통합을 통한 훈련 데이터 최적화: * 마크 콕스-스미스는 머신 러닝 프로젝트에서 고품질 훈련 데이터 획득의 중요성과 이를 최적화하는 방법에 대해 논의합니다.
-
멀티모달 모델 탐구: Llava-Next 및 TextQA 데이터셋: 하프리트 사호타는 LlaVa 모델의 최신 버전인 LlaVa-next를 사용하는 방법과 TextQA 데이터셋에서 Vicuna-7B 및 Mistral-7B 백본 모델의 성능을 시각적으로 확인하는 방법을 소개합니다.