
vLLM-Omni 소개
vLLM 팀은 텍스트 중심의 AI 서빙을 넘어, 음성 및 영상과 같은 멀티모달 데이터를 실시간으로 처리할 수 있는 새로운 프레임워크인 vLLM-Omni를 공개했습니다. 최근 AI 분야의 트렌드는 단순한 텍스트 채팅을 넘어, 보고 듣고 말하는 '옴니-모달(Omni-Modality)' 에이전트로 진화하고 있습니다. 하지만 기존의 오픈소스 서빙 엔진들은 주로 텍스트 기반의 자기회귀(Autoregressive, AR) 작업에만 최적화되어 있어, 이러한 복합적인 데이터를 실시간으로 처리하는 데 한계가 있었습니다.
vLLM-Omni는 이러한 격차를 해소하기 위해 설계되었습니다. 이 시스템은 텍스트뿐만 아니라 오디오와 이미지 입출력을 지원하며, 특히 실시간 음성 상호작용(Speech-to-Speech) 에 최적화된 엔드투엔드(End-to-End) 파이프라인을 제공합니다. 개발자들은 이를 통해 복잡한 별도의 음성 인식/합성 모델을 연결할 필요 없이, 단일 LLM 프로세스 내에서 사람과 대화하는 듯한 빠른 응답 속도의 AI 서비스를 구축할 수 있습니다.

즉, 기존의 vLLM이 텍스트 생성에 집중했다면, vLLM-Omni는 OmniStage라는 새로운 추상화 계층을 도입하여 비디오 생성이나 실시간 음성 대화와 같은 복잡한 멀티모달 워크플로우를 단일 파이프라인 안에서 매끄럽게 처리합니다.
기존에 멀티모달(특히 음성) 기능을 구현하기 위해서는 여러 개의 독립된 모델을 순차적으로 연결하는 캐스케이드(Cascade) 방식을 주로 사용했습니다. vLLM-Omni는 이 구조를 근본적으로 혁신했습니다. 이를 기존의 방식과 비교해보면 다음과 같습니다:
| 특징 | 기존 캐스케이드 방식 (Traditional Cascade) | vLLM-Omni (End-to-End) |
|---|---|---|
| 구조 | ASR(음성인식) → LLM(텍스트 생성) → TTS(음성합성) 순차 실행 | 단일 모델이 입력 오디오를 이해하고 오디오 토큰을 직접 생성 |
| 지연 시간 (Latency) | 각 단계의 처리 시간이 누적되어 응답이 느림 | 스트리밍 방식으로 처리하여 매우 낮은 지연 시간 달성 |
| 정보 손실 | 음성 톤, 감정 등의 비언어적 정보가 텍스트 변환 과정에서 소실됨 | 오디오 신호를 직접 처리하므로 뉘앙스와 감정 유지 가능 |
| 복잡도 | 3개 이상의 모델을 관리하고 조율해야 함 | 하나의 통합된 파이프라인으로 관리 용이 |
vLLM-Omni의 주요 특징

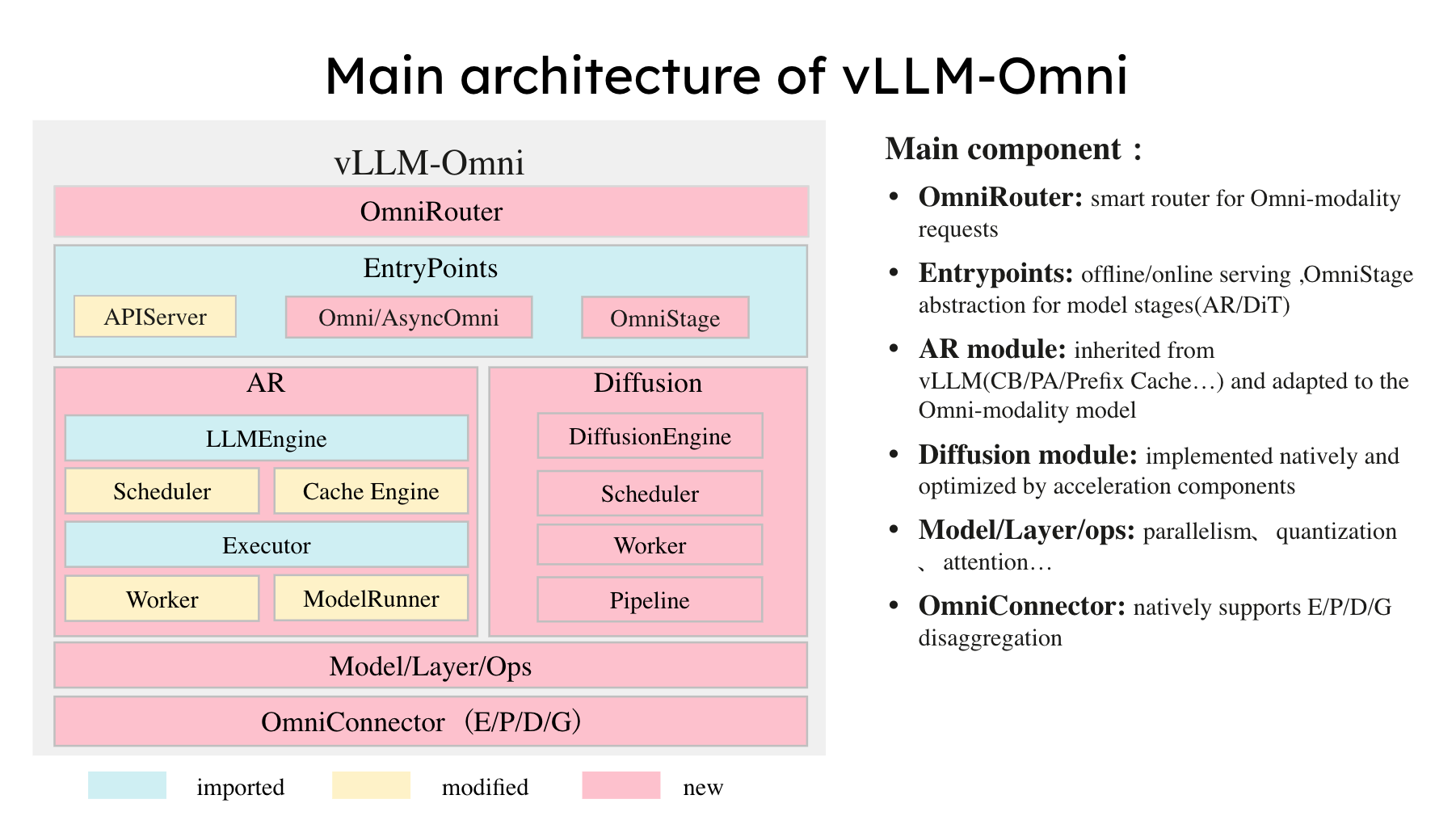
vLLM-Omni는 vLLM의 핵심 기술인 고성능 KV 캐시 관리(PagedAttention) 를 멀티모달 영역으로 확장하여, 복잡한 데이터 흐름에서도 메모리 효율성과 추론 속도를 극대화했습니다. 단순한 텍스트 생성을 넘어, 오디오와 이미지 입출력을 처리하기 위해 다음과 같은 세 가지 핵심 아키텍처를 도입했습니다.
분리형 파이프라인 아키텍처 (Disaggregated Pipeline)
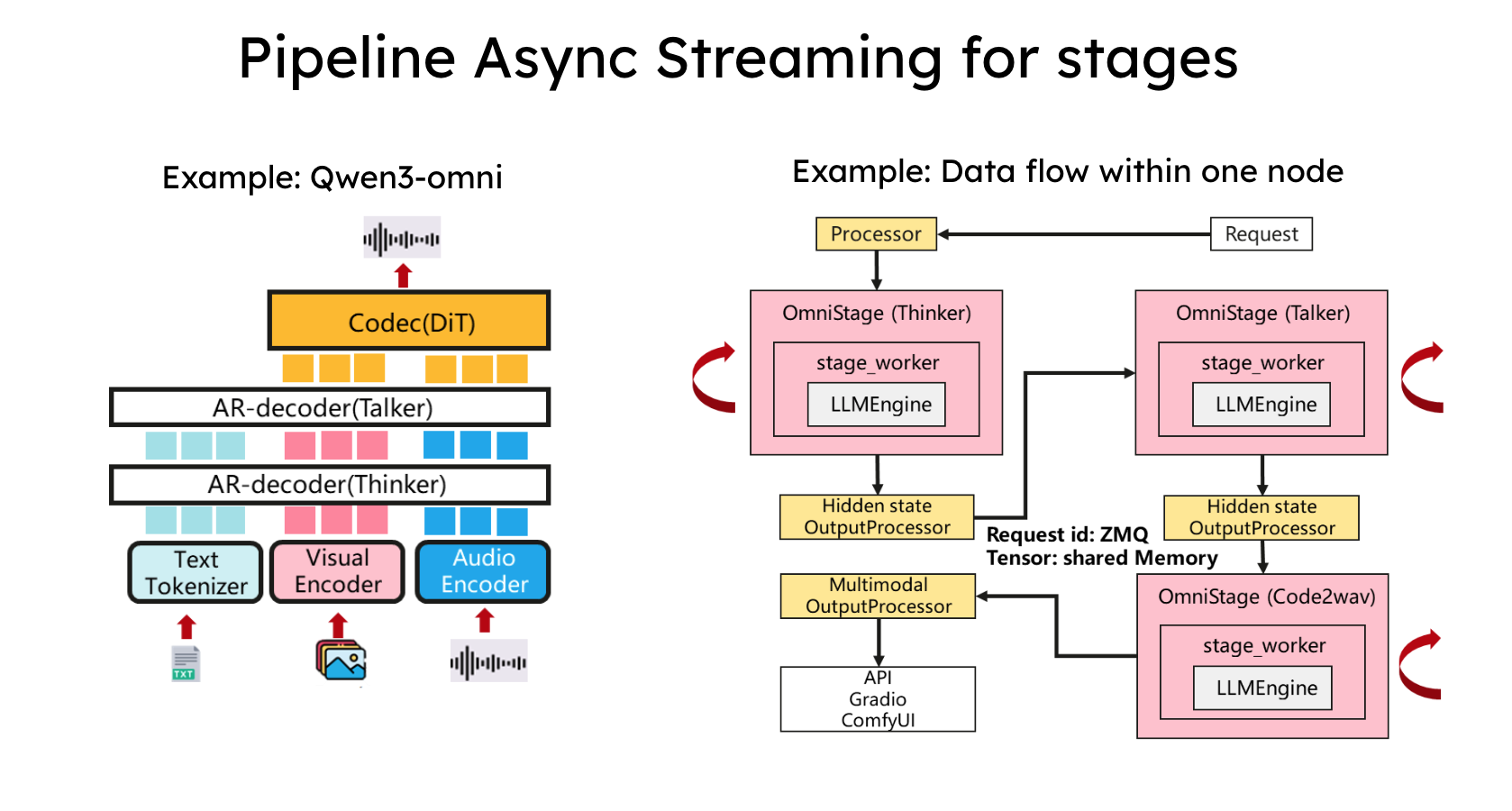
vLLM-Omni는 거대하고 복잡한 멀티모달 추론 과정을 단일 덩어리로 처리하지 않고, 세 가지의 독립적인 핵심 단계(Stage)로 분리하여 파이프라인화했습니다:
-
Modality Encoders (입력 처리 단계): 외부에서 들어오는 비정형 데이터(마이크의 음성 신호, 카메라의 이미지 등)를 모델이 이해할 수 있는 임베딩 벡터로 변환합니다. (사용 모델 예시: Whisper (음성 인코더), Vision Transformer (ViT, 이미지 인코더))
-
LLM Core (추론 엔진 단계): 인코딩된 입력을 바탕으로 텍스트 토큰과 오디오/이미지 생성을 위한 잠재(Latent) 토큰을 생성합니다. vLLM의 핵심 엔진을 사용하여 높은 처리량(Throughput)으로 다음 토큰을 예측합니다.
-
Modality Generators (출력 생성 단계): LLM이 생성한 출력 토큰을 디코딩하여 실제 사용자가 보고 들을 수 있는 오디오 파형이나 이미지로 변환합니다. (사용 모델 예시: HiFi-GAN (음성 합성), Diffusion Transformer (이미지 생성))
실시간 스트리밍 및 중첩 실행 (Stage Overlapping)

vLLM-Omni의 성능을 결정짓는 가장 큰 특징은 파이프라인의 각 단계가 순차적으로 대기하는 것이 아니라, 병렬적이고 유기적(Overlapping) 으로 작동한다는 점입니다.
-
입력 대기 시간 제거: 사용자의 발화가 완전히 끝나기를 기다리지 않고, 입력되는 오디오 청크(Chunk)를 실시간으로 인코딩하여 LLM에 전달합니다.
-
즉각적인 생성: LLM이 첫 번째 오디오 토큰을 생성하자마자, 제너레이터(Generator)가 즉시 이를 소리로 변환하여 스트리밍합니다.
-
지연 시간 최소화: 이러한 파이프라인 중첩(Pipelined Stage Execution) 기술을 통해 전체적인 응답 지연(Latency)을 획기적으로 줄여, 마치 사람과 대화하는 듯한 실시간성을 확보했습니다.
다양한 모델 지원 및 확장성 (OmniStage)
새로운 멀티모달 모델이 쏟아져 나오는 환경에 대응하기 위해, vLLM-Omni는 OmniStage라는 추상화 계층을 도입했습니다. 이를 통해 개발자는 복잡한 내부 로직을 수정하지 않고도 새로운 아키텍처를 쉽게 추가할 수 있습니다.
-
Qwen2.5-Omni: 텍스트와 오디오를 동시에 이해하고 생성하는 대표적인 음성 상호작용 모델입니다.
-
Qwen-Image: 텍스트 명령을 받아 고품질 이미지를 생성하는 모델을 지원합니다.
-
Llama-3.1-Omni: 최신 Llama 모델 기반의 옴니 모델까지 지원 범위를 확장하고 있습니다.
vLLM-Omni가 지원하는 모델들은 다음 문서에서 확인하실 수 있습니다:
현재 NVIDIA 및 AMD GPU에서 지원되는 모델들은 다음과 같습니다:
| Architecture | Models | Example HF Models |
|---|---|---|
Qwen3OmniMoeForConditionalGeneration |
Qwen3-Omni | Qwen/Qwen3-Omni-30B-A3B-Instruct |
Qwen2_5OmniForConditionalGeneration |
Qwen2.5-Omni | Qwen/Qwen2.5-Omni-7B, Qwen/Qwen2.5-Omni-3B |
QwenImagePipeline |
Qwen-Image | Qwen/Qwen-Image |
QwenImageEditPipeline |
Qwen-Image-Edit | Qwen/Qwen-Image-Edit |
QwenImageEditPlusPipeline |
Qwen-Image-Edit-2509 | Qwen/Qwen-Image-Edit-2509 |
QwenImageLayeredPipeline |
Qwen-Image-Layered | Qwen/Qwen-Image-Layered |
ZImagePipeline |
Z-Image | Tongyi-MAI/Z-Image-Turbo |
WanPipeline |
Wan2.2 | Wan-AI/Wan2.2-T2V-A14B-Diffusers |
OvisImagePipeline |
Ovis-Image | OvisAI/Ovis-Image |
LongcatImagePipeline |
LongCat-Image | meituan-longcat/LongCat-Image |
현재 NPU에서 지원되는 모델들은 다음과 같습니다:
| Architecture | Models | Example HF Models |
|---|---|---|
Qwen2_5OmniForConditionalGeneration |
Qwen2.5-Omni | Qwen/Qwen2.5-Omni-7B, Qwen/Qwen2.5-Omni-3B |
QwenImagePipeline |
Qwen-Image | Qwen/Qwen-Image |
vLLM-Omni 설치 및 사용 예시

vLLM-Omni의 초기 릴리즈인 v0.11.0rc 버전은 vLLM v0.11.0을 기반으로 구축되었습니다. 현재 vLLM-Omni는 vllm 패키지의 확장 형태로 제공되며, 사용법이 매우 직관적입니다. pip 를 사용하여 손쉽게 설치할 수 있습니다:
# vLLM이 설치되어 있지 않다면, 먼저 vLLM을 설치해야 합니다
pip install vllm
# vLLM-Omni 설치
pip install vllm-omni
GPU 및 NPU 등, 가속 H/W에 따른 상세한 설치 관련 설명은 다음 vLLM 설치 문서를 참고해주세요:
서버 실행 (OpenAI API 호환)
기존의 vLLM을 사용하여 OpenAI API와 호환되는 서버를 실행할 때 --omni 플래그를 추가하여 멀티모달 기능을 활성화할 수 있습니다. 다음은 Qwen2.5-Omni 모델의 서빙 예시입니다:
# Qwen2.5-Omni 모델 서빙 예제
vllm serve Qwen/Qwen2.5-Omni --omni --port 8000 --trust-remote-code
Python Client 요청 예시
아래는 위와 같은 방식으로 실행된 vLLM Omni의 OpenAI 호환 API Server에 요청하는 Python Client 예시입니다. 실제 API 호출 포맷은 모델 및 vLLM 버전에 따라 다소 차이가 있을 수 있으므로 공식 문서를 참조해야 합니다:
# pip install openai 로 OpenAI SDK 설치 필요
from openai import OpenAI
client = OpenAI(
api_key="EMPTY",
base_url="http://localhost:8000/v1",
)
# 오디오 입력과 함께 채팅 요청 (가상의 예시)
response = client.chat.completions.create(
model="Qwen/Qwen2.5-Omni",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "이 오디오 파일의 내용을 요약해줘."},
{"type": "image_url", "image_url": {"url": "data:audio/wav;base64,..."}} # 오디오 데이터 전송
]
}
],
stream=True
)
멀티모달 모델 서빙 예제
이미지, 오디오, 비디오 생성 워크플로우를 실행하기 위한 스크립트는 GitHub의 예제 디렉토리에서 확인할 수 있습니다. 또한, 사용자 경험을 높이기 위해 Qwen-Image 서빙 데모 등의 예시를 Gradio 기반의 웹 데모도 지원합니다. 예시 코드는 다음 GitHub 저장소의 example/ 디렉토리에서 확인하실 수 있습니다.
vLLM-Omni의 향후 발전 계획(Roadmap)
vLLM-Omni는 현재 빠르게 발전하고 있으며, 향후 다음과 같은 기술적 도약을 준비하고 있습니다:
- 지원 모델 확장 (Expanded Model Support): 새롭게 등장하는 다양한 오픈소스 옴니 모델과 확산 트랜스포머(Diffusion Transformer) 모델에 대한 지원을 지속적으로 추가할 예정입니다.
- 적응형 프레임워크 개선 (Adaptive Framework Refinement): 프로덕션 환경과 최첨단 연구 환경 모두에서 신뢰할 수 있는 기반이 되도록, 새로운 실행 패턴을 지원하는 방향으로 프레임워크를 고도화합니다.
- vLLM과의 통합 심화 (Deeper vLLM Integration): vLLM-Omni의 핵심 기능을 vLLM의 메인 스트림으로 병합하여, 멀티모달 기능을 vLLM 생태계의 '일급 시민(First-class citizen)'으로 격상시킬 계획입니다.
- Diffusion 가속화 (Diffusion Acceleration): 이미지/비디오 생성을 위한 확산 모델의 성능을 극한으로 끌어올립니다.
- 병렬 추론: DP(데이터 병렬), TP(텐서 병렬), SP(시퀀스 병렬) 등 지원.
- 캐시 가속: TeaCache, DBCache 등의 기술 적용.
- 연산 가속: 양자화(Quantization), 희소 어텐션(Sparse Attention) 도입.
- 완전 분리형 아키텍처 (Full Disaggregation): OmniStage 추상화를 기반으로 인코더, 프리필(Prefill), 디코딩, 생성 단계를 물리적으로 분리하여 실행할 수 있게 합니다. 이는 대규모 서빙 환경에서 처리량을 높이고 지연 시간을 줄이는 데 핵심적인 역할을 할 것입니다.
- 하드웨어 지원 확장 (Hardware Support): 하드웨어 플러그인 시스템을 통해 GPU 외에도 다양한 하드웨어 백엔드에서 효율적으로 실행되도록 지원 범위를 넓힐 예정입니다.
라이선스
vLLM-Omni 프로젝트는 Apache License 2.0으로 배포되고 있어, 연구 목적은 물론 상업적 용도로도 자유롭게 사용 및 수정이 가능합니다.
 vLLM-Omni 공식 홈페이지
vLLM-Omni 공식 홈페이지
 vLLM-Omni 출시 및 소개 블로그
vLLM-Omni 출시 및 소개 블로그
 vLLM-Omni 프로젝트 GitHub 저장소
vLLM-Omni 프로젝트 GitHub 저장소
https://github.com/vllm-project/vllm-omni
 vLLM-Omni 설계 디자인 및 로드맵 소개
vLLM-Omni 설계 디자인 및 로드맵 소개
커뮤니티 참여 (Join the Community)
vLLM 팀에서는 이제 막 시작된 Omni-Modality 서빙의 미래를 함께 만들어갈 개발자들의 참여를 기다리고 있습니다.
Slack 참여
vLLM Slack의 #sig-omni 채널에서 질문하고 피드백을 주고받을 수 있습니다.
주간 미팅
매주 화요일 19:30 (PDT 기준)에 로드맵과 기능을 논의하는 정기 미팅이 열립니다. 미팅 참여 링크 및 기존 미팅에 대한 내용은 다음 문서에 정리되어 있습니다.
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()