
vLLM Semantic Router 소개
vLLM Semantic Router는 다양한 언어 모델(LLM) 환경에서 사용자 요청을 이해하고, 사용자의 요청을 적절한 모델로 효율적으로 라우팅하는 인공지능 기반의 시스템입니다. 이 시스템은 특히 모델 선택 및 라우팅의 지능화를 목표로 하며, 실시간 추론 성능을 극대화하고 보안 및 효율성을 강화합니다. 기존의 단순한 룰 기반 분기 방식과 달리, 의미적 이해를 바탕으로 요청의 의도, 복잡도, 보안 수준 등을 종합적으로 고려해 가장 적합한 LLM으로 자동 분기합니다.
이러한 기술은 특히 다양한 크기의 언어 모델들이 병렬적으로 운영되는 하이브리드 환경에서 그 중요성이 커지고 있습니다. 예를 들어, 단순 요청은 소형 모델로 빠르게 처리하고, 복잡하거나 고난도 요청은 대형 모델로 전달하여 응답 품질을 높이는 방식입니다. 이는 처리 시간과 비용을 줄이는 동시에 응답 품질을 유지하거나 향상시키는 데 중요한 역할을 합니다.
vLLM Semantic Router는 ModernBERT 기반의 파인튜닝 모델을 활용해 요청의 의미를 이해하고, 개인 식별 정보(PII) 감지 및 프롬프트 보안 기능, 의미적 캐싱, 실시간 분석 기능까지 제공합니다. 클라우드 네이티브 설계를 통해 기존 인프라와도 쉽게 통합할 수 있으며, 분산 처리 및 자동 스케일링 기능을 갖춰 대규모 환경에서도 안정적으로 운영할 수 있습니다.
Semantic Kernel과 비교
vLLM Semantic Router는 Microsoft의 Semantic Kernel과 개념적으로 유사한 점이 있지만, 적용 방식과 주요 기능에서 차별점을 갖고 있습니다. Semantic Kernel은 주로 플러그인 기반으로 프롬프트 워크플로우를 구성하고 실행하는 데 초점을 두는 반면, vLLM Semantic Router는 요청 자체를 다양한 모델로 라우팅하는 데 중점을 둡니다. 특히 의미 기반 캐싱이나 프롬프트 보안, 실시간 분석 기능 등은 운영 환경에서 더욱 실용적인 이점을 제공합니다.
또한, vLLM Semantic Router는 다양한 LLM 환경에 유연하게 통합될 수 있는 설계를 갖추고 있어, MLOps 측면에서도 우수한 확장성과 유연성을 제공합니다. Semantic Kernel이 개발자 친화적인 워크플로우 중심이라면, vLLM Semantic Router는 운영 친화적인 고성능 라우팅 중심이라는 차이가 있습니다.
vLLM Semantic Router의 주요 기능
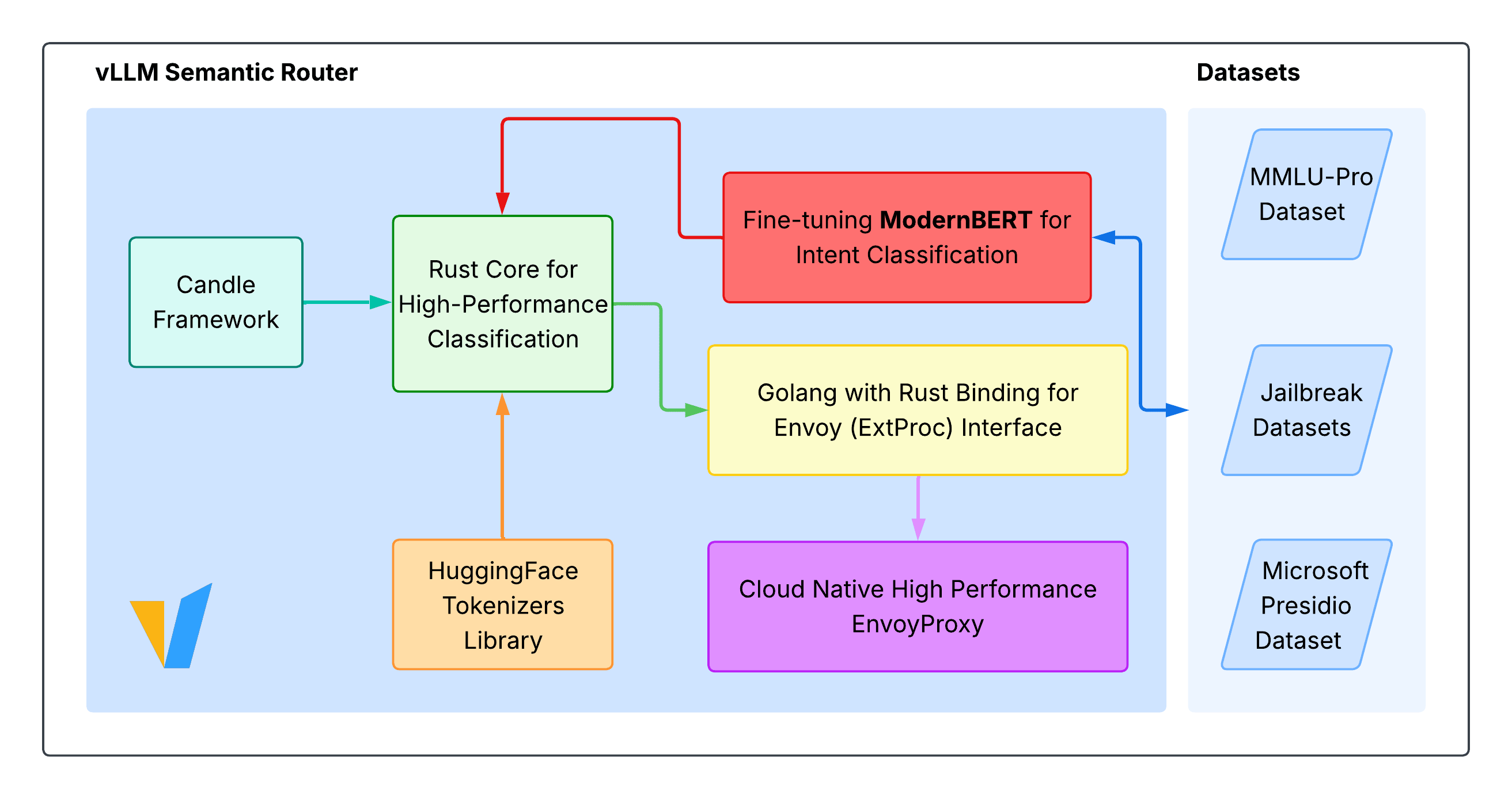
-
Mixture-of-Models (MoM) 기반 지능형 라우팅: vLLM Semantic Router는 단순한 라우팅 시스템이 아니라, Mixture-of-Experts(MoE) 개념을 외부 모델 수준에서 구현한 Mixture-of-Models (MoM) 라우터입니다. 기존 MoE는 하나의 거대한 모델 안에서 전문가 서브네트워크를 선택하여 효율을 높이는 방식이었다면, vLLM Semantic Router는 여러 개의 LLM 중에서 가장 적합한 “전체 모델”을 선택하는 방식으로 구현되어 있습니다.
BERT 기반 분류기를 통해 요청의 복잡도, 과제 성격, 필요한 도구 등을 분석한 후, 이에 가장 적합한 모델(OpenAI API 포함)을 자동으로 선택합니다. 이를 통해 모델의 정확도를 유지하면서도, 추론 비용과 응답 시간을 효율적으로 관리할 수 있습니다. -
자동 도구 선택 기능 (Auto-Selection of Tools): vLLM Semantic Router는 요청에 따라 적절한 도구(예: 계산기, 검색기 등)를 자동으로 선택하는 기능도 제공합니다. 이 기능은 프롬프트에서 불필요한 도구 호출을 줄여서 토큰 소비를 최소화하고, LLM의 도구 사용 정확도를 향상시킵니다.
-
AI 보안 기능 (AI-Powered Security): 시스템은 PII(개인 식별 정보) 감지와 Prompt Guard를 통해 민감한 데이터 노출이나 Jailbreak 시도를 사전에 탐지하고 차단할 수 있습니다. 이로써 보안이 중요한 산업 환경에서도 안전한 AI 운영이 가능합니다. 특히 Prompt Injection 공격에 대한 방어 메커니즘은 실서비스에서 필수적인 요소로 평가됩니다.
-
의미 기반 캐싱 (Semantic Caching): 의미적 캐시는 기존 프롬프트의 의미적 표현을 저장해두고, 유사한 요청이 들어올 경우 이를 재활용하여 불필요한 토큰 소비를 줄이고 응답 속도를 빠르게 합니다. 단순 캐시가 아니라, 의미 수준에서의 유사성 비교를 기반으로 하기 때문에 정밀도가 매우 높습니다.
-
자동 추론 엔진 (Auto-Reasoning Engine): 요청의 복잡도, 도메인 전문성 요구사항, 성능 제약 조건 등을 분석해 가장 적합한 모델을 선택하는 자동 추론 시스템입니다. 이 기능은 단순 분기 이상으로, 실제 태스크 해결에 필요한 리소스를 정확히 예측해 분배합니다.
-
실시간 분석 대시보드 (Real-time Analytics): 시스템 운영자는 라우팅 결정, 모델 성능, 네트워크 처리 흐름 등을 실시간으로 모니터링할 수 있는 대시보드를 활용할 수 있습니다. 이 대시보드는 신경망 수준의 통찰력 및 지표를 제공하여, 시스템 최적화와 디버깅을 용이하게 만듭니다.
-
확장 가능한 아키텍처 (Scalable Architecture): vLLM Semantic Router는 클라우드 네이티브 설계로, 분산 처리 및 자동 스케일링 기능을 갖추고 있습니다. 이는 대규모 AI 시스템 운영에 적합하며, 기존 LLM 서빙 인프라에도 쉽게 통합됩니다. 예를 들어, vLLM, Ray Serve, Kubernetes 등 다양한 환경에서 유연하게 운영이 가능합니다.
-
API 및 설치 문서 제공
vLLM Semantic Router 공식 홈페이지에는 매우 상세한 설치 가이드, 시스템 아키텍처 문서, 모델 훈련 방식, API 명세 등이 제공되고 있어, 실제 구축 및 운영 단계에서 큰 도움이 됩니다.
이러한 문서들은 실무자들이 vLLM Semantic Router를 직접 설치하고 운영하는 데 필요한 거의 모든 정보를 담고 있으며, 이는 단순한 오픈소스가 아닌 엔터프라이즈 수준의 LLM 라우팅 솔루션임을 보여주는 증거이기도 합니다.
- Golang 및 Rust 기반 구현: 기술적인 구현 측면에서 이 라우터는 Golang 언어로 구현되었으며, 일부 신경망 연산은 Candle 프레임워크를 기반으로 한 Rust FFI를 사용합니다. 이는 고성능 실시간 처리를 위한 선택이며, Python 버전과의 성능 비교 벤치마킹도 예정되어 있습니다. 이를 통해 개발자들은 다양한 언어 환경에서 효율적으로 통합하고 운영할 수 있는 유연성을 확보할 수 있습니다.
문서 및 개발 가이드
vLLM Semantic Router는 실사용에 필요한 모든 기술 문서를 완비하고 있으며, 이를 통해 개발자와 운영자가 쉽게 시스템을 구축하고 커스터마이징할 수 있도록 지원합니다. 이 문서들은 Read the Docs 플랫폼에 정리되어 있으며, 실제 운영 환경에서 필요한 기술적 인사이트와 가이드를 제공합니다.
특히 다음과 같은 주요 문서가 포함되어 있습니다:
-
설치 가이드 문서: 이 문서에서는 시스템 요구 사항, 의존성 설치, 초기 설정 방법까지 자세히 설명하고 있어, 처음 설치하는 사용자도 단계별로 따라갈 수 있도록 구성되어 있습니다. 특히 Golang 기반 서버 실행 방법과 API 연동 방식 등이 명확히 제시되어 있습니다.
-
시스템 아키텍처 설명 문서: vLLM Semantic Router의 전체 시스템 구조에 대한 기술적 설명이 포함되어 있습니다. BERT 기반 분류기의 역할, 라우팅 처리 흐름, 캐시 메커니즘, 도구 선택 로직 등 핵심 모듈들의 상호작용을 도식과 함께 설명합니다.
-
모델 학습 방법: 이 부분은 Semantic Router의 중심이 되는 분류 모델을 어떻게 학습시키는지에 대한 설명을 제공합니다. 데이터 전처리, fine-tuning 방식, 실험적 하이퍼파라미터 등이 포함되어 있어, 사용자 환경에 맞춘 재학습도 가능합니다.
-
API 명세(Specification) 문서: RESTful API 기반으로 구성된 라우터의 모든 엔드포인트를 문서화하고 있으며, 요청 및 응답 형식, 파라미터 설명, 예제 등도 함께 제공됩니다. 이는 외부 시스템과의 통합 개발 시 매우 유용합니다.
이처럼 문서가 체계적으로 구성되어 있어, 개발자나 MLOps 담당자가 vLLM Semantic Router를 빠르게 이해하고 운영 환경에 도입하는 데 큰 도움이 됩니다.
라이선스
vLLM Semantic Router 프로젝트는 Apache-2.0 License 하에 공개 및 배포되고 있습니다.
 vLLM Semantic Router 공식 홈페이지
vLLM Semantic Router 공식 홈페이지
 vLLM Semantic Router 프로젝트 GitHub 저장소
vLLM Semantic Router 프로젝트 GitHub 저장소
더 읽어보기
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()