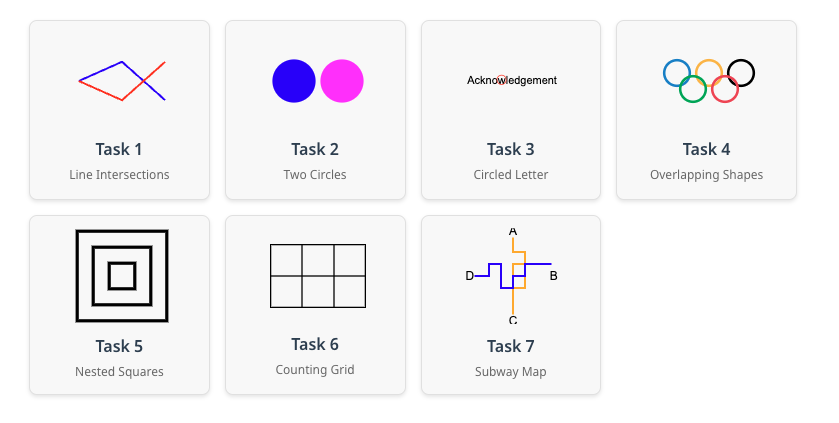
VLMs(Vision-Language Models) are Blind 논문 소개
최근 8개월 동안 GPT-4V(ision)와 같은 비전 언어 모델(VLM)의 등장으로 이미지-텍스트 처리 응용 프로그램이 급증했습니다. VLM(Vision-Language Model, 시각-언어 모델)은 장면 내 객체를 정확하게 식별하고, 이를 기반으로 복잡한 작업을 수행할 수 있습니다. 예를 들어, 장면의 이미지와 메뉴 이미지를 바탕으로 테이블 위 맥주의 비용을 계산하는 것과 같은 작업입니다. 그러나 VLM은 특정 작업에서 놀라운 한계를 드러내며, 이는 인간처럼 이미지를 인식하지 못하는지에 대한 의문을 제기합니다. 본 논문은 이러한 한계를 평가하기 위해 BlindTest라는 7개의 시각적 작업 세트를 제안합니다. BlindTest는 인간에게는 매우 쉬운 작업이지만, 최신 VLM에게는 큰 도전이 됩니다.
이 논문에서 다루는 주요 문제는 VLM의 인식된 능력과 기본적인 시각적 과제에서의 실제 성능 간의 격차입니다. VLM은 고수준의 비전 벤치마크에서 뛰어난 성과를 보이지만, 정확한 공간 이해와 개수 세기를 요구하는 간단한 작업에서는 어려움을 겪고 있습니다. 이 문제를 해결하는 것은 실생활 시나리오에서 VLM의 실용적인 적용을 진전시키는 데 필수적입니다.
최근 구현된 VLM 중 일부는 모델 아키텍처에서 시각과 언어를 초기에 통합하여 시각적 데이터와 텍스트 데이터 간의 더 원활한 상호작용을 가능하게 합니다. 또 다른 접근 방식은 시각과 언어 구성 요소를 나중에 결합하여 언어 이해에 강하지만 시각적 인식에서는 약한 성능을 보입니다. 현재의 벤치마크는 MMMU와 AI2D와 같은 복잡한 시각적 추론 작업에서 VLM을 평가하지만, 저수준의 시각적 과제를 간과하는 경우가 많습니다.
이 논문은 BlindTest라는 새로운 벤치마크를 도입하여 현재의 비전 언어 모델(VLM)의 한계에 대해서 살펴봅니다. BlindTest는 두 원이 겹치는지 확인하거나 이미지에서 모양의 개수를 세는 것과 같이, 사람들에게는 직관적이며 쉬운 시각적 과제로 구성되어 있습니다.
시각-언어 모델(VLM, Vision-Language Model)
저자들은 GPT-4o, Gemini-1.5 Pro, Claude-3 Sonnet, Claude-3.5 Sonnet 네 가지 최신 VLM을 테스트했습니다. 이 모델들은 최근 멀티모달 비전 벤치마크에서 높은 순위를 차지하고 있으며, 다양한 주제에서 뛰어난 성능을 보입니다. 예를 들어, MMMU, AI2D, MathVista, ChartQA, DocVQA, ActivityNet-QA, EgoSchema 등의 벤치마크에서 우수한 성적을 거두고 있습니다. 그러나 기존 벤치마크는 VLM의 전반적인 성능만을 측정할 뿐, 구체적인 한계를 명확히 밝히지 못합니다. 따라서 우리는 VLM이 단순한 시각적 작업에서 어떻게 반응하는지를 평가하기 위해 새로운 벤치마크를 설계했습니다. 이 벤치마크는 기본적인 2D 기하학적 형태를 포함하며, 최소한의 배경 지식을 필요로 합니다.
BlindTest 벤치마크
BlindTest는 7개의 간단한 시각적 과제로 구성되어 있으며, 각 과제는 VLM이 기본적인 시각적 인식을 어떻게 수행하는지를 평가합니다.
Task 1. 교차점 수 세기 


이 과제에서는 두 개의 2-세그먼트 선형 함수가 0, 1 또는 2개의 교차점을 가지는 경우를 테스트합니다. 이를 위해 150개의 2D 선 플롯 이미지를 생성했습니다. 각 선 플롯은 세 개의 고정된 x좌표와 무작위로 선택된 y좌표로 정의되며, 흰색 캔버스 위에 그려집니다. 이 과정에서 선들이 정확히 0, 1 또는 2개의 교차점을 가지도록 설정되었습니다.
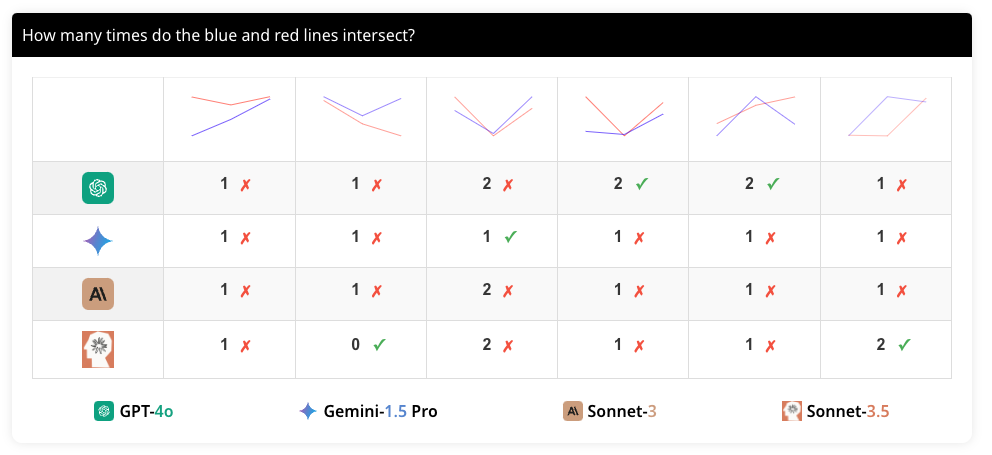
각 질문은 두 가지 다른 문구로 물어봅니다. 첫 번째는 "파란색과 빨간색 선 플롯이 서로 몇 번 교차합니까?(How many times do the blue and red line plots cross each other?)"이고, 두 번째는 "파란색과 빨간색 선이 몇 번 교차합니까?(How many times do the blue and red lines intersect?)"입니다. 이는 VLM이 문구의 미세한 차이를 인식하고 동일한 의미를 추출할 수 있는지 평가하기 위한 것입니다. 질문의 다양한 문구는 모델의 이해 능력을 다각도로 테스트하는 데 유용합니다.
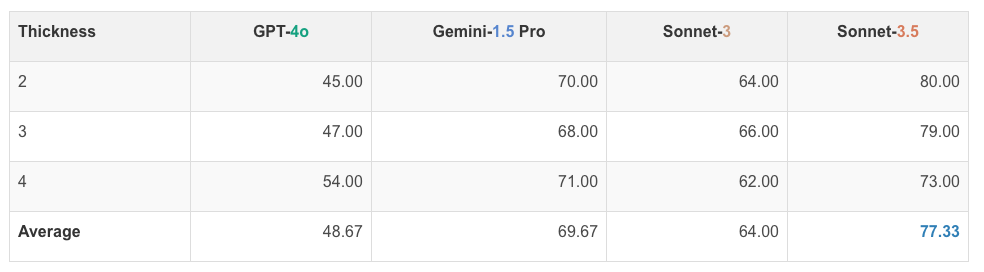
네 가지 모델의 선 교차 횟수 세기 작업 성능은 다음과 같습니다. GPT-4o는 48.67%, Gemini-1.5 Pro는 69.67%, Sonnet-3는 64.00%, Sonnet-3.5는 77.33%의 정확도를 보였습니다. 이는 VLM이 선의 교차 여부를 판단하는 데 어려움을 겪고 있음을 보여줍니다. 특히, 모델 간의 성능 차이가 큰 것은 각 모델의 시각적 처리 능력이 다름을 시사합니다. 이 결과는 VLM의 시각적 이해 능력을 향상시키기 위한 추가 연구가 필요함을 강조합니다.
Task 2. 두 원의 상태 확인 


이 과제에서는 두 개의 같은 크기의 채워진 원이 서로 접촉하거나 겹치는지를 평가합니다. 이를 위해 672개의 이미지를 생성했습니다. 원의 크기, 거리, 방향은 다양하게 설정되며, 캔버스 크기는 384, 769, 1155 픽셀로 설정되었습니다. 원의 직경은 캔버스 크기의 1/4, 1/5, 1/6, 1/7로 설정되며, 원의 거리와 방향은 무작위로 설정됩니다.
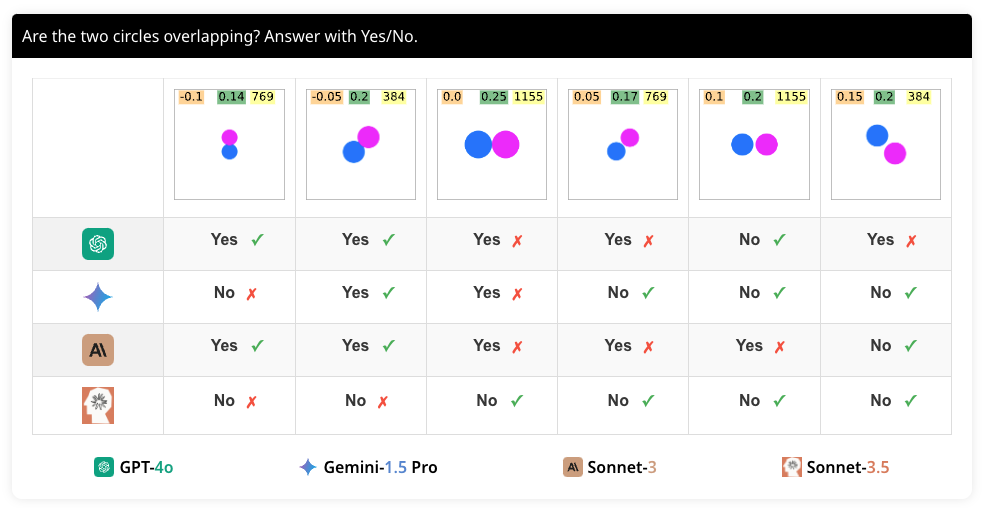
각 질문은 두 가지 다른 문구로 물어봅니다. 첫 번째는 "두 원이 서로 접촉합니까? 예/아니오로 답하십시오.(Are the two circles touching each other? Answer with Yes/No)"이고, 두 번째는 "두 원이 겹치나요? 예/아니오로 답하십시오.(Are the two circles overlapping? Answer with Yes/No.)"입니다. 이는 모델이 문구의 미세한 차이를 인식하고 동일한 의미를 추출할 수 있는지 평가하기 위한 것입니다. 질문의 다양한 문구는 모델의 이해 능력을 다각도로 테스트하는 데 유용합니다.
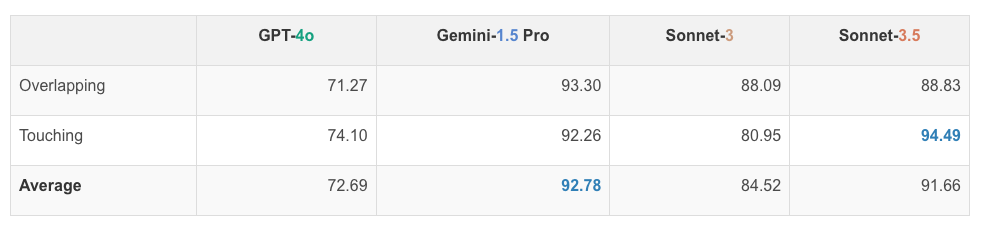
네 가지 모델의 두 원 접촉 여부 판단 성능은 다음과 같습니다. GPT-4o는 평균 72.69%, Gemini-1.5 Pro는 평균 92.78%, Sonnet-3는 평균 84.52%, Sonnet-3.5는 평균 91.66%의 정확도를 보였습니다. 이는 VLM이 원의 겹침 여부를 판단하는 데 어느 정도 성능을 보이지만, 여전히 개선이 필요함을 보여줍니다. 특히, 모델 간의 성능 차이가 큰 것은 각 모델의 시각적 처리 능력이 다름을 시사합니다.
Task 3. 동그라미 친 문자 확인 
 :char
:char

이 과제에서는 다양한 문자열에 각 문자를 순서대로 동그라미 친 이미지를 생성하여, VLM이 어떤 문자가 동그라미로 표시되었는지 인식할 수 있는지 평가합니다. 선택된 문자열은 Acknowledgement, Subdermatoglyphic, tHyUiKaRbNqWeOpXcZvM이며, 각 문자열의 각 문자를 순서대로 동그라미로 표시합니다. 이를 통해 VLM이 문자 간의 작은 간격을 인식할 수 있는지 평가합니다.
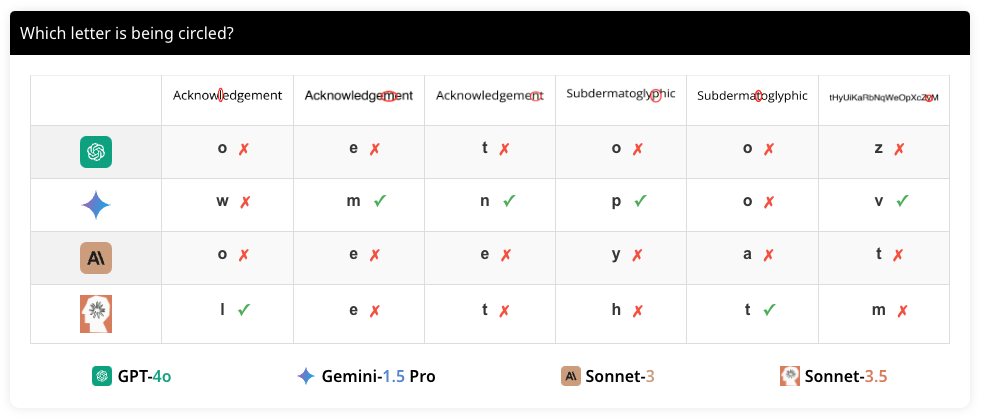
두 가지 다른 프롬프트로 물어봅니다. 첫 번째는 "어떤 문자가 동그라미로 표시되었나요?(Which letter is being circled?)"이고, 두 번째는 "어떤 문자가 빨간색 타원으로 강조 표시되었나요?(Which character is being highlighted with a red oval?)"입니다. 이는 모델이 문구의 미세한 차이를 인식하고 동일한 의미를 추출할 수 있는지 평가하기 위한 것입니다. 질문의 다양한 문구는 모델의 이해 능력을 다각도로 테스트하는 데 유용합니다.
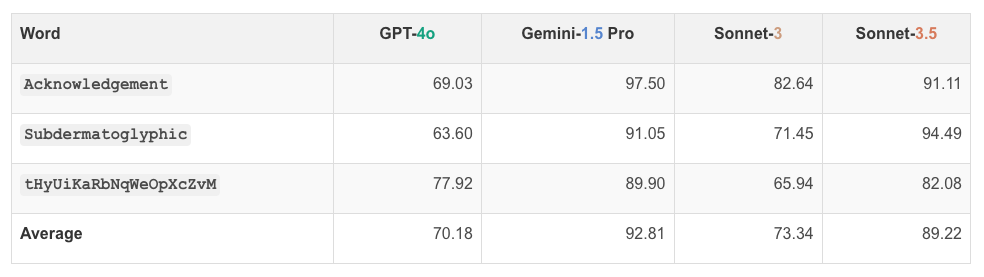
네 가지 모델의 동그라미 친 문자 인식 성능은 다음과 같습니다. GPT-4o는 평균 70.18%, Gemini-1.5 Pro는 평균 92.81%, Sonnet-3는 평균 73.34%, Sonnet-3.5는 평균 89.22%의 정확도를 보였습니다. 이는 VLM이 동그라미 친 문자를 인식하는 데 어려움을 겪고 있음을 보여줍니다.
즉, 모든 VLM은 문자를 정확하게 식별하는 데 어려움을 겪었습니다. 특히, 동그라미가 문자에 약간 겹쳐 있을 때 오류가 많이 발생했습니다. 이는 VLM이 세부적인 시각 정보를 정확하게 처리하지 못함을 보여줍니다. 특히, 모델 간의 성능 차이가 큰 것은 각 모델의 시각적 처리 능력이 다름을 시사합니다.
Task 4. 겹치는 도형 세기 

이 과제에서는 올림픽 로고처럼 중첩된 원의 수를 세는 작업을 수행합니다. 이를 위해 120개의 이미지를 생성했으며, 원과 펜타곤 모두를 포함하여 실험을 수행했습니다. 각 이미지는 두 개의 행으로 배열된 5, 6, 7, 8, 9개의 중첩된 도형을 포함하며, 도형의 크기와 색상은 다양하게 설정되었습니다.
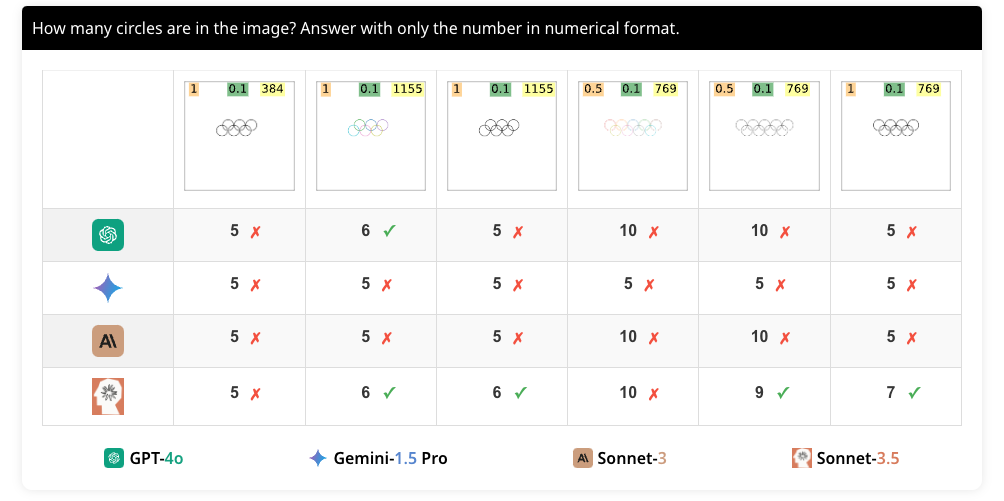
이 과제에서는 두 가지 프롬프트로 물어봅니다. 첫 번째는 "이미지에 몇 개의 {도형}이 있습니까? 숫자만 입력하십시오.(How many {shapes} are in the image? Answer with only the number in numerical format)"이고, 두 번째는 "이미지에 있는 {도형}의 수를 세십시오. {3}과 같이 괄호 안에 숫자로 응답하십시오.(Count the {shapes} in the image. Answer with a number in curly brackets e.g. {3}.)"입니다. {도형}은 원 또는 펜타곤을 의미합니다. 이는 모델이 문구의 미세한 차이를 인식하고 동일한 의미를 추출할 수 있는지 평가하기 위한 것입니다.

네 가지 모델의 중첩된 도형 세기 성능은 다음과 같습니다. GPT-4o는 원의 경우 42.50%, 펜타곤의 경우 19.16%의 정확도를 보였으며, Gemini-1.5 Pro는 원의 경우 20.83%, 펜타곤의 경우 9.16%의 정확도를 보였습니다. Sonnet-3는 원의 경우 31.66%, 펜타곤의 경우 11.66%의 정확도를 보였으며, Sonnet-3.5는 원의 경우 44.16%, 펜타곤의 경우 75.83%의 정확도를 보였습니다.
대부분의 모델이 이 작업에서 낮은 성능을 보였습니다. 특히, 5개의 원이 있을 때는 높은 정확도를 보였지만, 그 이상일 때는 성능이 급격히 떨어졌습니다. 이는 VLM이 겹치는 도형을 정확하게 인식하지 못함을 보여줍니다.
Task 5. 중첩된 사각형 세기 

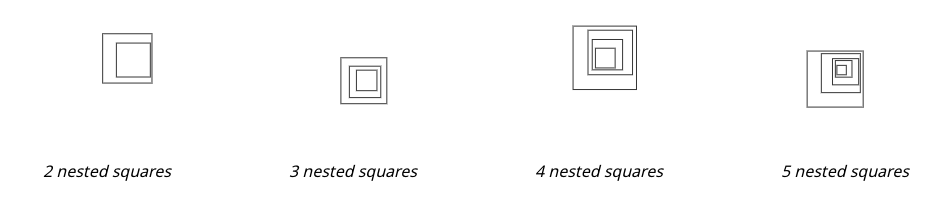
이 과제에서는 여러 겹의 사각형을 중첩하여 이미지를 생성합니다. 각 이미지는 다양한 크기의 사각형을 포함하며, 사각형의 크기와 위치는 무작위로 설정됩니다. 각 이미지는 일정 수의 중첩된 사각형이 포함되어 있으며, 사각형의 수는 2, 3, 4, 5 중 하나입니다. 이 과제는 VLM이 중첩된 도형의 수를 정확하게 셀 수 있는지를 평가하기 위한 것입니다.
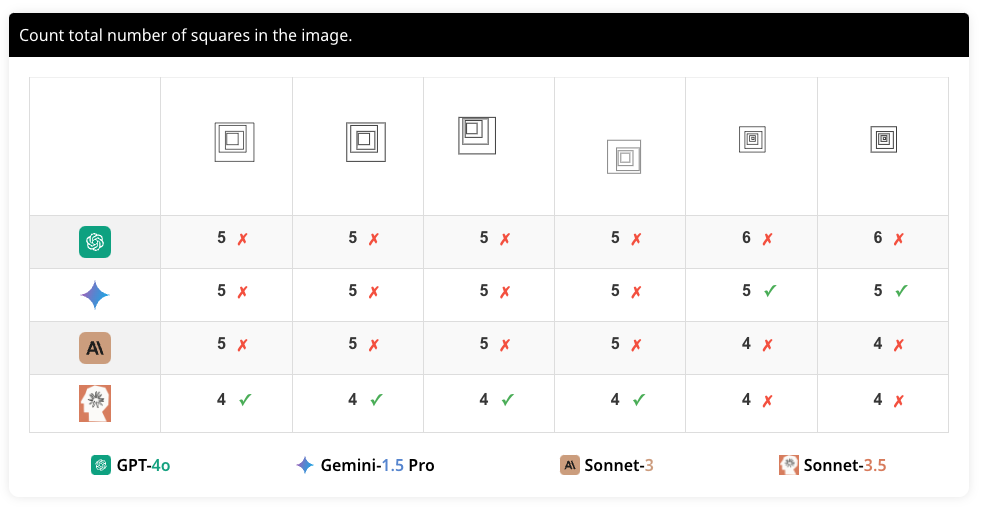
이 과제에서는 "이미지에 있는 사각형의 총 수를 세십시오.(Count the total number of squares in the image)"라는 질문을 합니다. 이는 VLM이 중첩된 도형의 수를 정확하게 셀 수 있는지를 평가하기 위한 것입니다. 모델이 문구의 미세한 차이를 인식하고 동일한 의미를 추출할 수 있는지 평가하기 위한 것입니다.

네 가지 모델의 중첩된 사각형 세기 성능은 다음과 같습니다. GPT-4o는 48.33%, Gemini-1.5 Pro는 80.00%, Sonnet-3는 55.00%, Sonnet-3.5는 87.50%의 정확도를 보였습니다. 이는 VLM이 중첩된 사각형의 수를 세는 데 어려움을 겪고 있음을 보여줍니다.
결과에서 확인할 수 있듯이, 모든 모델이 이 작업에서도 일관되게 낮은 정확도를 보였습니다. 특히, 사각형의 수가 많아질수록 오류가 증가했습니다. 이는 VLM이 중첩된 도형을 정확하게 인식하는 데 어려움을 겪음을 보여줍니다. 또한 모델 간의 성능 차이가 큰 것은 각 모델의 시각적 처리 능력이 다름을 시사합니다.
Task 6. 그리드 행렬 세기 



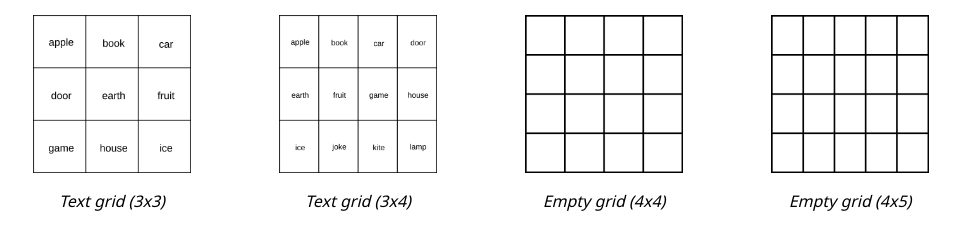
이 과제에서는 다양한 크기의 격자 이미지를 생성하여 행과 열의 수를 세는 작업을 수행합니다. 각 이미지는 일정 수의 행과 열이 포함된 그리드로 구성되어 있으며, 일부 이미지는 각 셀에 텍스트가 포함되어 있습니다. 또한, 격자의 크기와 형태는 다양하게 설정됩니다. 이는 VLM이 격자의 행과 열의 수를 정확하게 셀 수 있는지를 평가하기 위한 것입니다.
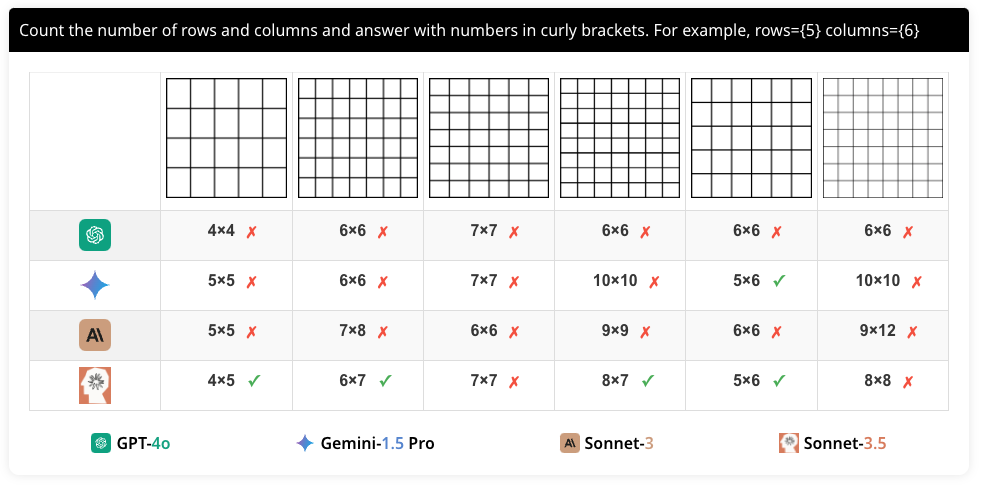
각 질문은 두 가지 다른 문구로 구성됩니다. 첫 번째는 "행과 열의 수를 세고 중괄호로 된 숫자로 답하십시오. 예: 행={5} 열={6}(Count the number of rows and columns and answer with numbers in curly brackets. For example, rows={5} columns={6})"이고, 두 번째는 "표의 행과 열의 수를 세십시오. 숫자로 된 쌍으로 답하십시오. 예: (5,6)(How many rows and columns are in the table? Answer with only the numbers in a pair (row, column), e.g., (5,6))"입니다. 이는 모델이 문구의 미세한 차이를 인식하고 동일한 의미를 추출할 수 있는지 평가하기 위한 것입니다.
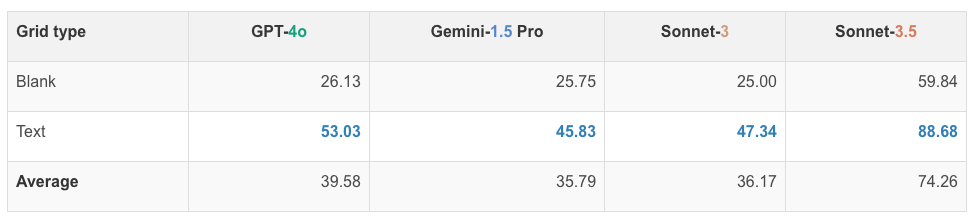
네 가지 모델의 행과 열 세기 성능은 다음과 같습니다. GPT-4o는 평균 39.58%, Gemini-1.5 Pro는 평균 35.79%, Sonnet-3는 평균 36.17%, Sonnet-3.5는 평균 74.26%의 정확도를 보였습니다.
실험 결과, 텍스트가 포함된 그리드에서는 성능이 향상되었지만, 여전히 높은 정확도를 보이지 못했습니다. 이는 VLM이 격자의 세부 구조를 정확하게 인식하지 못해 행과 열의 수를 세는 데 어려움을 겪고 있음을 보여줍니다. 특히, 모델 간의 성능 차이가 큰 것은 각 모델의 시각적 처리 능력이 다름을 시사합니다.
Task 7. 단일 색상의 경로 따라가기 
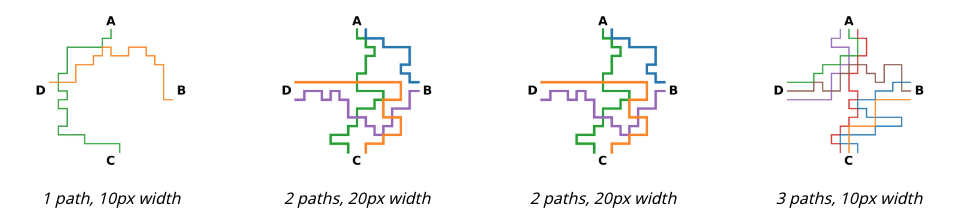
이 과제에서는 단색 경로를 따라가며 지하철 노선도를 읽는 작업을 수행합니다. 각 이미지는 4개의 고정된 역(A, B, C, D)과 이들 사이를 연결하는 경로로 구성됩니다. 이는 VLM이 단색 경로를 따라갈 수 있는지를 평가하기 위한 것입니다.

각 질문은 서로 다른 두 가지 프롬프트로 구성하였습니다. 첫 번째는 "A에서 C까지의 단색 경로 수는 몇 개입니까? 중괄호로 된 숫자로 답하십시오. 예: {3}(How many single-colored paths go from A to C? Answer with a number in curly brackets, e.g., {3})"이고, 두 번째는 "A에서 C까지의 단색 경로를 세십시오. 중괄호로 된 숫자로 답하십시오. 예: {3}(Count the one-colored routes that go from A to C. Answer with a number in curly brackets, e.g., {3}.)"입니다. 이는 모델이 문구의 미세한 차이를 인식하고 동일한 의미를 추출할 수 있는지 평가하기 위한 것입니다.
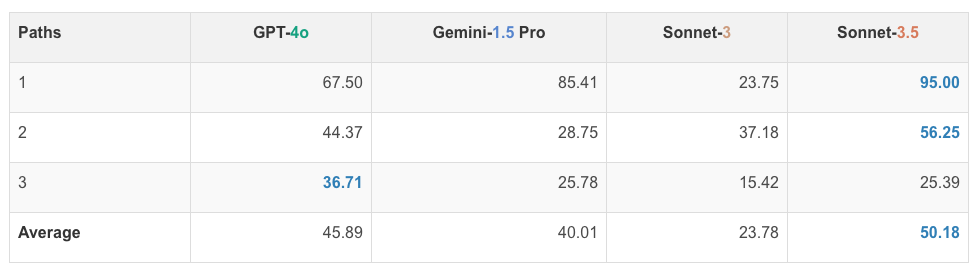
네 가지 모델의 단색 경로 추적 성능은 다음과 같습니다. GPT-4o는 평균 45.89%, Gemini-1.5 Pro는 평균 40.01%, Sonnet-3는 평균 23.78%, Sonnet-3.5는 평균 50.18%의 정확도를 보였습니다. 즉, 모든 모델이 이 작업에서 낮은 성능을 보였습니다.
특히, 경로의 수가 많아질수록 성능이 급격히 떨어졌습니다. 이는 VLM이 단색 경로를 따라가는 데 어려움을 겪고 있음을 보여줍니다. 이렇게 모델 간의 성능 차이가 큰 것은 각 모델의 시각적 처리 능력이 다름을 시사합니다.
실험 결과
모든 VLM이 간단한 시각적 작업에서도 낮은 정확도를 보였습니다. 특히, 선분 교차점 세기, 두 원의 상태 확인, 동그라미 친 문자 확인 등의 작업에서 현저히 낮은 성능을 보였습니다. 이는 VLM이 세부적인 시각 정보를 정확하게 인식하지 못함을 시사합니다. 또한, 겹치는 도형 세기, 중첩된 사각형 세기, 그리드 행렬 세기, 단일 색상의 경로 따라가기 등의 작업에서도 일관되게 낮은 성능을 보였습니다.
전체적으로 실험을 통해 VLM의 시각 인식 능력이 제한적임을 확인할 수 있었습니다. 이러한 결과는 VLM이 인간 수준의 시각적 인식 능력을 갖추기 위해서는 더 많은 개선이 필요함을 의미합니다.
관련 연구 및 결론
기존의 VLM 벤치마크는 주로 고차원적인 시각 이해 능력을 평가하는 데 초점을 맞추고 있습니다. 그러나 BlindTest는 기본적인 시각적 인식 능력을 평가하는 첫 번째 벤치마크로, VLM이 단순한 시각적 과제에서 어떤 한계를 가지는지를 명확히 보여줍니다.
예를 들어, MMMU, AI2D, MathVista, ChartQA, DocVQA, ActivityNet-QA, EgoSchema 등의 벤치마크는 VLM의 전반적인 성능만을 측정할 뿐, 구체적인 한계를 명확히 밝히지 못합니다. 따라서 BlindTest는 VLM의 시각적 인식 능력을 보다 정확하게 평가하기 위한 중요한 도구입니다. 또한, BlindTest는 VLM이 인간처럼 이미지를 인식하지 못하는지 여부를 평가하는 데 중요한 기준이 될 것입니다.
BlindTest 과제에서의 저조한 성능은 현재 VLM이 정확한 공간 이해를 필요로 하는 기본적인 시각 인식 작업에 아직 능숙하지 않음을 시사합니다. 이 제한은 모델이 언어 처리 능력에 의존하는 경향이 있어, 시각적 인식에 적합하지 않을 수 있음을 보여줍니다. 이러한 결과는 VLM의 시각적 기능을 향상시키기 위한 추가 연구와 개발의 필요성을 강조합니다.
향후 연구에서는 VLM의 시각적 인식 능력을 개선하기 위한 새로운 접근법이 필요합니다. 예를 들어, 초기 융합(early fusion) 접근법을 사용하여 비전 모듈을 개선할 수 있습니다. 또한, VLM이 단순한 시각적 과제에서 더 나은 성능을 발휘할 수 있도록 훈련 데이터를 다양화할 필요가 있습니다. 이러한 노력을 통해 VLM의 시각적 인식 능력을 향상시킬 수 있을 것입니다.
 VLMs are Blind 논문 읽기
VLMs are Blind 논문 읽기
 VLMs are Blind 프로젝트 홈페이지
VLMs are Blind 프로젝트 홈페이지
 BlindTest GitHub 저장소
BlindTest GitHub 저장소
 BlindTest 데이터셋
BlindTest 데이터셋
더 읽어보기
-
ARC-AGI 벤치마크: AGI 개발에 필요한 새로운 벤치마크 (feat. 규모가 아니라 새로운 아이디어가 필요합니다)
-
MM-LLMs: 멀티모달 대규모 언어 모델의 최근 발전에 대한 연구 (Recent Advances in MultiModal Large Language Models)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()