
Wan2.2 및 Wan 플랫폼(wan.video) 소개
최근 생성형 인공지능 기술은 텍스트, 이미지 생성에서 나아가 비디오 생성(Video Generation) 분야까지 급속히 확장되고 있습니다. 이러한 흐름 속에서 Wan2.2는 텍스트 기반 영상 생성뿐 아니라 이미지, 또는 텍스트와 이미지를 동시에 활용한 복합 입력 비디오 생성까지 지원하는 다기능 오픈소스 모델로서 높은 주목을 받고 있습니다. 이 모델은 알리바바(Alibaba) 의 연구팀이 개발한 것으로, 산업 및 학술 연구 목적 모두를 고려한 실용성과 확장성을 갖추고 있으며, Wan이라는 브랜드 아래 강력한 생성형 AI 서비스 플랫폼에 통합되어 제공되고 있습니다.
Wan2.2는 전작인 Wan2.1에서의 아키텍처, 성능, 해상도, 속도 등 전반적인 요소들을 대폭 강화하였으며, Mixture-of-Experts (MoE) 구조, 고해상도 생성 능력, 영화와 같은 미학 표현력(Cinematic-level Aesthetics), 고압축 VAE 기반 생성기 등의 주요 기술적 진보를 담고 있습니다. 이와 더불어 Hugging Face, ModelScope, ComfyUI 등과의 통합을 통해 누구나 손쉽게 사용할 수 있도록 설계되어 있어 진입 장벽도 낮습니다.
또한 Wan 플랫폼(wan.video) 은 생성형 AI를 누구나 쉽게 사용할 수 있는 방향으로 설계된 종합형 AI 콘텐츠 생성 서비스로, 텍스트-이미지, 이미지 편집, 동영상 생성 등 다양한 작업을 단일 인터페이스 내에서 처리할 수 있도록 구성되어 있습니다. 이 플랫폼은 알리바바의 AI 기술과 클라우드 인프라가 결합된 실시간 콘텐츠 생성 도구로, Wan2.2 모델을 중심으로 다양한 서비스가 구성됩니다.
Wan2.2와 다른 모델과의 비교
Wan2.2는 전작인 Wan2.1 및 다양한 상용 비공개 모델들과 비교해 다음과 같은 주요 차별점을 갖습니다:
- 모델 아키텍처: Wan2.2는 MoE 아키텍처를 채택하여 계산 비용은 유지하면서도 파라미터 수를 늘려 표현력을 향상시켰습니다. 이는 기존의 단일 모델 아키텍처 대비 구조적인 확장을 이뤄낸 사례입니다.
- 해상도 및 속도: 720P@24fps 기준에서 Wan2.2는 현재까지 공개된 비디오 생성 모델 중 가장 빠른 처리 속도를 보여주고 있습니다.
- 학습 데이터: 기존보다 이미지 수는 65.6%, 비디오 수는 83.2% 증가한 데이터셋으로 학습되어, 동작 표현, 의미적 표현, 미학적 품질 모두 향상된 결과물을 생성합니다.
- 기능 통합: 텍스트-비디오, 이미지-비디오, 텍스트+이미지-비디오까지 세 가지 모드를 단일 프레임워크 내에서 지원합니다.
Wan2.2의 주요 기술적 특성
Mixture-of-Experts (MoE) 기반 구조

Wan2.2 모델의 가장 핵심적인 부분은 MoE(Mixture-of-Experts) 구조입니다. 이는 최근 LLM에서도 활용되는 방식으로, Wan2.2에서는 각기 다른 노이즈 수준에 특화된 전문가 모델을 활용합니다. 노이즈 레벨이 높은 초기 단계에서는 레이아웃에 초점을 둔 High-Noise Expert를, 후반부의 노이즈 레벨이 낮은 정제 단계에서는 디테일을 정교화하는 Low-Noise Expert를 적용함으로써 총 파라미터 수는 27B이지만 실행 시엔 14B만 활성화되어 GPU 리소스를 효율적으로 사용합니다. 이 구조는 SNR(Signal-to-Noise Ratio) 기준으로 각 전문가를 동적으로 호출하는 전략을 적용하여, 복잡한 장면 구성과 디테일한 마무리를 효과적으로 수행할 수 있습니다.
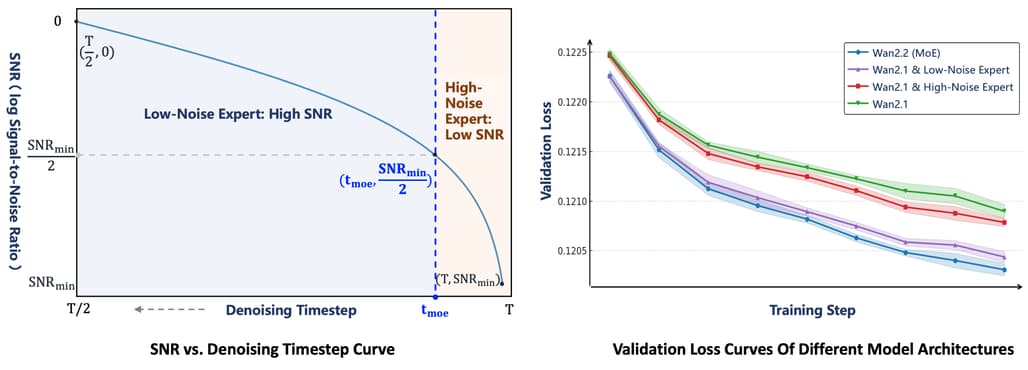
이러한 MoE 구조의 효과는 LLM에서도 효율성과 품질 향상의 핵심 구조로 검증된 방식으로, Wan2.2에서는 영상 생성 과정에 처음으로 본격 도입하여 검증 손실(Validation Loss)을 통해서도 입증되었습니다. 특히, Wan2.1 단독 모델 대비, 고노이즈, 저노이즈 전용 Expert를 활용한 조합, 그리고 최종 Wan2.2(MoE) 버전 모두 점진적인 성능 향상이 나타났습니다.
고압축 VAE 기반 고해상도 모델 (TI2V-5B)
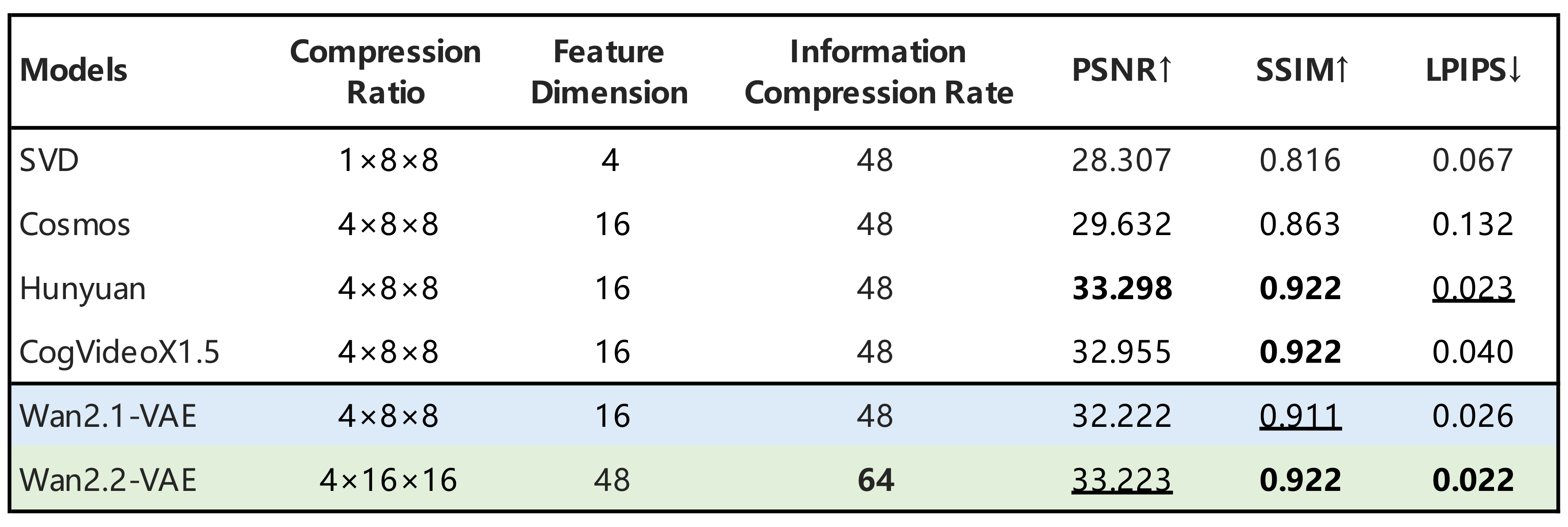
Wan2.2는 또한 5B 모델을 기반으로 한 고압축 VAE 구조인 Wan2.2-VAE를 채택한 TI2V-5B 모델을 탑재하여 고해상도 비디오 생성을 빠르게 수행할 수 있습니다. TI2V-5B 모델은 16x16x4 또는 32x32x4 수준의 압축률을 적용한 VAE를 사용하며, 텍스트-이미지-비디오 통합 프레임워크로 동작합니다.
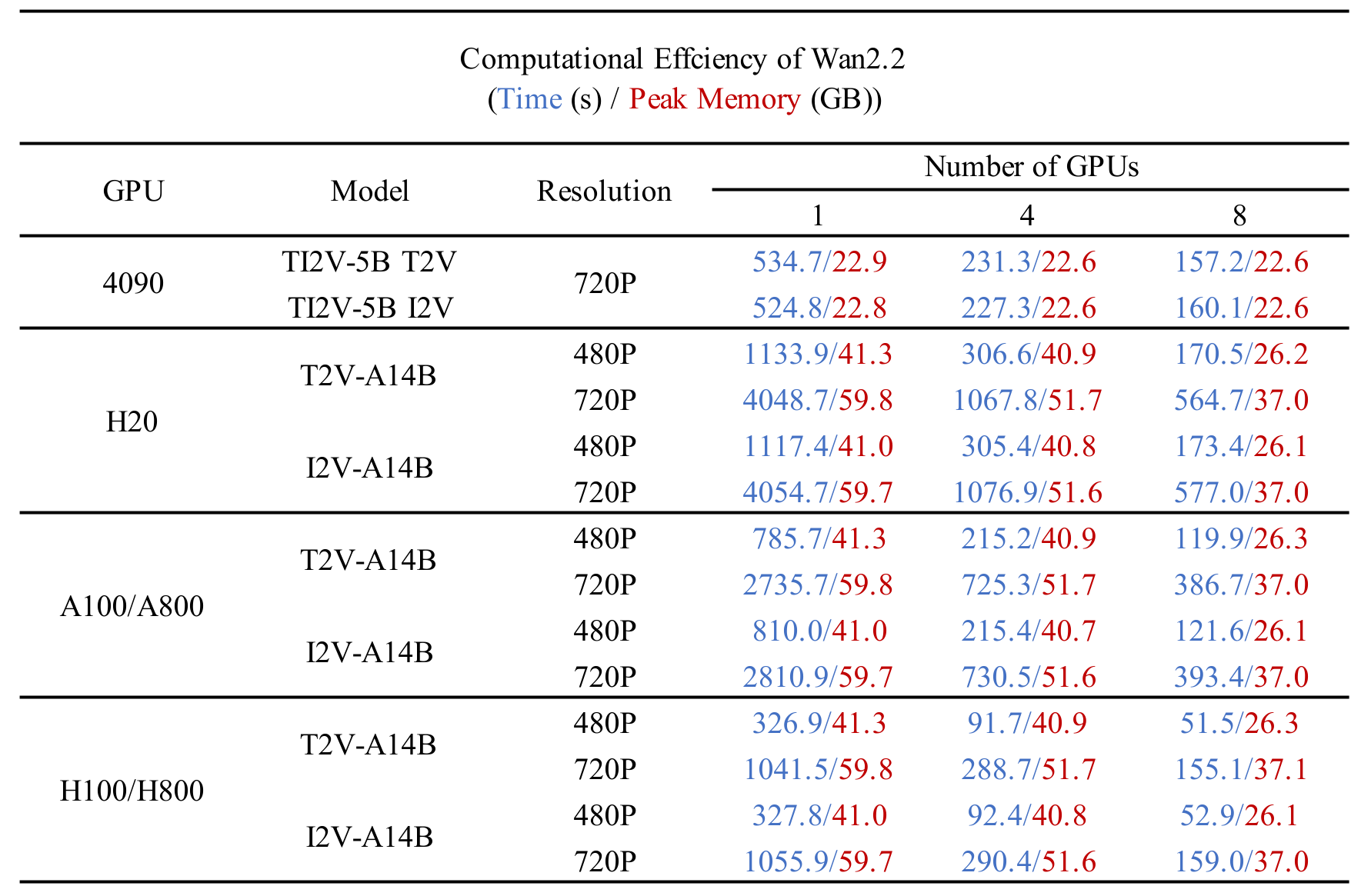
이는 고화질 비디오(720P) 5초 분량을 소비자용 GPU(RTX 4090)에서 9분 이내에 생성할 수 있도록 설계되었습니다. 이러한 소비자용 GPU에서 고해상도 비디오 생성이 가능한 점은 학계뿐 아니라 크리에이티브 산업에서도 실질적인 활용 가능성을 열어줍니다.
시네마틱 스타일 미학과 커스텀 생성
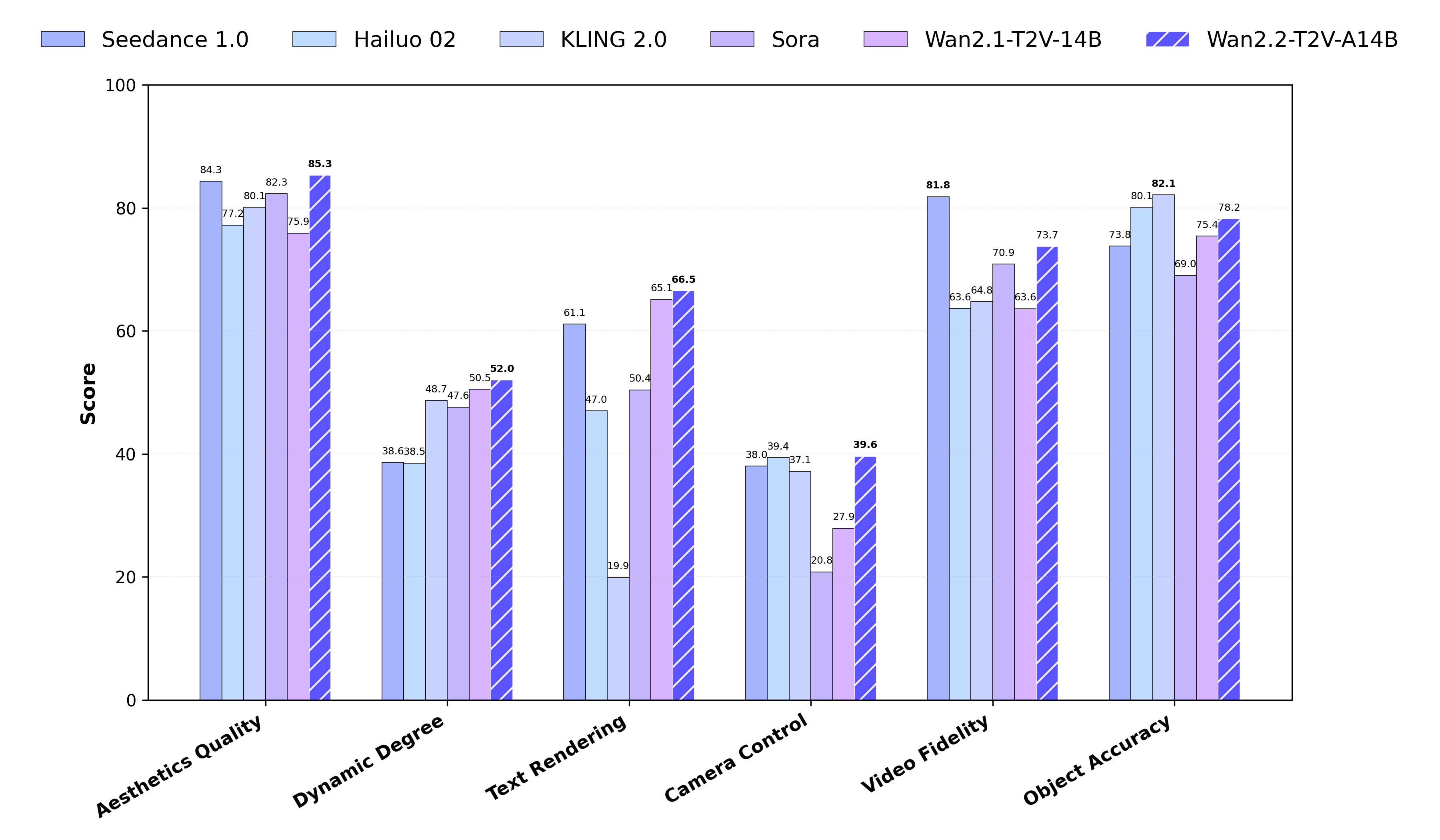
Wan2.2는 단순히 비디오를 생성하는 것을 넘어서, 조명, 구도, 색조, 명암 등 세부 미학 요소가 라벨링된 데이터셋을 활용하여 훈련되었습니다. 이를 통해 영상의 스타일을 보다 정교하게 제어할 수 있으며, 사용자 정의 기반 시네마틱 연출이 가능해집니다. 이는 영화 스타일 영상, 광고, 뮤직비디오 등에 활용할 수 있는 기술력을 의미합니다.
다양한 실행 옵션 및 환경 지원
Wan2.2는 Hugging Face, ModelScope와 같은 플랫폼에서 손쉽게 모델 다운로드가 가능하며, 아래와 같이 텍스트와 이미지, 또는 텍스트+이미지 모두를 입력으로 활용할 수 있습니다:
- 텍스트 → 비디오 (T2V)
- 이미지 → 비디오 (I2V)
- 텍스트 + 이미지 → 비디오 (TI2V)
이외에도 프롬프트 확장 기능(prompt extension)을 통해 더 풍부한 표현을 자동 생성하거나, Dashscope API 또는 로컬 Qwen 모델을 사용하여 프롬프트 자동 확장을 수행할 수 있습니다. 또한 단일 GPU와 멀티 GPU 환경 모두에서 실행 가능하며, FSDP, DeepSpeed Ulysses, FlashAttention 등 최신 분산 추론 최적화 기술도 지원합니다.
그 외에도 모델 실행 예시, 프롬프트 확장 방법, 멀티 GPU 설정, 실행 명령어 등은 매우 상세히 문서화되어 있어 실습 중심의 사용자에게도 진입 장벽이 낮습니다.
Wan 모델 설치 및 실행 가이드
모델 코드 및 실행을 위한 필요 라이브러리 설치
먼저, Wan2.2 GitHub 저장소를 복제합니다:
git clone https://github.com/Wan-Video/Wan2.2.git
cd Wan2.2
이후, 모델 실행에 필요한 의존성을 설치합니다:
pip install -r requirements.txt
이 때, PyTorch는 2.4 이상의 버전을 설치해야 하며, Flash Attention 패키지(flash_attn) 설치 중 실패하는 경우, 다른 패키지들을 먼저 설치한 뒤, 따로 설치해주세요.
Wan 모델 다운로드
다음 표는 모델별 기능, 지원 해상도, 링크 정보를 정리한 것입니다:
| 모델명 | 설명 | 해상도 | HuggingFace | ModelScope |
|---|---|---|---|---|
| T2V-A14B | 텍스트→비디오, MoE 기반 | 480P, 720P | 링크 | 링크 |
| I2V-A14B | 이미지→비디오, MoE 기반 | 480P, 720P | 링크 | 링크 |
| TI2V-5B | 텍스트+이미지→비디오, 고압축 VAE | 720P@24fps | 링크 | 링크 |
모델 다운로드는 위 링크를 눌러 다운로드 받을 수 있으며, 서버 환경에서 바로 받기 위해서는 다음과 같이 Hugging Face CLI 를 사용할 수 있습니다:
# Hugging Face CLI 설치
pip install "huggingface_hub[cli]"
# ./Wan2.2-T2V-A14B 디렉토리에 Wan2.2-T2V-A14B 모델 다운로드
huggingface-cli download Wan-AI/Wan2.2-T2V-A14B --local-dir ./Wan2.2-T2V-A14B
모델 실행 방법
TI2V‑5B 모델은 24GB VRAM 수준의 GPU(예: RTX 4090)에서도 단일 GPU 실행이 가능하지만, A14B 시리즈의 경우에는 80GB 이상의 VRAM이 필요하므로, 환경에 맞는 모델 선택이 중요합니다.
다음은 다양한 입력 형식 및 GPU 환경에 따른 실행 예시입니다:
-
하나의 GPU에서 텍스트로부터 비디오를 생성(T2V)하는 모델을 실행하는 경우:
python generate.py --task t2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-T2V-A14B --offload_model True --convert_model_dtype --prompt "두 마리 고양이가 링 위에서 복싱하는 장면" -
하나의 GPU에서 이미지로부터 비디오를 생성(I2V)하는 모델을 실행하는 경우:
python generate.py --task i2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-I2V-A14B --image examples/i2v_input.JPG --offload_model True --convert_model_dtype --prompt "해변에 앉아 선글라스를 낀 고양이" -
하나의 GPU에서 텍스트와 이미지로부터 비디오를 생성(TI2V)하는 모델을 실행하는 경우:
python generate.py --task ti2v-5B --size 1280*704 --ckpt_dir ./Wan2.2-TI2V-5B --image examples/i2v_input.JPG --offload_model True --convert_model_dtype --t5_cpu --prompt "여름 바닷가에서 서핑보드에 앉아있는 고양이" -
여러 GPU들에서 실행하는 경우(예: FSDP + DeepSpeed):
torchrun --nproc_per_node=8 generate.py --task t2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-T2V-A14B --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "두 고양이가 링 위에서 복싱하는 장면"
또는, 다음과 같은 방식으로 Diffusers 연동이 가능합니다:
from diffusers import WanPipeline, AutoencoderKLWan, UniPCMultistepScheduler
pipe = WanPipeline.from_pretrained("Wan-AI/Wan2.2-TI2V-5B-Diffusers", torch_dtype=torch.bfloat16)
# ...(생략)...
export_to_video(output.frames[0], "output.mp4", fps=24)
--use_prompt_extend 옵션을 통해 Dashscope API 또는 로컬 Qwen 모델로 프롬프트를 자동 확장할 수 있으며, 이를 통해 영상의 세부 디테일과 표현력이 크게 향상됩니다. 단, Dashscope API 사용 시 API Key가 필요합니다:
DASH_API_KEY=<<YOUR_API_KEY>> torchrun --nproc_per_node=8 generate.py --task t2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-T2V-A14B --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage" --use_prompt_extend --prompt_extend_method 'dashscope' --prompt_extend_target_lang 'en'
더 상세한 실행 방식들은 GitHub 저장소의 README 문서 등을 참고해주세요.
OOM(Out-of-Memory) 에러 발생 시 대응
OOM 에러 발생 시 아래의 옵션을 조합하여 GPU 메모리 사용량을 줄일 수 있습니다:
| 옵션명 | 설명 |
|---|---|
--offload_model True |
일부 모델 파라미터를 CPU 메모리로 이동시켜 VRAM 사용을 줄임 |
--convert_model_dtype |
모델 파라미터를 더 적은 메모리를 사용하는 dtype(FP16 등)으로 변환 |
--t5_cpu |
T5 기반 텍스트 인코더를 GPU 대신 CPU에서 실행 |
예를 들어, 다음과 같이 실행할 수 있습니다:
python generate.py --task t2v-A14B --size 1280*720 \
--ckpt_dir ./Wan2.2-T2V-A14B \
--offload_model True \
--convert_model_dtype \
--t5_cpu \
--prompt "두 고양이가 링 위에서 복싱하는 장면"
 Wan 플랫폼
Wan 플랫폼
 Wan 논문: Wan: Open and Advanced Large-Scale Video Generative Models
Wan 논문: Wan: Open and Advanced Large-Scale Video Generative Models
 Wan2.2 모델 GitHub 저장소
Wan2.2 모델 GitHub 저장소
https://github.com/Wan-Video/Wan2.2
 Wan2.2 모델의 영상 생성 예시 및 프롬프트 사용 가이드 문서
Wan2.2 모델의 영상 생성 예시 및 프롬프트 사용 가이드 문서
 Wan2.2 모델 다운로드
Wan2.2 모델 다운로드
| 모델명 | 설명 | 해상도 | HuggingFace | ModelScope |
|---|---|---|---|---|
| T2V-A14B | 텍스트→비디오, MoE 기반 | 480P, 720P | 다운로드 | 링크 |
| I2V-A14B | 이미지→비디오, MoE 기반 | 480P, 720P | 다운로드 | 링크 |
| TI2V-5B | 텍스트+이미지→비디오, 고압축 VAE | 720P@24fps | 다운로드 | 링크 |
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()