
WaterCrawl 소개
LLM 기반 애플리케이션을 만들 때 가장 번거로운 단계 중 하나는 웹에 흩어진 정보를 모델이 읽을 수 있는 형태로 정리하는 일입니다. 일반적인 HTML 페이지에는 내비게이션 바, 광고, 푸터, 사이드바처럼 본문과 무관한 요소가 섞여 있어, 그대로 모델에 넣으면 토큰만 낭비하고 답변 품질도 떨어집니다. 직접 스크래퍼를 짜더라도 크롤링 깊이 제어, 속도 제한, 비동기 처리, 결과 저장 같은 운영 문제를 매번 다시 풀어야 합니다.
WaterCrawl은 이 과정을 하나의 플랫폼으로 묶어 웹 페이지를 크롤링하고 본문만 추출해 LLM이 바로 쓸 수 있는 데이터로 변환합니다. Python, Django, Scrapy, Celery를 기반으로 동작하며, 크롤링·검색·사이트맵 생성을 REST API 하나로 제공합니다. 추출 결과는 불필요한 태그를 걷어낸 본문 텍스트나 Markdown 형태로 받을 수 있어, 검색 인덱스 구축이나 RAG 파이프라인의 입력으로 그대로 연결됩니다.
WaterCrawl의 또 다른 축은 셀프호스트(self-hosted) 구조입니다. Docker Compose로 직접 띄울 수 있어 크롤링 대상과 결과 데이터를 외부 SaaS에 맡기지 않고 자체 인프라 안에서 관리할 수 있습니다. 여기에 Python, Node.js, Go, PHP용 클라이언트 SDK와 Dify, N8N 같은 AI/자동화 플랫폼 연동을 함께 제공해, 기존 워크플로우에 크롤링 단계를 끼워 넣기 쉽게 설계되어 있습니다.
WaterCrawl의 크롤링 파이프라인
WaterCrawl의 동작은 크게 네 단계로 이어집니다. 대상 URL을 지정하면, 설정된 범위 안에서 페이지를 크롤링하고, 본문을 추출한 뒤, 정제된 데이터로 출력합니다. 아래 그림은 이 흐름을 한눈에 정리한 것입니다.
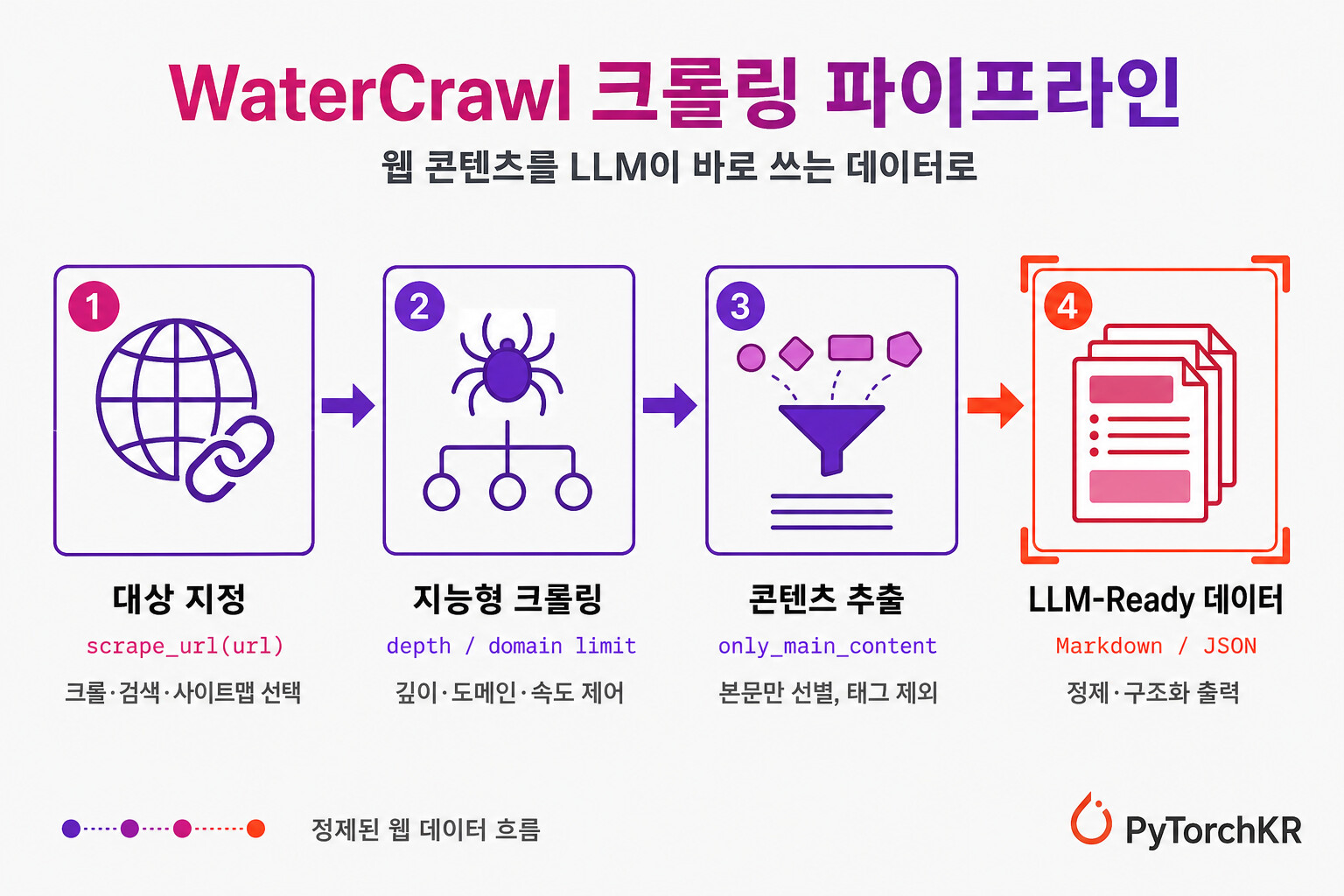
먼저 크롤링 단계에서는 시작 URL에서 관련 링크를 따라가되, 크롤링 깊이와 페이지 수 한도를 지정해 범위를 통제할 수 있습니다. 특정 도메인과 경로로 대상을 제한하고, 내장된 속도 제한(rate limiting)으로 대상 사이트에 부담을 주지 않도록 조절합니다. 공식 문서는 대상 사이트의 robots.txt 를 확인하고 존중할 것을 권장 사항으로 안내합니다.
추출 단계에서는 페이지에서 원하는 HTML 요소만 골라내고 불필요한 부분은 제외합니다. include_tags 와 exclude_tags, only_main_content 같은 옵션으로 본문 영역만 남기고 내비게이션이나 푸터를 걷어낼 수 있으며, 결과는 HTML이나 일반 텍스트 등 여러 형식으로 받을 수 있습니다. 크롤링이 진행되는 동안에는 Server-Sent Events(SSE)를 통해 처리한 페이지 수와 성공률 같은 진행 상황을 실시간으로 확인할 수 있습니다.
WaterCrawl의 주요 기능
WaterCrawl이 제공하는 기능은 단순 크롤링을 넘어 검색과 모니터링까지 포함합니다. 저장소의 README 와 공식 문서 에 정리된 핵심 기능은 다음과 같습니다.
- 크롤링과 스크래핑 : 크롤링 깊이, 속도, 대상 콘텐츠를 세밀하게 설정해 원하는 범위만 수집합니다.
- 검색 엔진 : 기본(basic), 고급(advanced), 최고(ultimate)의 세 가지 검색 깊이로 웹에서 관련 콘텐츠를 찾습니다.
- 다국어 지원 : 국가별 타기팅과 함께 여러 언어의 콘텐츠를 검색하고 크롤링합니다.
- 비동기 처리 : SSE로 크롤링과 검색 진행 상황을 실시간으로 모니터링합니다.
- REST API와 OpenAPI : 문서화된 REST API와 클라이언트 라이브러리를 제공합니다.
- 연동 생태계 : Dify, N8N 등 AI 및 자동화 플랫폼과 연결됩니다.
검색 엔진 기능은 단순히 미리 지정한 URL만 긁어오는 데 그치지 않고, 웹에서 관련 콘텐츠를 찾아 크롤링 대상으로 삼을 수 있다는 점에서 RAG용 데이터 수집과 잘 맞습니다. 개발자 연동 측면에서는 Python 클라이언트가 가장 완성도가 높고, Node.js, Go, PHP용 SDK도 함께 제공되며 Rust 클라이언트는 준비 중입니다. 외부 도구 연동으로는 Dify 플러그인 과 N8N 워크플로 노드 가 제공되고, Langflow는 풀 리퀘스트 단계, Flowise는 준비 중으로 안내되어 있습니다.
WaterCrawl 설치 및 사용법
WaterCrawl은 Docker로 직접 호스팅할 수 있습니다. 저장소를 받아 docker 디렉토리의 환경 변수 파일을 준비한 뒤 컨테이너를 띄우는 방식입니다.
git clone https://github.com/watercrawl/watercrawl.git
cd watercrawl/docker
cp .env.example .env
docker compose up -d
기본 설정으로 띄운 뒤에는 http://localhost 에서 접속할 수 있습니다. localhost가 아닌 도메인이나 IP에 배포할 때는 파일 업로드와 다운로드가 깨지지 않도록 저장소의 docker 디렉토리 의 MinIO 관련 설정(MINIO_EXTERNAL_ENDPOINT 등)을 실제 주소로 바꿔야 한다고 안내합니다. 운영 환경 배포 전 설정과 데이터베이스, MinIO 구성은 저장소의 DEPLOYMENT.md 에 정리되어 있습니다.
코드에서 크롤링을 호출할 때는 Python 클라이언트를 사용합니다. 공식 문서가 제시하는 기본 예시는 다음과 같습니다.
pip install watercrawl-py
from watercrawl import WaterCrawlAPIClient
# 클라이언트 초기화
client = WaterCrawlAPIClient('your_api_key')
# 단일 페이지 스크래핑
result = client.scrape_url(
url="https://example.com",
page_options={
"exclude_tags": ["nav", "footer"],
"include_tags": ["article", "main"],
"only_main_content": True,
},
)
위 예시는 nav 와 footer 를 제외하고 article, main 영역만 남겨 본문 위주의 결과를 얻는 설정입니다. 인증은 JWT 기반으로 처리되며, 크롤링 이벤트를 외부 시스템에 전달하는 웹훅(Webhook)도 지원합니다.
WaterCrawl의 라이선스
WaterCrawl은 WaterCrawl License 로 공개되어 있습니다. 공식 문서는 이를 "추가 조항이 붙은 수정된 MIT 라이선스(modified MIT License with additional terms)" 로 설명하며, 코드의 원 저작권 표기를 유지해야 하고 watercrawl.dev와 유사한 서비스 형태의 상업적 이용에는 별도 허가가 필요하다는 조건을 둡니다. 자유롭게 사용·수정·배포할 수 있는 오픈소스이지만 일반적인 MIT와는 차이가 있으므로, 상업적 서비스로 활용할 계획이라면 LICENSE 원문을 직접 확인하는 편이 좋습니다.
 WaterCrawl 공식 홈페이지
WaterCrawl 공식 홈페이지
 WaterCrawl 문서 사이트
WaterCrawl 문서 사이트
 WaterCrawl 프로젝트 GitHub 저장소
WaterCrawl 프로젝트 GitHub 저장소
더 읽어보기
-
AutoCLI: 웹사이트 데이터를 단일 명령어로 추출하는 초고속 AI 기반 CLI 도구 (feat. OpenCLI-rs)
-
Cloudflare, AI Bot들(Scraper&Crawler)을 한 번에 차단하는 새로운 기능 도입 (feat. AI 독립선언, AI Independence)
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다!
로 보내드립니다!
텔레그램(Telegram)이나 Slack/Discord/Teams/Dooray/GoogleChat 등으로도 새 글 알림을 받으실 수 있습니다. ![]()
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()