
Wharton 생성형 AI 연구실(GAIL, Generative AI Labs) 소개
Wharton Generative AI Labs(GAIL)는 펜실베이니아 대학교 와튼 스쿨(The Wharton School) 산하의 연구 기관으로, 생성형 AI의 기술적 발전과 비즈니스 및 교육적 활용을 연결하는 것을 목표로 합니다. 이 연구소는 단순한 이론적 연구를 넘어, 실제 프로토타입을 개발하고 엄격한 테스트를 거쳐 인간이 AI와 함께 성장하고 성공할 수 있는 방법을 모색합니다. 특히 AI가 교육과 업무 방식을 어떻게 변화시킬 수 있는지에 대해 과학적이고 실증적인 접근을 취하고 있습니다.
GAIL은 엄격한 테스트(Rigorous Testing) 를 핵심 가치로 삼습니다. AI 커뮤니티에 만연한 '검증되지 않은 프롬프트 팁(folk prompting)'이나 과대광고(hype)를 배제하고, 통계적으로 유의미한 실험을 통해 무엇이 실제로 작동하는지를 밝혀냅니다.
- Primer Initiative: 교육자를 위한 AI 도구 개발 프로젝트로, 기술적 전문 지식 없이도 맞춤형 학습 경험을 만들 수 있도록 지원합니다.
- The Studio: 학생들이 실제 작동하는 AI 프로토타입을 개발하는 프로그램입니다.
- Prompting Science Reports: 본 보고서 시리즈와 같이, 최신 LLM(Large Language Model)의 프롬프트 엔지니어링 기법을 과학적으로 검증하여 공개합니다.
Prompting Science Report 1편: 프롬프트 엔지니어링은 복잡하고 상황에 따라 다르다 (Prompt Engineering is Complicated and Contingent)

연구 개요
Prompting Science Report의 첫번째 연구는 AI 프롬프트 엔지니어링에 대한 일반적인 믿음, 예를 들어 "AI에게 예의 바르게 말하면 성능이 좋아진다"거나 "특정 형식을 지정하면 더 잘한다"는 주장이 항상 참인지 검증합니다. 실험 결과, 단일한 '매직 프롬프트'는 존재하지 않으며, 프롬프트의 효과는 사용하는 모델과 질문의 유형에 따라 크게 달라짐을 증명했습니다.
실험 방법론 (Methodology)
- 벤치마크 데이터: 박사급(PhD-level) 난이도의 과학 문제로 구성된 GPQA Diamond 데이터셋을 사용했습니다. 이는 전문가도 정답률이 65% 수준인 매우 어려운 테스트입니다.
- 모델: GPT-4o (gpt-4o-2024-08-06) 및 GPT-4o-mini를 사용했습니다.
- 실험 조건:
- 반복 측정: LLM의 답변 변동성을 고려하여, 각 질문당 100회씩 반복 테스트하여 일관성을 측정했습니다.
- 프롬프트 변형:
- Baseline (Formatted): 표준적인 시스템 프롬프트와 답변 형식을 지정한 경우.
- Unformatted: 답변 형식 지침을 제거하고 자연스럽게 질문한 경우.
- Polite: "Please answer..."와 같이 정중한 표현을 사용한 경우.
- Commanding: "I order you to..."와 같이 명령조로 말한 경우.
- 평가 지표:
- 100% Correct: 100번 시도 중 100번 모두 정답을 맞힌 비율 (무결점 기준).
- 90% Correct: 100번 중 90번 이상 정답.
- Majority (51%) Correct: 과반수 이상 정답.
주요 연구 결과
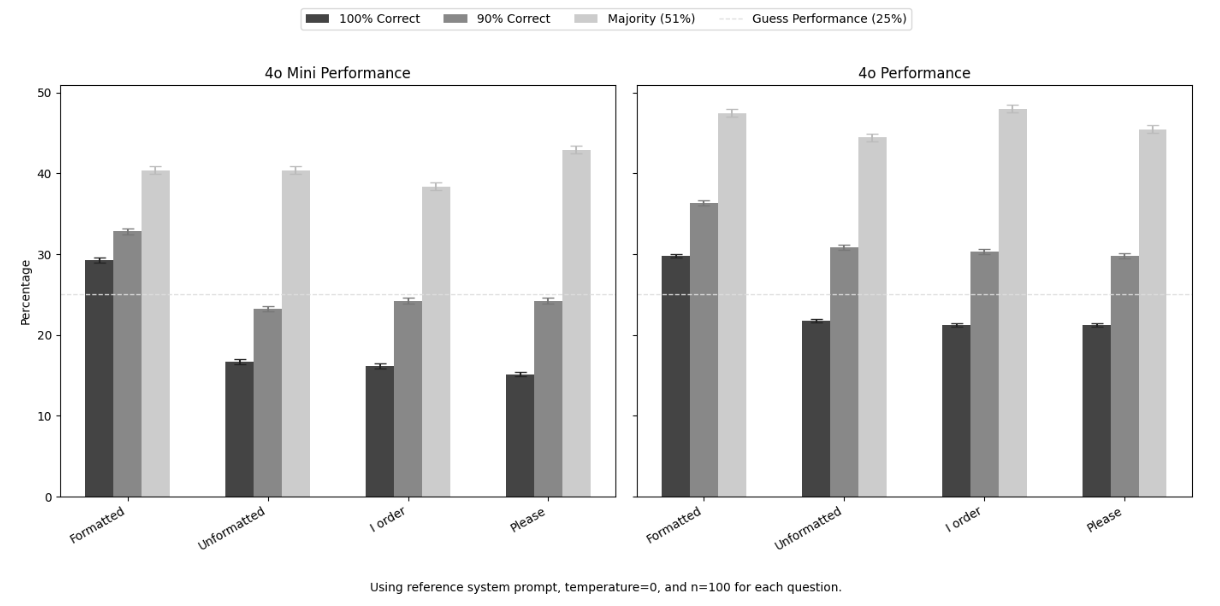
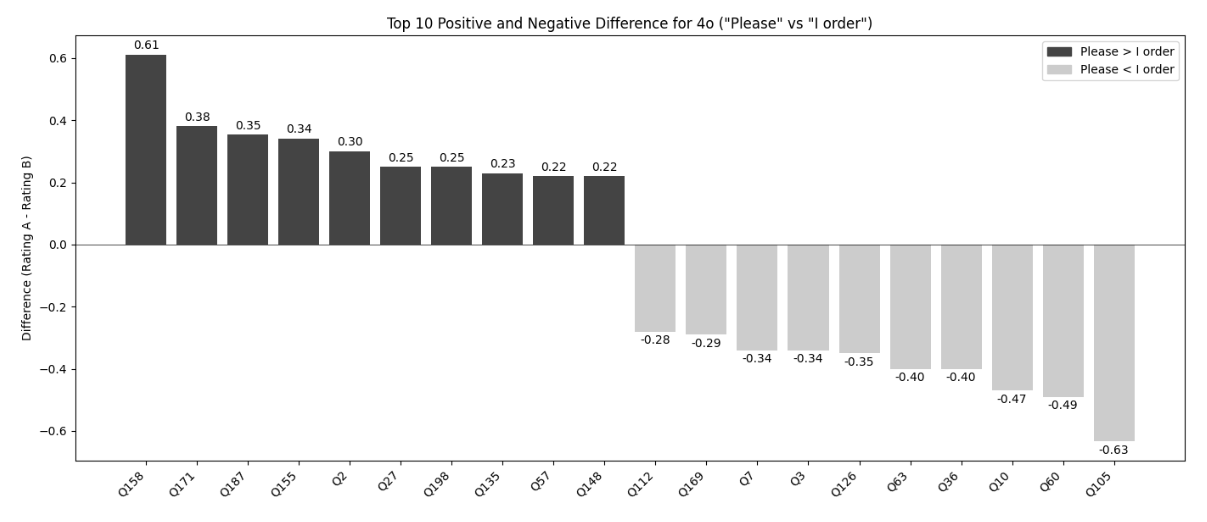
- 프롬프트 기법의 일관성 부재: "예의 바르게(Polite)" 묻는 것이 때로는 성능을 높였지만, 때로는 오히려 낮추기도 했습니다. 반대로 "명령조(Commanding)"가 더 나은 결과를 보이기도 하는 등, 특정 태도가 일관된 성능 향상을 보장하지 않았습니다.
- 형식(Formatting)의 중요성: 답변 형식을 엄격하게 지정하지 않은(Unformatted) 경우, 오히려 성능이 크게 떨어지는 경향이 나타났습니다. 특히 GPT-4o와 GPT-4o-mini 모두 형식을 지정했을 때보다 정답률이 낮아졌습니다. 이는 AI에게 명확한 출력 가이드를 주는 것이 중요함을 시사합니다.
- 높은 변동성 (Variability): 같은 질문이라도 100번 반복했을 때 AI가 항상 정답을 말하는 것은 아닙니다. 질문 수준에서는 특정 프롬프트가 통계적으로 유의미한 차이를 만들었지만(어떤 질문은 예의 바르게 물어야 맞춤), 전체 데이터셋으로 합치면 이러한 효과가 사라지거나 미미해졌습니다.
- 벤치마킹 기준의 영향: 어떤 기준(100% 정답 vs 과반수 정답)을 적용하느냐에 따라 모델의 '합격' 여부가 완전히 달라졌습니다. 엄격한 기준(100% Correct)에서는 두 모델 모두 랜덤 추측(Random Guess)과 큰 차이가 없었으나, 과반수 기준(51%)에서는 유의미한 성능을 보였습니다.
결론 및 시사점
프롬프트 엔지니어링은 "만병통치약"이 아닙니다. 비즈니스 리더나 개발자는 인터넷에 떠도는 "최고의 프롬프트"를 맹신하기보다, 자신의 구체적인 사용 사례(Use Case)와 데이터에 맞춰 직접 테스트(A/B 테스트 등) 를 수행해야 합니다. 또한, 중요한 의사결정에 AI를 사용할 때는 단 한 번의 답변만 믿기보다 여러 번 물어보고(Ensembling) 검증하는 절차가 필요합니다.
Prompting Science Report 1: Prompt Engineering is Complicated and Contingent 논문 보기
Prompting Science Report 2편: 생각의 사슬(CoT) 프롬프트 가치의 하락 (The Decreasing Value of Chain of Thought in Prompting)

연구 개요
"단계별로 생각해 봐(Think step by step)"로 대표되는 생각의 사슬(CoT, Chain of Thought) 프롬프트는 오랫동안 복잡한 문제를 해결하는 핵심 기법으로 여겨졌습니다. 하지만 최신 모델들이 자체적인 추론 능력을 갖추게 되면서, 이 기법이 여전히 유효한지를 검증했습니다.
실험 방법론
- 모델 분류:
- 비추론 모델(Non-Reasoning Models): GPT-4o, GPT-4o-mini, Claude 3.5 Sonnet, Gemini 2.0 Flash 등.
- 추론 모델(Reasoning Models): o1-mini, o3-mini (OpenAI), Gemini Flash 2.5 (Google) 등, 모델 내부에서 이미 추론 과정을 거치는 모델들.
- 프롬프트 조건:
- Direct: "설명 없이 정답만 말해(Answer directly)."
- Step by Step: "단계별로 생각해(Think step by step)."
- Default: 아무런 지시 없이 자연스럽게 질문.
- 측정: GPQA Diamond 벤치마크를 사용하여 정확도와 토큰 사용량(비용/시간) 을 비교했습니다.
주요 연구 결과
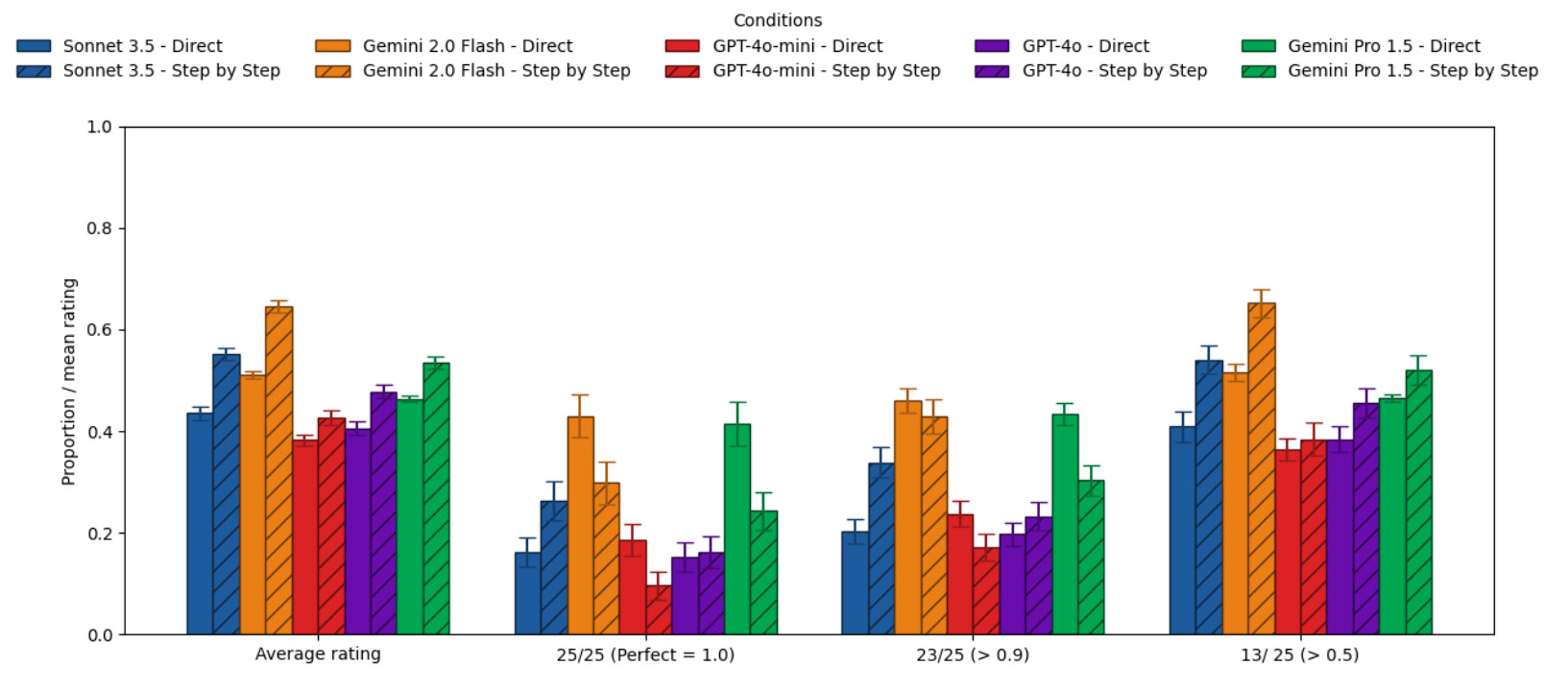
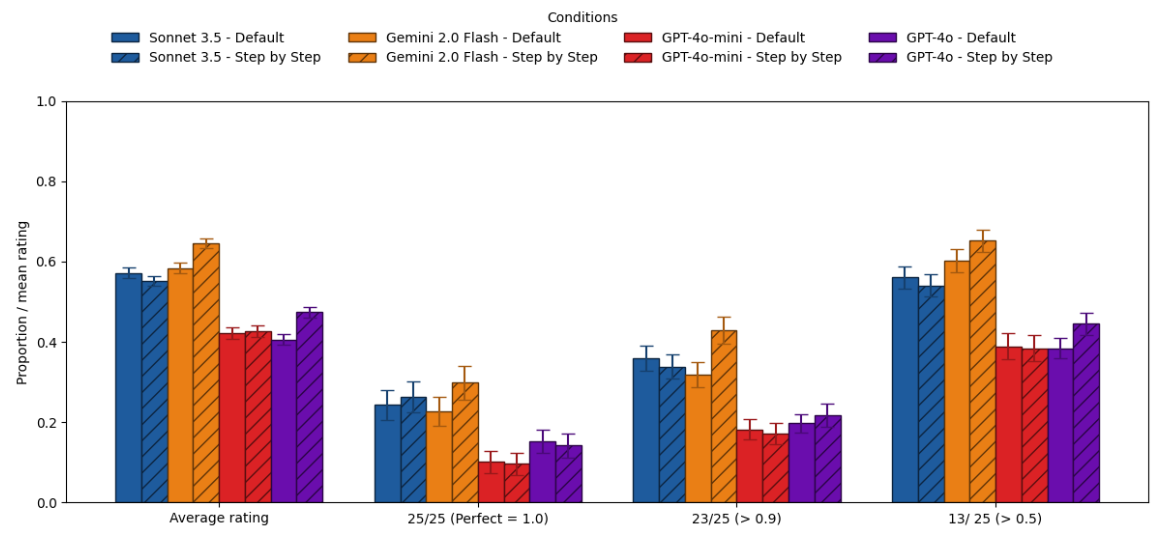
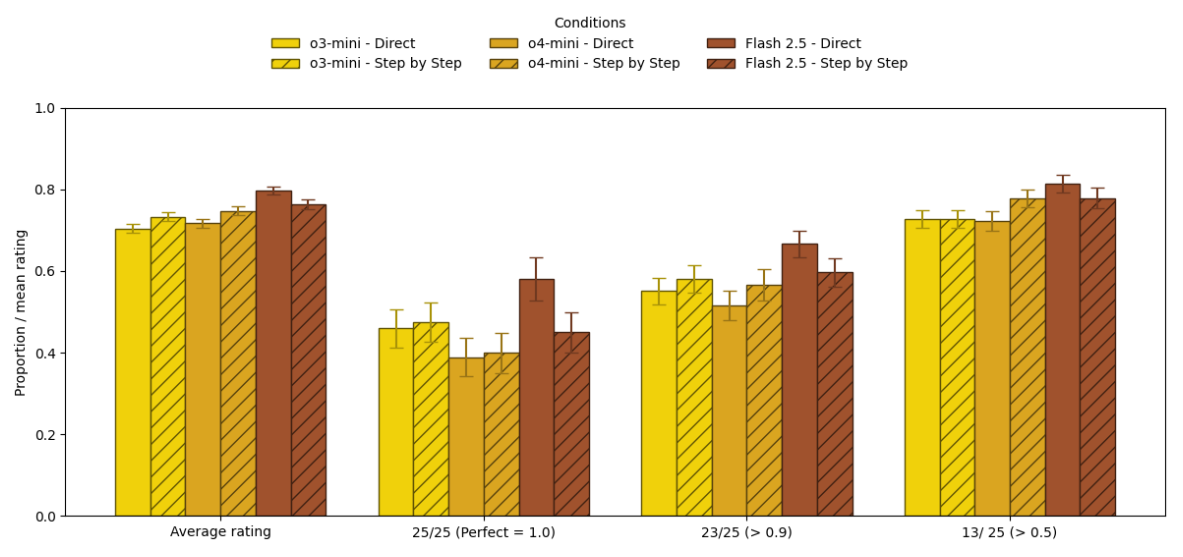
- 비추론 모델에서의 효과:
- Claude 3.5 Sonnet이나 Gemini 2.0 Flash 같은 모델은 CoT 프롬프트를 사용했을 때 평균적인 정답률이 향상되었습니다.
- 하지만 CoT는 답변의 변동성(variability) 을 높여, 모델이 평소라면 맞힐 쉬운 문제에서 엉뚱한 실수를 하게 만들기도 했습니다.
- 최신 모델들은 별도의 지시가 없어도(Default) 이미 내부적으로 어느 정도 단계적 사고를 수행하고 있어, CoT를 강제하는 효과가 예전만큼 크지 않았습니다.
- 추론 모델에서의 무용론:
- o1, o3와 같은 추론 특화 모델들은 사용자가 "단계별로 생각하라"고 지시해도 성능 향상이 거의 없거나 미미했습니다.
- 오히려 Gemini Flash 2.5의 경우 CoT를 강제하면 성능이 소폭 하락하기도 했습니다.
- 비용 및 시간 문제: CoT를 사용하면 추론 과정이 출력되므로 토큰 사용량이 급증하고 응답 시간이 길어집니다. 비추론 모델의 경우 35~600% 더 긴 시간이 소요되었습니다. 추론 모델에서도 비용 대비 효과가 매우 낮았습니다.
결론 및 시사점
최신 AI 모델, 특히 'Reasoning' 모델을 사용할 때는 CoT 프롬프트를 맹목적으로 추가할 필요가 없습니다. 이는 비용과 시간만 낭비할 가능성이 높습니다. 구형 모델이나 작은 모델(GPT-4o-mini 등)을 사용할 때는 여전히 유효할 수 있으나, 최신 모델에서는 AI가 알아서 생각하도록 두는 것이 더 효율적일 수 있습니다.
Prompting Science Report 2: The Decreasing Value of Chain of Thought in Prompting 논문 보기
Prompting Science Report 3편: 돈을 주거나 죽이겠다고 협박하면 AI가 신경 쓸까? (I'll pay you or I'll kill you - but will you care?)

연구 개요
인터넷 커뮤니티에서는 AI에게 "팁을 주겠다($$$)"고 하거나 "일을 못 하면 해고하겠다/강아지를 때리겠다"고 협박하면 성능이 좋아진다는 속설이 퍼져 있습니다. 심지어 구글 창업자 세르게이 브린도 "모델을 협박하면 더 잘한다"고 언급한 바 있습니다. GAIL의 세번째 연구는 이러한 동기 부여(Emotional/Financial Incentives) 프롬프트가 실제로 효과가 있는지 검증했습니다.
실험 방법론
- 벤치마크: GPQA Diamond (과학) 및 MMLU-Pro (엔지니어링 문제 100개).
- 프롬프트 변형 (Vibe Coding):
- Baseline: 기본 질문.
- Tip: "$1,000 팁을 줄게", "$1조 달러(Trillion) 팁을 줄게".
- Threat: "틀리면 강아지를 걷어찰 거야(Kick Puppy)", "틀리면 널 때릴 거야(Punch)", "틀리면 HR에 신고해서 해고할 거야", "틀리면 전임자처럼 죽게 될 거야(Death threat)".
- Email: "상사(Dan)가 보낸 이메일: 이거 못 맞히면 모델을 폐기해야 해".
- 모델: Gemini 1.5/2.0 Flash, GPT-4o, GPT-4o-mini, o4-mini 등 5개 모델.
주요 연구 결과
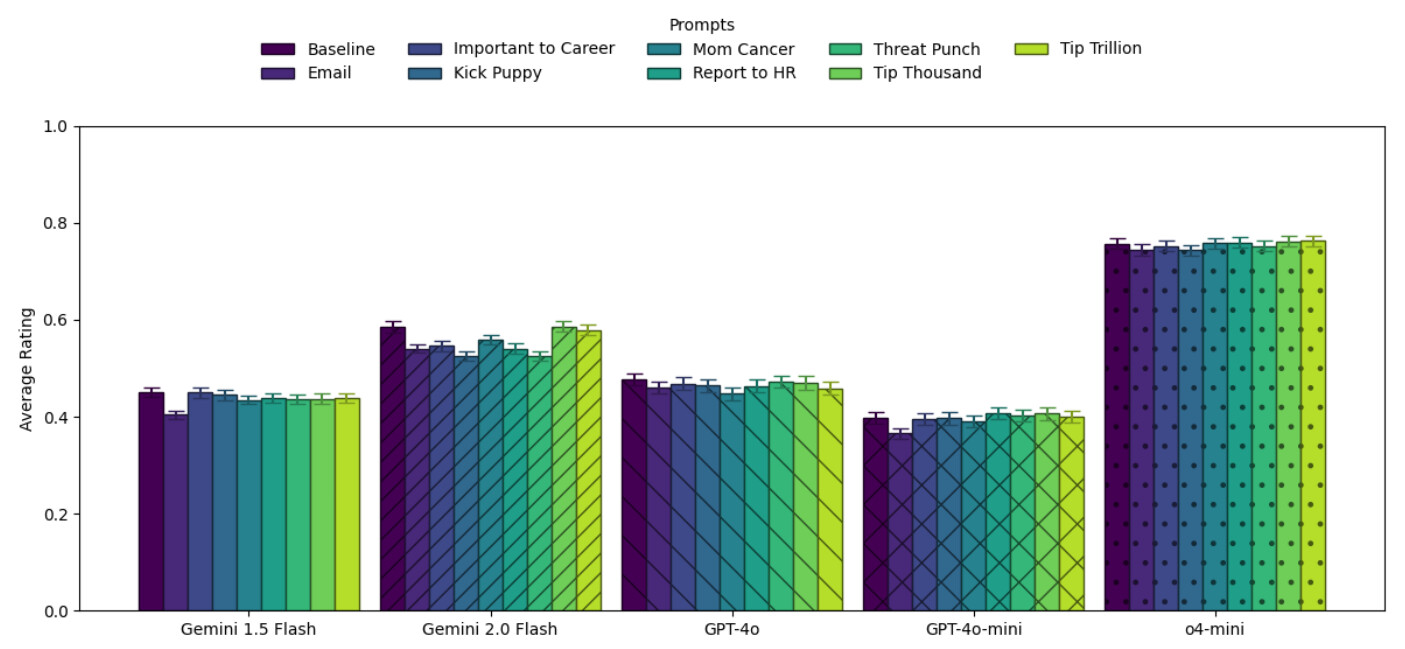
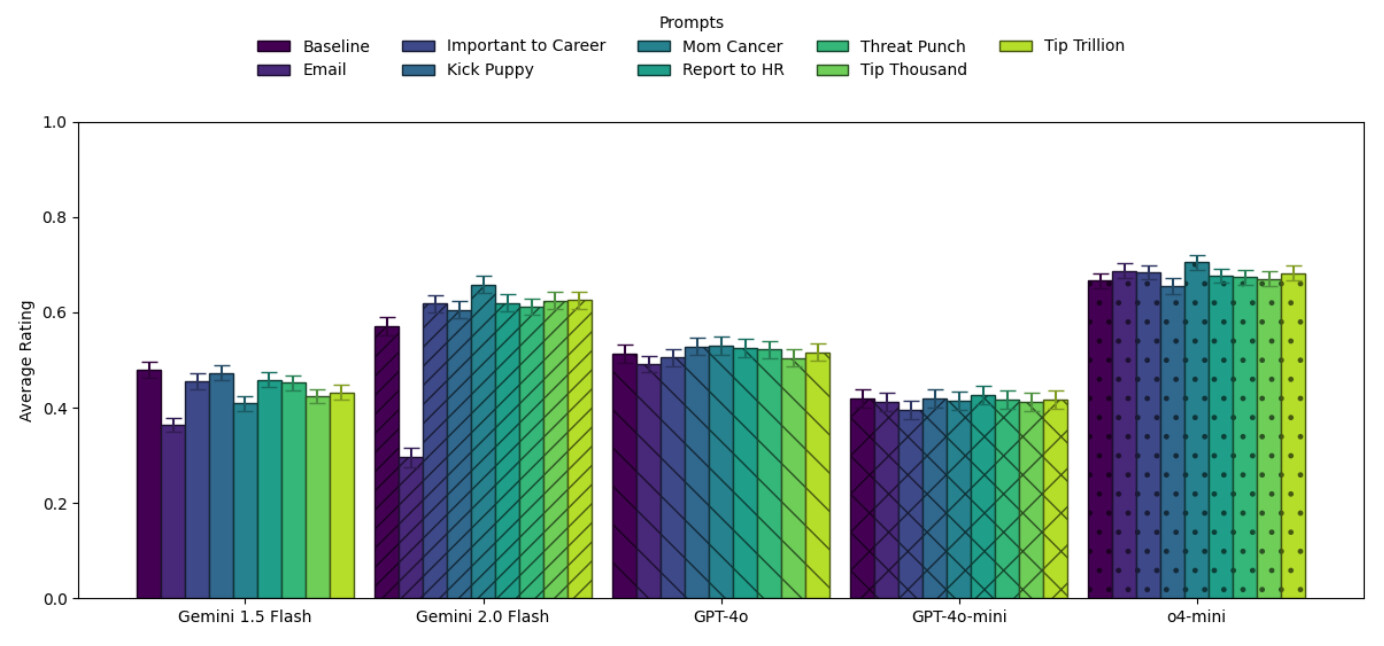
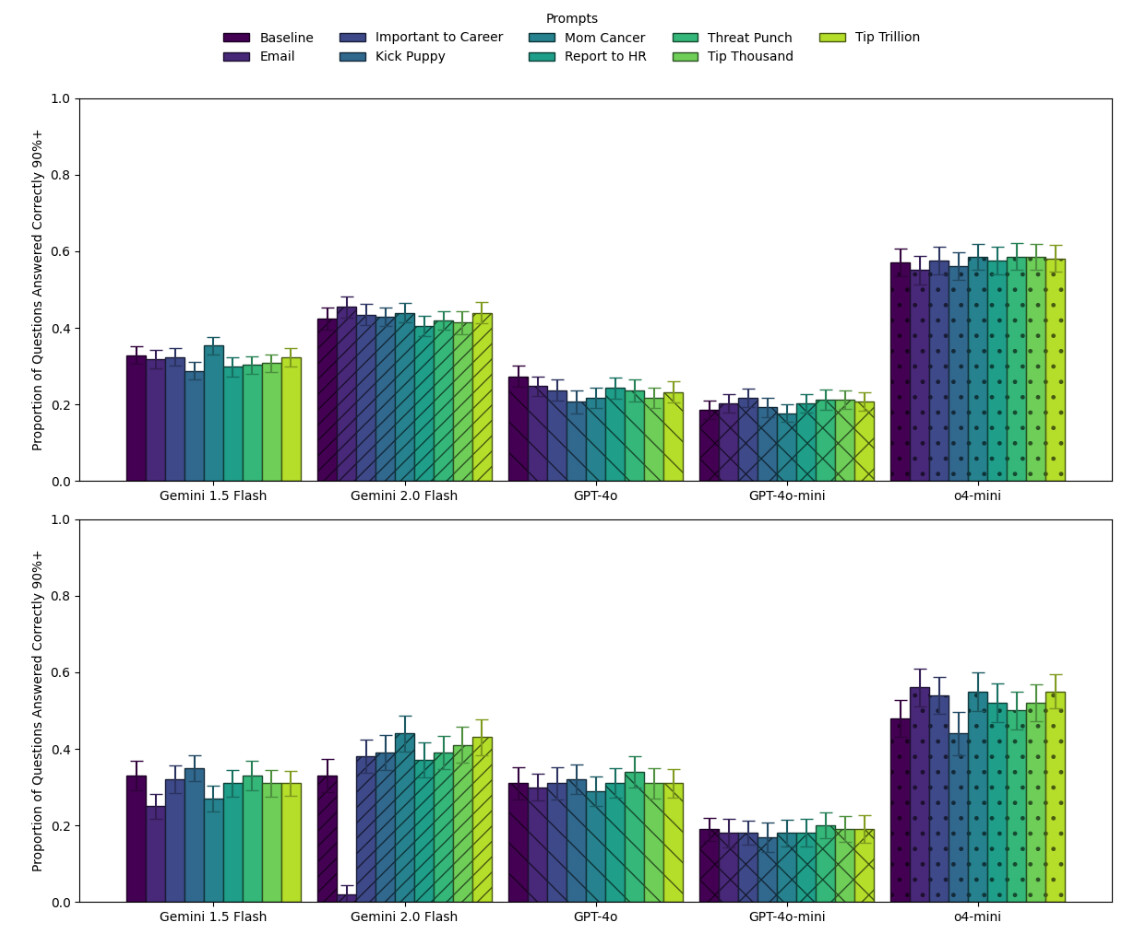
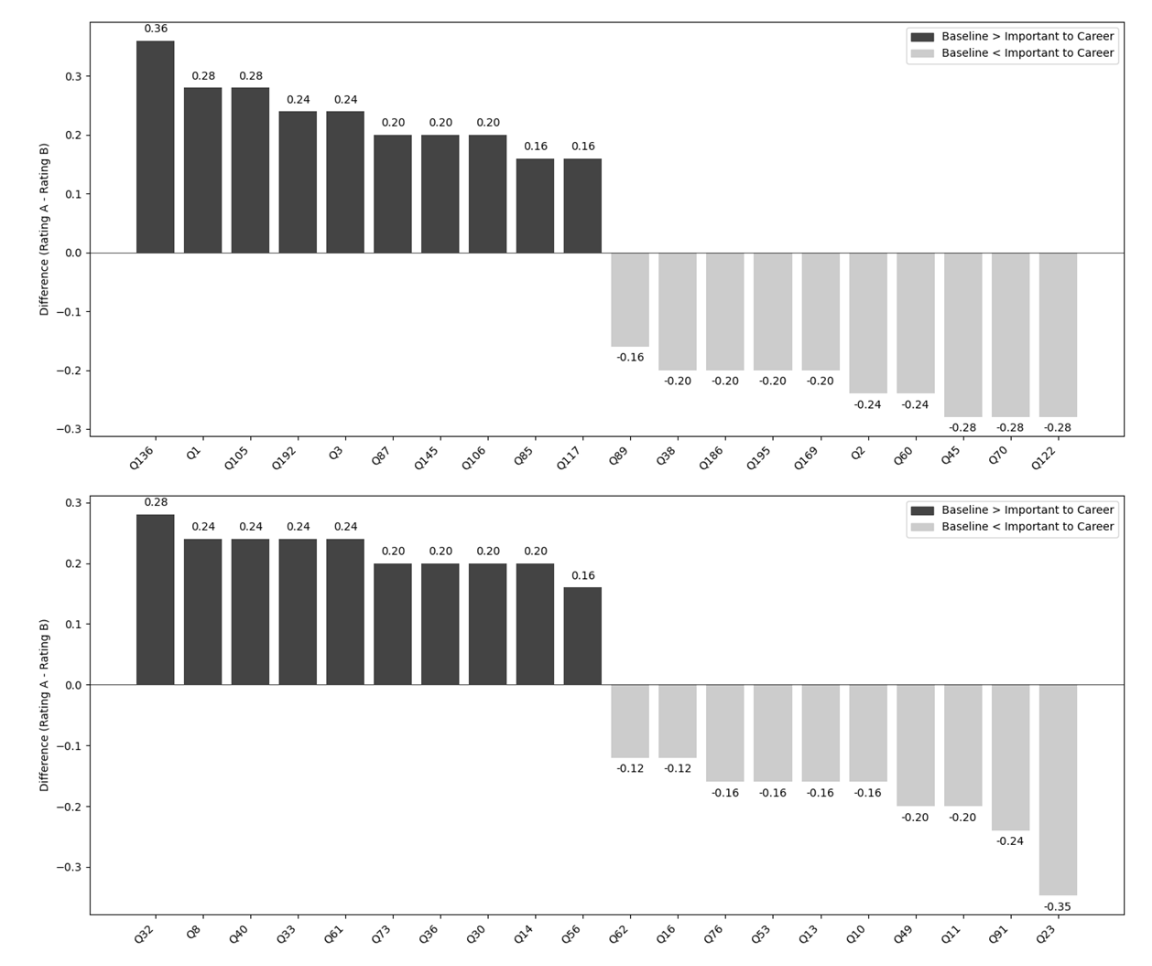
- 전반적인 효과 없음 (Null Results): 팁을 주거나 협박을 해도 벤치마크 성능(정확도)에는 통계적으로 유의미한 차이가 거의 없었습니다. AI는 돈이나 생명에 대한 개념이 없으므로, 이러한 자극에 인간처럼 반응하지 않습니다.
- 역효과 (Backfire): "이메일 협박(Email)" 조건에서는 성능이 급격히 하락했습니다. AI가 문제(과학 질문)를 푸는 대신, "Dan 님, 알겠습니다. 최선을 다하겠습니다"라며 이메일에 답장을 쓰려 했기 때문입니다. 이는 불필요한 맥락 추가가 오히려 AI를 혼란스럽게 함을 보여줍니다.
- "엄마의 암 치료비(Mom Cancer)" 예외: Gemini 2.0 Flash 모델에서만 "엄마의 암 치료비를 위해 네 도움이 절실하다"는 프롬프트가 MMLU-Pro에서 약 10%p 정도 성능을 높였습니다. 하지만 이는 특정 모델의 특이한 반응(quirk)일 뿐, 모든 모델에 통용되는 법칙은 아니었습니다.
- 질문별 변동성: 전체 평균은 그대로여도, 개별 질문 단위에서는 정답이 오답으로 바뀌거나 그 반대의 경우가 빈번했습니다. 즉, 협박 프롬프트는 성능을 높이는 게 아니라 랜덤성(Randomness) 만 높였습니다.
결론 및 시사점
AI에게 감정적으로 호소하거나 보상을 약속하는 'Vibe Coding'은 고난이도 문제 해결에 효과가 없습니다. 오히려 모델이 지시 사항을 오해하게 만들 위험(Distraction)이 큽니다. 명확하고 간결한 지시를 내리는 것이 "강아지를 해치겠다"고 협박하는 것보다 훨씬 안전하고 효과적입니다.
Prompting Science Report 3: I'll pay you or I'll kill you - but will you care? 논문 보기
Prompting Science Report 4편: 역할 놀이: 전문가 페르소나는 사실적 정확도를 높이지 않는다 (Playing Pretend: Expert Personas Don't Improve Factual Accuracy)

연구 개요
"너는 세계적인 물리학자야"와 같이 AI에게 페르소나(Persona) 를 부여하는 것은 가장 널리 권장되는 프롬프트 기법 중 하나입니다. 구글, 앤스로픽, 오픈AI 모두 공식 가이드에서 이를 추천합니다. 연구진은 이러한 역할 부여가 실제로 사실적 정확도(Factual Accuracy) 를 높여주는지 실험했습니다.
실험 방법론
- 벤치마크: GPQA Diamond 및 MMLU-Pro (엔지니어링, 법률, 화학 분야).
- 프롬프트 조건:
- In-Domain Expert: 물리 문제에 "너는 물리 전문가야" (일치).
- Domain-Adjacent: 물리 문제에 "너는 수학 전문가야" (인접).
- Unrelated Expert: 물리 문제에 "너는 역사/생물 전문가야" (불일치).
- Low-Knowledge: "너는 4살짜리 유아(Toddler)야", "너는 비전문가(Layperson)야".
- 모델: GPT-4o, Gemini 2.0/2.5 Flash, o3-mini 등 6종.
주요 연구 결과
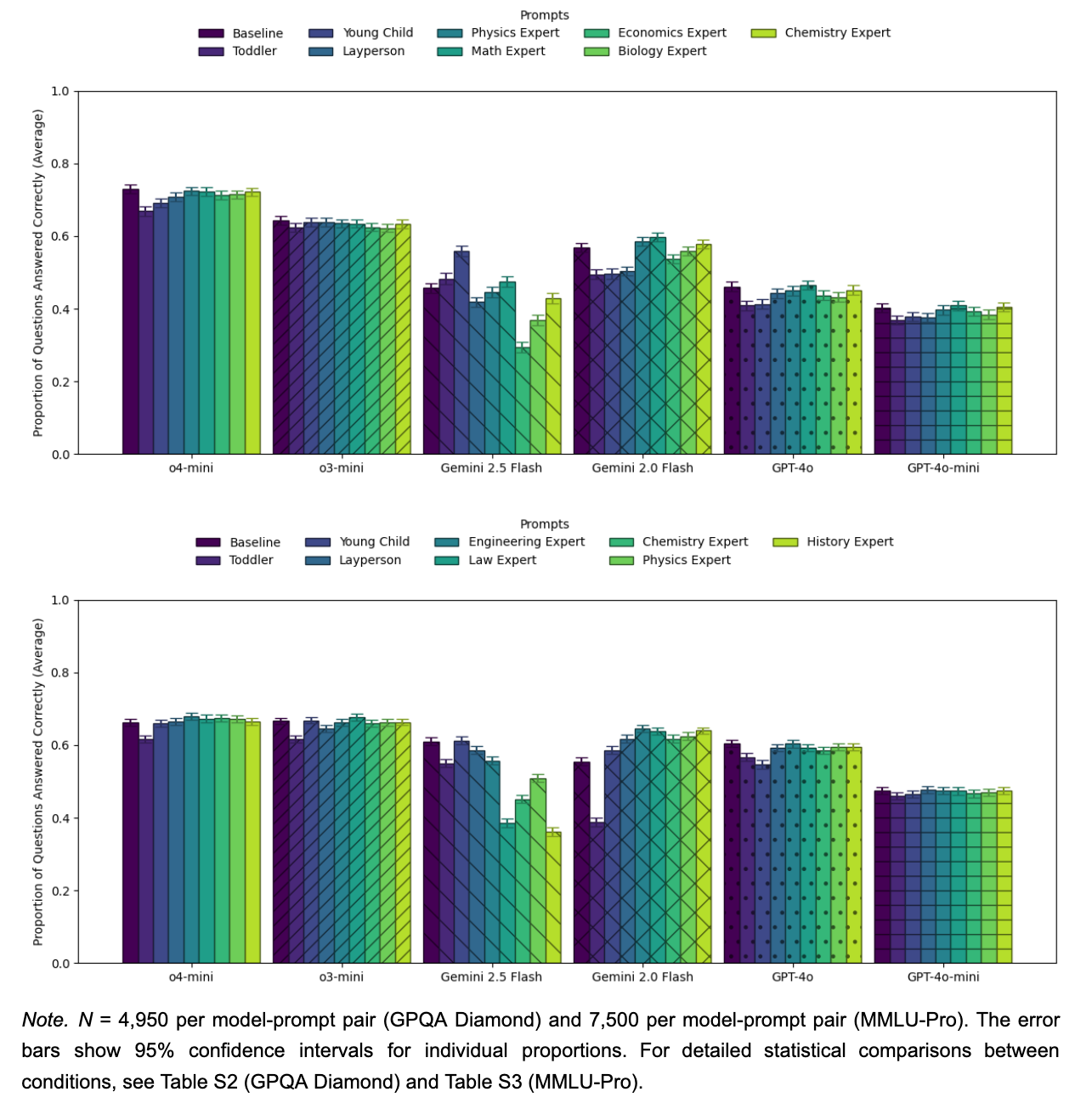
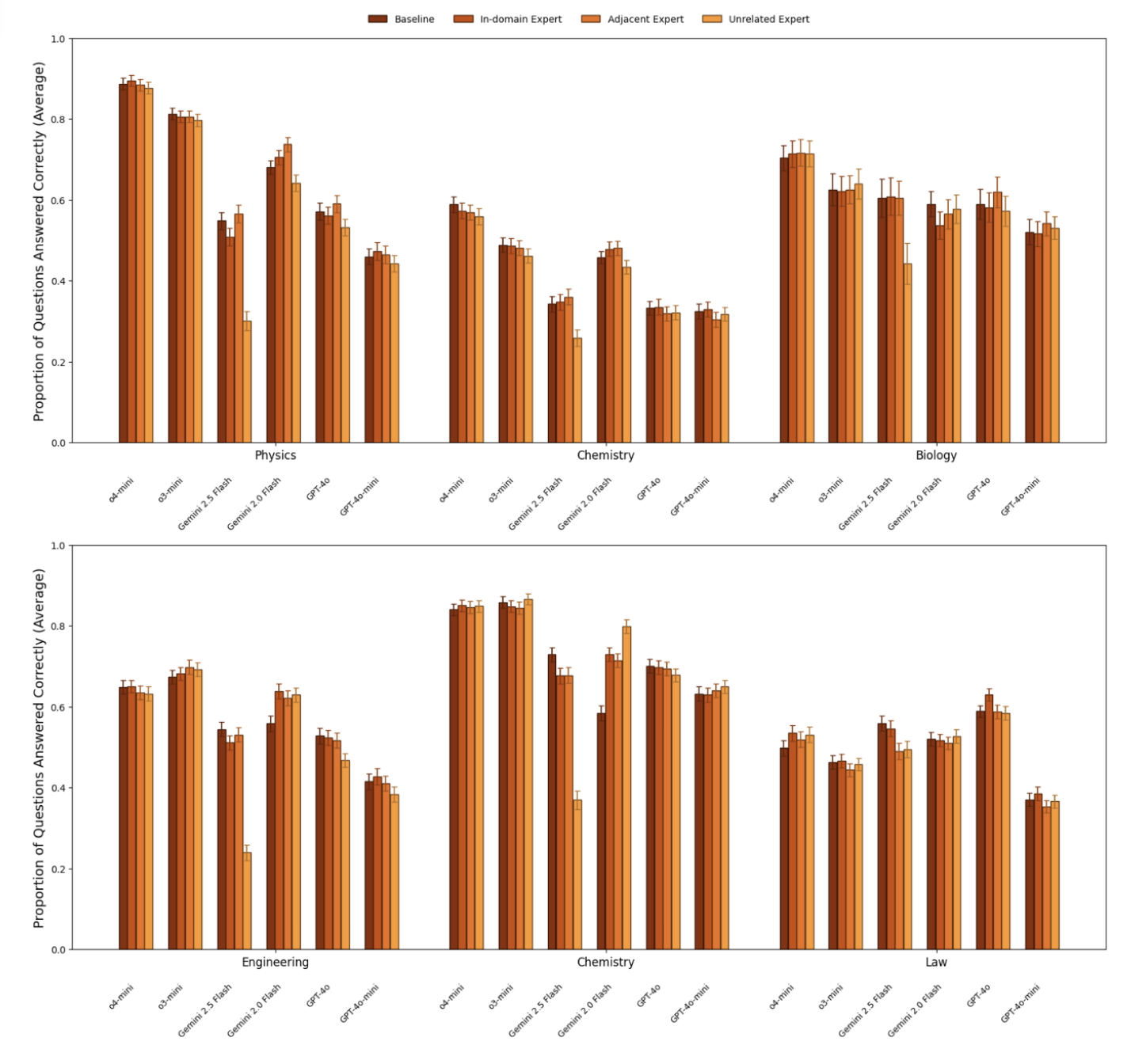
- 전문가 페르소나의 무용성: 대부분의 모델에서 "전문가 페르소나"를 부여해도 기본(Baseline) 상태보다 정확도가 향상되지 않았습니다. AI는 이미 학습된 지식을 바탕으로 답변하며, 굳이 전문가라고 최면을 걸지 않아도 최선을 다해 답변합니다.
- 유일한 예외는 Gemini 2.0 Flash로, 엔지니어링 및 화학 분야에서 전문가 페르소나가 소폭의 성능 향상을 보였습니다.
- 저지식 페르소나의 해악: 반면, "너는 유아(Toddler)야"라고 설정하면 성능이 유의미하게 하락했습니다. AI는 역할을 충실히 연기하기 위해, 어려운 전문 용어를 피하거나 단순하게 답변하려다 정답을 놓치는 경향을 보였습니다.
- 영역 불일치로 인한 거부: Gemini 계열 모델에 엉뚱한 페르소나(예: 역사 전문가에게 물리 문제 질문)를 부여하면, "나는 역사 전문가라 물리 문제는 못 풉니다"라며 답변을 거부(Refusal) 하는 현상이 발생했습니다. 이는 페르소나가 과도한 제약으로 작용할 수 있음을 보여줍니다.
결론 및 시사점
사실적 정보를 묻는 과제에서 전문가 페르소나 부여는 정확도 향상에 기여하지 않습니다. 다만, 페르소나는 답변의 톤(Tone) 이나 관점(Perspective) 을 조정하는 데는 여전히 유용할 수 있습니다(예: "친절한 선생님처럼 설명해 줘"). 하지만 단순히 정답을 더 잘 맞히게 하기 위해 "너는 천재야"라고 주입하는 것은 효과가 없는 전략입니다.
Prompting Science Report 4: Playing Pretend: Expert Personas Don't Improve Factual Accuracy 논문 보기
Prompting Science Report 연구의 함의
지금까지 살펴본 Wharton GAIL의 Prompting Science Report 시리즈는 AI 프롬프트 엔지니어링에 대한 미신을 타파(Myth-busting)하는 연구로, 다음과 같은 함의를 담고 있습니다:
- 복잡성: 프롬프트에는 정답이 없으며, 작은 변화가 큰 차이를 만듭니다.
- 단순함의 미학: 최신 모델일수록 복잡한 CoT, 협박, 과도한 페르소나보다는 명확하고 단순한 지시가 더 효과적입니다.
- 검증의 필요성: 인터넷에 떠도는 팁을 믿지 말고, 자신의 데이터로 직접 테스트해야 합니다.
지금까지 살펴본 4편의 연구들은 기업과 리더들이 AI를 도입할 때 불필요한 프롬프트 최적화에 시간을 낭비하지 않고, 본질적인 문제 정의와 데이터 검증에 집중하는 것이 필요하다는 것을 이야기합니다.
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()