YOLOv5를 안드로이드에서 돌리는 프로젝트를 분석해 봤습니다.
예제 프로젝트의 위치는 여기입니다.
사실 어느정도 안드로이드 앱 개발에 익숙한 분들은 예제 코드 동작 원리같은 것들을 바로 이해하실 수 있습니다. 하지만 인공지능을 공부하고자 하는 분들은 안드로이드 앱의 구조나 동작 관련해서 잘 모르는 분들이 있습니다. 그래서 어느정도 차근차근 정리해 봤습니다. 지엽적인 부분에 집중하기 보다는 전체 데이터 흐름에 집중하시면 될 거 같습니다.
README.md
기본적인 프로젝트의 설명이 적혀 있는 파일입니다. 깃허브 프로젝트의 첫 페이지가 이 파일을 그대로 보여줍니다. 문제는 파일 이름대로 이 문서를 읽는 것이 좋은데 대충 훑어보는 사람이 많습니다(저도 그렇네요…). 대략적으로 어떤 프로젝트인지, 빌드는 어떻게 하는지, 어떤 라이브러리를 쓰는지, 동작을 제대로 하면 어떤 화면이 뜨는지 등 프로젝트 관련해서 전반적인 내용이 씌여 있습니다. 먼저 앱을 실행해 보거나 소스코드를 보는 것도 도움이 되지만, 잘 작성된 README 파일을 읽는 것도 프로젝트 파악에 큰 도움이 됩니다.
우리가 확인해야 되는 부분은 Prepare the model(모델 준비하기) 섹션입니다. 미리 준비된 모델 파일인 yolov5s.torchscript.pt 파일을 다운로드해서 assets 폴더에 저장해 둡니다. 앱을 실행시켰을 때 이런 기본적인 것들을 빠뜨려서 이상한 동작을 하는 경우가 많으니 조심하도록 합시다.
AndroidManifest.xml
안드로이드 프로젝트를 확인할 때 제일 처음 보는 파일이 manifest와 gradle 파일입니다. 이 두 종류의 파일만 보더라도 대략적으로 어떤 기능을 사용하고, 그런 기능을 사용하기 위해 어떤 라이브러리를 사용하는지 알 수 있습니다.
먼저 manifest부터 보시죠.
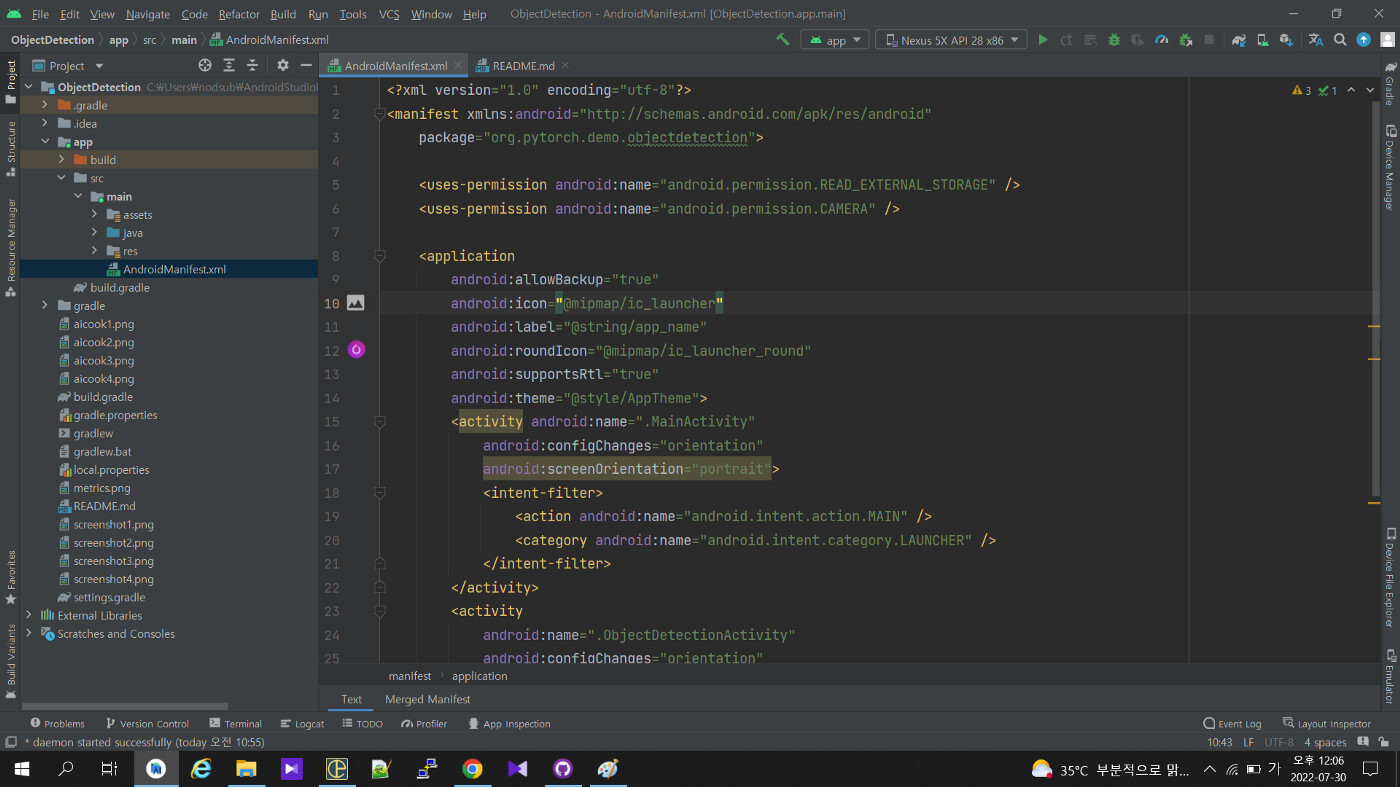
app 폴더 내부에 있습니다.
앱이 특정한 기능을 사용할 때 권한이 필요하다면 manifest 파일에 선언을 해 둬야 합니다. 이런 것만 확인하더라도 어떤 기능을 사용하는지 알 수 있고, 대략적으로 어떤 식으로 구현이 되어 있는지도 알 수 있습니다. 먼저 권한 부분부터 볼까요.

카메라와 외부 저장장치 접근 권한
태그를 보면 카메라 사용과 외부 저장장치 READ 권한 두 가지를 사용한다고 선언한 것을 볼 수 있습니다. 여기 선언한 권한은 ‘앱에서 이런 기능을 사용할 것이다’ 라고 선언만 한 것입니다. 안드로이드 버전에 따라 사용자가 실제로 카메라나 외부 저장 장치 접근을 허용한다는 팝업에서 승낙을 해야 해당 기능을 사용할 수 있기도 합니다(최신 버전들은 다 이렇습니다).
앱이 어떤 권한을 쓰는지 알았으니 이제 어떤 화면을 쓰는지도 알아봅시다.
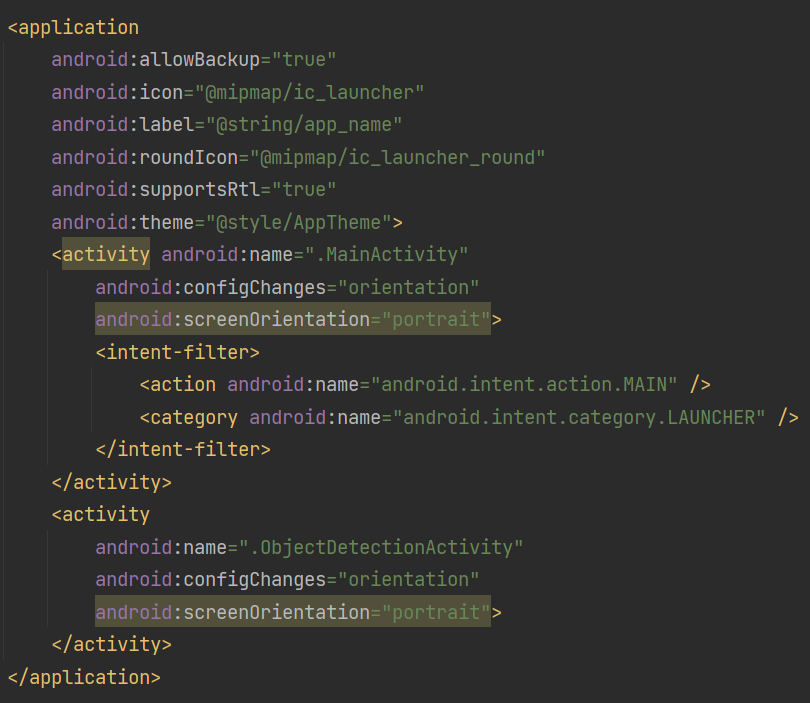
앱이 사용하는 화면 정보가 있네요
태그 내부에는 앱의 이름, 아이콘 등 앱에 대한 대략적인 정보를 기입할 수 있습니다. 우리가 알고 싶은 것들은 이 앱에서 어떤 화면을 사용하는지이기 때문에, 태그는 대략적으로 어떤 것들을 설정할 수 있는지만 보고 넘어가도 됩니다.
이제 이 앱에서 어떤 화면을 쓰는지 확인해 볼까요. 안드로이드에서는 개별 화면을 activity, 액티비티라고 부릅니다. manifest 내부에 라고 화면을 선언해 주면 앱에서 선언한 화면을 액티비티라는 형태로 사용할 수 있습니다. 과 마찬가지로 여러가지 설정을 할 수도 있습니다. 간략하게 보자면 이름부터 화면 방향, 화면 설정 갱신을 액티비티에서 직접 다룰 것인지 관련된 설정이 되어 있습니다. 화면이 portrait로 선언되어 있으니 세로 방향의 화면은 지원하지 않는구나 정도만 알아두시면 될 것 같네요.
설정할 수 있는 태그는 생각보다 엄청나게 많습니다. 관련된 설정은 여기 참고하시면 됩니다. 사용하고자 하는 목적에 따라 각 화면 설정을 여러가지로 고민해 보는 것도 좋겠군요.
build.gradle, build.gradle
그럼 이제 안드로이드에서 앱을 빌드하기 위한 gradle 설정 파일을 보도록 하겠습니다. Maven이나 Ant와 같은 빌드 시스템과 마찬가지로 이런 빌드 파일을 보는 것 만으로도 대략적으로 어떤 라이브러리를 사용하고 있는지, 그 버전은 무엇인지도 알 수 있습니다.
한가지 명심하셔야 하는 것은 프로젝트 전체 수준에서의 gradle 파일과 그 프로젝트 내부의 개별 앱에 대한 파일이 개별적으로 존재하고 있다는 것입니다. 프로젝트 전체 gradle 파일은 앱이나 모듈간의 의존관계를 정의하기도 하고, 의존성을 어디에서 가져오는지 등 전체적인 프로젝트를 관리하는 역할을 한다면 개별 앱(정확히는 모듈)의 gradle 파일은 해당 앱에서만 사용하는 라이브러라니 의존성, 빌드 job이나 task를 설정한다고 생각하시면 됩니다. 커다란 조직에서 함께 지켜야 되는 업무 규칙과 개별 팀에서 따라야 되는 규칙 정도로 생각하시면 편하겠군요.
여기에서 프로젝트 수준에서의 gradle 파일은 넘어가도록 하겠습니다. 빌드에 필요한 gradle의 버전이 표시되어 있긴 한데, 특별히 중요한 내용은 아닙니다 ![]() 앱의 gradle 파일 보시죠.
앱의 gradle 파일 보시죠.
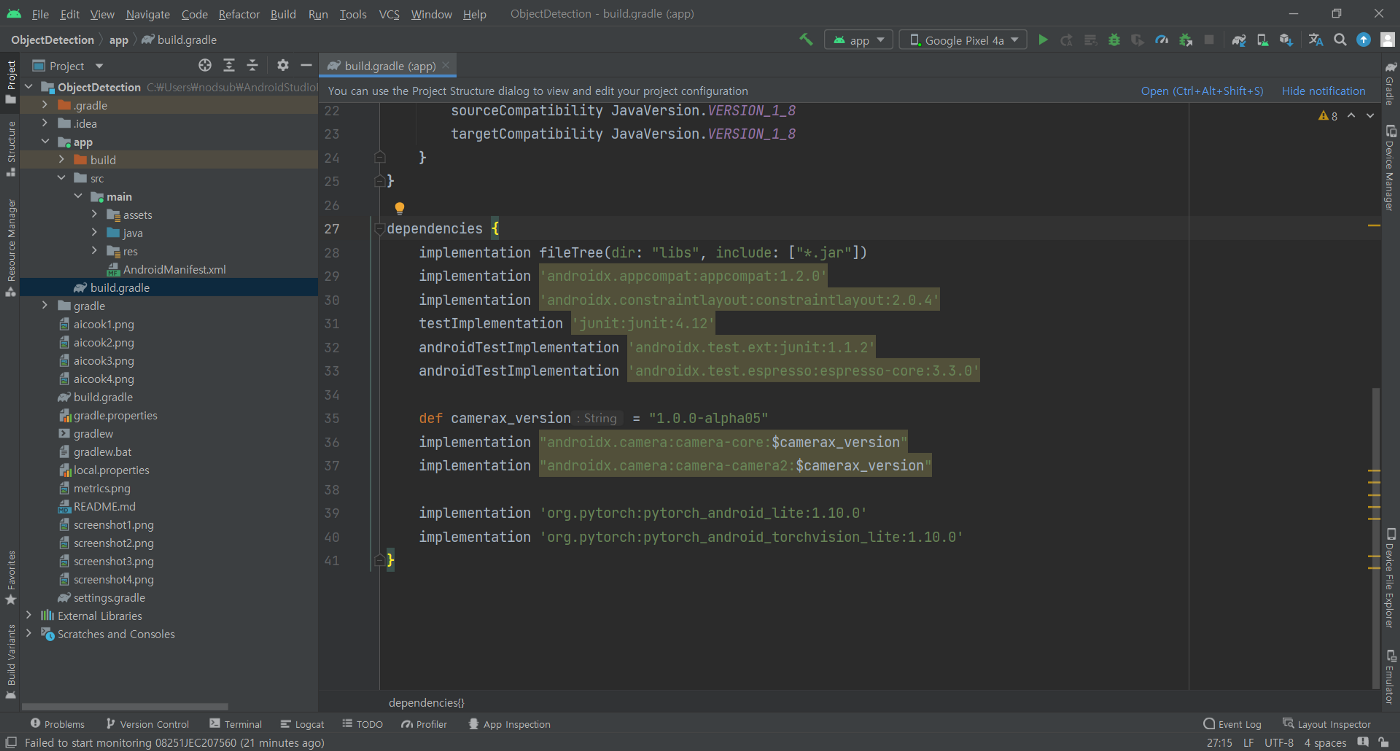
app 폴더 내부에 존재하는 build.gradle
앱의 컴파일에 필요한 SDK부터 시작해서 다양한 설정을 할 수 있는 것을 볼 수 있습니다. 그 중에서도 우리가 봐야 하는 것은 dependencies부분입니다. 앱에서 사용하고자 하는 라이브러리 중 안드로이드에서 기본적으로 지원해주지 않는 의존성은 여기에 선언을 해 줘야 됩니다.
먼저 implementation fileTree(dir: “libs”, include: [“*.jar”]) 이런 것들이 보이네요. 눈치채신 분들도 계시겠지만 파일 시스템에서 어떤 폴더의 jar 파일을 참조해야 되는지 선언한 부분입니다. jar 파일로 배포되는 라이브러리나 모듈의 경우 libs 폴더에서 받아올 것이라는 선언으로, 혹시라도 jar 파일을 가져와서 사용해야 되는 경우에 유용하겠군요.
testImplementation, androidTestImplementation 과 같은 것들은 이름에서도 짐작하시겠지만 테스트 관련된 의존성을 선언하는 부분입니다. 굳이 여기서 짚고 넘어갈 필요는 없겠지만, jUnit이나 espresso를 이용해서 테스트를 구현하면 되겠구나 하는 정도만 보고 가면 됩니다.
이제 슬슬 중요한 부분들이 나오기 시작합니다. androidx.xxxx 이런 라이브러리들은 안드로이드의 jetpack에서 제공하는 라이브러리들입니다. 모든 안드로이드 버전에서 동일한 최신 기능을 지원하기 위한 라이브러리들이며, 자세한 사항은 여기에서 확인 가능합니다. 어떤 기능을 사용하는지 볼까요.
implementation 'androidx.appcompat:appcompat:1.2.0'
implementation 'androidx.constraintlayout:constraintlayout:2.0.4'def camerax_version = "1.0.0-alpha05"
implementation "androidx.camera:camera-core:$camerax_version"
implementation "androidx.camera:camera-camera2:$camerax_version"
윗부분의 appcompat 및 constraintlayout은 화면 구성을 위한 액티비티를 보조하기 위한 라이브러리입니다. 그 밑의 camera x는 카메라를 사용한 기능 개발을 쉽게 하기 위한 라이브러리입니다. manifest에서 선언한 카메라 권한을 이 라이브러리가 이용한다고 보면 되겠군요.
한가지 명심해야 되는 것은 Android Studio가 최신 camerax_version이 존재한다고 suggestion을 해 주는데, 최신 버전을 사용하면 빌드가 되지 않습니다. jetpack이 계속해서 개발이 되고 있고 신기능이 최신 버전으로 업데이트하면 현재 소스코드가 라이브러리를 잘못 사용하고 있다고 컴파일이 되지 않기에 조심해야겠죠.
이제 드디어 파이토치 관련된 라이브러리가 등장합니다.
implementation 'org.pytorch:pytorch_android_lite:1.10.0'
implementation 'org.pytorch:pytorch_android_torchvision_lite:1.10.0'
파이토치 관련된 기능을 사용하기 위한 라이브러리들이 기술되어 있는 부분입니다. camera x도 라이브러리 버전이 맞지 않으면 빌드가 되지 않을 수 있다고 말씀드렸다시피 파이토치 라이브러리들도 최신 버전을 사용하면 동작이 되지 않을 수도 있습니다. 참조하는 라이브러리 버전이 꼬이면 정말 이상한 곳에서 기묘한 문제들이 발생할 수도 있습니다. 그래서 예제 프로젝트의 동작을 확인할 때에는 돌아가는 것을 확인한 다음 라이브러리들을 하나하나씩 최신 버전으로 교체해 가며 최신 기능을 사용하도록 하는 것도 좋은 방법입니다.
이제 드디어 안드로이드 소스코드를 볼 차례입니다. 코틀린이 아닌 자바 버전이라 아쉽긴 하네요.
BaseModuleActivity
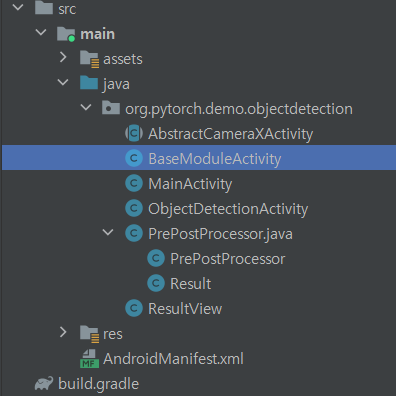
생각보다 액티비티가 많네요
manifest에선 선언이 되어 있지 않은 액티비티가 몇 개 보입니다. 부모 클래스로 선언해 놓고, 실제로 보여주는 액티비티만 manifest에 선언을 해서 사용한다고 생각하면 됩니다. 그 중 제일 기본이 되는 BaseModuleActivity를 보도록 합시다.
클래스 변수부터 살펴보도록 하겠습니다. 안드로이드에서 비동기 처리나 멀티쓰레딩을 위한 방법 중 하나인 핸들러를 사용했네요. 핸들러 쓰레드를 하나 생성하고, 액티비티가 화면이 뜰 때 핸들러 쓰레드를 시작하고 화면이 사라질 때 쓰레드를 정지하는 처리를 합니다.

좋은 비동기 처리 방식은 아니에요
안드로이드에서는 main 쓰레드가 화면을 그려주는 역할을 해서 시간이 많이 걸리는 작업은 별도 쓰레드에서 처리를 해 주는 것이 좋습니다. 여기에서도 핸들러 전용 쓰레드를 만들어서 실행하고, 화면이 나타나고 사라지는 생명주기에 따라 알아서 쓰레드 동작을 제어하기 위한 처리를 해 뒀다 정도로 이해하시면 됩니다. 별도로 설명을 덧붙일 정도로 복잡한 코드는 없어 보이네요.
사실 이런 멀티쓰레딩 방식이 좋은 방식은 아닙니다. 예전에는 액티비티에서 멀티쓰레딩을 위한 이런저런 방법이 있었고, AsyncTask 등으로 이런 비동기 멀티쓰레딩을 처리하기도 했습니다. 하지만 최근에는 액티비티는 순수하게 화면과 연관된 처리만 하고, 별도 쓰레드가 필요한 경우에는 ViewModel 같은 곳에서 처리를 하도록 위임하는 방식을 많이 사용합니다. 액티비티의 생명주기에 따라 작업을 종료해야 한다면 ViewModel에서 알아서 처리하도록 위임하는 것이죠. 그 이외에도 코루틴이나 RX 등을 사용해도 되지만, 아무튼 여기에서 알아두셔야 하는 점은 여기서는 예제 프로젝트이기 때문에 상용 서비스에서는 사용하지 않을 단순한 방식을 사용했다 정도로 이해하시면 됩니다.
AbstractCameraXActivity
prefix로 abstract라는 단어가 붙어 있어 추상 클래스라고 생각할 수도 있습니다. 네 맞습니다. 이렇게 명시적으로 파일이 어떤 역할을 하는지 파일 이름에 명기하기도 합니다. 인터페이스를 구현한 파일 같은 경우에는 postfix로 xxxImpl 이런 식으로 이름을 짓기도 합니다. 카메라 관련된 추상 액티비티구나 정도로 생각하고 코드를 보도록 하겠습니다.

카메라 권한 제어 변수
먼저 카메라 권한 획득을 위한 부분부터 볼까요. 앞서 말씀드린대로 특정한 기능을 사용하기 위해서는 사용자의 명시적인 동의가 있어야 되고, 그런 것들을 처리하기 위한 작업을 위한 것들이라고 보시면 됩니다.
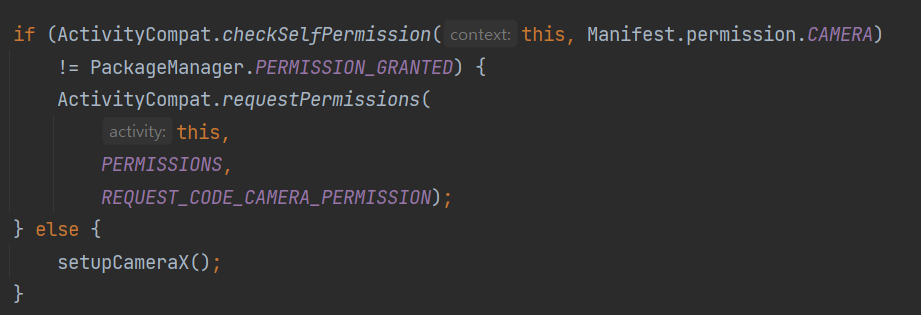
권한이 없다면 권한 요청을 합니다
onCreate()에서 카메라 사용 권한이 있는지 체크한 다음 권한이 없으면 사용자의 동의를 얻는 팝업을 띄웁니다. 권한이 이미 있다면 setupCameraX() 메소드를 통해 카메라를 사용할 수 있게 합니다.
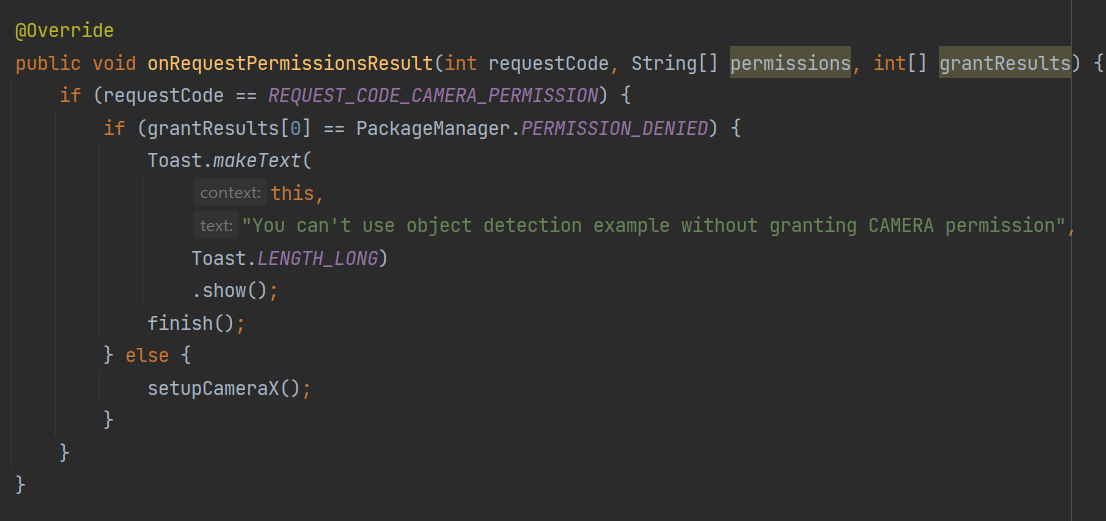
카메라 사용 동의를 하지 않는다면?
onRequestPermissionsResult() 메소드에서는 사용자에게 요청한 권한을 획득했는지 확인합니다. 만약에 사용자가 카메라 사용을 동의하지 않는다면 권한이 없이 카메라 사용이 불가능하다는 문구를 출력해 줍니다.
이제 이 액티비티에서 제일 중요한 setupCameraX() 메소드를 보도록 하겠습니다. 카메라를 사용할 수 있도록 준비작업을 하는 메소드로서, camera x에서 제공하는 기능을 사용합니다. 한 가지 주의해야 되는 것은 여기에서 설명하는 내용은 camera x 버전 1.0.0-alpha05 버전 기준으로 카메라 기능을 사용하기 위한 준비작업입니다.

view에 preview를 연결
먼저 메소드 앞 부분부터 살펴보겠습니다. 추상 메소드인 getCameraPreviewTextureView()를 이용해서 미리보기를 뿌려줄 TextureView를 가져옵니다. 컨텐트 스트림을 보여주는 view인데, 동영상이나 미리보기 같은 것들을 보여주는 뷰라고 생각하면 됩니다. 이 view에 미리보기를 뿌려주기 위해 PreviewConfig라는 설정을 이용해서 Preview() 인스턴스를 생성하고, preview의 결과값으로 나오는 output을 TextureView에 뿌려주도록 연결을 하고 있습니다.
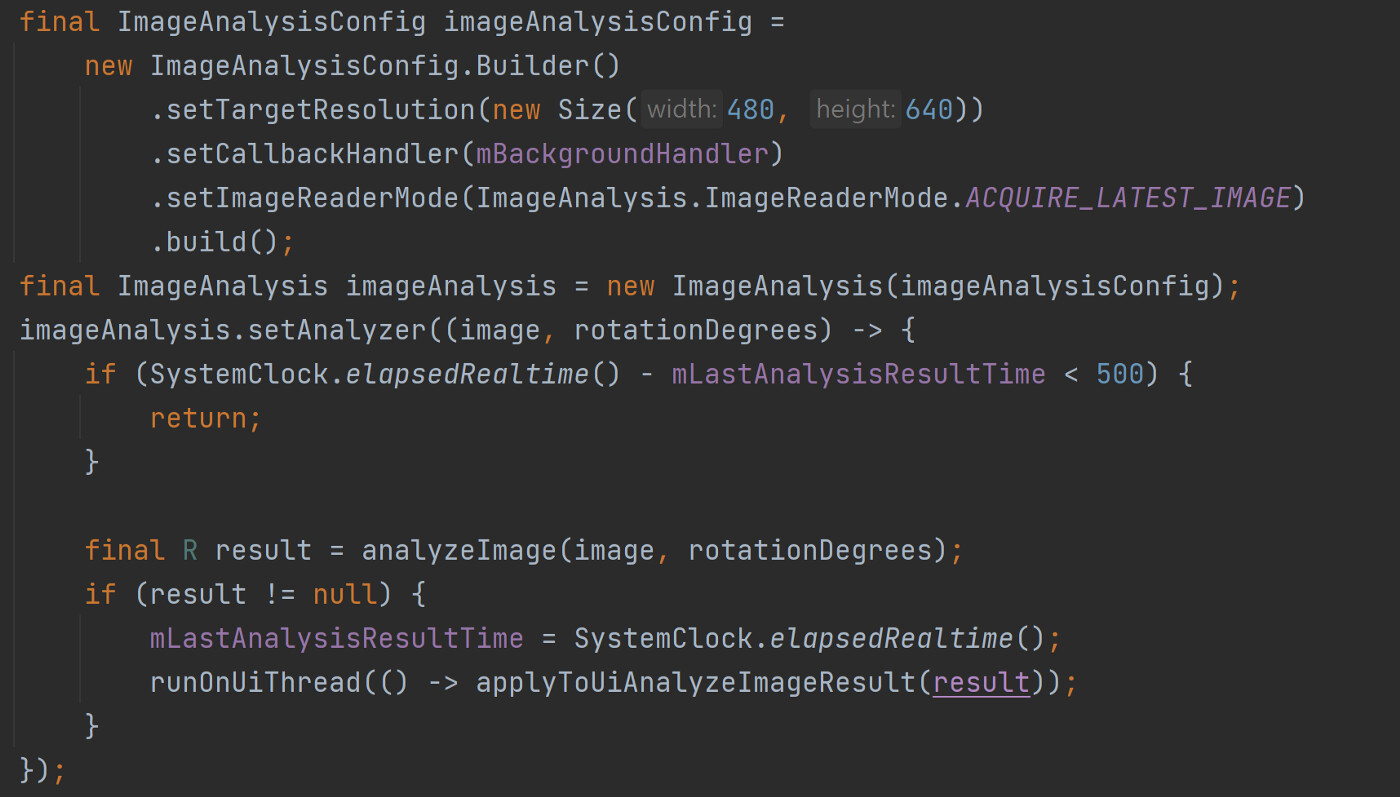
이미지 분석을 위한 인스턴스 생성
그 다음은 이미지 분석을 위한 ImageAnalysis 인스턴스 생성입니다. 이 인스턴스를 생성하기 위해 먼저 설정을 위한 빌더 인스턴스에서 해상도, 콜백, 이미지 렌더 모드 등을 설정합니다. 최신 버전인 1.2에는 콜백 함수를 등록하는 메소드는 사라지는 등 변경점이 많아 자세하게는 설명하진 않겠습니다만, 이미지 분석을 위한 백그라운드 처리나 해상도 설정, 가장 최신 이미지를 사용해서 이미지를 분석할 것이다 정도의 의미입니다.
앞서 설정한 설정값으로 ImageAnalysis 인스턴스를 생성하고 나면 이제 이미지 분석을 위한 Analyzer를 설정합니다. 여기에서는 람다식으로 Analyzer의 익명 클래스를 생성해 줍니다. 새로운 이미지를 받자마자 계속해서 분석하는 것을 방지하기 위해 이전에 이미지 분석한 시간에서부터 500ms가 지나고 받은 새로운 이미지를 분석하고, 그 중간에 받은 이미지는 분석하지 않습니다.
final R result = analyzeImage(image, rotationDegrees);
if (result != null) {
mLastAnalysisResultTime = SystemClock.*elapsedRealtime*();
runOnUiThread(() -> applyToUiAnalyzeImageResult(result));
}
본격적인 분석 메소드인 analyzeImage() 및 applyToUiAnalyzeImageResult()도 추상 메소드입니다. 따라서 이 클래스를 상속받은 자식 클래스에서 정의한 분석 로직을 실행하고, 그 결과를 runOnUiThread()를 통해서 화면을 갱신시켜준다 정도의 뜻이 됩니다.
CameraX.*bindToLifecycle*(this, preview, imageAnalysis);
이 코드는 ImageAnalysis와 preview를 각 화면의 생명 주기에 맞출 수 있도록 해 줍니다. 이미지 분석, 캡쳐 등의 카메라를 사용해서 수행할 수 있는 다양한 작업을 Use Case라고 하는데, 자세한 사항은 여기를 참고하시면 됩니다. 아무튼 안드로이드에서는 화면 전환이나 화면 변경과 같은 화면의 생명 주기에 카메라 기능을 맞춰서 사용하게 하는 기능도 있다 정도만 알아두시면 됩니다. 실제로 모바일 환경에서는 화면 전환이나 앱 종료 등의 다양한 이벤트가 존재하기에 안드로이드에서는 이런 동작을 자동으로 처리하도록 제공하는 기능들이 많이 있습니다.
추상 클래스인 만큼 세부적인 분석 로직은 자식 클래스에서 알아서 구현할 수 있도록 추상 메소드로 처리를 해 뒀고, camera x의 미리보기 설정 같은 공통 작업은 추상 클래스에서 처리를 할 수 있게 해 뒀습니다. 파이토치를 이용한 이미지 분석 로직과 카메라 사용을 위한 안드로이드 로직을 어느 정도 분리를 잘 시켰다고도 할 수 있습니다. 물론 스트래티지 패턴을 이용해서 분석 로직을 잘 분리시키고 인터페이스로 구현하게 할 수도 있지만, 예제 코드에서는 이 정도로도 충분한 수준입니다.
예제 앱이 어떻게 구성이 되어 있는지 대략적인 밑그림은 설명을 한 것 같군요. 한데 지금까지 파이토치나 YOLO 모델과 관련된 내용은 하나도 나오지 않아 의아하게 여길 수도 있을 겁니다. 하지만 반대로 생각해 보자면, 지금까지 이렇게 안드로이드 관련된 부분을 전부 구현해 두고, 파이토치를 사용하는 코드는 추상 클래스의 추상 메소드 내부에 내용을 채워넣기만 하면 되는 구조로 구현을 했다고도 볼 수 있습니다. 이렇게 구조를 구성해 두면 비단 객체 탐지뿐만 아니라 다른 기능도 camera x에서 읽어들인 이미지를 이용할 수도 있기에 이미지 분석을 위한 다양한 기능을 시험해 볼 수 있는 밑그림으로 사용할 수도 있습니다.
MainActivity
제일 먼저 onCreate() 메소드를 살펴보겠습니다. onCreate() 메소드는 안드로이드에서 화면이 뜨게 되면 실행되는 메소드 중 하나인데, 액티비티 클래스를 분석할 때 제일 먼저 보는 메소드 중 하나라고 생각하시면 됩니다. 권한 설정 점검에서부터 각종 변수나 화면 구성요소인 버튼, 뷰 등을 초기화 시켜줍니다. 굉장히 긴 메소드라 중요한 부분만 살펴보도록 하겠습니다.
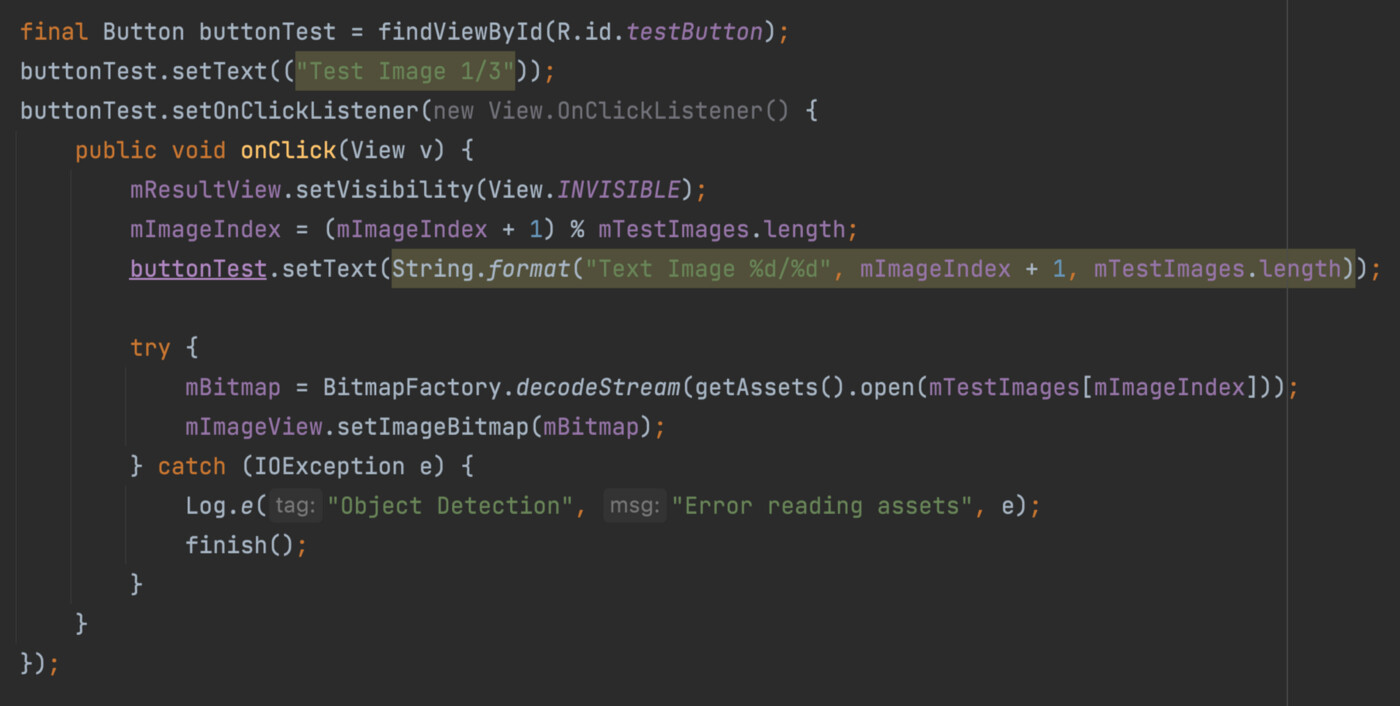
제일 왼쪽 아래의 버튼 동작 정의
먼저 버튼 클릭 이벤트들을 처리하는 코드들이 보이는군요. 위의 코드는 메인 화면 왼쪽 아래의 코드를 눌렀을 때 수행되는 코드입니다. 클릭 이벤트를 처리하기 위해 버튼에 setOnClickListener()를 이용해서 클릭 리스너를 달아줍니다. 버튼 초기 텍스트는 setText() 메소드를 이용해 ‘Test Image 1/3’ 으로 설정했고, 클릭할 때 마다 mImageIndex을 바꿔 가며 버튼의 문구와 화면에 표시할 이미지를 변경해 줍니다.
그 다음으론 메인 화면 하단 중앙의 Select 버튼을 눌렀을 때의 동작을 보겠습니다. 이 버튼을 누르면 다이얼로그를 띄우는 코드가 수행이 되는데, 대략적으로 다이얼로그를 띄우기 위한 코드들이라고 보시면 됩니다. 다이얼로그에는 세 가지 선택지가 있는데, 갤러리에서 이미지를 가져올 수도 있고, 카메라로 사진을 찍어서 이미지를 가져올 수도 있습니다. 제일 중요한 부분의 코드만 보겠습니다.
builder.setItems(options, new DialogInterface.OnClickListener() {
@Override
public void onClick(DialogInterface dialog, int item) {
if (options[item].equals("Take Picture")) {
Intent takePicture = new Intent(android.provider.MediaStore.*ACTION_IMAGE_CAPTURE*);
startActivityForResult(takePicture, 0);
}
else if (options[item].equals("Choose from Photos")) {
Intent pickPhoto = new Intent(Intent.*ACTION_PICK*, android.provider.MediaStore.Images.Media.*INTERNAL_CONTENT_URI*);
startActivityForResult(pickPhoto , 1);
}
else if (options[item].equals("Cancel")) {
dialog.dismiss();
}
}
});
사용자가 객체 탐지를 위해 카메라나 갤러리를 선택하면 실행되는 코드입니다. 여기에서 호출하는 startActivityForResult() 메소드는 다른 액티비티, 즉 다른 화면을 실행시키고 , 실행된 다른 화면이 종료될 때 이 메소드를 호출한 화면에서 사용할 결과값을 콜백 메소드인 onActivityResult()로 전달해 달라는 메소드입니다.
특히나 메소드에 전달하는 인자 중 제일 마지막 0, 1 이 숫자들을 자세히 볼 필요가 있는데요, 이 숫자들은 requestCode로서 어떤 화면에 어떤 요청을 했는지 구분을 하게 만드는 숫자들입니다. onActivityResult() 메소드에서 이 requestCode를 이용합니다. onActivityResult() 메소드는 전달받은 이미지를 화면에 표시해 주는 로직이 있는데, 안드로이드에 치중한 내용이라 한 번 읽어보시길 추천드리고 넘어가도록 하겠습니다. 여기에서는 다이얼로그의 메뉴를 클릭하면 Intent에 이런저런 값을 넣어서 화면을 실행한다 정도만 알아 두시고, 안드로이드에서 카메라나 갤러리 실행을 위해서는 이런 것들이 필요하구나 정도만 아셔도 무방합니다. 보통 0, 1 이렇게 하지 않고 FROM_GALLARY = 1 이렇게 상수를 정의한 다음 이런 상수를 쓰기도 한다는 점도 알아두세요.
한 가지 주목해야 할사항은 카메라나 갤러리에서 가져온 비트맵을 90도 회전 시키고 있습니다.
Matrix matrix = new Matrix();
matrix.postRotate(90.0f);
mBitmap = Bitmap.*createBitmap*(mBitmap, 0, 0, mBitmap.getWidth(), mBitmap.getHeight(), matrix, true);
카메라나 갤러리에서 가져온 사진은 수평으로 놓여진 이미지라 이렇게 회전을 시킨다고 보시면 됩니다. 각도를 조절해 보면서 모델의 분석 결과가 어떻게 달라지는지 보는 것도 재미가 될 수 있겠군요 ![]()
화면 우하단의 Live 버튼은 단순히 ObjectDetectionActivity를 실행시킵니다. 단순한 코드라 따로 설명이 필요할 것 같진 않습니다. 마지막으로 메인 화면의 중앙에 떠 있는 사진에서 객체 탐지를 수행하는 버튼인 Detect 버튼 동작을 보겠습니다.
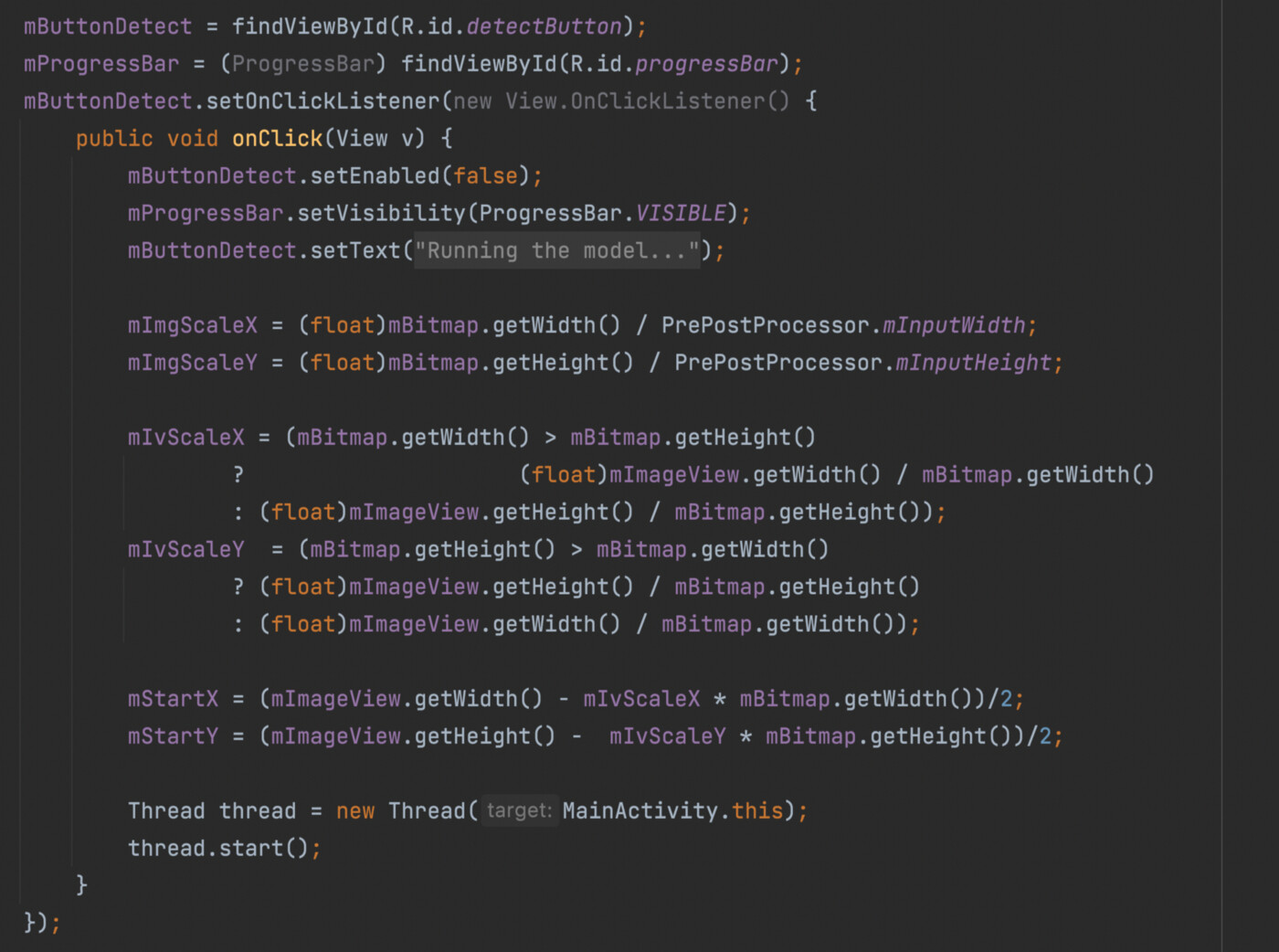
주어진 이미지로 객체 탐지를 수행하고 화면에 결과도 그려줍니다.
이미지 분석중임을 나타내기 위한 프로그레스바를 띄워주고, 화면에 떠 있는 mBitmap을 모델에서 사용할 수 있도록 이미지 비율 관련 변수를 초기화 해 줍니다. 이미지 크기에 따라 x축이나 y축으로 늘이거나 줄여야 될 수 있기 때문에 여기에서 이런 변수를 조절해 줍니다. 그 후에 백그라운드에서 이미지 분석을 해서 객체 탐지를 할 수 있도록 쓰레드 객체를 생성 및 실행합니다. MainActivity가 Runnable을 구현하고 있어서 쓰레드 생성할 때 인자로 전달한다고 생각하시면 됩니다.
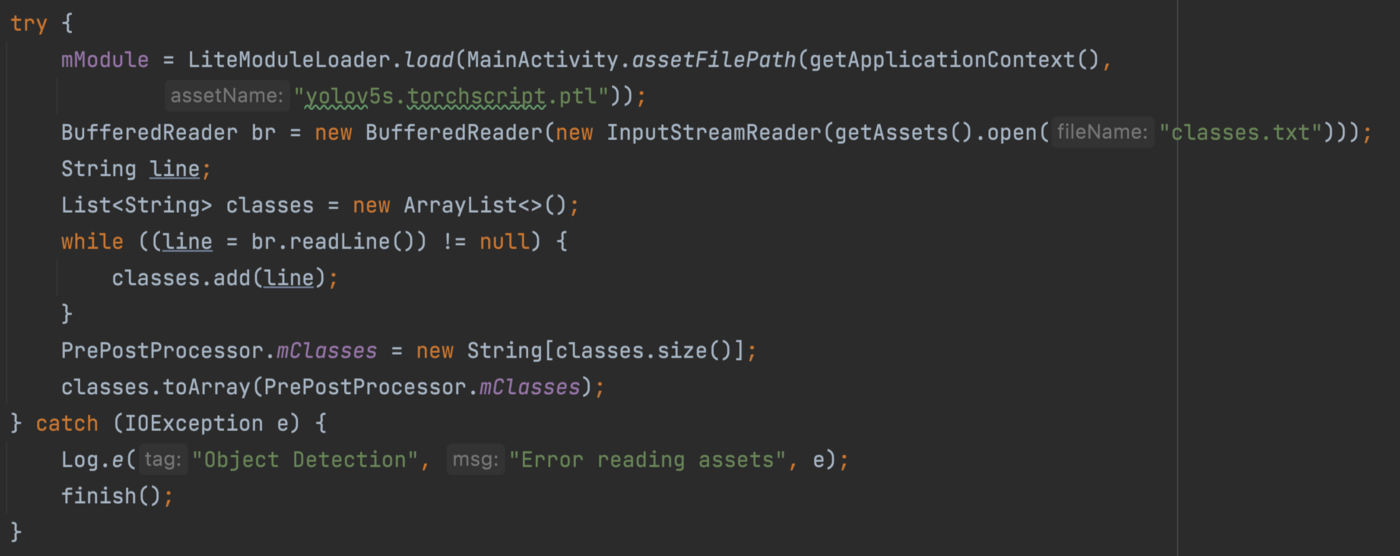
모델을 초기화 합니다.
이제 마지막으로 파일에서 모델을 읽어들입니다. classes.txt 파일은 모델에서 분류 가능한 객체들의 분류(class)가 표기되어 있습니다. 이 부분은 프로젝트의 README에도 설명이 나와 있는 부분이니 거기도 참고하세요.
80가지 종류의 객체 탐지가 가능합니다.
분류할 항목들을 파일에서 읽어들인 다음 PrePostProcessor에 String 문자열 형태로 저장을 하는 것으로 객체 탐지 준비가 끝이 납니다.
그럼 이제 객체 탐지를 하는 곳을 살펴볼 차례입니다. 모델 파일을 읽는 assetFilePath() 메소드를 보겠습니다.
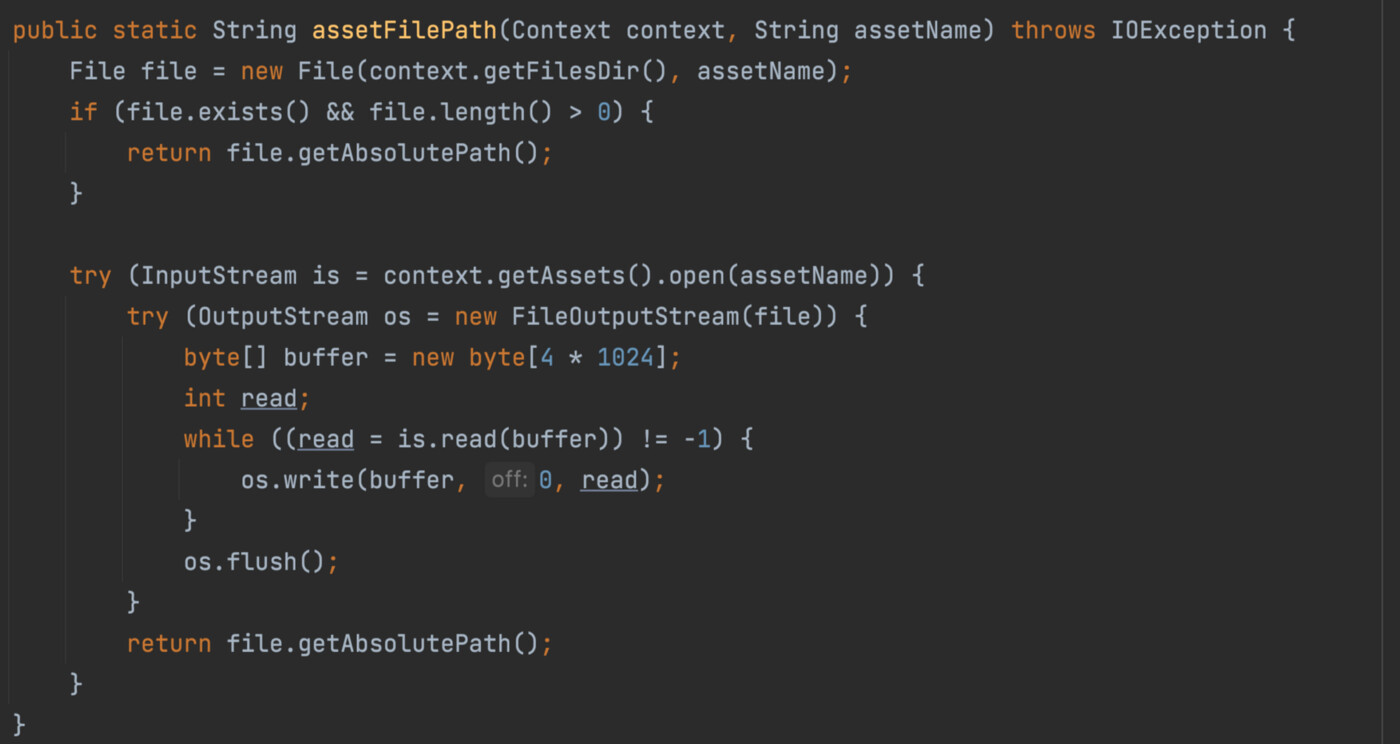
학습시켜놓은 모델을 읽어들이는 역할을 합니다.
이 메소드를 사용한 곳은 앞서 설명한 onCreate()의 제일 아래쪽입니다. assets에 있는 모델인 ‘yolo5s.torchscript.ptl’을 파일 객체로 읽어들인 다음 그 파일의 절대경로를 이용해 파이토치의 Module 객체를 만듭니다.
mModule = LiteModuleLoader.*load*(MainActivity.*assetFilePath*(getApplicationContext(), "yolov5s.torchscript.ptl"));
BufferedReader br = new BufferedReader(new InputStreamReader(getAssets().open("classes.txt")));
이렇게 생성한 모듈 객체를 이용해서 이미지에서 객체를 탐지하는 거죠. 조금 더 많은 예제를 확인하고 싶다면 여기도 참고하세요.
참고로 이 메소드는 ObjectDetectionActivity에서도 사용하기 위해 MainActivity에 static으로 선언이 되어 있습니다. 예제라서 용인될 구조입니다… 깔끔하진 않군요.
이제 읽어들인 모델을 이용해서 객체를 탐지하는 run() 메소드를 살펴보겠습니다. 자바에 익숙한 분들은 아시겠지만 Runnable 인터페이스에서 정의한 메소드로서, Select 버튼을 눌렀을 때 생성한 쓰레드에서 이미지 분석을 처리할 로직을 run() 메소드 내부에 정의해 두었습니다.
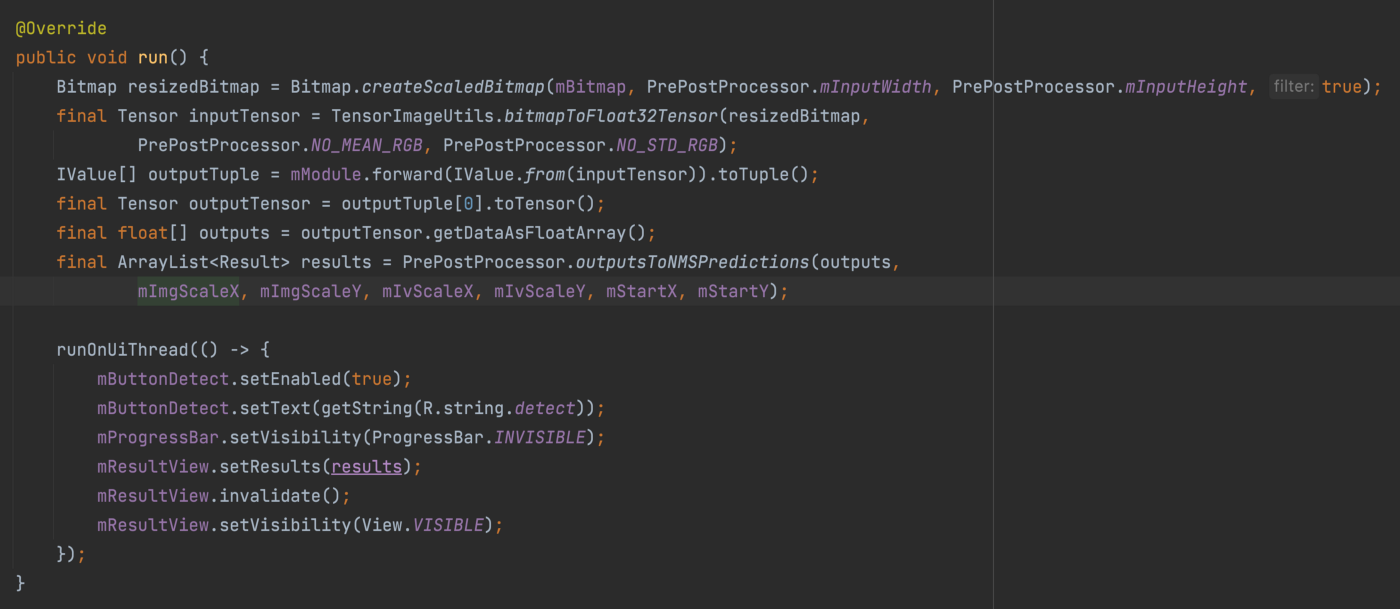
백그라운드에서 이미지 분석을 합니다.
이미지를 처리하는 순서가 약간은 복잡해 보입니다만, 대체적인 흐름은
이미지 → 텐서 → 모델 → 추론 결과 → 결과값을 텐서로 변환 → 텐서에서 float형 배열로 변환 → 배열에서 각각의 객체 좌표 추출
이런 순서입니다. 파이썬에서 이미지를 처리하는 것과 크게 다르지 않죠.
먼저 비트맵 이미지의 크기를 조절합니다. 학습시켜 놓은 모델의 인풋으로 받을 수 있는 이미지의 크기에 맞추는 작업입니다. PrePostProcessor 클래스에서 전처리나 후처리에 필요한 각종 값을 확인할 수 있는데, 여기에선 640 x 640 크기의 비트맵을 인풋 데이터로 받습니다. 그 다음 변환된 비트맵을 모델에 입력하도록 텐서로 변환합니다. 이렇게 텐서로 변환된 이미지는 좀 전에 읽어들인 모듈에 forward() 메소드로 전달되어 객체 탐지를 수행합니다.
IValue[] outputTuple = mModule.forward(IValue.*from*(inputTensor)).toTuple();
final Tensor outputTensor = outputTuple[0].toTensor();
final float[] outputs = outputTensor.getDataAsFloatArray();
final ArrayList<Result> results = PrePostProcessor.*outputsToNMSPredictions*(outputs,
mImgScaleX, mImgScaleY, mIvScaleX, mIvScaleY, mStartX, mStartY);
배열에서 결과값을 좌표로 추출하는 부분은 PrePostProcessor에서 처리합니다. 모델에서 중첩된 객체 좌표들까지 반환하기 때문에 outputsToNMSPredictions() 메소드에서 임계점 이하의 결과는 제거하면서 그 중에 제일 높은 점수를 획득한, 제일 정확한 객체의 테두리만 남깁니다. 비-최대 억제 알고리즘(NMS)을 사용해서 이러한 일을 수행하는데요, 자세한 설명은 여기에서 확인하실 수 있습니다. 다른 YOLO 프로젝트의 코드를 자바로 포팅했는데, 코드가 지저분해서 쉽사리 읽혀지진 않네요. 예제 코드인 점을 감안해서 보시고, 단순히 YOLO 모델뿐만 아니라 여러 알고리즘도 사용하고 있고, 이런 것들도 이해를 해야 효율적으로 모델을 사용할 수 있다 정도만 알아두시면 됩니다.
객체인지 아닌지 판단하는 임계점 값인 mThreshold을 0.30f로 설정을 해 놓았는데, 값을 조절해 가며 다양하게 시도를 해 보는 것도 재미있을 것 같네요.
run() 메소드의 마지막 부분은 화면을 갱신하는 부분입니다.
runOnUiThread(() -> {
mButtonDetect.setEnabled(true);
mButtonDetect.setText(getString(R.string.*detect*));
mProgressBar.setVisibility(ProgressBar.*INVISIBLE*);
mResultView.setResults(results);
mResultView.invalidate();
mResultView.setVisibility(View.*VISIBLE*);
});
안드로이드는 main 쓰레드에서만 화면 갱신을 할 수 있기 때문에 main 쓰레드에서 동작하는 runOnUiThread() 메소드에 화면 갱신 로직을 전달하고 있습니다. Runnable 인터페이스를 인자로 받기 때문에 람다 형식으로 화면 처리 코드를 전달한다 정도로 생각하시면 됩니다. MainActivity에서 정의한 run() 메소드이기에 MainActivity의 객체를 전달하지는 못하는군요..
ResultView
메인 화면에 떠 있는 사진에서 객체 탐지를 수행한 결과를 붉은 색 네모 칸으로 표시하고 어떤 클래스에 속해 있는지 표시하는 뷰 입니다. 메인 화면에서 결과값 표시를 위해 객체들의 좌표를 받아 표시한다 정도만 알아 두시면 됩니다. 뷰에 사각형을 어떻게 그리는지, 글자를 어떻게 쓰는지 궁금하다면 어려운 코드는 없기에 한번 읽어보시면 됩니다.
ObjectDetectionActivity
1편에서 살펴봤던 AbstractCameraXActivity를 상속받는 액티비티입니다. 이 액티비티는 카메라로 읽어들인 이미지에서 실시간으로 객체 탐지를 수행합니다.
먼저 클래스에서 선언한 변수부터 살펴 보겠습니다.
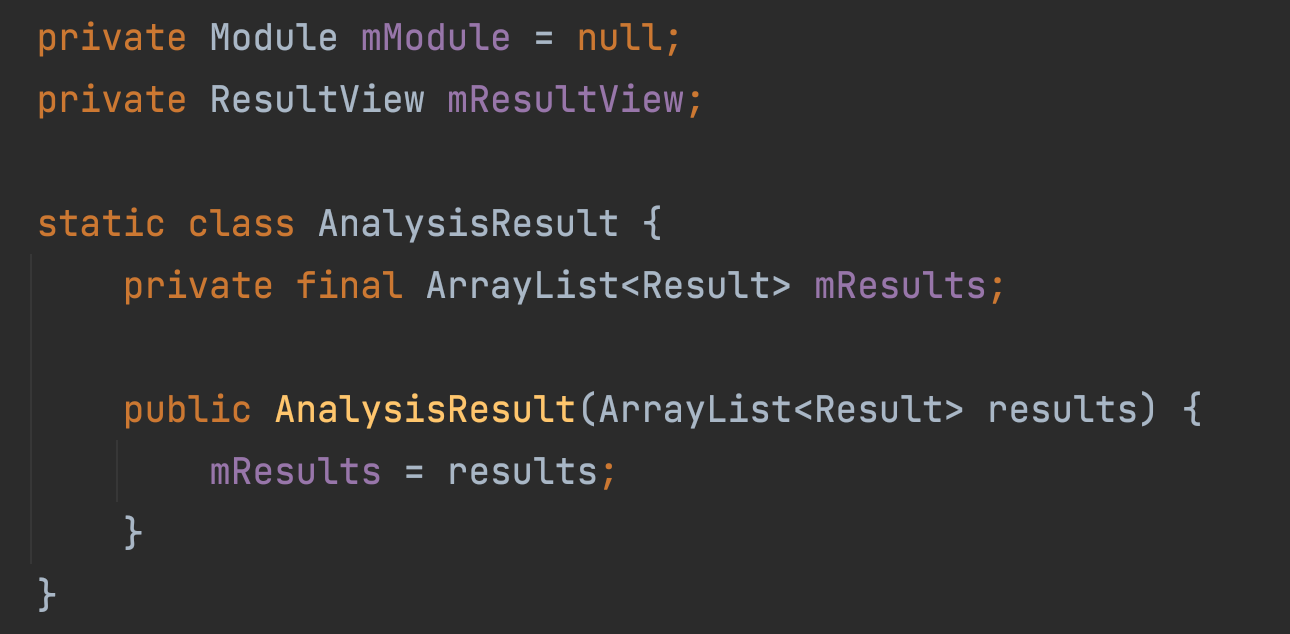
변수 선언부
파이토치 모델을 담고 객체 탐지를 할 모듈, 객체 탐지 결과를 화면에 표시하기 위한 ResultView, 탐지 결과를 저정하는 AnalysisResult 클래스가 있습니다. Result 클래스는 PrePostProcessor.java 내부에 있는 클래스로 탐지한 객체의 분류와 스코어, 좌표를 가지고 있습니다.
class Result {
int classIndex;
Float score;
Rect rect;
public Result(int cls, Float output, Rect rect) {
this.classIndex = cls;
this.score = output;
this.rect = rect;
}
}
클래스 구조는 그렇게 깔끔하지 않습니다. 예제임을 감안하면서 봐 주세요.
그 다음으로는 getCameraPreviewTextureView() 메소드를 살펴보겠습니다. AbstractCameraXActivity에서 정의된 메소드로, 카메라에서 받아온 영상을 어느 뷰에 표시할 것인지 반환하고 있습니다.
@Override
protected TextureView getCameraPreviewTextureView() {
mResultView = findViewById(R.id.*resultView*);
return ((ViewStub) findViewById(R.id.*object_detection_texture_view_stub*))
.inflate()
.findViewById(R.id.*object_detection_texture_view*);
}
먼저 객체 탐지 결과를 표시하기 위한 mResultView 변수를 초기화 해 주고, 그 다음으로는 카메라에서 실시간으로 표시를 해 주기 위한 TextureView를 반환하고 있습니다. object_detection_texture_view.xml 화면 내에 있는 texture_view.xml을 가져오기 위한 코드라고 보시면 됩니다.
안드로이드에서는 특정 뷰나 레이아웃을 가져와서 inflate() 메소드를 호출해서 메모리에 그 화면을 객체화시켜 조작을 합니다. 즉, object_detection_texture_view_stub로 등록된 뷰를 가져와서 객체화, 실체화, 메모리에 로딩한 뒤에 그 뷰 내부에서 id가 object_detection_texture_view인 뷰를 또다시 가져온다 정도로 생각하시면 됩니다.
객체 탐지 결과를 화면에 표시하는 applyToUiAnalyzeImageResult() 메소드는 화면에 결과를 표시하는 처리만 하는군요. 결과값을 ResultView에 넣어주고 새롭게 저장된 결과값을 화면에 그려주도록 invalidate()를 호출합니다. invalidate() 메소드는 특정 뷰의 위치나 색상같은 내용이 변경되어 화면 갱신이 필요한 경우, 변경된 값을 기반으로 뷰를 화면에 다시 화면에 그려주는 메소드입니다.
@Override
protected void applyToUiAnalyzeImageResult(AnalysisResult result) {
mResultView.setResults(result.mResults);
mResultView.invalidate();
}
이 메소드는 실시간 객체 탐지를 위한 화면 분석이 끝나면 호출이 됩니다. ObjectDetectionActivity의 부모 클래스인 AbstractCameraXActivity 클래스의 imageAnalysis 콜백 선언부를 참고해 주세요.
imageAnalysis.setAnalyzer((image, rotationDegrees) -> {
if (SystemClock.*elapsedRealtime*() - mLastAnalysisResultTime < 500) {
return;
}
final R result = analyzeImage(image, rotationDegrees);
if (result != null) {
mLastAnalysisResultTime = SystemClock.*elapsedRealtime*();
runOnUiThread(() -> applyToUiAnalyzeImageResult(result));
}
});
부모 클래스에서 화면 분석이 끝날 때마다 결과 화면을 표시하도록 로직은 마련해 두고, 구체적으로 어떻게 화면에 표시할 것인지는 자식 클래스에서 정하게 해 두었습니다. 템플릿 메소드 패턴이라고 생각하시면 되겠습니다.
이제 이미지 분석 메소드인 analyzeImage() 메소드를 살펴볼 차례입니다. 이 메소드에서는 객체 탐지를 할 타겟 이미지를 비트맵으로 가져오는데, 비트맵으로 가져오기 위한 처리를 하는 imgToBitmap() 메소드 먼저 살펴보시죠.
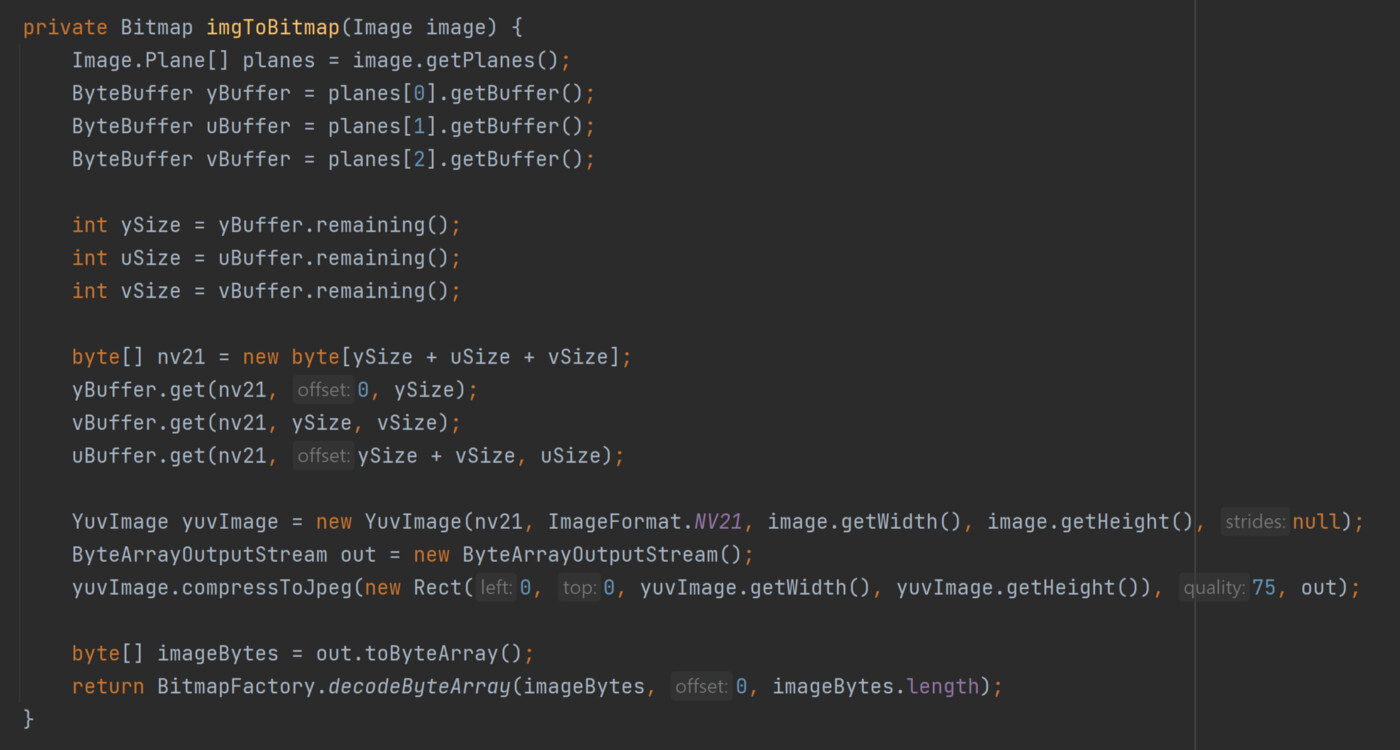
메인 화면에서는 이미지를 비트맵으로 가져오기 위해 BitMapFactory나 Bitmap 객체에서 지원하는 메소드들을 바로 사용했습니다만, 여기에서는 중간 단계를 조금 더 거치고 있습니다. 실시간으로 받아오는 이미지가 ImageProxy 형태로 되어 있고, 여기에서 Image 객체를 받아온 이후 객체 탐지 모델에 입력할 수 있는 비트맵 형태로 변환해 준다고 생각하시면 됩니다. 상당히 복잡한 코드인데, 인공지능 등의 이미지 처리를 위한 Image 객체에서 필요한 정보를 배열로 가져온 다음 비트맵으로 다시 조립하는 로직입니다. 이미지를 화면에 그려주는 용도가 아닌지라 배열 등의 로우 데이터를 직접 조작하는 로직이라고 보시면 됩니다.
NV21 포맷의 이미지로 만든 다음에 비트맵으로 다시 변환해 주고 있는데, 이 변환 코드는 여기에서 가져온 것 코드이기에 왜 이렇게 변환했는지는 해당 링크 참고해 주세요. camera x 관련 내용 때문에 어려울 수도 있는데, 제품을 만드는 것이 아닌 예제 프로젝트 제작이나 특정 기능을 구현하기 위해 인터넷에서 코드를 가져올 수도 있다는 것도 알아두세요. 남이 만들어둔 코드를 잘 활용하는 것도 도움이 됩니다.
이제 마지막으로 analyzeImage() 메소드를 살펴보겠습니다. 앞부분에는 YOLO5 모델을 가져오고, 만약에 없으면 예외를 발생시키고 있습니다. MainActivity에서 모델을 초기화 하는데 공용으로 사용하는 처리를 했으면 어떨까 싶기도 하네요.
try {
if (mModule == null) {
mModule = LiteModuleLoader.*load*(MainActivity.*assetFilePath*(getApplicationContext(), "yolov5s.torchscript.ptl"));
}
} catch (IOException e) {
Log.*e*("Object Detection", "Error reading assets", e);
return null;
}
그 이후엔 비트맵을 모델이 받을 수 있도록 처리하고 있습니다.
Bitmap bitmap = imgToBitmap(image.getImage());
Matrix matrix = new Matrix();
matrix.postRotate(90.0f);
bitmap = Bitmap.*createBitmap*(bitmap, 0, 0, bitmap.getWidth(), bitmap.getHeight(), matrix, true);
Bitmap resizedBitmap = Bitmap.*createScaledBitmap*(bitmap, PrePostProcessor.*mInputWidth*, PrePostProcessor.*mInputHeight*, true);
final Tensor inputTensor = TensorImageUtils.*bitmapToFloat32Tensor*(resizedBitmap, PrePostProcessor.*NO_MEAN_RGB*, PrePostProcessor.*NO_STD_RGB*);
IValue[] outputTuple = mModule.forward(IValue.*from*(inputTensor)).toTuple();
final Tensor outputTensor = outputTuple[0].toTensor();
final float[] outputs = outputTensor.getDataAsFloatArray();
앞서 나온 MainActivity와 거의 동일한 코드를 사용하네요. 이미지를 가져와서 모델에 입력시키기 위해 텐서로 만들고, forward() 메소드를 이용해 모델에서 객체 탐지를 수행합니다. 카메라에서 가져온 이미지를 처리하기 위해 앞서 설명한 imgToBitmap()메소드를 사용하여 비트맵을 만들어 주는 것만 주의해 주세요.
마지막으로 NMS를 이용해서 결과값을 나타내고 있습니다.
float imgScaleX = (float)bitmap.getWidth() / PrePostProcessor.*mInputWidth*;
float imgScaleY = (float)bitmap.getHeight() / PrePostProcessor.*mInputHeight*;
float ivScaleX = (float)mResultView.getWidth() / bitmap.getWidth();
float ivScaleY = (float)mResultView.getHeight() / bitmap.getHeight();
final ArrayList<Result> results = PrePostProcessor.*outputsToNMSPredictions*(outputs, imgScaleX, imgScaleY, ivScaleX, ivScaleY, 0, 0);
return new AnalysisResult(results);
이렇게 생성된 결과값 AnalysisResult은 AbstractCameraXActivity에서 applyToUiAnalyzeImageResult() 메소드로 전달되어 화면을 갱신하게 됩니다.
final R result = analyzeImage(image, rotationDegrees);
if (result != null) {
mLastAnalysisResultTime = SystemClock.*elapsedRealtime*();
runOnUiThread(() -> applyToUiAnalyzeImageResult(result));
}
전체적으로 까다로운 부분이 군데군데 보이는 예제군요. 객체 탐지를 위한 이미지를 비트맵으로 변환해서 입력하는 부분은 android x의 이미지 처리 관련 지식이 필요하고, 모델에서 출력한 결과 중 제일 정확한 객체의 테두리를 구하기 위한 NMS는 객체 탐지 모델이 어떻게 구성되어 있는지 알아야 하면서 안드로이드에서 직접 구현해야 되는 부분이기도 합니다. 한마디로 말하자면 안드로이드와 인공지능 지식이 둘 다 어느 정도 있어야 완벽히 이해가 되는 예제로군요.
그럼에도 모델이 어떻게 동작하는지 대략적인 흐름을 확인하기엔 좋은 예제인 것 같습니다. 군데군데 어려운 부분이 있지만, 이런 것들이 실제로 모델을 어떻게 동작시킬 것인지에 대해 더 깊은 이해를 할 수 있는 부분입니다. 실무에서도 이런 것들을 어떻게 처리하느냐에 따라 서비스의 퀄리티가 엄청나게 차이나기도 합니다만, 예제 코드 분석이니만큼 가벼운 마음으로 접근하는 것도 좋습니다.
위의 글은 미디움에도 작성해서 올려 뒀습니다.