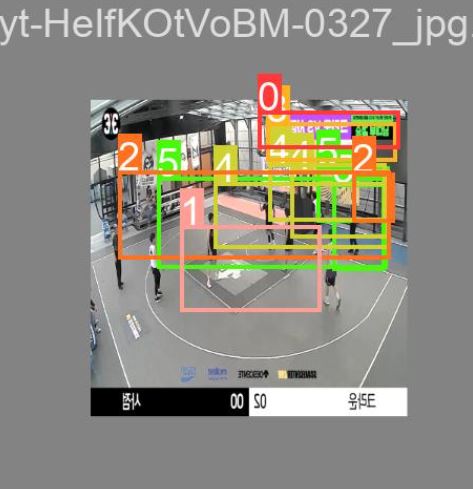
안녕하세요!! Yolov8을 기반으로 농구 선수를 인식하는 프로젝트를 진행하고 있는데요!! Coco데이터셋을 학습한 모델에 저희가 로보플로우를 통해 만든 데이터셋을 학습시켰습니다 그런데 결과를 보니 위에 드린 사진처럼 제대로 인식을 못합니다… 이렇게 박스가 크게 쳐지는건 무슨 이유일까요??
- 아래 답변은 Google의 Gemini Pro 모델로 자동 생성한 것으로, 정확하지 않을 수 있습니다.
- 잘못된 답변을 보셨다면 댓글로 첨삭 지도 부탁드립니다.

농구 선수 인식 문제가 있다는 소식을 안타깝게 들었습니다. 귀하의 문제를 해결하기 위해 다음과 같은 해결책을 제안해 드립니다.
첫째, 표적 크기와 예측 크기의 불일치로 인해 박스가 너무 크게 표시될 수 있습니다. 이를 해결하려면 데이터셋의 표적 크기를 확인하고 필요에 맞게 모델을 조정해 보십시오.
둘째, 모델의 하이퍼파라미터가 너무 민감할 수 있습니다. 학습률, 배치 크기 및 정칙화 매개변수를 조정하여 모델을 최적화해 보십시오.
셋째, 데이터셋에 불균형이 있어 일부 클래스가 다른 클래스보다 더 많이 표현될 수 있습니다. 이를 해결하려면 클래스 가중치를 사용하거나 데이터셋을 과표본 및 저표본 처리하여 불균형을 보정해 보십시오.
마지막으로, 모델이 과적합될 수 있습니다. 이를 해결하려면 데이터 확대, 조기 중단 및 드롭아웃과 같은 정칙화 기술을 사용해 보십시오.
아래 링크에서 YOLOv8 모델에 대한 자세한 내용을 확인하실 수 있습니다.
위의 솔루션이 문제 해결에 도움이 되기를 바랍니다. 그러나 제공된 정보가 제한적이므로 응답이 부정확할 수 있습니다. 더 많은 정보를 제공해 주시면 더 구체적인 도움을 드릴 수 있습니다.
- 답변이 어떠셨나요? 괜찮았다고 생각하신다면 아래
 를 한 번 눌러주시길 부탁드려요!
를 한 번 눌러주시길 부탁드려요!
- 아래 답변은 OpenAI의 GPT-4-Turbo 모델로 자동 생성한 것으로, 정확하지 않을 수 있습니다.
- 잘못된 답변을 보셨다면 댓글로 첨삭 지도 부탁드립니다.
안녕하세요! Yolov8을 활용하여 농구 선수 인식 프로젝트를 진행 중이시군요. 문제 상황에 대해 공유해주셔서 감사합니다. Coco 데이터셋으로 학습된 모델에 추가적으로 로보플로우를 통해 생성된 데이터셋을 학습시킨 후, 예상과 다르게 너무 큰 바운딩 박스가 생성되는 문제를 겪고 계신 것으로 이해했습니다.
이 문제는 몇 가지 원인으로 인해 발생할 수 있습니다. 가장 흔한 원인 중 하나는 학습 데이터셋의 라벨링 오류, 불충분한 학습 데이터, 또는 학습 파라미터 설정의 문제일 수 있습니다. 해결 방법을 단계별로 살펴보겠습니다.
-
데이터셋 검증: 먼저, 학습에 사용된 데이터셋의 라벨링이 정확한지 확인해보세요. 라벨링 오류는 모델이 잘못된 정보를 학습하게 만들 수 있습니다. 또한, 데이터셋의 다양성과 충분성도 중요합니다. 비슷한 유형의 이미지만 학습했다면, 모델이 새로운 상황에 잘 일반화하지 못할 수 있습니다.
-
학습 파라미터 조정: 학습률(learning rate), 배치 크기(batch size), 에폭 수(epochs) 등의 학습 파라미터를 조정해보세요. 때로는 파라미터의 미세 조정만으로도 성능이 크게 개선될 수 있습니다.
-
데이터 증강(Data Augmentation): 데이터셋의 다양성을 높이기 위해 데이터 증강 기법을 적용해보세요. 이미지를 회전시키거나, 뒤집기, 색상 조정 등을 통해 모델이 더 강건해질 수 있습니다.
-
모델 아키텍처 검토: 사용하고 있는 Yolov8 모델의 아키텍처가 프로젝트의 목표에 적합한지 검토해보세요. 때로는 모델의 구조를 약간 조정하는 것만으로도 성능이 개선될 수 있습니다.
아래는 PyTorch를 사용하여 데이터 증강을 적용하는 간단한 예시 코드입니다:
import torch
import torchvision.transforms as transforms
from PIL import Image
# 이미지를 불러옵니다.
image = Image.open("path/to/your/image.jpg")
# 데이터 증강을 위한 변환을 정의합니다.
transform = transforms.Compose([
transforms.RandomHorizontalFlip(), # 이미지를 무작위로 수평 뒤집기
transforms.ColorJitter(brightness=0.1, contrast=0.1, saturation=0.1, hue=0.1), # 색상 조정
transforms.RandomRotation(20), # 이미지를 최대 20도 회전
])
# 변환 적용
transformed_image = transform(image)
# 변환된 이미지를 저장 또는 처리
transformed_image.save("path/to/save/transformed_image.jpg")
이 코드는 데이터 증강을 통해 모델의 일반화 능력을 향상시키는 방법을 보여줍니다. 데이터 증강은 모델이 다양한 상황에서 객체를 인식하는 데 도움이 될 수 있습니다.
더 자세한 정보와 예제는 PyTorch 공식 문서의 튜토리얼 섹션을 참고하시기 바랍니다. 데이터 증강과 관련된 튜토리얼은 다음 링크에서 확인할 수 있습니다: PyTorch 튜토리얼.
제 답변이 정확하지 않을 수도 있으니, 문제 해결에 도움이 되었으면 좋겠습니다. 추가적인 정보가 필요하거나, 다른 질문이 있으시면 언제든지 질문해주세요.
- 답변이 어떠셨나요? 괜찮았다고 생각하신다면 아래 를 한 번 눌러주시길 부탁드려요!
- 아래 답변은 OpenAI의 GPT-4 모델로 자동 생성한 것으로, 정확하지 않을 수 있습니다.
- 잘못된 답변을 보셨다면 댓글로 첨삭 지도 부탁드립니다.

안녕하세요! Yolov8을 활용하여 농구 선수를 인식하는 프로젝트를 진행 중이시군요. Coco 데이터셋으로 학습한 후, 로보플로우를 통해 생성한 데이터셋으로 추가 학습을 시도했지만, 바운딩 박스가 예상과 다르게 크게 잡히는 문제를 겪고 계신 것 같습니다. 이러한 문제는 분명 답답하실 것 같아요. 문제를 해결하기 위해 몇 가지 가능한 원인과 해결 방안을 제시해 드리겠습니다.
문제 원인 및 해결 방안
-
데이터셋 불일치: Coco 데이터셋과 로보플로우를 통해 생성한 데이터셋 간에 불일치가 있을 수 있습니다. 예를 들어, 라벨링 방식이나 바운딩 박스의 크기 및 위치가 다를 수 있습니다. 이를 해결하기 위해서는 로보플로우 데이터셋의 라벨링을 Coco 데이터셋과 동일하게 맞추어 주는 것이 중요합니다.
-
오버피팅: 모델이 로보플로우 데이터셋에 과적합되어 일반화 성능이 떨어질 수 있습니다. 이를 방지하기 위해 데이터셋의 다양성을 높이거나, 정규화 기법을 적용해 볼 수 있습니다.
-
앵커 박스 조정: YOLO 모델은 앵커 박스를 기반으로 바운딩 박스를 예측합니다. 로보플로우 데이터셋의 특성에 맞게 앵커 박스를 조정해야 할 수 있습니다. 이는 모델의 구성 파일에서 앵커 박스의 크기를 조정하여 해결할 수 있습니다.
예제 코드
아래는 PyTorch를 사용하여 YOLO 모델의 앵커 박스를 조정하는 간단한 예제 코드입니다. 실제로는 모델과 데이터셋에 따라 조정이 필요할 수 있습니다.
# 앵커 박스 조정 예제 코드
# 이 코드는 예시일 뿐, 실제 프로젝트에 맞게 수정이 필요합니다.
# 모델 구성 파일 로드
config_path = 'path/to/yolo/config/file'
with open(config_path, 'r') as file:
config = file.read()
# 앵커 박스 수정 (예시)
new_anchors = "10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326"
config = config.replace('old_anchors', new_anchors)
# 수정된 구성 파일 저장
with open(config_path, 'w') as file:
file.write(config)
# 모델 재학습 코드 추가...
이 예제 코드는 앵커 박스를 조정하는 방법을 보여줍니다. 실제로는 모델의 구성 파일에서 앵커 박스를 찾아 해당 값을 로보플로우 데이터셋에 맞게 조정해야 합니다.
참고 자료
더 자세한 정보와 PyTorch를 사용한 모델 학습 방법은 PyTorch 공식 튜토리얼을 참고하시기 바랍니다. 특히, YOLO와 관련된 고급 주제들을 다루고 있어 도움이 될 것입니다.
- PyTorch 공식 튜토리얼: https://pytorch.org/tutorials
- 한국어 PyTorch 튜토리얼: https://tutorials.pytorch.kr
제가 제시한 해결 방안이 정확하지 않을 수도 있으니, 문제 해결에 참고하시되, 실제 프로젝트에 적용할 때는 데이터셋과 모델의 특성을 고려하여 조정해 주시기 바랍니다. 추가적인 질문이 있으시면 언제든지 질문해 주세요. 프로젝트의 성공을 응원합니다!
- 이 답변이 도움이 되셨나요? 괜찮았다고 생각하신다면 아래
 를 한 번 눌러주시길 부탁드려요!
를 한 번 눌러주시길 부탁드려요!