
GLM-5 소개
인공지능 기술의 발전이 거듭됨에 따라 개발자 생태계는 단순한 코드 스니펫 생성을 넘어 복잡한 시스템 단위의 작업을 자율적으로 수행할 수 있는 모델을 요구하고 있습니다. 이러한 흐름에 맞춰 Z.ai(Zhipu AI)는 2026년 2월, 복잡한 시스템 엔지니어링과 장기적인 에이전트(Agentic) 작업에 특화된 차세대 플래그십 파운데이션 모델인 GLM-5를 새롭게 선보였습니다. 이 모델은 그동안 인기를 끌었던 단순한 텍스트 프롬프트 기반의 '바이브 코딩(Vibe Coding)' 수준을 뛰어넘어, 다단계의 계획 수립, 외부 도구의 능동적 호출, 시스템 상태 유지 및 오류 발생 시의 롤백(Rollback)까지 아우르는 '에이전틱 엔지니어링(Agentic Engineering)'으로의 패러다임 전환을 목표로 설계되었습니다. 즉, 인간 개발자가 여러 도구를 오가며 수십 단계에 걸쳐 수행해야 하는 장기 프로젝트를 AI가 엔드투엔드(End-to-End)로 관리하고 실행할 수 있도록 지능과 효율성을 극대화한 것이 가장 큰 특징입니다.
GLM-5는 인공일반지능(AGI)으로 나아가기 위해 모델의 매개변수와 학습 데이터 규모를 대폭 확장하는 방식을 택했습니다. 단순히 크기만 키운 것이 아니라, 추론 능력, 코딩 역량, 그리고 자율적인 에이전트 작업 수행 측면에서 전 세계 오픈소스 모델 중 단연 최고 수준의 성능(SOTA)을 달성하며 글로벌 개발자 커뮤니티에 큰 충격을 안겨주었습니다. 특히, 프론티어급 폐쇄형(Closed) 상용 모델들에 필적하는 프로덕션급 성능을 제공하도록 정교하게 튜닝되어, 기존에 보안이나 비용 문제로 최고 수준의 AI 도입을 망설였던 기업과 개인 개발자들에게 완벽한 대안을 제시하고 있습니다.
단순한 코드 생성뿐만 아니라 기획자와 지식 노동자의 업무 생산성을 극대화하기 위한 문서 생성 및 관리 기능도 내장되어 있습니다. GLM-5는 채팅 기반의 작업 지시를 넘어, 사용자가 제공한 텍스트나 원본 소스 자료를 바탕으로 제품 요구사항 정의서(PRD), 재무 보고서, 시험지 등의 복잡한 완성본 문서를 .docx, .pdf, .xlsx와 같은 실제 오피스 파일 형식으로 즉시 생성해냅니다. 사용자는 Z.ai의 공식 웹사이트 또는 애플리케이션의 에이전트 모드를 통해 다중 회차에 걸친 협업을 진행하며 결과물을 세밀하게 다듬어 나갈 수 있습니다. 이처럼 GLM-5는 개발 영역부터 기획 및 일반 사무 영역까지 애플리케이션의 경계를 허물며 실질적인 '업무 파트너'로서의 입지를 확고히 하고 있습니다.
GLM-5 모델 vs. 이전 세대 모델 비교
GLM-5는 아키텍처 규모와 처리 능력 면에서 이전 세대 모델인 GLM-4.5에 비해 비약적인 발전을 이루어냈습니다. GLM-4.5가 총 3,550억 개(355B)의 매개변수와 토큰당 320억 개(32B)의 활성화 매개변수를 가졌던 반면, GLM-5는 총 7,440억 개(744B)의 매개변수와 토큰당 400억 개(40B)의 활성화 매개변수를 사용하는 거대한 규모로 확장되었습니다. 모델의 기초 지식을 형성하는 사전 학습(Pre-training) 데이터 역시 기존 23조(23T) 토큰에서 28.5조(28.5T) 토큰으로 대폭 증가했습니다. 이러한 확장을 바탕으로 내부 평가 세트인 CC-Bench-V2를 비롯하여 프론트엔드 및 백엔드 개발, 장기 작업 지속성 테스트 등에서 GLM-4.7 등 이전 세대를 압도하는 성능 향상을 기록했습니다.
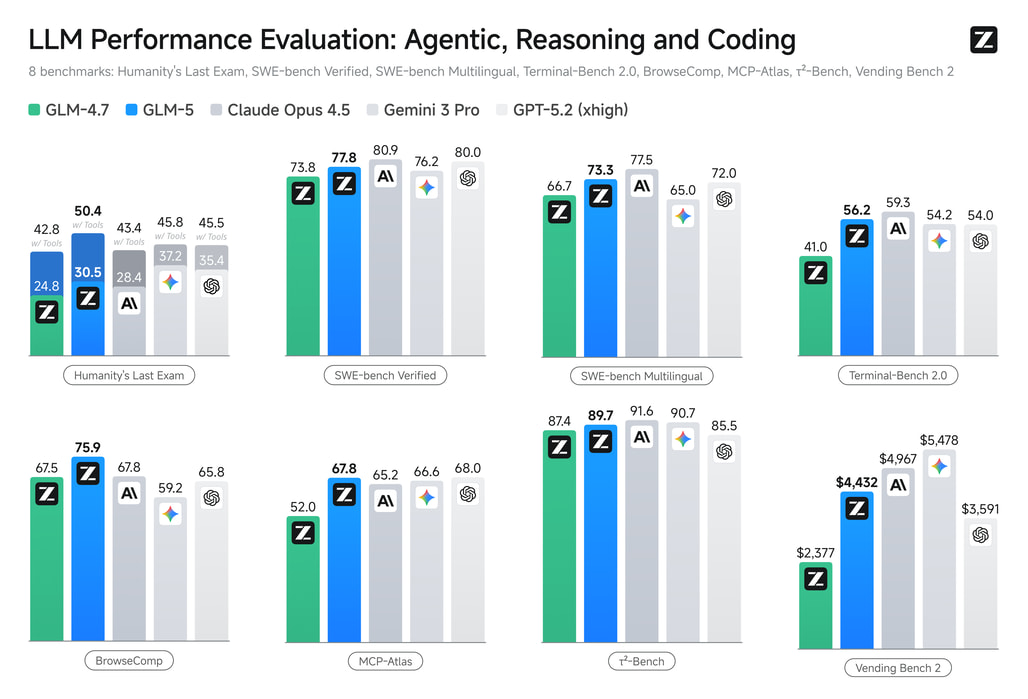
전 세계 최상위권의 상용 모델들과 직접 경쟁하는 벤치마크 평가에서도 GLM-5의 성과는 눈부십니다. 대표적인 코딩 평가 지표인 SWE-bench Verified에서 77.8점이라는 놀라운 점수를 기록했으며, 실제 환경의 터미널 조작 능력을 평가하는 Terminal-Bench 2.0(Terminus 2) 및 BrowserComp(62.0점) 등에서도 탁월한 성과를 보였습니다.
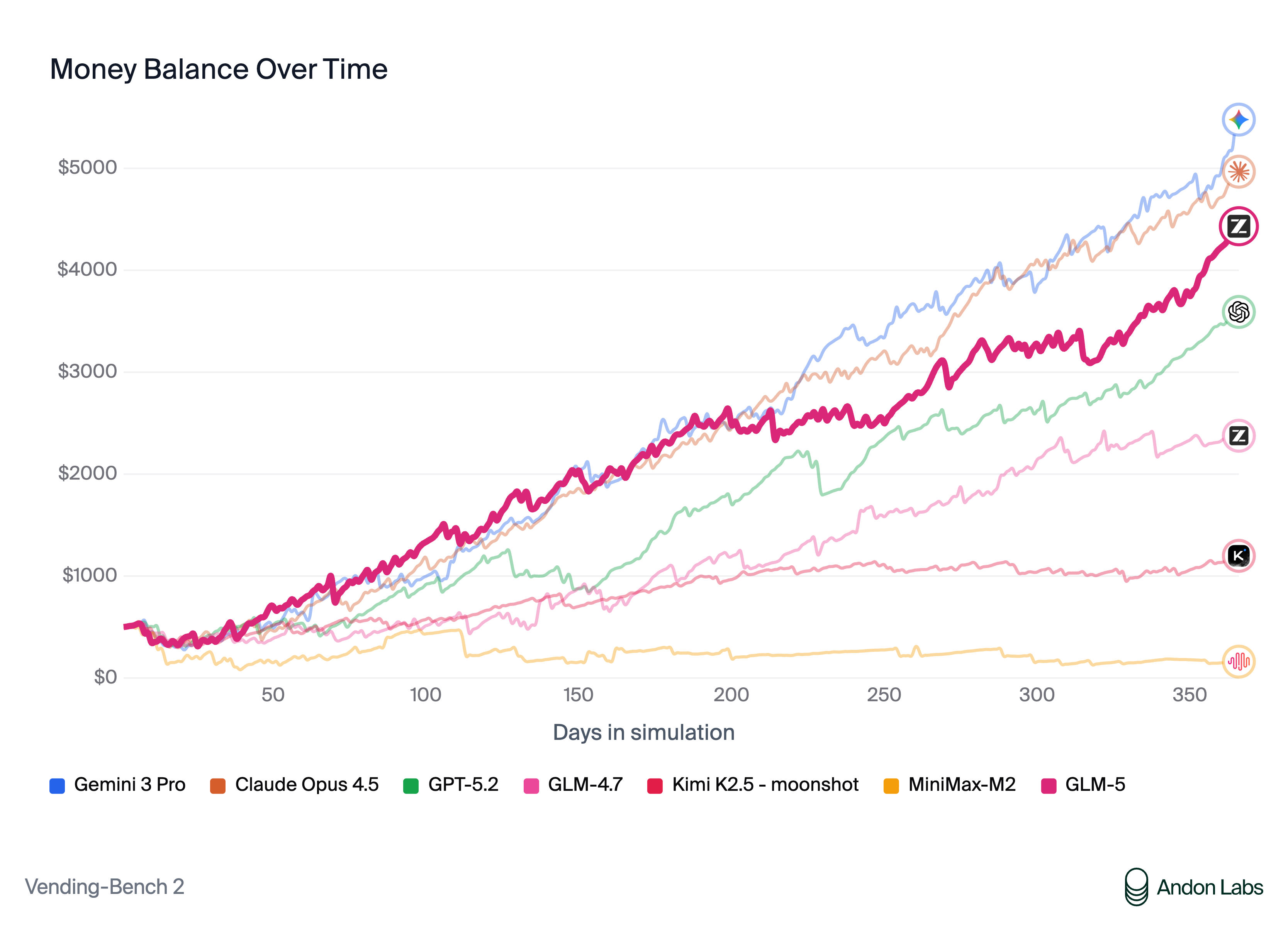
특히, 1년이라는 긴 시간 동안 가상의 자판기 사업을 운영하는 시뮬레이션 환경인 Vending Bench 2 벤치마크에서는 오픈소스 모델 중 1위를 차지했으며, 최종 잔고 4,432달러를 기록하여 최고 수준의 폐쇄형 모델인 Claude Opus 4.5(최종 잔고 4,967달러)의 장기 기획력 및 자원 관리 능력에 매우 근접했음을 스스로 증명했습니다. 학술적 추론을 평가하는 GPQA Diamond에서도 86.0점을 달성하며 GPT-5.2나 Gemini 3.0 Pro와 같은 최신 프론티어 모델들과의 격차를 실질적으로 지워냈습니다.
GLM-5의 주요 특징
대규모 MoE 아키텍처 및 DeepSeek Sparse Attention 도입
총 7,440억 개라는 방대한 매개변수를 지닌 GLM-5 모델을 실제 프로덕션 환경에서 경제적으로 구동하기 위해, GLM-5는 전문가 혼합(MoE, Mixture-of-Experts) 아키텍처를 기반으로 설계되었습니다. MoE 구조를 통해 모델은 입력되는 데이터의 성격에 따라 744B의 전체 신경망 중 약 40B 규모의 하위 네트워크만 선택적으로 활성화합니다. 이를 통해 모델의 지능과 파라미터 용량은 극대화하면서도 추론 시 발생하는 VRAM 소모와 연산 리소스를 혁신적으로 절감할 수 있게 되었습니다.
여기에 더해, GLM-5는 수십만 토큰에 달하는 방대한 컨텍스트를 처리할 때 발생하는 메모리 병목 현상을 해결하기 위해 DeepSeek Sparse Attention (DSA) 메커니즘을 새롭게 통합했습니다. 기존의 밀집(Dense) 어텐션 방식은 문맥이 길어질수록 연산량이 기하급수적으로 증가하여 200K 이상의 컨텍스트를 유지하기가 매우 어려웠습니다. 그러나 DSA 구조의 도입으로 과거의 컨텍스트 중 현재 추론에 가장 핵심적인 정보만 희소(Sparse)하게 참조할 수 있게 됨으로써, 무려 20만(200K) 토큰 이상의 장문 처리 용량을 안정적으로 유지하면서도 서버 배포 비용과 지연 시간(Latency)을 획기적으로 낮추었습니다.
혁신적인 비동기 강화학습 인프라 'Slime'
사전 학습된 모델이 단순히 지식을 나열하는 수준을 넘어 인간의 복잡한 의도를 정확히 따르고 에이전트로서 훌륭하게 작동하려면 사후 학습(Post-training), 특히 강화학습(RL, Reinforcement Learning) 과정이 필수적입니다. 그러나 모델의 규모가 700B를 넘어가면 기존의 동기식 강화학습 환경에서는 데이터를 생성(Rollout)하는 시간과 모델을 학습(Training)하는 시간 사이의 병목으로 인해 훈련 효율이 극도로 저하되는 문제가 발생합니다. Z.ai 연구진은 이 한계를 극복하기 위해 'Slime'이라는 독자적인 비동기 강화학습 인프라를 새롭게 개발하여 적용했습니다.
Slime 인프라는 데이터 생성 과정과 학습 과정을 별도의 하드웨어에서 비동기적으로 분리하여 실행합니다. 이를 통해 학습을 담당하는 GPU는 대기 시간 없이 지속적으로 파라미터를 업데이트하고, 데이터 생성 서버는 병렬로 피드백 데이터를 무한히 공급합니다. 이러한 아키텍처 혁신 덕분에 대규모 모델의 훈련 처리량(Throughput)과 효율성이 비약적으로 상승하였고, 결과적으로 GLM-5가 프로그래밍 도구 사용, 터미널 제어, 오류 수정과 같은 매우 세밀하고 복잡한 에이전트 작업에 대해 무수히 많은 사후 학습 반복(Iteration)을 거칠 수 있도록 만들었습니다. 이것이 바로 GLM-5가 다양한 에이전틱 벤치마크에서 타 오픈소스 모델들을 압도할 수 있었던 핵심 비결입니다.
다양한 개발 환경 통합 및 유연한 배포 생태계
오픈소스 철학에 기반한 GLM-5는 전 세계의 다양한 개발자와 인프라 환경을 지원하기 위해 매우 유연한 배포 옵션을 제공합니다. 모델의 가중치는 Hugging Face 저장소 및 ModelScope에 완전하게 공개되었으며, vLLM과 SGLang 같은 최신 고성능 추론 프레임워크를 기본적으로 지원합니다. 특히 SGLang을 활용할 경우, 공식적으로 제공되는 Docker 이미지(예: docker pull lmsysorg/sglang:glm5-hopper)를 통해 복잡한 의존성 설정 없이 로컬의 다중 GPU 환경에 모델을 즉시 배포할 수 있습니다. 또한 NVIDIA GPU 외에도 Huawei Ascend, Moore Threads, Cambricon 등 다양한 비(非) NVIDIA 칩셋에서도 원활하게 실행되도록 커널 최적화가 이루어져 있어 인프라 종속성을 탈피했습니다.
로컬 하드웨어 자원이 부족하거나 클라우드 환경을 선호하는 사용자들을 위해 API 및 주요 코딩 에이전트와의 완벽한 연동 또한 지원합니다. 개발자 플랫폼이나 BigModel.cn을 통해 제공되는 OpenAI 호환 API 인터페이스를 사용하면 기존 애플리케이션 코드를 거의 수정하지 않고도 GLM-5의 강력한 능력을 통합할 수 있으며, 입력 100만 토큰당 약 $0.672라는 매우 합리적인 비용으로 서비스를 운영할 수 있습니다. 나아가 Claude Code, Roo Code, OpenClaw 등 인기 있는 코딩 CLI 도구들과의 직접 통합도 지원하여, 사용자는 단순히 설정 파일(~/.claude/settings.json 등)에서 모델 이름만 "GLM-5"로 변경하면 자신이 평소 즐겨 쓰던 터미널 환경에서 프론티어급 에이전틱 코딩 기능을 곧바로 경험할 수 있습니다.
GLM-5 로컬 배포 방법
GLM-5는 오픈소스 생태계를 적극 지원하며, vLLM, SGLang, KTransformers, xLLM 등 다양한 최신 추론 프레임워크를 통해 로컬 환경에 배포할 수 있습니다. 여기에서는 vLLM을 활용한 GLM-5 모델을 로컬 배포하는 방법을 살펴보겠습니다.
먼저, pip를 사용하여 최신 버전(nightly 빌드)의 vLLM 또는 transformers 라이브러리를 설치하여 환경을 준비합니다:
# nightly 버전의 vllm 설치
pip install -U vllm --pre --index-url https://pypi.org/simple --extra-index-url https://wheels.vllm.ai/nightly
# 소스코드로부터 transformers 라이브러리설치
pip install git+https://github.com/huggingface/transformers.git
이후, vLLM을 사용하여 모델을 다운로드 및 실행합니다. 다음은 텐서 병렬 처리(Tensor Parallelism)를 위해 8장의 GPU(--tensor-parallel-size 8)에서 GLM-5-FP8 모델을 실행하는 예시 명령어입니다:
vllm serve zai-org/GLM-5-FP8 \
--tensor-parallel-size 8 \
--gpu-memory-utilization 0.85 \
--speculative-config.method mtp \
--speculative-config.num_speculative_tokens 1 \
--tool-call-parser glm47 \
--reasoning-parser glm45 \
--enable-auto-tool-choice \
--served-model-name glm-5-fp8
그 외애도 SGLang 및 KTransformers, xLLM 등을 활용하여 배포하는 방법은 Hugging Face의 GLM-5 모델 카드를 참고해주세요.
 GLM-5 출시 블로그
GLM-5 출시 블로그
GLM-5 사용 문서
 GLM-5 프로젝트 GitHub 저장소
GLM-5 프로젝트 GitHub 저장소
 GLM-5 모델 다운로드
GLM-5 모델 다운로드
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()