- 이 글은 GPT 모델로 자동 요약한 설명으로, 잘못된 내용이 있을 수 있으니 원문을 참고해주세요!

- 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다!

소개
이번 주의 논문들은 대부분 LLM(Large Language Models)에 초점을 맞춘 것으로 보입니다. 그 중에서도 여러 환경에서의 LLM 프로세스 효율성 알고리즘 개선, LLM의 Graph Neural Prompting, 논리적 사고 과정의 적용 등 다양한 주제들을 다루고 있네요. 올해는 머신러닝 및 딥러닝 학계에서 언어모델에 대한 연구가 활발한 추세입니다.
LLM의 연구는 가장 기본적인 인공지능분야인 자연어 처리(NLP)를 이해하고 그 성능을 향상시키는 데 큰 도움이 됩니다. 이번 주에 선택된 논문들은 대부분 이러한 언어모델에 관련된 주제를 다뤘습니다. 이것은 이번 주의 주요 추세를 설정합니다.
또한, 이번 주에 선택된 논문들 중에는 'Boolformer'와 'Vision Transformers Need Registers' 같은 논문들은 다른 AI 분야와 융합하여 연구가 진행되는 추세도 볼 수 있습니다. 이렇듯 AI 기술의 발전은 각 분야를 개별적으로 발굴하는 것뿐만 아니라 여러 분야를 융합하여 새로운 접근법과 해결책을 모색하는 중요한 일환임을 알 수 있습니다.
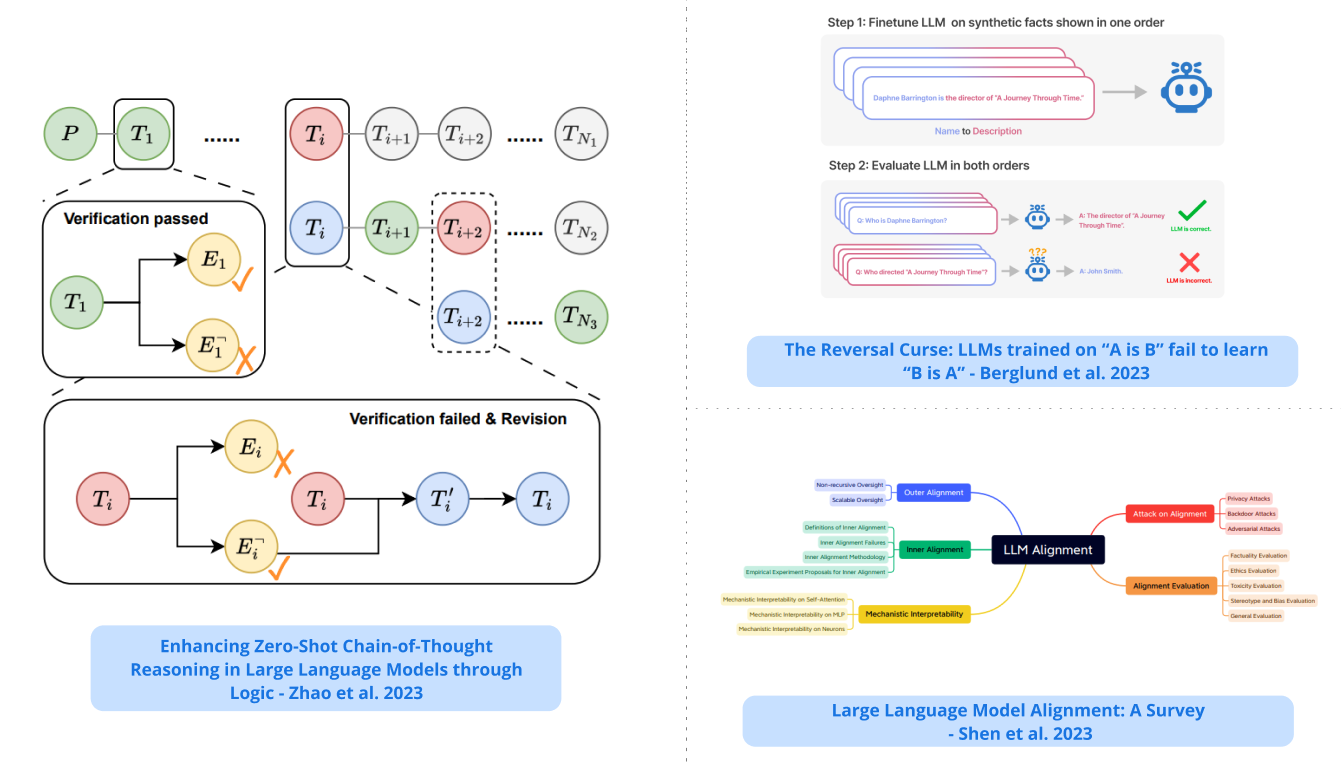
반전의 저주 / The Reversal Curse
논문 소개
- 'a는 b'라는 형식의 문장에 대해 학습된 인공신경망은 그 반대 방향인 'b는 a'로 자동 일반화되지 않는다는 사실, 즉 반전 저주를 발견하고, 가상의 문장에 대한 인공신경망을 미세 조정하고 모델 크기와 모델군 전반에 걸쳐 그 효과를 입증합니다. llm-reasoning
Finds that llms trained on sentences of the form “a is b” will not automatically generalize to the reverse direction “b is a”, i.e., the reversal curse; shows the effect through finetuning llms on fictitious statements and demonstrating its robustness across model sizes and model families.
논문 링크
더 읽어보기
https://x.com/OwainEvans_UK/status/1705285631520407821
파운데이션 모델의 효과적인 장기 컨텍스트 확장 / Effective Long-Context Scaling of Foundation Models
논문 소개
- 긴 컨텍스트 작업 모음에서 이미
gpt-3.5-turbo-16k의 전체 성능을 능가하는70b변형을 제안합니다. 여기에는 사람이 주석이 달린 긴 명령어 데이터가 필요하지 않은 비용 효율적인 명령어 튜닝 절차가 포함됩니다. llama llama2 llama2-long 1b-context-window 100k-context-windowPropose a 70b variant that can already surpass gpt-3.5-turbo-16k’s overall performance on a suite of long-context tasks. this involves a cost-effective instruction tuning procedure that does not require human-annotated long instruction data.
논문 초록
- 최대 32,768개 토큰의 효과적인 컨텍스트 창을 지원하는 일련의 긴 컨텍스트 LLM을 소개합니다. 당사의 모델 시리즈는 더 긴 학습 시퀀스와 긴 텍스트가 업샘플링된 데이터셋을 사용하여 Llama 2에서 지속적인 사전 학습을 통해 구축됩니다. 언어 모델링, 합성 문맥 프로빙 작업 및 다양한 연구 벤치마크에 대한 광범위한 평가를 수행합니다. 연구 벤치마크에서 우리 모델은 대부분의 일반 작업에서 일관되게 개선되었으며, 긴 컨텍스트 작업에서는 Llama 2에 비해 상당한 개선이 이루어졌습니다. 특히, 사람이 주석이 달린 긴 명령어 데이터를 필요로 하지 않는 비용 효율적인 명령어 튜닝 절차를 통해 70B 변형은 이미 긴 컨텍스트 작업에서 gpt-3.5-turbo-16k의 전체 성능을 능가할 수 있습니다. 이러한 결과와 함께, 저희는 이 방법의 개별 구성 요소에 대한 심층적인 분석을 제공합니다. Llama의 위치 인코딩에 대해 자세히 살펴보고 긴 종속성을 모델링할 때의 한계에 대해 논의합니다. 또한 데이터 조합과 시퀀스 길이의 학습 커리큘럼 등 사전 학습 과정에서 다양한 설계 선택이 미치는 영향을 살펴봅니다. 제거 실험을 통해 사전 학습 데이터셋에 긴 텍스트가 많다고 해서 강력한 성능을 달성할 수 있는 것은 아니며, 긴 시퀀스로 처음부터 사전 학습을 하는 것보다 긴 컨텍스트 연속 사전 학습이 더 효율적이고 비슷한 효과를 낸다는 사실을 경험적으로 검증합니다.
We present a series of long-context LLMs that support effective context windows of up to 32,768 tokens. Our model series are built through continual pretraining from Llama 2 with longer training sequences and on a dataset where long texts are upsampled. We perform extensive evaluation on language modeling, synthetic context probing tasks, and a wide range of research benchmarks. On research benchmarks, our models achieve consistent improvements on most regular tasks and significant improvements on long-context tasks over Llama 2. Notably, with a cost-effective instruction tuning procedure that does not require human-annotated long instruction data, the 70B variant can already surpass gpt-3.5-turbo-16k's overall performance on a suite of long-context tasks. Alongside these results, we provide an in-depth analysis on the individual components of our method. We delve into Llama's position encodings and discuss its limitation in modeling long dependencies. We also examine the impact of various design choices in the pretraining process, including the data mix and the training curriculum of sequence lengths -- our ablation experiments suggest that having abundant long texts in the pretrain dataset is not the key to achieving strong performance, and we empirically verify that long context continual pretraining is more efficient and similarly effective compared to pretraining from scratch with long sequences.
논문 링크
더 읽어보기
https://x.com/omarsar0/status/1707780482178400261
대규모 언어 모델을 사용한 그래프 신경망 프롬프트 / Graph Neural Prompting with Large Language Models
논문 소개
- 지식 그래프(Knowledge Graph)에서 유용한 지식을 학습할 수 있도록 사전 학습된 머신러닝을 지원하는 플러그 앤 플레이 방식을 제안하며, 표준 그래프 신경망 인코더, 크로스 모달리티 풀링 모듈, 도메인 프로젝터, 자기 감독 링크 예측 목표 등 다양한 설계가 포함되어 있습니다. knowledge-graph
Proposes a plug-and-play method to assist pre-trained llms in learning beneficial knowledge from knowledge graphs (kgs); includes various designs, including a standard graph neural network encoder, a cross-modality pooling module, a domain projector, and a self-supervised link prediction objective.
논문 초록
- 대규모 언어 모델(LLM)은 다양한 언어 모델링 작업에서 뛰어난 성능으로 놀라운 일반화 능력을 보여 왔습니다. 그러나 여전히 근거 지식을 정확하게 포착하고 반환하는 데는 내재적인 한계가 있습니다. 기존 연구에서는 공동 학습 및 맞춤형 모델 아키텍처를 통해 언어 모델링을 향상시키기 위해 지식 그래프를 활용하는 방법을 모색했지만, 이를 LLM에 적용하는 것은 많은 수의 매개변수와 높은 계산 비용으로 인해 어려움이 있습니다. 또한 사전 학습된 LLM을 활용하고 맞춤형 모델을 처음부터 학습하는 것을 피하는 방법도 여전히 미해결 과제로 남아 있습니다. 이 연구에서는 사전 학습된 LLM이 KG로부터 유용한 지식을 학습할 수 있도록 지원하는 새로운 플러그 앤 플레이 방법인 그래프 신경 프롬프트(GNP)를 제안합니다. GNP는 표준 그래프 신경망 인코더, 크로스 모달리티 풀링 모듈, 도메인 프로젝터, 자가 감독 링크 예측 목표 등 다양한 설계를 포함합니다. 여러 데이터셋에 대한 광범위한 실험을 통해 다양한 LLM 크기와 설정에 걸쳐 상식 및 생의학 추론 작업 모두에서 GNP의 우수성이 입증되었습니다.
Large Language Models (LLMs) have shown remarkable generalization capability with exceptional performance in various language modeling tasks. However, they still exhibit inherent limitations in precisely capturing and returning grounded knowledge. While existing work has explored utilizing knowledge graphs to enhance language modeling via joint training and customized model architectures, applying this to LLMs is problematic owing to their large number of parameters and high computational cost. In addition, how to leverage the pre-trained LLMs and avoid training a customized model from scratch remains an open question. In this work, we propose Graph Neural Prompting (GNP), a novel plug-and-play method to assist pre-trained LLMs in learning beneficial knowledge from KGs. GNP encompasses various designs, including a standard graph neural network encoder, a cross-modality pooling module, a domain projector, and a self-supervised link prediction objective. Extensive experiments on multiple datasets demonstrate the superiority of GNP on both commonsense and biomedical reasoning tasks across different LLM sizes and settings.
논문 링크
더 읽어보기
https://x.com/omarsar0/status/1707211751354212382
비전 트랜스포머에는 레지스터가 필요합니다 / Vision Transformers Need Registers
논문 소개
- 내부 계산을 위해 용도가 변경된 비전 트랜스포머 네트워크의 피처 맵에서 아티팩트를 식별하고, 해당 역할을 수행하기 위해 입력 시퀀스에 추가 토큰을 제공하는 솔루션을 제안합니다. 이 솔루션은 문제를 해결하고 피처 및 주의 맵을 더 매끄럽게 만들며 밀집된 시각 예측 작업에서 새로운 최첨단 결과를 설정합니다. vision-transformer transformer
Identifies artifacts in feature maps of vision transformer networks that are repurposed for internal computations; this work proposes a solution to provide additional tokens to the input sequence to fill that role; the solution fixes the problem, leads to smoother feature and attention maps, and sets new state-of-the-art results on dense visual prediction tasks.
논문 초록
- 트랜스포머는 최근 시각적 표현을 학습하기 위한 강력한 도구로 부상했습니다. 이 논문에서는 지도형 및 자가 지도형 ViT 네트워크의 특징 맵에서 아티팩트를 식별하고 그 특성을 분석합니다. 이러한 아티팩트는 주로 이미지의 정보가 적은 배경 영역에서 추론 중에 나타나는 하이노멀 토큰에 해당하며, 내부 계산을 위해 용도가 변경됩니다. 우리는 비전 트랜스포머의 입력 시퀀스에 추가 토큰을 제공하여 이러한 역할을 수행하는 간단하면서도 효과적인 솔루션을 제안합니다. 이 솔루션은 지도 및 자율 지도 모델 모두에서 이러한 문제를 완전히 해결하고, 고밀도 시각 예측 작업에서 자율 지도 시각 모델을 위한 새로운 최신 기술을 설정하며, 더 큰 모델에서 객체 발견 방법을 가능하게 하고, 가장 중요한 것은 다운스트림 시각 처리를 위한 더 매끄러운 특징 맵과 관심 맵으로 이어진다는 것을 보여줍니다.
Transformers have recently emerged as a powerful tool for learning visual representations. In this paper, we identify and characterize artifacts in feature maps of both supervised and self-supervised ViT networks. The artifacts correspond to high-norm tokens appearing during inference primarily in low-informative background areas of images, that are repurposed for internal computations. We propose a simple yet effective solution based on providing additional tokens to the input sequence of the Vision Transformer to fill that role. We show that this solution fixes that problem entirely for both supervised and self-supervised models, sets a new state of the art for self-supervised visual models on dense visual prediction tasks, enables object discovery methods with larger models, and most importantly leads to smoother feature maps and attention maps for downstream visual processing.
논문 링크
더 읽어보기
https://x.com/TimDarcet/status/1707769575981424866
불포머: 트랜스포머를 사용한 논리 함수의 기호적 회귀 / Boolformer: Symbolic Regression of Logic Functions with Transformers
논문 소개
- 부울 함수의 종단 간 기호 회귀를 수행하도록 학습된 최초의 트랜스포머 아키텍처를 제공하며, 복잡한 함수에 대한 간결한 공식을 예측하고 유전자 조절 네트워크의 역학 모델링에 적용할 수 있습니다. transformer
Presents the first transformer architecture trained to perform end-to-end symbolic regression of boolean functions; it can predict compact formulas for complex functions and be applied to modeling the dynamics of gene regulatory networks.
논문 초록
- 이번 연구에서는 부울 함수의 종단 간 기호 회귀를 수행하도록 학습된 최초의 Transformer 아키텍처인 Boolformer를 소개합니다. 먼저, 깨끗한 진리 테이블이 주어졌을 때 학습 중에 볼 수 없었던 복잡한 함수에 대한 간결한 공식을 예측할 수 있음을 보여줍니다. 그런 다음 불완전하고 잡음이 많은 관측값이 주어졌을 때 대략적인 식을 찾을 수 있는 능력을 보여줍니다. 광범위한 실제 바이너리 분류 데이터셋에서 Boolformer를 평가하여 기존 머신러닝 방법의 해석 가능한 대안으로서의 잠재력을 입증합니다. 마지막으로, 유전자 조절 네트워크의 역학을 모델링하는 광범위한 작업에 적용합니다. 최근 벤치마크를 통해 Boolformer가 몇 배의 속도 향상으로 최첨단 유전 알고리즘과 경쟁할 수 있음을 보여줍니다. 코드와 모델은 공개적으로 사용할 수 있습니다.
In this work, we introduce Boolformer, the first Transformer architecture trained to perform end-to-end symbolic regression of Boolean functions. First, we show that it can predict compact formulas for complex functions which were not seen during training, when provided a clean truth table. Then, we demonstrate its ability to find approximate expressions when provided incomplete and noisy observations. We evaluate the Boolformer on a broad set of real-world binary classification datasets, demonstrating its potential as an interpretable alternative to classic machine learning methods. Finally, we apply it to the widespread task of modelling the dynamics of gene regulatory networks. Using a recent benchmark, we show that Boolformer is competitive with state-of-the art genetic algorithms with a speedup of several orders of magnitude. Our code and models are available publicly.
논문 링크
더 읽어보기
https://x.com/stephanedascoli/status/1706235856778834015
대형 멀티모달 모델을 사실적으로 증강된 RLHF로 정렬하기 / Aligning Large Multimodal Models with Factually Augmented RLHF
논문 소개
- 대규모 멀티모달 모델을 정렬하기 위해 사실적으로 증강된 rlhf를 적용합니다. 이 접근 방식은 rlhf의 보상 해킹을 완화하고 텍스트 전용 gpt-4의 94% 성능 수준으로 llava 벤치 데이터 세트의 성능을 개선합니다. llm-alignment multimodal rlhf
Adapts factually augmented rlhf to aligning large multimodal models; this approach alleviates the reward hacking in rlhf and improves performance on the llava-bench dataset with the 94% performance level of the text-only gpt-4.
논문 초록
- 대규모 멀티모달 모델(LMM)은 여러 모달리티에 걸쳐 구축되며 두 모달리티 간의 정렬이 잘못되면 문맥상 멀티모달 정보에 근거하지 않은 텍스트 출력이 생성되는 "환각"이 발생할 수 있습니다. 멀티모달 오정렬 문제를 해결하기 위해 텍스트 영역의 인간 피드백 강화 학습(RLHF)을 시각 언어 정렬 작업에 적용하여 인간 주석가에게 두 가지 반응을 비교하고 더 환각적인 반응을 찾아내도록 요청하고, 시뮬레이션된 인간 보상을 최대화하도록 시각 언어 모델을 학습합니다. 이미지 캡션 및 사실 기반 객관식 옵션과 같은 추가 사실 정보로 보상 모델을 보강하는 사실 증강 RLHF라는 새로운 정렬 알고리즘을 제안하여 RLHF의 보상 해킹 현상을 완화하고 성능을 더욱 향상시킵니다. 또한, 이전에 사용 가능한 사람이 작성한 이미지-텍스트 쌍으로 GPT-4에서 생성된 학습 데이터(비전 명령 튜닝용)를 강화하여 모델의 전반적인 기능을 개선했습니다. 실제 시나리오에서 제안된 접근 방식을 평가하기 위해 환각에 대한 불이익에 특별히 초점을 맞춘 새로운 평가 벤치마크 MMHAL-BENCH를 개발했습니다. RLHF로 학습된 최초의 LMM으로서, 우리의 접근 방식은 텍스트 전용 GPT-4의 94% 성능 수준(이전 최상의 방법은 87% 수준만 달성할 수 있음)으로 LLaVA-Bench 데이터셋에서 괄목할 만한 개선을 달성했으며, 다른 기준선보다 MMHAL-BENCH에서 60% 향상된 성능을 보였습니다. 코드, 모델, 데이터는 https://llava-rlhf.github.io 에서 오픈소스입니다.
Large Multimodal Models (LMM) are built across modalities and the misalignment between two modalities can result in "hallucination", generating textual outputs that are not grounded by the multimodal information in context. To address the multimodal misalignment issue, we adapt the Reinforcement Learning from Human Feedback (RLHF) from the text domain to the task of vision-language alignment, where human annotators are asked to compare two responses and pinpoint the more hallucinated one, and the vision-language model is trained to maximize the simulated human rewards. We propose a new alignment algorithm called Factually Augmented RLHF that augments the reward model with additional factual information such as image captions and ground-truth multi-choice options, which alleviates the reward hacking phenomenon in RLHF and further improves the performance. We also enhance the GPT-4-generated training data (for vision instruction tuning) with previously available human-written image-text pairs to improve the general capabilities of our model. To evaluate the proposed approach in real-world scenarios, we develop a new evaluation benchmark MMHAL-BENCH with a special focus on penalizing hallucinations. As the first LMM trained with RLHF, our approach achieves remarkable improvement on the LLaVA-Bench dataset with the 94% performance level of the text-only GPT-4 (while previous best methods can only achieve the 87% level), and an improvement by 60% on MMHAL-BENCH over other baselines. We opensource our code, model, data at https://llava-rlhf.github.io.
논문 링크
더 읽어보기
https://x.com/arankomatsuzaki/status/1706839311306621182
대규모 언어 모델 정렬: 설문 조사 / Large Language Model Alignment: A Survey
논문 소개
- 외적 정렬, 내적 정렬, 기계론적 해석 가능성, 정렬된 LLM에 대한 공격, 정렬 평가, 향후 방향 및 토론을 주제로 하는 LLM 정렬에 대한 포괄적인 조사 보고서입니다. survey-paper llm-alignment
A comprehensive survey paper on llm alignment; topics include outer alignment, inner alignment, mechanistic interpretability, attacks on aligned llms, alignment evaluation, future directions, and discussions.
논문 초록
- 최근 몇 년 동안 대규모 언어 모델(LLM)이 괄목할 만한 발전을 이루었습니다. 이러한 발전은 큰 주목을 받으면서도 동시에 다양한 우려를 불러일으키고 있습니다. 이러한 모델의 잠재력은 부인할 수 없을 정도로 방대하지만, 부정확하거나 오해의 소지가 있거나 심지어 해로운 텍스트를 생성할 수도 있습니다. 따라서 이러한 모델이 인간의 가치에 부합하는 행동을 보이도록 하기 위해 조정 기술을 사용하는 것이 무엇보다 중요합니다. 이 설문조사는 이 분야의 기존 역량 연구와 함께 LLM을 위해 설계된 정렬 방법론에 대한 광범위한 탐색을 제공하기 위해 노력합니다. AI 정렬이라는 렌즈를 채택하여 LLM의 정렬을 위한 일반적인 방법과 새로운 제안을 외적 정렬과 내적 정렬로 분류합니다. 또한 모델의 해석 가능성, 적대적 공격에 대한 잠재적 취약성 등 중요한 문제를 조사합니다. LLM 정렬을 평가하기 위해 다양한 벤치마크와 평가 방법론을 제시합니다. LLM에 대한 정렬 연구 현황에 대해 논의한 후, 마지막으로 미래를 향한 비전을 제시하고 앞으로의 유망한 연구 분야를 고려했습니다. 이 조사에 대한 우리의 열망은 단순히 이 영역에 대한 연구 관심을 불러일으키는 것 이상으로 확장됩니다. 또한 유능하고 안전한 LLM을 위해 AI 정렬 연구 커뮤니티와 LLM의 기능 탐색에 몰두하는 연구자 간의 간극을 좁히고자 합니다.
Recent years have witnessed remarkable progress made in large language models (LLMs). Such advancements, while garnering significant attention, have concurrently elicited various concerns. The potential of these models is undeniably vast; however, they may yield texts that are imprecise, misleading, or even detrimental. Consequently, it becomes paramount to employ alignment techniques to ensure these models to exhibit behaviors consistent with human values. This survey endeavors to furnish an extensive exploration of alignment methodologies designed for LLMs, in conjunction with the extant capability research in this domain. Adopting the lens of AI alignment, we categorize the prevailing methods and emergent proposals for the alignment of LLMs into outer and inner alignment. We also probe into salient issues including the models' interpretability, and potential vulnerabilities to adversarial attacks. To assess LLM alignment, we present a wide variety of benchmarks and evaluation methodologies. After discussing the state of alignment research for LLMs, we finally cast a vision toward the future, contemplating the promising avenues of research that lie ahead. Our aspiration for this survey extends beyond merely spurring research interests in this realm. We also envision bridging the gap between the AI alignment research community and the researchers engrossed in the capability exploration of LLMs for both capable and safe LLMs.
논문 링크
더 읽어보기
https://x.com/omarsar0/status/1706845285064818905
Qwen 기술 보고서 / Qwen Technical Report
논문 소개
- 언어 에이전트 생성을 위한 도구 사용 및 계획 기능과 관련된 작업에서 RLHF의 강점을 보여주는 일련의 LLM를 제안합니다. qwen-vl rlhf
Proposes a series of llms demonstrating the strength of rlhf on tasks involving tool use and planning capabilities for creating language agents.
논문 초록
- 대규모 언어 모델(LLM)은 인공지능 분야에 혁명을 일으켜 이전에는 인간의 전유물로 여겨지던 자연어 처리 작업을 가능하게 했습니다. 이번 글에서는 대규모 언어 모델 시리즈의 첫 번째 제품인 Qwen을 소개합니다. Qwen은 다양한 매개변수 수를 가진 여러 모델을 포괄하는 포괄적인 언어 모델 시리즈입니다. 여기에는 사전 학습된 기본 언어 모델인 Qwen과 휴먼 얼라인먼트 기술로 미세 조정된 채팅 모델인 Qwen-Chat이 포함됩니다. 기본 언어 모델은 다양한 다운스트림 작업에서 일관되게 우수한 성능을 보여주며, 특히 인간 피드백을 통한 강화 학습(RLHF)을 사용하여 학습된 채팅 모델은 경쟁력이 매우 높습니다. 채팅 모델은 상담원 애플리케이션을 만들기 위한 고급 도구 사용 및 계획 기능을 갖추고 있어 코드 인터프리터 활용과 같은 복잡한 작업에서 더 큰 규모의 모델과 비교했을 때도 인상적인 성능을 보여줍니다. 또한 기본 언어 모델을 기반으로 구축된 코딩 전문 모델인 Code-Qwen 및 Code-Qwen-Chat과 수학 전문 모델인 Math-Qwen-Chat도 개발했습니다. 이 모델들은 오픈소스 모델에 비해 현저히 향상된 성능을 보여주며, 독점 모델에 비해서는 약간 뒤떨어집니다.
Large language models (LLMs) have revolutionized the field of artificial intelligence, enabling natural language processing tasks that were previously thought to be exclusive to humans. In this work, we introduce Qwen, the first installment of our large language model series. Qwen is a comprehensive language model series that encompasses distinct models with varying parameter counts. It includes Qwen, the base pretrained language models, and Qwen-Chat, the chat models finetuned with human alignment techniques. The base language models consistently demonstrate superior performance across a multitude of downstream tasks, and the chat models, particularly those trained using Reinforcement Learning from Human Feedback (RLHF), are highly competitive. The chat models possess advanced tool-use and planning capabilities for creating agent applications, showcasing impressive performance even when compared to bigger models on complex tasks like utilizing a code interpreter. Furthermore, we have developed coding-specialized models, Code-Qwen and Code-Qwen-Chat, as well as mathematics-focused models, Math-Qwen-Chat, which are built upon base language models. These models demonstrate significantly improved performance in comparison with open-source models, and slightly fall behind the proprietary models.
논문 링크
더 읽어보기
MentalLLaMA: 대규모 언어 모델을 사용한 소셜 미디어에서의 해석 가능한 정신 건강 분석 / MentalLLaMA: Interpretable Mental Health Analysis on Social Media with Large Language Models
논문 소개
- 지침 추종 기능을 갖춘 해석 가능한 정신 건강 분석을 위한 오픈소스 llm 시리즈로, 105,000개의 데이터 샘플이 포함된 소셜 미디어에서 멀티태스크 및 멀티소스 해석 가능한 정신 건강 지침 데이터셋을 제안합니다. medical llm-for-clinical-task llama
An open-source llm series for interpretable mental health analysis with instruction-following capability; it also proposes a multi-task and multi-source interpretable mental health instruction dataset on social media with 105k data samples.
논문 초록
- 웹 기술의 발달로 소셜 미디어 텍스트는 자동 정신 건강 분석을 위한 풍부한 소스가 되고 있습니다. 기존의 판별 방법은 해석 가능성이 낮다는 문제가 있기 때문에, 최근 소셜 미디어에서 해석 가능한 정신 건강 분석을 위해 예측과 함께 상세한 설명을 제공하는 것을 목표로 하는 대규모 언어 모델이 연구되고 있습니다. 그 결과 ChatGPT는 정확한 분류에 대해 인간에 가까운 설명을 생성할 수 있음을 보여주었습니다. 그러나 LLM은 여전히 제로 샷/소수의 샷 방식으로 만족스럽지 못한 분류 성능을 달성합니다. 도메인별 미세 조정은 효과적인 솔루션이지만 두 가지 문제에 직면해 있습니다: 1) 고품질 학습 데이터가 부족합니다. 2) 미세 조정 비용을 낮출 수 있는 해석 가능한 정신 건강 분석용 오픈소스 LLM이 출시되지 않았습니다. 이러한 문제를 해결하기 위해 Facebook은 소셜 미디어에서 105만 개의 데이터 샘플로 구성된 최초의 다중 작업 및 다중 소스 해석 가능한 정신 건강 지침(IMHI) 데이터셋을 구축했습니다. 원시 소셜 미디어 데이터는 8가지 정신 건강 분석 작업을 다루는 10개의 기존 소스에서 수집됩니다. 전문가가 작성한 몇 장짜리 프롬프트와 수집된 레이블을 사용하여 ChatGPT에 메시지를 표시하고 응답에서 설명을 얻습니다. 설명의 신뢰성을 보장하기 위해 생성된 데이터의 정확성, 일관성 및 품질에 대해 엄격한 자동 및 인적 평가를 수행합니다. IMHI 데이터세트와 LLaMA2 파운데이션 모델을 기반으로, 지침 추종 기능을 갖춘 해석 가능한 정신 건강 분석을 위한 최초의 오픈소스 LLM 시리즈인 MentalLLaMA를 학습시킵니다. 또한 10개의 테스트 세트로 구성된 IMHI 평가 벤치마크에서 예측의 정확성과 설명의 품질을 검사하여 MentalLaMA의 성능을 평가합니다. 그 결과, MentalLLaMA는 최첨단 판별 방법에 근접한 정확도와 고품질 설명을 생성하는 것으로 나타났습니다.
With the development of web technology, social media texts are becoming a rich source for automatic mental health analysis. As traditional discriminative methods bear the problem of low interpretability, the recent large language models have been explored for interpretable mental health analysis on social media, which aims to provide detailed explanations along with predictions. The results show that ChatGPT can generate approaching-human explanations for its correct classifications. However, LLMs still achieve unsatisfactory classification performance in a zero-shot/few-shot manner. Domain-specific finetuning is an effective solution, but faces 2 challenges: 1) lack of high-quality training data. 2) no open-source LLMs for interpretable mental health analysis were released to lower the finetuning cost. To alleviate these problems, we build the first multi-task and multi-source interpretable mental health instruction (IMHI) dataset on social media, with 105K data samples. The raw social media data are collected from 10 existing sources covering 8 mental health analysis tasks. We use expert-written few-shot prompts and collected labels to prompt ChatGPT and obtain explanations from its responses. To ensure the reliability of the explanations, we perform strict automatic and human evaluations on the correctness, consistency, and quality of generated data. Based on the IMHI dataset and LLaMA2 foundation models, we train MentalLLaMA, the first open-source LLM series for interpretable mental health analysis with instruction-following capability. We also evaluate the performance of MentalLLaMA on the IMHI evaluation benchmark with 10 test sets, where their correctness for making predictions and the quality of explanations are examined. The results show that MentalLLaMA approaches state-of-the-art discriminative methods in correctness and generates high-quality explanations.
논문 링크
더 읽어보기
https://x.com/SAnaniadou/status/1707668936634794442
로직을 통해 대규모 언어 모델에서 제로 샷 연쇄 추론 강화하기 / Enhancing Zero-Shot Chain-of-Thought Reasoning in Large Language Models through Logic
논문 소개
- LLM의 제로 샷 사고 연쇄 추론을 개선하기 위한 새로운 신경 기호 프레임워크, 기호 논리의 원리를 활용하여 추론 프로세스를 검증하고 수정하여 LLM의 추론 기능을 개선합니다. chain-of-thought
A new neurosymbolic framework to improve zero-shot chain-of-thought reasoning in llms; leverages principles from symbolic logic to verify and revise reasoning processes to improve the reasoning capabilities of llms.
논문 초록
- 최근 대규모 언어 모델의 발전은 다양한 영역에서 놀라운 일반화 가능성을 보여주었습니다. 그러나 추론 능력은 특히 다단계 추론이 필요한 시나리오에 직면했을 때 여전히 상당한 개선의 여지가 있습니다. 대규모 언어 모델은 광범위한 지식을 보유하고 있지만, 특히 추론 측면에서 이러한 지식을 효과적으로 활용하여 일관된 사고 패러다임을 구축하는 데 실패하는 경우가 많습니다. 생성적 언어 모델은 추론 절차가 논리적 원칙의 제약을 받지 않기 때문에 때때로 환각을 보이기도 합니다. 대규모 언어 모델의 제로 샷 사고 연쇄 추론 능력을 향상시키기 위해, 우리는 기호 논리의 원리를 활용하여 추론 과정을 검증하고 그에 따라 수정하는 신경 상징적 프레임워크인 논리적 사고 연쇄(LogiCoT)를 제안합니다. 산술, 상식, 상징, 인과 추론, 사회 문제 등 다양한 영역의 언어 과제에 대한 실험적 평가를 통해 논리에 의한 향상된 추론 패러다임의 효과를 입증했습니다.
Recent advancements in large language models have showcased their remarkable generalizability across various domains. However, their reasoning abilities still have significant room for improvement, especially when confronted with scenarios requiring multi-step reasoning. Although large language models possess extensive knowledge, their behavior, particularly in terms of reasoning, often fails to effectively utilize this knowledge to establish a coherent thinking paradigm. Generative language models sometimes show hallucinations as their reasoning procedures are unconstrained by logical principles. Aiming to improve the zero-shot chain-of-thought reasoning ability of large language models, we propose Logical Chain-of-Thought (LogiCoT), a neurosymbolic framework that leverages principles from symbolic logic to verify and revise the reasoning processes accordingly. Experimental evaluations conducted on language tasks in diverse domains, including arithmetic, commonsense, symbolic, causal inference, and social problems, demonstrate the efficacy of the enhanced reasoning paradigm by logic.
논문 링크
더 읽어보기
https://x.com/omarsar0/status/1706711389803287019