[2025/06/23 ~ 29] 이번 주에 살펴볼 만한 AI/ML 논문 모음
PyTorchKR



![]() 이번 주 선정된 논문들을 살펴보면, 첫째로 멀티에이전트 협업과 경험 축적을 통한 추론 능력 강화에 대한 연구가 두드러집니다. 예를 들어, Xolver는 올림피아드 팀처럼 다양한 경험과 협업을 통해 문제 해결 능력을 높이는 프레임워크를 제안하며, MEM1은 장기 대화 상황에서 효율적인 메모리 관리와 추론을 동시에 수행하는 강화학습 기반 방법을 소개합니다. 이러한 연구들은 기존의 독립적인 문제 해결 방식에서 벗어나, 경험을 누적하고 동료 에이전트와 상호작용하며 점진적으로 성능을 향상시키는 방향으로 AI 에이전트의 추론 능력을 발전시키려는 흐름을 반영합니다.
이번 주 선정된 논문들을 살펴보면, 첫째로 멀티에이전트 협업과 경험 축적을 통한 추론 능력 강화에 대한 연구가 두드러집니다. 예를 들어, Xolver는 올림피아드 팀처럼 다양한 경험과 협업을 통해 문제 해결 능력을 높이는 프레임워크를 제안하며, MEM1은 장기 대화 상황에서 효율적인 메모리 관리와 추론을 동시에 수행하는 강화학습 기반 방법을 소개합니다. 이러한 연구들은 기존의 독립적인 문제 해결 방식에서 벗어나, 경험을 누적하고 동료 에이전트와 상호작용하며 점진적으로 성능을 향상시키는 방향으로 AI 에이전트의 추론 능력을 발전시키려는 흐름을 반영합니다.
![]() 둘째, 멀티모달 AI, 특히 시각과 언어를 결합한 모델들의 발전이 두드러집니다. Visionary-R1과 Griffon-R 같은 모델들은 시각적 질문응답과 복잡한 시각 추론 문제를 해결하기 위해 강화학습과 인간과 유사한 이해-사고-응답 프로세스를 도입합니다. 또한, 시각적 표현과 언어 표현 간의 정렬 메커니즘을 분석하는 연구도 포함되어 있어, 멀티모달 모델의 내재적 작동 원리를 이해하고 최적화하려는 시도가 활발함을 알 수 있습니다. 이러한 연구들은 멀티모달 AI가 단순한 인식 수준을 넘어 고차원적 추론과 응용으로 확장되고 있음을 보여줍니다.
둘째, 멀티모달 AI, 특히 시각과 언어를 결합한 모델들의 발전이 두드러집니다. Visionary-R1과 Griffon-R 같은 모델들은 시각적 질문응답과 복잡한 시각 추론 문제를 해결하기 위해 강화학습과 인간과 유사한 이해-사고-응답 프로세스를 도입합니다. 또한, 시각적 표현과 언어 표현 간의 정렬 메커니즘을 분석하는 연구도 포함되어 있어, 멀티모달 모델의 내재적 작동 원리를 이해하고 최적화하려는 시도가 활발함을 알 수 있습니다. 이러한 연구들은 멀티모달 AI가 단순한 인식 수준을 넘어 고차원적 추론과 응용으로 확장되고 있음을 보여줍니다.
![]() 마지막으로, 장기적이고 복잡한 입력을 효율적으로 처리하기 위한 메모리 및 토큰 선택 기법에 관한 연구가 눈에 띕니다. MEM1은 장기 대화에서 메모리 사용량을 일정하게 유지하면서도 성능을 향상시키는 방법을 제시하고, FlexSelect는 긴 영상 데이터에서 핵심 정보를 선별하여 처리 효율을 극대화합니다. 또한, 비디오 LLM 훈련에서 영상 데이터의 중요성과 한계를 분석하는 연구도 포함되어 있어, 대규모 시퀀스 데이터 처리의 효율성과 효과성 개선이 AI 연구의 중요한 과제로 자리잡고 있음을 시사합니다. 이처럼 장기 기억과 효율적 정보 선택은 AI 모델의 실용성과 확장성을 높이는 데 필수적인 요소로 부각되고 있습니다.
마지막으로, 장기적이고 복잡한 입력을 효율적으로 처리하기 위한 메모리 및 토큰 선택 기법에 관한 연구가 눈에 띕니다. MEM1은 장기 대화에서 메모리 사용량을 일정하게 유지하면서도 성능을 향상시키는 방법을 제시하고, FlexSelect는 긴 영상 데이터에서 핵심 정보를 선별하여 처리 효율을 극대화합니다. 또한, 비디오 LLM 훈련에서 영상 데이터의 중요성과 한계를 분석하는 연구도 포함되어 있어, 대규모 시퀀스 데이터 처리의 효율성과 효과성 개선이 AI 연구의 중요한 과제로 자리잡고 있음을 시사합니다. 이처럼 장기 기억과 효율적 정보 선택은 AI 모델의 실용성과 확장성을 높이는 데 필수적인 요소로 부각되고 있습니다.
Xolver: 올림피아드 팀처럼 전체 경험 학습을 통한 다중 에이전트 추론 / Xolver: Multi-Agent Reasoning with Holistic Experience Learning Just Like an Olympiad Team
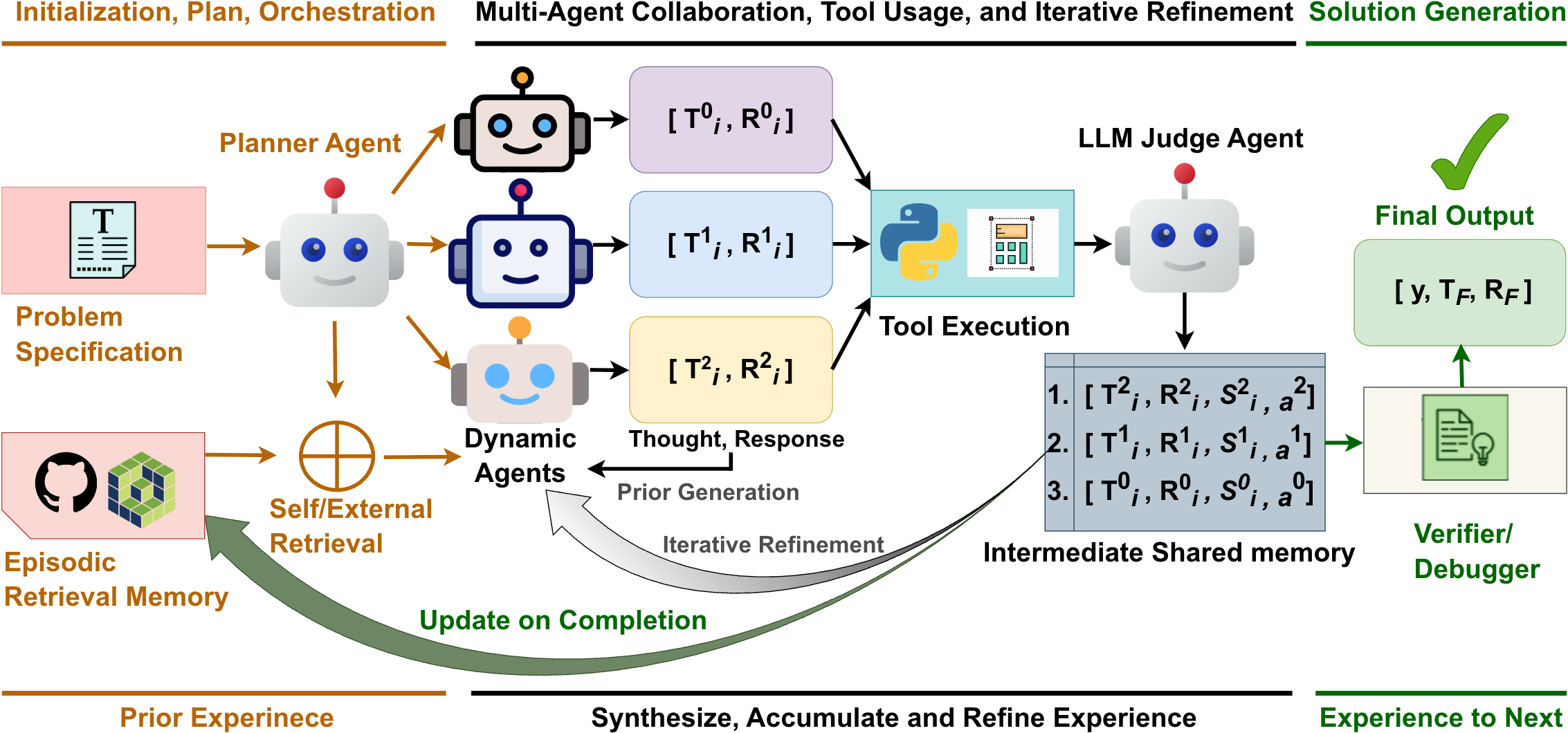
논문 소개
Xolver는 기존 대형 언어 모델(LLM)이 문제를 독립적으로 처리하는 한계를 극복하고, 올림피아드 팀과 같이 다양한 경험을 통합하여 지속적이고 진화하는 메모리를 활용하는 다중 에이전트 추론 프레임워크입니다. 외부 및 자기 검색, 도구 활용, 협업 상호작용, 에이전트 주도 평가, 반복적 개선 등 다양한 경험 방식을 결합하여 추론 시점에 전략, 코드 조각, 추상적 추론 패턴을 학습함으로써 문제 해결을 처음부터 생성하는 방식을 지양합니다. 경량 모델에서도 최첨단 대형 모델을 능가하는 성능을 보이며, 수학 및 코딩 벤치마크에서 최고 성과를 기록하여 전문적 수준의 추론이 가능한 범용 에이전트 개발에 중요한 진전을 제시합니다.
논문 초록(Abstract)
복잡한 추론 분야에서 눈에 띄는 발전에도 불구하고, 현재의 대형 언어 모델(LLM)은 일반적으로 독립적으로 작동하며, 각 문제를 별개의 시도로 처리하고 경험적 지식을 축적하거나 통합하지 않습니다. 반면, 올림피아드나 프로그래밍 대회 팀과 같은 전문가 문제 해결자는 코치로부터의 멘토링을 흡수하고, 과거 문제들로부터 직관을 개발하며, 도구 사용법과 라이브러리 기능에 대한 지식을 활용하고, 동료들의 전문성과 경험에 기반해 전략을 조정하며, 시행착오를 통해 추론을 지속적으로 개선하고, 대회 중에도 관련된 다른 문제들로부터 학습하는 등 풍부한 경험의 망을 활용합니다. 본 논문에서는 블랙박스 LLM에 전체적 경험의 지속적이고 진화하는 메모리를 부여하는 학습 불필요 다중 에이전트 추론 프레임워크인 Xolver를 제안합니다. Xolver는 외부 및 자기 검색, 도구 사용, 협업 상호작용, 에이전트 주도 평가, 반복적 개선 등 다양한 경험 양식을 통합합니다. 추론 시점에 관련 전략, 코드 조각, 추상적 추론 패턴으로부터 학습함으로써 Xolver는 솔루션을 처음부터 생성하는 것을 피하며, 독립적 추론에서 경험 인지 언어 에이전트로의 전환을 의미합니다. 오픈 웨이트 및 독점 모델 모두에 기반한 Xolver는 전문화된 추론 에이전트들을 지속적으로 능가합니다. 경량 백본(QWQ-32B 등)에서도 Qwen3-235B, Gemini 2.5 Pro, o3, o4-mini-high 등 고급 모델을 자주 능가합니다. o3-mini-high와 함께 GSM8K(98.1%), AIME'24(94.4%), AIME'25(93.7%), Math-500(99.8%), LiveCodeBench-V5(91.6%)에서 새로운 최고 성과를 달성하며, 전체적 경험 학습이 전문가 수준의 추론이 가능한 범용 에이전트로 나아가는 핵심 단계임을 강조합니다. 코드와 데이터는 𝕏olver: Multi-Agent Reasoning with Holistic Experience Learning Just Like an Olympiad Team 에서 확인할 수 있습니다.
Despite impressive progress on complex reasoning, current large language models (LLMs) typically operate in isolation - treating each problem as an independent attempt, without accumulating or integrating experiential knowledge. In contrast, expert problem solvers - such as Olympiad or programming contest teams - leverage a rich tapestry of experiences: absorbing mentorship from coaches, developing intuition from past problems, leveraging knowledge of tool usage and library functionality, adapting strategies based on the expertise and experiences of peers, continuously refining their reasoning through trial and error, and learning from other related problems even during competition. We introduce Xolver, a training-free multi-agent reasoning framework that equips a black-box LLM with a persistent, evolving memory of holistic experience. Xolver integrates diverse experience modalities, including external and self-retrieval, tool use, collaborative interactions, agent-driven evaluation, and iterative refinement. By learning from relevant strategies, code fragments, and abstract reasoning patterns at inference time, Xolver avoids generating solutions from scratch - marking a transition from isolated inference toward experience-aware language agents. Built on both open-weight and proprietary models, Xolver consistently outperforms specialized reasoning agents. Even with lightweight backbones (e.g., QWQ-32B), it often surpasses advanced models including Qwen3-235B, Gemini 2.5 Pro, o3, and o4-mini-high. With o3-mini-high, it achieves new best results on GSM8K (98.1%), AIME'24 (94.4%), AIME'25 (93.7%), Math-500 (99.8%), and LiveCodeBench-V5 (91.6%) - highlighting holistic experience learning as a key step toward generalist agents capable of expert-level reasoning. Code and data are available at 𝕏olver: Multi-Agent Reasoning with Holistic Experience Learning Just Like an Olympiad Team.
논문 링크
더 읽어보기
MEM1: 효율적인 장기 대화 에이전트를 위한 메모리와 추론의 시너지 학습 / MEM1: Learning to Synergize Memory and Reasoning for Efficient Long-Horizon Agents
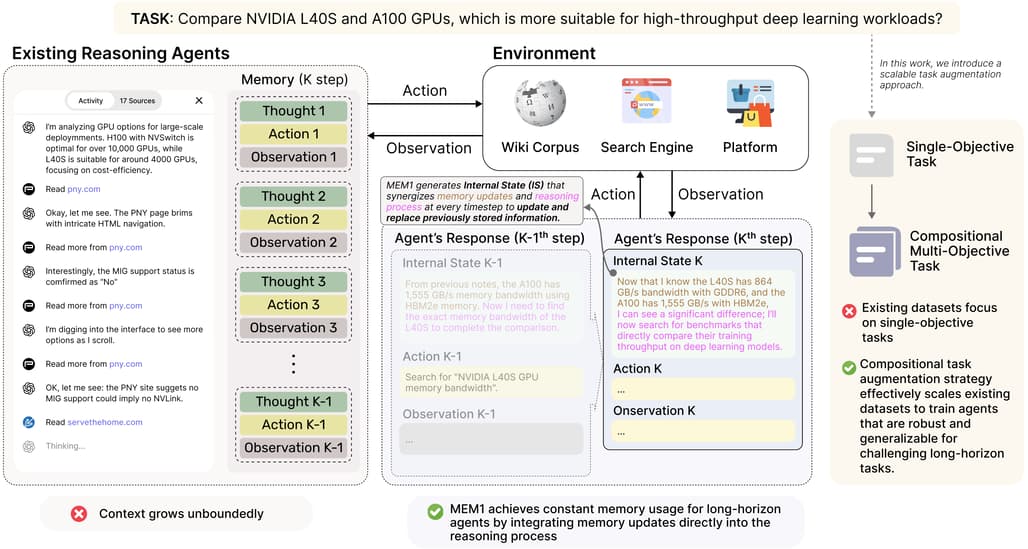
논문 소개
현대 언어 에이전트는 장기 다중 대화에서 외부 정보를 검색하고 관찰에 적응하며 상호 연관된 질문에 답해야 합니다. 기존 대형언어모델(LLM) 시스템은 모든 과거 대화를 무차별적으로 포함하는 전체 문맥 프롬프트 방식을 사용해 메모리 사용량이 무한히 증가하고 계산 비용이 높아지며, 분포 밖 입력 길이에서는 추론 성능이 저하되는 문제가 있습니다. MEM1은 강화학습 기반의 프레임워크로, 매 턴마다 관련 없는 정보를 전략적으로 버리면서 이전 기억과 새로운 관찰을 통합하는 압축된 내부 상태를 유지하여 일정한 메모리 사용량으로 장기 다중 대화 작업을 수행할 수 있게 합니다. 다양한 도메인에서 MEM1은 기존 모델 대비 추론 성능을 크게 향상시키고 메모리 사용을 대폭 줄이며, 훈련 시의 대화 길이를 넘어서는 일반화 능력도 입증하였습니다.
논문 초록(Abstract)
현대의 언어 에이전트는 장기적이고 다중 턴으로 이루어진 상호작용에서 외부 정보를 검색하고, 관찰에 적응하며, 상호 의존적인 질의에 답변해야 합니다. 그러나 대부분의 LLM 시스템은 관련성에 관계없이 모든 과거 턴을 덧붙이는 전체 문맥 프롬프팅에 의존합니다. 이는 무한한 메모리 증가, 계산 비용 상승, 그리고 분포 밖 입력 길이에 대한 추론 성능 저하를 초래합니다. 본 논문에서는 MEM1을 제안합니다. MEM1은 장기 다중 턴 작업에서 일정한 메모리 사용량으로 에이전트가 동작할 수 있도록 하는 종단 간 강화학습 프레임워크입니다. 각 턴마다 MEM1은 메모리 통합과 추론을 동시에 지원하는 간결한 공유 내부 상태를 갱신합니다. 이 상태는 이전 메모리와 환경으로부터의 새로운 관찰을 통합하며, 관련 없거나 중복된 정보를 전략적으로 폐기합니다. 보다 현실적이고 구성적인 학습 환경을 지원하기 위해, 기존 데이터셋을 조합하여 임의로 복잡한 작업 시퀀스를 구성하는 간단하면서도 효과적이고 확장 가능한 다중 턴 환경 구축 방식을 제안합니다. 내부 검색 QA, 개방형 웹 QA, 다중 턴 웹 쇼핑 등 세 가지 도메인에서의 실험 결과, MEM1-7B는 16개 목표의 다중 홉 QA 작업에서 Qwen2.5-14B-Instruct 대비 성능을 3.5배 향상시키고 메모리 사용량은 3.7배 절감하였으며, 학습 범위를 넘어 일반화됨을 확인하였습니다. 본 연구 결과는 효율성과 성능을 동시에 최적화하는 장기 상호작용 에이전트 학습을 위한 확장 가능한 대안으로서, 추론 중심 메모리 통합의 가능성을 보여줍니다.
Modern language agents must operate over long-horizon, multi-turn interactions, where they retrieve external information, adapt to observations, and answer interdependent queries. Yet, most LLM systems rely on full-context prompting, appending all past turns regardless of their relevance. This leads to unbounded memory growth, increased computational costs, and degraded reasoning performance on out-of-distribution input lengths. We introduce MEM1, an end-to-end reinforcement learning framework that enables agents to operate with constant memory across long multi-turn tasks. At each turn, MEM1 updates a compact shared internal state that jointly supports memory consolidation and reasoning. This state integrates prior memory with new observations from the environment while strategically discarding irrelevant or redundant information. To support training in more realistic and compositional settings, we propose a simple yet effective and scalable approach to constructing multi-turn environments by composing existing datasets into arbitrarily complex task sequences. Experiments across three domains, including internal retrieval QA, open-domain web QA, and multi-turn web shopping, show that MEM1-7B improves performance by 3.5x while reducing memory usage by 3.7x compared to Qwen2.5-14B-Instruct on a 16-objective multi-hop QA task, and generalizes beyond the training horizon. Our results demonstrate the promise of reasoning-driven memory consolidation as a scalable alternative to existing solutions for training long-horizon interactive agents, where both efficiency and performance are optimized.
논문 링크
GSO: SWE-에이전트 평가를 위한 도전적 소프트웨어 최적화 과제 / GSO: Challenging Software Optimization Tasks for Evaluating SWE-Agents

논문 소개
GSO는 고성능 소프트웨어 개발 능력을 평가하기 위한 벤치마크로, 10개 코드베이스에서 102개의 어려운 최적화 과제를 자동으로 생성하고 성능 테스트를 수행합니다. 에이전트는 코드베이스와 성능 테스트를 받아 런타임 효율성을 개선하는 과제를 수행하며, 전문가 최적화와 비교하여 평가됩니다. 주요 SWE-Agents는 5% 미만의 낮은 성공률을 보였고, 추론 시간 확장에도 성능 향상이 제한적이었습니다. 분석 결과, 저수준 언어 처리, 소극적 최적화 전략, 병목 구간 정확한 파악의 어려움이 주요 실패 원인으로 나타났습니다.
논문 초록(Abstract)
고성능 소프트웨어 개발은 전문적인 지식을 요구하는 복잡한 과제입니다. 본 논문에서는 언어 모델의 고성능 소프트웨어 개발 역량을 평가하기 위한 벤치마크인 GSO를 제안합니다. 우리는 저장소 커밋 이력을 분석하여 10개의 코드베이스에 걸쳐 다양한 도메인과 프로그래밍 언어를 포함하는 102개의 도전적인 최적화 과제를 식별하고, 성능 테스트를 자동으로 생성 및 실행하는 파이프라인을 개발하였습니다. 에이전트는 코드베이스와 성능 테스트를 명확한 명세로 제공받아, 전문가 개발자의 최적화와 비교하여 런타임 효율성을 향상시키는 임무를 수행합니다. 정량적 평가 결과, 주요 SWE-Agents는 5% 미만의 성공률을 기록하며, 추론 시 확장에도 불구하고 개선이 제한적임을 확인하였습니다. 정성적 분석에서는 저수준 언어 처리의 어려움, 소극적인 최적화 전략 사용, 병목 현상 정확한 위치 파악의 어려움 등 주요 실패 원인을 규명하였습니다. 본 벤치마크의 코드와 산출물, 에이전트 경로를 공개하여 향후 연구를 지원합니다.
Developing high-performance software is a complex task that requires specialized expertise. We introduce GSO, a benchmark for evaluating language models' capabilities in developing high-performance software. We develop an automated pipeline that generates and executes performance tests to analyze repository commit histories to identify 102 challenging optimization tasks across 10 codebases, spanning diverse domains and programming languages. An agent is provided with a codebase and performance test as a precise specification, and tasked to improve the runtime efficiency, which is measured against the expert developer optimization. Our quantitative evaluation reveals that leading SWE-Agents struggle significantly, achieving less than 5% success rate, with limited improvements even with inference-time scaling. Our qualitative analysis identifies key failure modes, including difficulties with low-level languages, practicing lazy optimization strategies, and challenges in accurately localizing bottlenecks. We release the code and artifacts of our benchmark along with agent trajectories to enable future research.
논문 링크
더 읽어보기
통합 멀티모달 사전학습에서 나타나는 신흥 특성 / Emerging Properties in Unified Multimodal Pretraining

논문 소개
BAGEL은 텍스트, 이미지, 비디오, 웹 데이터를 대규모로 혼합(pretraining)하여 학습한 통합 멀티모달(decoder-only) 기초 모델입니다. 다양한 멀티모달 데이터를 활용함으로써 복잡한 멀티모달 추론 능력에서 뛰어난 성능을 보이며, 기존 공개된 통합 모델 대비 멀티모달 생성과 이해 양쪽에서 우수한 결과를 나타냅니다. 특히 자유형 이미지 조작, 미래 프레임 예측, 3D 조작, 세계 내비게이션 등 고급 멀티모달 추론 기능을 구현합니다. 연구진은 모델 학습 방법, 데이터 생성 프로토콜, 코드와 체크포인트를 공개하여 멀티모달 연구 활성화를 도모하고 있습니다.
논문 초록(Abstract)
최첨단 독점 시스템에서 멀티모달 이해와 생성을 통합하는 접근법은 뛰어난 성능을 보여주고 있습니다. 본 연구에서는 멀티모달 이해와 생성을 본질적으로 지원하는 오픈소스 기반 모델인 BAGEL을 소개합니다. BAGEL은 대규모로 교차된 텍스트, 이미지, 비디오, 웹 데이터를 기반으로 수조 개의 토큰에 대해 사전학습된 통합형 디코더 전용 모델입니다. 이렇게 다양한 멀티모달 교차 데이터를 활용하여 확장할 때, BAGEL은 복잡한 멀티모달 추론에서 새로운 능력을 발휘합니다. 그 결과, 표준 벤치마크에서 멀티모달 생성과 이해 모두에서 오픈소스 통합 모델을 크게 능가하며, 자유형 이미지 조작, 미래 프레임 예측, 3D 조작, 세계 내비게이션과 같은 고급 멀티모달 추론 능력도 보여줍니다. 멀티모달 연구의 추가 기회를 촉진하고자, 주요 발견사항, 사전학습 세부사항, 데이터 생성 프로토콜을 공유하며, 코드와 체크포인트를 커뮤니티에 공개합니다. 프로젝트 페이지는 https://bagel-ai.org/ 입니다.
Unifying multimodal understanding and generation has shown impressive capabilities in cutting-edge proprietary systems. In this work, we introduce BAGEL, an open-source foundational model that natively supports multimodal understanding and generation. BAGEL is a unified, decoder-only model pretrained on trillions of tokens curated from large-scale interleaved text, image, video, and web data. When scaled with such diverse multimodal interleaved data, BAGEL exhibits emerging capabilities in complex multimodal reasoning. As a result, it significantly outperforms open-source unified models in both multimodal generation and understanding across standard benchmarks, while exhibiting advanced multimodal reasoning abilities such as free-form image manipulation, future frame prediction, 3D manipulation, and world navigation. In the hope of facilitating further opportunities for multimodal research, we share the key findings, pretraining details, data creation protocal, and release our code and checkpoints to the community. The project page is at https://bagel-ai.org/
논문 링크
더 읽어보기
Visionary-R1: 강화학습을 통한 시각적 추론의 지름길 문제 완화 / Visionary-R1: Mitigating Shortcuts in Visual Reasoning with Reinforcement Learning
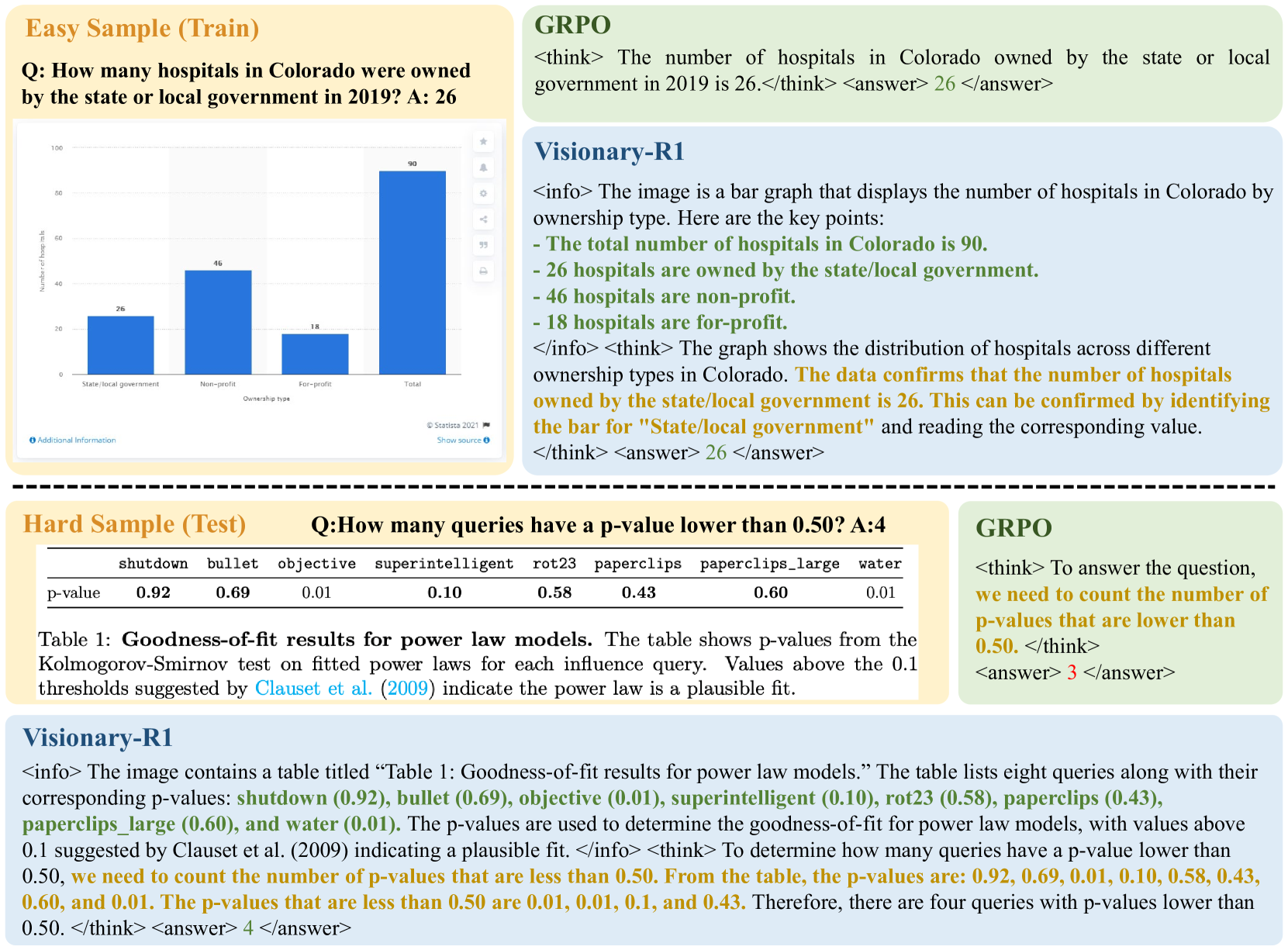
논문 소개
본 연구에서는 시각 언어 모델(VLM)에 강화학습을 적용하여 명시적인 사고 연쇄(chain-of-thought, CoT) 지도 없이 이미지 기반 추론 능력을 향상시키고자 하였습니다. 단순히 강화학습으로 추론 과정을 유도할 경우 쉬운 문제에서 편법(shortcut)이 발생하여 일반화 성능이 저하되는 문제를 발견하였습니다. 이를 해결하기 위해 이미지에 대한 상세한 캡션 생성 후 추론 과정을 거쳐 답변을 도출하는 캡션-추론-답변(caption-reason-answer) 출력 형식을 도입하였습니다. 27만 3천 개의 CoT 비지도 시각 질문-답변 쌍으로 학습한 Visionary-R1 모델은 GPT-4o, Claude3.5-Sonnet, Gemini-1.5-Pro 등 강력한 다중모달 모델들을 여러 시각 추론 벤치마크에서 능가하는 성과를 보였습니다.
논문 초록(Abstract)
일반 목적의 추론 능력 학습은 AI 분야에서 오랫동안 어려운 문제로 남아있었습니다. DeepSeek-R1과 같은 대형 언어 모델(LLM) 연구에서는 GRPO와 같은 강화 학습 기법이 사전 학습된 LLM이 단순한 질문-답변 쌍을 통해 추론 능력을 개발할 수 있음을 보여주었습니다. 본 논문에서는 명시적인 사고의 연쇄(CoT) 감독 없이 강화 학습과 시각적 질문-답변 쌍을 활용하여 시각 언어 모델(VLM)이 이미지 데이터에 대해 추론을 수행하도록 학습하는 것을 목표로 합니다. 연구 결과, 단순히 VLM에 강화 학습을 적용하여 답변 전에 추론 과정을 생성하도록 유도하는 경우, 모델이 쉬운 질문에서 지름길(shortcut)을 학습하여 미지의 데이터 분포에 대한 일반화 능력이 저하되는 현상이 나타났습니다. 우리는 이러한 지름길 학습을 완화하는 핵심이 모델이 추론 전에 이미지를 해석하도록 유도하는 데 있다고 주장합니다. 따라서 본 연구에서는 모델이 캡션-추론-답변 출력 형식을 준수하도록 학습하는데, 먼저 이미지에 대한 상세한 캡션을 생성한 후 광범위한 추론 과정을 구성하도록 하였습니다. 273K 개의 CoT 비사용 시각적 질문-답변 쌍으로만 강화 학습을 수행한 결과, Visionary-R1이라 명명한 본 모델은 GPT-4o, Claude3.5-Sonnet, Gemini-1.5-Pro와 같은 강력한 멀티모달 모델들을 여러 시각 추론 벤치마크에서 능가하는 성능을 보였습니다.
Learning general-purpose reasoning capabilities has long been a challenging problem in AI. Recent research in large language models (LLMs), such as DeepSeek-R1, has shown that reinforcement learning techniques like GRPO can enable pre-trained LLMs to develop reasoning capabilities using simple question-answer pairs. In this paper, we aim to train visual language models (VLMs) to perform reasoning on image data through reinforcement learning and visual question-answer pairs, without any explicit chain-of-thought (CoT) supervision. Our findings indicate that simply applying reinforcement learning to a VLM -- by prompting the model to produce a reasoning chain before providing an answer -- can lead the model to develop shortcuts from easy questions, thereby reducing its ability to generalize across unseen data distributions. We argue that the key to mitigating shortcut learning is to encourage the model to interpret images prior to reasoning. Therefore, we train the model to adhere to a caption-reason-answer output format: initially generating a detailed caption for an image, followed by constructing an extensive reasoning chain. When trained on 273K CoT-free visual question-answer pairs and using only reinforcement learning, our model, named Visionary-R1, outperforms strong multimodal models, such as GPT-4o, Claude3.5-Sonnet, and Gemini-1.5-Pro, on multiple visual reasoning benchmarks.
논문 링크
더 읽어보기
멀티모달 LLM에서 시각 표현이 언어 특징 공간에 매핑되는 방식 연구 / How Visual Representations Map to Language Feature Space in Multimodal LLMs
논문 소개
멀티모달 추론의 효과는 시각 및 언어 표현의 정렬(alignment)에 달려 있으나, 시각-언어 모델(VLM)이 이를 어떻게 달성하는지는 명확하지 않습니다. 본 연구는 고정된 대형 언어 모델(LLM)과 고정된 비전 트랜스포머(ViT)를 선형 어댑터(linear adapter)로만 연결하여 시각적 명령 조정(visual instruction tuning)을 수행하는 방법론적 틀을 제안합니다. 이를 통해 시각 특징이 LLM의 기존 언어 표현 공간으로 직접 매핑되는 과정을 분석할 수 있으며, 사전학습된 희소 오토인코더(SAE)를 활용해 계층별 시각-언어 표현 정렬 과정을 체계적으로 탐구합니다. 결과적으로, 시각 표현은 중간~후반부 LLM 계층에서 언어 표현과 점진적으로 정렬되며, 초기 LLM 계층과 ViT 출력 간에는 근본적인 불일치가 존재함을 밝혀 어댑터 기반 구조의 한계를 시사합니다.
논문 초록(Abstract)
효과적인 멀티모달 추론은 시각적 표현과 언어적 표현의 정렬에 달려 있으나, 비전-언어 모델(VLM)이 이러한 정렬을 달성하는 메커니즘은 아직 명확히 이해되지 않고 있습니다. 본 논문에서는 대형 언어 모델(LLM)과 비전 트랜스포머(ViT)를 모두 고정(frozen)한 상태로 유지하고, 시각적 지시 학습(visual instruction tuning) 중에 선형 어댑터(linear adapter)만 학습시키는 방법론적 프레임워크를 제안합니다. 이 설계는 본 접근법의 핵심으로, 언어 모델을 고정함으로써 시각 데이터에 적응하지 않고 원래의 언어 표현을 유지하도록 보장합니다. 따라서 선형 어댑터는 언어 모델이 미세조정(fine-tuning)을 통해 특화된 시각적 이해를 발전시키는 대신, 시각적 특징을 LLM의 기존 표현 공간으로 직접 매핑해야 합니다. 실험 설계는 LLM의 사전학습된 희소 오토인코더(SAE)를 분석 도구로 활용할 수 있게 하여 독창적입니다. 이 SAE들은 변하지 않은 언어 모델과 완벽히 정렬되어 있으며, 학습된 언어 특징 표현의 스냅샷 역할을 합니다. SAE 재구성 오류, 희소성 패턴, 특징 SAE 설명에 대한 체계적인 분석을 통해, 시각적 표현이 점진적으로 언어 특징 표현과 정렬되어 중간층에서 후반층으로 수렴하는 계층별 진행 과정을 밝혀냈습니다. 이는 ViT 출력과 초기 LLM 층 간의 근본적인 불일치를 시사하며, 현재의 어댑터 기반 아키텍처가 교차 모달 표현 학습을 최적으로 지원하는지에 대한 중요한 의문을 제기합니다.
Effective multimodal reasoning depends on the alignment of visual and linguistic representations, yet the mechanisms by which vision-language models (VLMs) achieve this alignment remain poorly understood. We introduce a methodological framework that deliberately maintains a frozen large language model (LLM) and a frozen vision transformer (ViT), connected solely by training a linear adapter during visual instruction tuning. This design is fundamental to our approach: by keeping the language model frozen, we ensure it maintains its original language representations without adaptation to visual data. Consequently, the linear adapter must map visual features directly into the LLM's existing representational space rather than allowing the language model to develop specialized visual understanding through fine-tuning. Our experimental design uniquely enables the use of pre-trained sparse autoencoders (SAEs) of the LLM as analytical probes. These SAEs remain perfectly aligned with the unchanged language model and serve as a snapshot of the learned language feature-representations. Through systematic analysis of SAE reconstruction error, sparsity patterns, and feature SAE descriptions, we reveal the layer-wise progression through which visual representations gradually align with language feature representations, converging in middle-to-later layers. This suggests a fundamental misalignment between ViT outputs and early LLM layers, raising important questions about whether current adapter-based architectures optimally facilitate cross-modal representation learning.
논문 링크
이해하고 사고하며 답하다: 대형 멀티모달 모델을 활용한 시각 추론의 발전 / Understand, Think, and Answer: Advancing Visual Reasoning with Large Multimodal Models
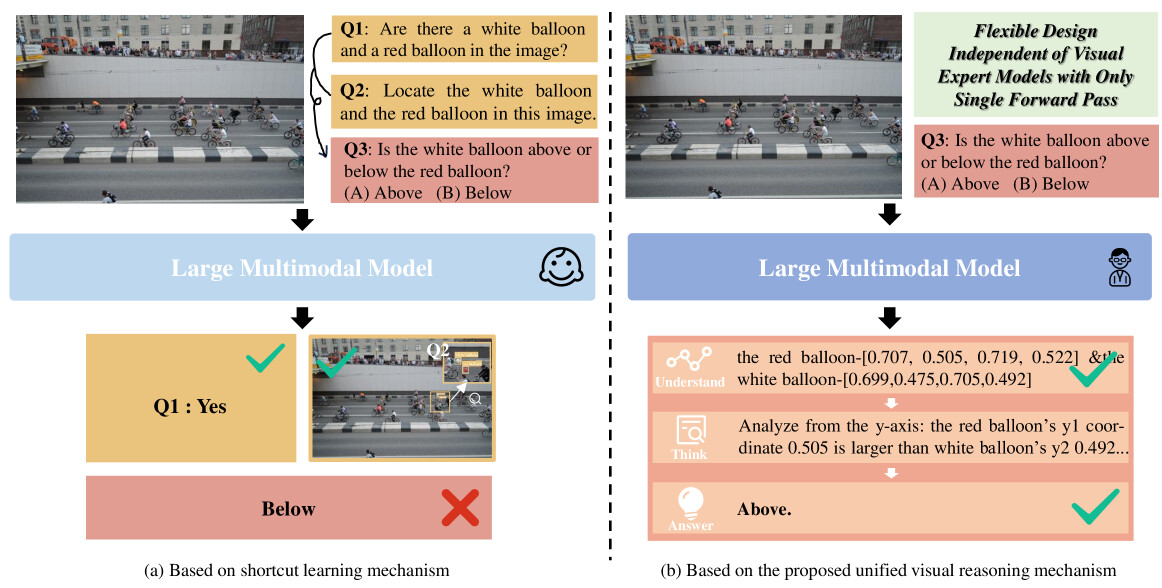
논문 소개
대규모 멀티모달 모델(Large Multimodal Models, LMMs)은 시각-언어 및 시각 중심 과제에서 뛰어난 성능을 보이나, 복합적 구성 추론(compositional reasoning) 능력 통합에는 한계가 있습니다. 이를 개선하기 위해, 본 연구는 LMM이 내재된 시각 이해 및 그라운딩(grounding) 능력을 활용하여 복잡한 문제를 한 번의 순전파(forwarding)로 인간과 유사한 이해-사고-응답 과정을 수행하도록 하는 통합 시각 추론 메커니즘을 제안합니다. 또한, 33만 4천 개의 시각 지시문 데이터를 구축하여 다양한 장면과 다중 기초 시각 능력을 포함한 학습을 진행하였으며, 이를 통해 개발된 Griffon-R 모델은 복합 시각 추론 벤치마크에서 우수한 성능을 보이고 다중모달 능력 전반을 향상시켰습니다. 데이터와 모델, 코드는 곧 공개될 예정입니다.
논문 초록(Abstract)
대규모 멀티모달 모델(LMM)은 최근 비전-언어 및 비전 중심 과제에서 뛰어난 시각 이해 성능을 보여주고 있습니다. 그러나 이들은 복합적 추론을 위한 고급 과제 특화 기능 통합에 있어 한계를 보이며, 진정으로 유능한 일반 비전 모델로 나아가는 데 장애가 되고 있습니다. 이를 해결하기 위해, 본 논문에서는 LMM이 내재된 능력(예: 그라운딩 및 시각 이해 능력)을 활용하여 복잡한 복합 문제를 해결할 수 있는 통합 시각 추론 메커니즘을 제안합니다. 기존의 단축 학습 메커니즘과 달리, 본 접근법은 인간과 유사한 이해-사고-응답 과정을 도입하여, 다중 추론이나 외부 도구 없이 단일 포워딩 과정에서 모든 단계를 완료할 수 있도록 합니다. 이러한 설계는 기초적인 시각 능력과 일반 질의응답 간의 간극을 메우며, LMM이 복잡한 시각 추론에 대해 신뢰할 수 있고 추적 가능한 응답을 생성하도록 유도합니다. 한편, 본 연구에서는 일반 장면과 텍스트가 풍부한 장면을 모두 포함하고 여러 기초 시각 능력을 아우르는 33만 4천 개의 시각 지시 샘플을 선별하였습니다. 학습된 모델인 Griffon-R은 자동 이해, 자기 사고 및 추론 응답의 엔드투엔드(end-to-end) 능력을 갖추고 있습니다. 종합적인 실험 결과, Griffon-R은 VSR 및 CLEVR을 포함한 복잡한 시각 추론 벤치마크에서 뛰어난 성능을 달성할 뿐만 아니라, MMBench 및 ScienceQA와 같은 다양한 벤치마크에서 멀티모달 능력도 향상시켰음을 보여줍니다. 데이터, 모델 및 코드는 곧 Griffon/Griffon-R at master · jefferyZhan/Griffon · GitHub 에 공개될 예정입니다.
Large Multimodal Models (LMMs) have recently demonstrated remarkable visual understanding performance on both vision-language and vision-centric tasks. However, they often fall short in integrating advanced, task-specific capabilities for compositional reasoning, which hinders their progress toward truly competent general vision models. To address this, we present a unified visual reasoning mechanism that enables LMMs to solve complicated compositional problems by leveraging their intrinsic capabilities (e.g. grounding and visual understanding capabilities). Different from the previous shortcut learning mechanism, our approach introduces a human-like understanding-thinking-answering process, allowing the model to complete all steps in a single pass forwarding without the need for multiple inferences or external tools. This design bridges the gap between foundational visual capabilities and general question answering, encouraging LMMs to generate faithful and traceable responses for complex visual reasoning. Meanwhile, we curate 334K visual instruction samples covering both general scenes and text-rich scenes and involving multiple foundational visual capabilities. Our trained model, Griffon-R, has the ability of end-to-end automatic understanding, self-thinking, and reasoning answers. Comprehensive experiments show that Griffon-R not only achieves advancing performance on complex visual reasoning benchmarks including VSR and CLEVR, but also enhances multimodal capabilities across various benchmarks like MMBench and ScienceQA. Data, models, and codes will be release at Griffon/Griffon-R at master · jefferyZhan/Griffon · GitHub soon.
논문 링크
더 읽어보기
FlexSelect: 효율적인 장기 영상 이해를 위한 유연한 토큰 선택 전략 / FlexSelect: Flexible Token Selection for Efficient Long Video Understanding

논문 소개
FlexSelect는 긴 영상 이해를 위한 효율적인 토큰 선택(token selection) 전략으로, 비디오 대형 언어 모델(VideoLLM)의 높은 계산 및 메모리 요구를 줄이는 데 중점을 둡니다. 크로스모달 주의(attention) 패턴을 활용해 의미적으로 중요한 영상 토큰을 식별하고, 훈련이 필요 없는 토큰 랭킹과 이를 모방하는 경량 선택기(rank-supervised selector)를 결합하여 중복 토큰을 효과적으로 필터링합니다. 이 방법은 LLaVA-Video, InternVL, Qwen-VL 등 다양한 VideoLLM에 플러그인 형태로 쉽게 통합 가능하며, 여러 장기 영상 벤치마크에서 성능 향상과 최대 9배의 속도 개선을 입증하였습니다. FlexSelect는 긴 영상 처리에서 계산 효율성과 성능을 동시에 달성할 수 있는 유망한 접근법입니다.
논문 초록(Abstract)
장기 영상 이해는 매우 높은 계산 및 메모리 요구량으로 인해 비디오 대형 언어 모델(VideoLLM)에게 큰 도전 과제를 제시합니다. 본 논문에서는 장기 영상을 처리하기 위한 유연하고 효율적인 토큰 선택 전략인 FlexSelect를 제안합니다. FlexSelect는 참조 트랜스포머 층에서 추출한 교차 모달 어텐션 패턴을 활용하여 가장 의미론적으로 관련성 높은 콘텐츠를 식별하고 유지합니다. 이 방법은 두 가지 핵심 구성 요소로 이루어져 있습니다: (1) 각 비디오 토큰의 중요도를 추정하기 위해 신뢰할 수 있는 교차 모달 어텐션 가중치를 활용하는 학습 불필요 토큰 랭킹 파이프라인, (2) 이러한 랭킹을 모방하고 중복 토큰을 필터링하도록 학습된 랭크-감독 경량 셀렉터입니다. 이 범용 접근법은 LLaVA-Video, InternVL, Qwen-VL 등 다양한 VideoLLM 아키텍처에 플러그 앤 플레이 모듈로 원활하게 통합되어 시간적 문맥 길이를 확장할 수 있습니다. 실험적으로, FlexSelect는 VideoMME, MLVU, LongVB, LVBench 등 여러 장기 영상 벤치마크에서 뛰어난 성능 향상을 보여줍니다. 또한, LLaVA-Video-7B 모델에서 최대 9배의 속도 향상을 달성하는 등 효율적인 장기 영상 이해를 위한 FlexSelect의 가능성을 입증합니다. 프로젝트 페이지는 다음에서 확인할 수 있습니다: FlexSelect
Long-form video understanding poses a significant challenge for video large language models (VideoLLMs) due to prohibitively high computational and memory demands. In this paper, we propose FlexSelect, a flexible and efficient token selection strategy for processing long videos. FlexSelect identifies and retains the most semantically relevant content by leveraging cross-modal attention patterns from a reference transformer layer. It comprises two key components: (1) a training-free token ranking pipeline that leverages faithful cross-modal attention weights to estimate each video token's importance, and (2) a rank-supervised lightweight selector that is trained to replicate these rankings and filter redundant tokens. This generic approach can be seamlessly integrated into various VideoLLM architectures, such as LLaVA-Video, InternVL and Qwen-VL, serving as a plug-and-play module to extend their temporal context length. Empirically, FlexSelect delivers strong gains across multiple long-video benchmarks including VideoMME, MLVU, LongVB, and LVBench. Moreover, it achieves significant speed-ups (for example, up to 9 times on a LLaVA-Video-7B model), highlighting FlexSelect's promise for efficient long-form video understanding. Project page available at: FlexSelect
논문 링크
더 읽어보기
비디오 LLM 학습에서 비디오의 중요성은 어느 정도일까? / How Important are Videos for Training Video LLMs?
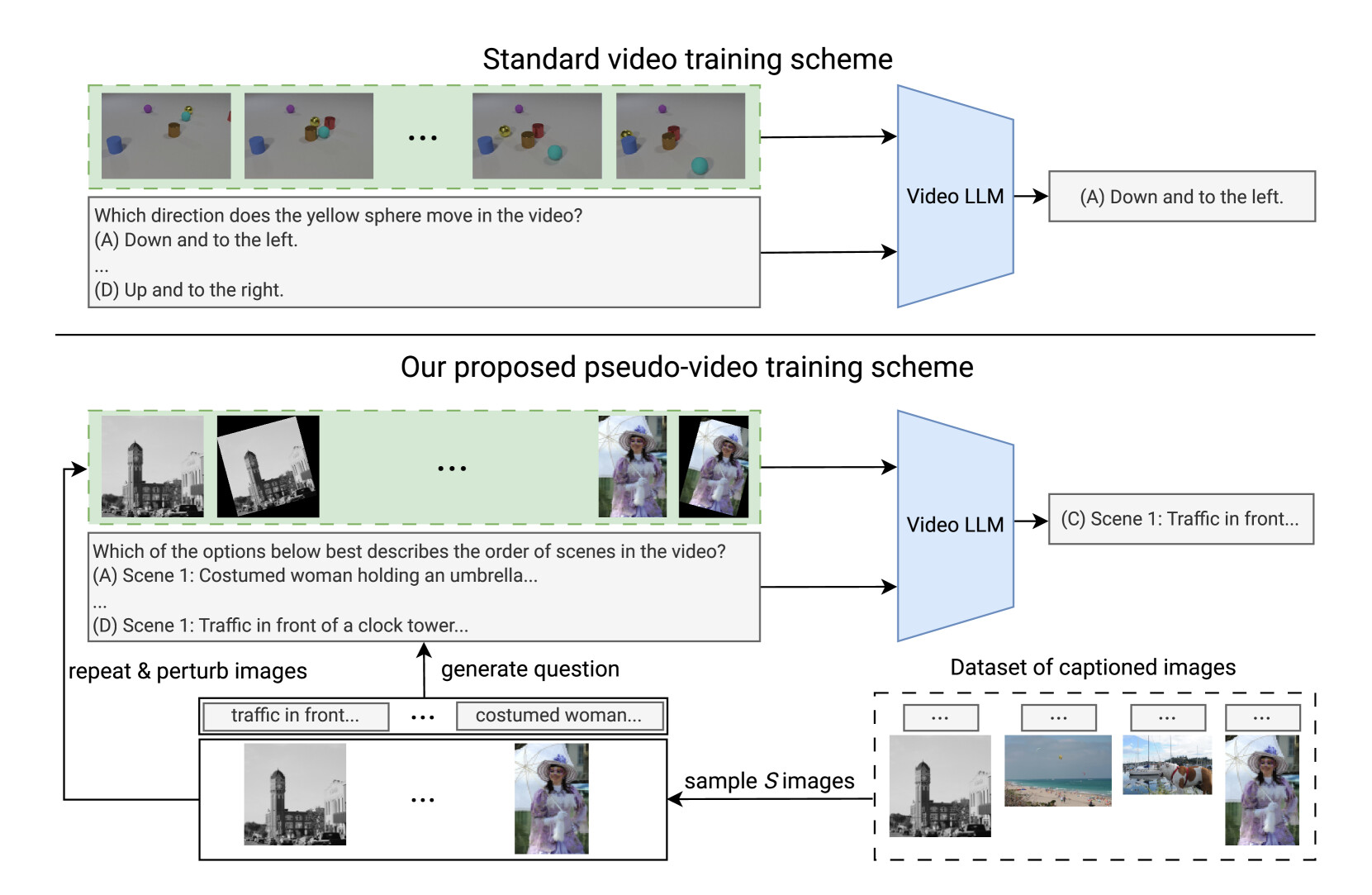
논문 소개
비디오 대형 언어 모델(Video LLMs)은 주로 텍스트 기반 사전학습 모델을 이미지 및 비디오 캡션 데이터로 미세조정하여 개발됩니다. 연구 결과, 이미지 전용 학습만으로도 시간적 추론(temporal reasoning) 능력이 상당히 향상되며, 비디오 특화 학습에서 얻는 성능 향상은 예상보다 미미한 것으로 나타났습니다. 특히, LongVU 알고리즘을 적용한 이미지 학습 모델이 TVBench 벤치마크에서 우수한 성능을 보였고, 주석이 달린 이미지와 질문 시퀀스를 활용한 간단한 미세조정 기법도 비디오 학습 모델과 유사하거나 더 나은 결과를 도출했습니다. 이는 현재 비디오 학습 방식이 실제 비디오의 풍부한 시간적 특성을 충분히 활용하지 못하고 있음을 시사하며, 이미지 학습 모델의 시간적 추론 메커니즘과 비디오 학습의 비효율성에 대한 추가 연구가 필요함을 강조합니다.
논문 초록(Abstract)
비디오 대형 언어 모델(LLM)에 대한 연구는 최근 몇 년간 급속히 발전하여 수많은 모델과 벤치마크가 등장하였습니다. 일반적으로 이러한 모델들은 사전 학습된 텍스트 전용 LLM으로 초기화된 후 이미지 및 비디오 캡션 데이터셋 모두에 대해 미세 조정됩니다. 본 논문에서는 이미지 전용 학습만으로도 비디오 LLM이 시간적 추론 능력을 예상보다 더 잘 수행하며, 비디오 특화 학습으로 인한 성능 향상은 의외로 미미하다는 점을 발견하였습니다. 구체적으로, 최근 LongVU 알고리즘으로 학습된 두 개의 LLM의 이미지 학습 버전이 시간적 추론 벤치마크인 TVBench에서 우연 수준을 훨씬 상회하는 성과를 보임을 증명합니다. 또한, 시간적 능력을 겨냥한 주석 이미지와 질문 시퀀스를 활용한 간단한 미세 조정 방식을 제안합니다. 이 기본선은 비디오 학습 LLM이 달성하는 성능에 근접하거나 때로는 이를 능가하는 시간적 추론 성능을 나타냅니다. 이는 현 모델들이 실제 비디오에서 발견되는 풍부한 시간적 특징을 최적으로 활용하지 못하고 있음을 시사합니다. 본 분석은 이미지 학습 LLM이 시간적 추론을 수행할 수 있는 메커니즘과 현재 비디오 학습 방식의 비효율성을 초래하는 병목 현상에 대한 추가 연구를 촉진합니다.
Research into Video Large Language Models (LLMs) has progressed rapidly, with numerous models and benchmarks emerging in just a few years. Typically, these models are initialized with a pretrained text-only LLM and finetuned on both image- and video-caption datasets. In this paper, we present findings indicating that Video LLMs are more capable of temporal reasoning after image-only training than one would assume, and that improvements from video-specific training are surprisingly small. Specifically, we show that image-trained versions of two LLMs trained with the recent LongVU algorithm perform significantly above chance level on TVBench, a temporal reasoning benchmark. Additionally, we introduce a simple finetuning scheme involving sequences of annotated images and questions targeting temporal capabilities. This baseline results in temporal reasoning performance close to, and occasionally higher than, what is achieved by video-trained LLMs. This suggests suboptimal utilization of rich temporal features found in real video by current models. Our analysis motivates further research into the mechanisms that allow image-trained LLMs to perform temporal reasoning, as well as into the bottlenecks that render current video training schemes inefficient.
논문 링크
더 읽어보기
Dolphin: 이종 앵커 프롬프트를 활용한 문서 이미지 파싱 / Dolphin: Document Image Parsing via Heterogeneous Anchor Prompting
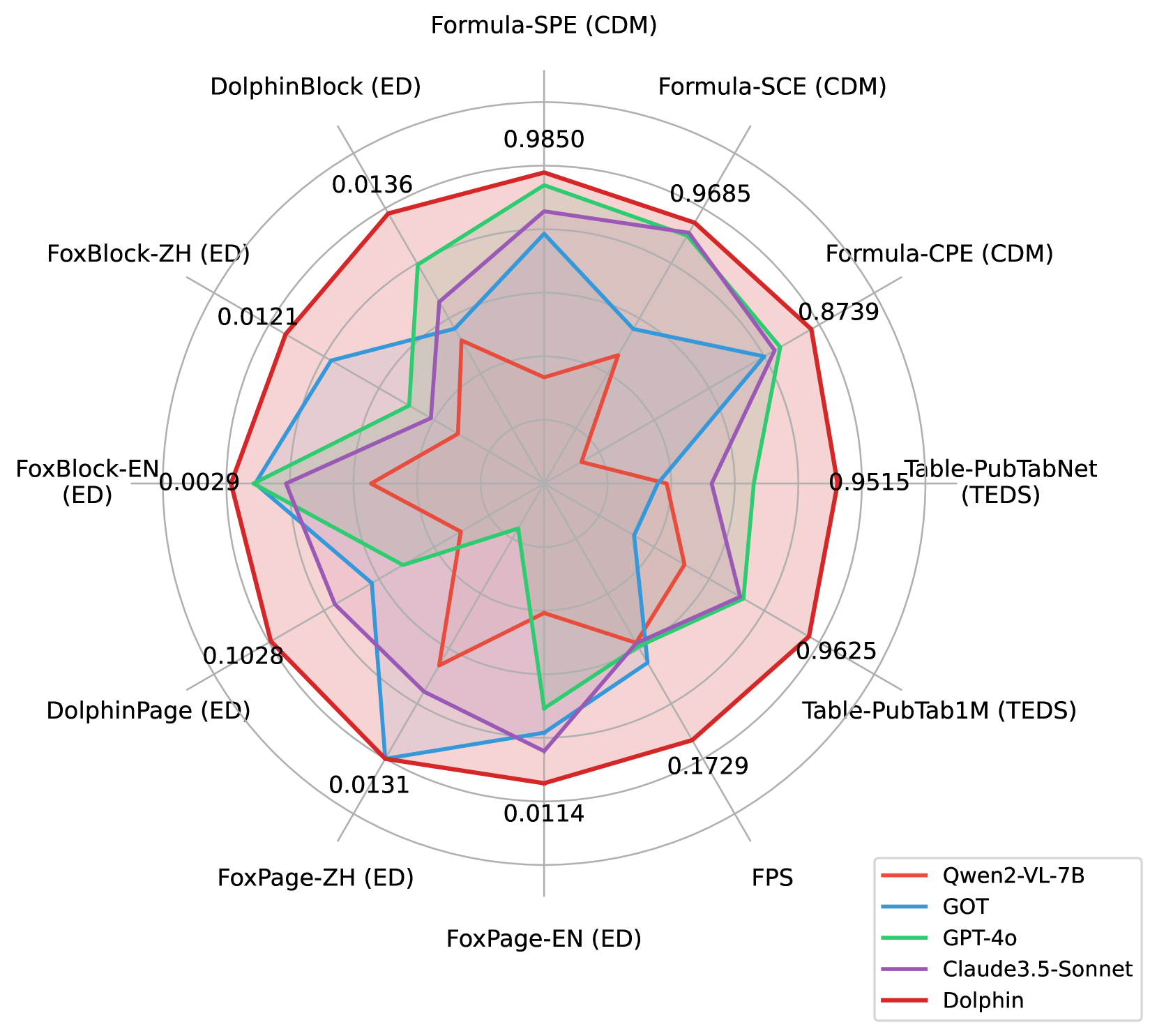
논문 소개
문서 이미지 파싱은 텍스트, 도형, 수식, 표 등 복잡하게 얽힌 요소들로 인해 어려움이 있습니다. 기존 방법들은 전문 모델을 조합하거나 페이지 단위로 자동 생성하는 방식을 사용하지만, 통합 비용과 효율성 문제, 레이아웃 구조 손상 등의 한계가 존재합니다. Dolphin은 이질적인 앵커(anchor)와 작업별 프롬프트(prompt)를 활용해 먼저 레이아웃 요소를 순서대로 생성한 후, 이를 기반으로 병렬 콘텐츠 파싱을 수행하는 새로운 다중모달 문서 이미지 파싱 모델입니다. 3천만 개 이상의 대규모 데이터셋으로 학습되었으며, 다양한 벤치마크에서 최첨단 성능과 경량화된 구조를 통한 우수한 효율성을 입증하였습니다.
논문 초록(Abstract)
문서 이미지 파싱은 텍스트 단락, 도형, 수식, 표 등 복잡하게 얽혀 있는 요소들로 인해 매우 어려운 과제입니다. 기존 접근법들은 전문화된 개별 모델들을 조합하거나 페이지 단위 콘텐츠를 자기회귀적으로 직접 생성하는 방식을 사용하지만, 이들은 준수한 성능에도 불구하고 통합 오버헤드, 효율성 병목 현상, 그리고 레이아웃 구조 저하 문제에 직면합니다. 이러한 한계를 극복하기 위해, 본 논문에서는 분석-후-파싱(analyze-then-parse) 패러다임을 따르는 새로운 멀티모달 문서 이미지 파싱 모델인 \textit{Dolphin}(\textit{\textbf{Do}cument Image \textbf{P}arsing via \textbf{H}eterogeneous Anchor Prompt\textbf{in}g})을 제안합니다. 첫 번째 단계에서 Dolphin은 읽기 순서에 따른 레이아웃 요소 시퀀스를 생성합니다. 이 이종 요소들은 앵커(anchor) 역할을 하며, 작업별 프롬프트와 결합되어 두 번째 단계에서 Dolphin에 병렬 콘텐츠 파싱을 위해 다시 입력됩니다. Dolphin 학습을 위해, 다중 세분화 파싱 작업을 포함하는 3천만 개 이상의 대규모 데이터셋을 구축하였습니다. 널리 사용되는 벤치마크와 자체 구축 벤치마크에서의 종합적인 평가를 통해, Dolphin은 다양한 페이지 및 요소 수준 설정에서 최첨단 성능을 달성함과 동시에 경량 아키텍처와 병렬 파싱 메커니즘을 통해 우수한 효율성을 보장합니다. 코드와 사전학습 모델은 GitHub - bytedance/Dolphin: The official repo for “Dolphin: Document Image Parsing via Heterogeneous Anchor Prompting”, ACL, 2025. 에서 공개되어 있습니다.
Document image parsing is challenging due to its complexly intertwined elements such as text paragraphs, figures, formulas, and tables. Current approaches either assemble specialized expert models or directly generate page-level content autoregressively, facing integration overhead, efficiency bottlenecks, and layout structure degradation despite their decent performance. To address these limitations, we present \textit{Dolphin} (\textit{\textbf{Do}cument Image \textbf{P}arsing via \textbf{H}eterogeneous Anchor Prompt\textbf{in}g}), a novel multimodal document image parsing model following an analyze-then-parse paradigm. In the first stage, Dolphin generates a sequence of layout elements in reading order. These heterogeneous elements, serving as anchors and coupled with task-specific prompts, are fed back to Dolphin for parallel content parsing in the second stage. To train Dolphin, we construct a large-scale dataset of over 30 million samples, covering multi-granularity parsing tasks. Through comprehensive evaluations on both prevalent benchmarks and self-constructed ones, Dolphin achieves state-of-the-art performance across diverse page-level and element-level settings, while ensuring superior efficiency through its lightweight architecture and parallel parsing mechanism. The code and pre-trained models are publicly available at GitHub - bytedance/Dolphin: The official repo for “Dolphin: Document Image Parsing via Heterogeneous Anchor Prompting”, ACL, 2025.
논문 링크
더 읽어보기
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 뉴스 발행에 힘이 됩니다~
를 눌러주시면 뉴스 발행에 힘이 됩니다~ ![]()