
Dophin 모델 소개
문서 이미지를 텍스트, 수식, 표, 그림 등 다양한 요소로 나누고 이를 자동으로 추출하는 기술은 여전히 어렵고 복잡한 문제입니다. ByteDance가 발표한 Dolphin(Document Image Parsing via Heterogeneous Anchor Prompting)은 이를 해결하기 위해 ‘분석 후 파싱(analyze-then-parse)’ 방식을 제안하며, 학계와 산업계의 최신 모델들과 비교해 속도와 성능 모두에서 우수한 결과를 보여주고 있습니다.

Dolphin은 문서 이미지에서 복잡하게 얽힌 구성 요소를 인식하고 이를 구조화된 형태로 파싱하는 데 초점을 맞춘 모델입니다. 기존 방식은 보통 OCR 기반 파이프라인을 사용하거나 VLM(비전-언어 모델) 기반으로 전체 페이지를 생성해내는 방식이었지만, 이들은 효율성과 레이아웃 보존 측면에서 한계를 보였습니다.
이에 Dolphin은 2단계 접근을 제안합니다. 첫 번째 단계에서는 전체 문서 페이지의 요소들을 읽기 순서에 따라 나열하고, 두 번째 단계에서는 각 요소별 프롬프트를 통해 병렬로 파싱을 수행합니다. 특히 이때 사용되는 heterogeneous anchor prompting이 핵심 기술로, 요소별 특화된 파싱이 가능합니다.
ByteDance는 이를 위해 3천만 개 이상의 학습 데이터를 구축했고, 다양한 벤치마크에서 최신 모델들과 비교해 성능을 입증했습니다. Dolphine과 기존의 OCR 기반 파이프라인, VLM 기반 모델들과의 주요 특징을 비교하면 다음과 같습니다:
| 모델/방식 | 구조 | 특징 | 성능 | 속도 |
|---|---|---|---|---|
| OCR 기반 파이프라인 | 레이아웃 분석 + OCR + 후처리 | 복잡한 모델 조합 필요 | 요소 인식 성능 높음 | 느림 |
| VLM 기반 | End-to-End autoregressive | 시맨틱 추론 강점 | 레이아웃 깨짐 우려 | 느림 |
| Dolphin | 분석 후 파싱 (2단계) | 병렬 처리 + 프롬프트 기반 파싱 | SOTA 수준 | 빠름 (2배 이상 빠름) |
특히 Mathpix, GOT, GPT-4V 등과 비교해도 복잡 문서에서의 성능과 FPS 측면에서 확연히 앞서는 결과를 보여줍니다.
Dophin 모델의 구조 및 동작 방식
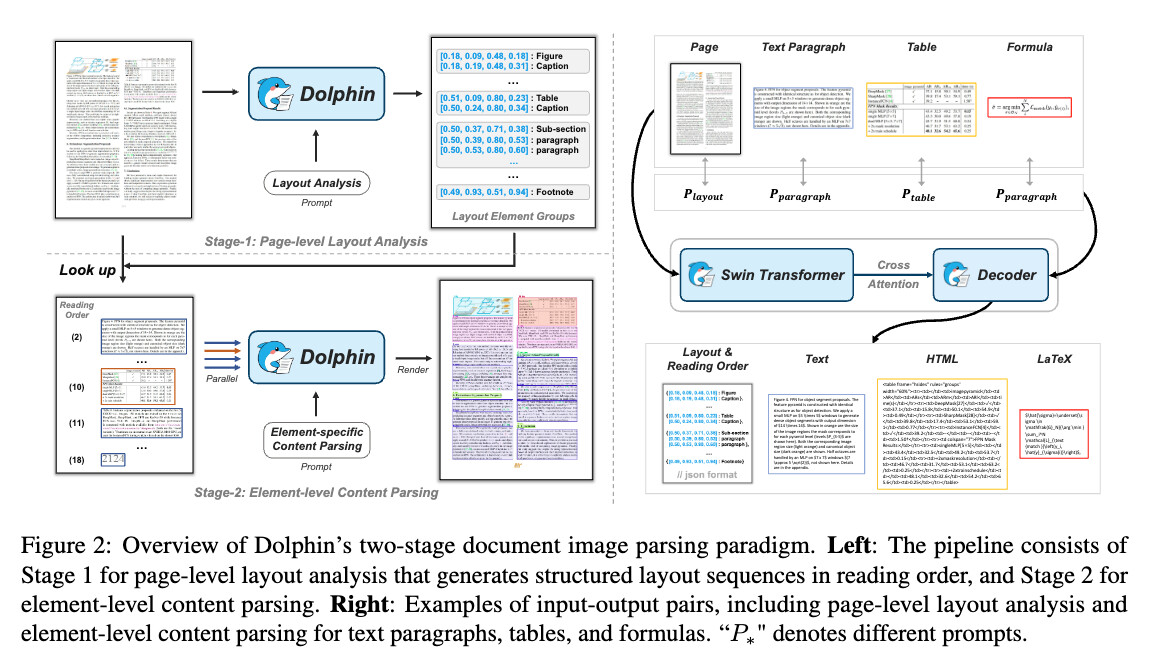
Dolphin은 분석 후 파싱(analyze-then-parse) 방식을 따르는 2단계 구조의 Vision-Language Model (VLM)입니다. 이 방식은 복잡한 문서 이미지를 정확하고 빠르게 파싱하기 위한 구조로, 페이지 전체를 한번에 처리하지 않고 요소 단위로 병렬 처리할 수 있다는 점이 핵심입니다.
| 구성 | 상세 |
|---|---|
| Vision Encoder | Swin Transformer (window=7, 4-stage) |
| Language Decoder | mBART, 10-layer, hidden dim 1024 |
| 병렬 처리 방식 | 요소 16개 단위로 배치 처리 |
| 입력 이미지 전처리 | 896x896 정규화 후 패딩 |
| 사전학습 초기화 | Donut 모델에서 weight 가져옴 후 프롬프트 기반 튜닝 |
Dolphin 모델의 주요 구성은 위 표와 같으며, 각 단계는 다음과 같이 동작합니다:

Stage 1: Page-level Layout Analysis
Dolphin의 첫 번째 단계는 문서 이미지의 전체 레이아웃을 분석하는 과정입니다. 이 단계에서는 먼저 Swin Transformer를 기반으로 한 비전 인코더가 이미지 전체를 받아들여, 페이지 내의 시각적 패턴과 요소들을 임베딩 벡터로 변환합니다. 이 과정에서 문서 내의 텍스트, 표, 그림, 수식 등 다양한 요소들의 존재와 그 위치 정보가 파악됩니다.
이후 mBART 기반의 디코더가 ‘이 문서의 읽기 순서를 분석하라’는 프롬프트를 입력받고, 이전 인코더로부터 전달된 시각 정보를 바탕으로 문서 내 요소들을 읽기 순서대로 나열합니다. 각 요소는 그 유형(예: 텍스트, 표, 수식 등), 위치 좌표(bounding box), 그리고 시퀀스 상의 순서를 포함합니다. 이 과정을 통해 문서 전체의 구조를 파악하고, 이후 각 요소를 파싱하기 위한 기준점(anchor)들이 생성됩니다. 이 분석 결과는 Stage 2에서 각 요소를 개별적으로 처리하기 위한 기반 정보로 활용됩니다.
Stage 2: Element-level Parsing
두 번째 단계는 Stage 1에서 생성된 요소 리스트를 바탕으로, 각 요소의 콘텐츠를 실제로 추출하는 과정입니다. 먼저 Stage 1에서 지정한 요소 위치 정보를 기반으로 이미지에서 해당 영역을 잘라냅니다(crop). 이렇게 잘라낸 이미지들은 다시 Swin Transformer에 입력되어 요소별 시각 임베딩이 생성되며, 이 작업은 병렬로 처리됩니다.
이후, 요소의 타입(예: 텍스트 단락, 표, 수식 등)에 따라 각기 다른 프롬프트가 주어집니다. 예를 들어, 표는 HTML 형식으로 출력되도록 “이 이미지를 HTML 테이블로 변환하세요”라는 프롬프트가 사용되고, 수식은 LaTeX 형식으로 출력되며, 일반 텍스트는 텍스트 단락으로 파싱되도록 프롬프트가 제공됩니다. mBART 디코더는 이러한 요소별 임베딩과 프롬프트를 받아 최종적으로 요소의 실제 내용을 텍스트 형태로 생성하게 됩니다.
이러한 방식은 각 요소를 독립적으로, 그리고 병렬적으로 처리할 수 있도록 하여 전체 문서 파싱 속도를 크게 향상시킵니다. 또한, 요소 단위의 특화된 프롬프트 덕분에 복잡한 구조나 레이아웃에서도 높은 정확도를 유지할 수 있습니다. 결국 Stage 2는 문서의 각 구성 요소를 의미 있는 구조화된 데이터로 변환하는 핵심 단계이며, 이를 통해 Dolphin은 시각적으로 표현된 문서를 기계가 이해할 수 있는 형식으로 재구성하게 됩니다.
데이터셋
Dolphin 모델은 고성능 문서 파싱 능력을 갖추기 위해 방대한 규모의 다종 문서 데이터셋을 활용해 학습되었습니다. 총 3천만 개 이상의 샘플이 사용되었으며, 이는 페이지 단위 문서와 요소 단위 데이터 모두를 포함합니다. 학습 데이터셋은 다양성과 실제 문서 형태 반영을 위해 여러 출처와 포맷으로 구성되어 있습니다.
-
Mixed Documents: 우선 가장 대표적인 구성은 혼합형 문서(Mixed Documents)입니다. 약 12만 개의 문서가 수집되었으며, 여기에는 교육 자료(시험지, 교과서), 출판물(잡지, 신문), 그리고 기업 문서(프레젠테이션, 보고서 등)가 포함됩니다. 이 데이터는 문서 내 요소들의 경계 박스 정보뿐만 아니라 읽기 순서 정보까지 함께 포함되어 있어, Dolphin의 Stage 1 레이아웃 분석 학습에 매우 유용합니다.
-
HTML 기반 문서: HTML 문서는 Wikipedia(중/영문)를 크롤링하여 웹 렌더링을 통해 이미지화한 후, 그로부터 텍스트, 문단, 단어, 글자 수준의 경계 정보를 추출합니다. 이 방식으로 약 437만 개의 샘플이 생성되었고, 다양한 시각적 표현을 위해 렌더링 시 폰트를 무작위로 선택해 시각적 다양성을 확보했습니다.
-
LaTeX 기반 문서: arXiv에서 수집된 약 50만 개의 LaTeX 문서를 기반으로 합니다. ‘LaTeX Rainbow’라는 렌더링 프레임워크를 활용해 수식, 그림, 표 등 요소들을 각각 구분된 색상으로 시각화하며, 문서 내 계층 구조 및 요소 간 관계(예: 수식-캡션, 섹션-본문)를 보존한 상태로 이미지 및 주석을 생성합니다.
-
Markdown 문서: GitHub에서 크롤링한 71만 개의 Markdown 문서를 Pandoc으로 PDF로 변환하고, 이를 기반으로 문단, 단락, 줄, 단어 수준의 경계 정보를 생성합니다. 수식은 다양한 색상으로 렌더링한 후 픽셀 매칭 기법으로 블록을 감지하는 방식으로 처리되며, 구조적 텍스트 인식에 적합한 학습 데이터를 제공합니다.
-
Table 데이터셋: 표 인식을 위한 전문 데이터셋으로는 PubTabNet(568K 표)과 PubTab1M(1M 표)이 사용됩니다. 이들은 과학 논문에서 추출한 표 이미지와 함께 HTML 기반의 정답 데이터를 포함하고 있어, 구조적 파싱 학습에 최적화된 자료입니다.
-
Formula 데이터셋: 수식 인식을 위한 데이터는 arXiv에서 추출한 2,300만 개의 LaTeX 수식 표현을 바탕으로 구성되었으며, 단일 수식에서부터 멀티라인 블록 수식까지 다양하게 포함되어 있습니다. 각 수식은 XeTeX을 활용해 다양한 배경과 폰트로 렌더링되어, 모델의 수식 일반화 능력을 높였습니다.
Dophin의 성능적 특징
Dolphin은 문서 이미지 파싱 분야에서 기존 모델들이 직면한 한계를 극복하기 위해 고안된 구조로, 다양한 수준의 벤치마크에서 최고 수준의 성능을 입증했습니다. 특히 페이지 수준과 요소 수준에서의 정밀한 인식 능력과 더불어 효율적인 처리 속도는 이 모델의 큰 강점입니다.
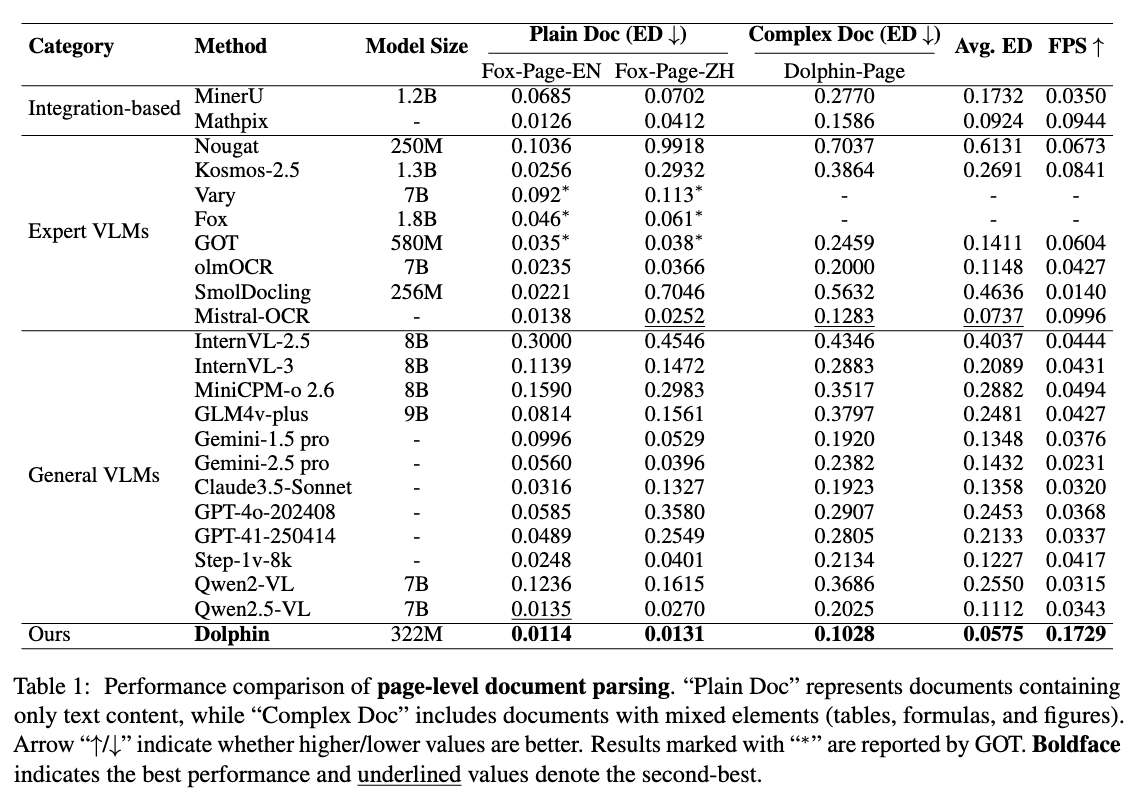
페이지 수준의 평가에서는 Fox-Page와 Dolphin-Page라는 두 가지 주요 벤치마크를 통해 성능을 측정했습니다. Fox-Page는 순수 텍스트 기반의 문서(영문/중문 혼합)로 구성되어 있고, Dolphin-Page는 표, 수식, 그림이 혼재된 복합 레이아웃 문서로 구성되어 있어 더 높은 난이도를 가집니다. 평가 지표로 사용된 Edit Distance(ED) 기준에서, Dolphin은 영어 기준 0.0114, 중국어 기준 0.0131이라는 탁월한 결과를 기록했습니다. 이는 GPT-4.1이나 GOT 같은 대형 비전-언어 모델들과 비교했을 때 세 배 이상 정확한 결과이며, 복합 문서가 포함된 Dolphin-Page에서도 0.1283이라는 SOTA 성능을 보여 기존 모델들(GOT 0.1519, Mathpix 0.1811)을 모두 능가합니다.
성능뿐만 아니라 Dolphin은 처리 속도에서도 경쟁 우위를 갖고 있습니다. 병렬 파싱 구조 덕분에 1초당 0.1729 페이지를 처리할 수 있으며, 이는 Mathpix(0.0944 FPS)보다 거의 두 배 빠르고, GPT-4.1 대비 세 배 이상 빠른 수준입니다. 더욱이 Dolphin은 단 322M 파라미터 규모로 설계되어, GOT이나 GPT 계열 모델에 비해 훨씬 경량화된 구조임에도 불구하고 성능과 속도 모두에서 앞서고 있습니다.

요소 수준의 평가에서도 Dolphin은 높은 인식 정확도를 보입니다. Table 3에 따르면, 텍스트 단락(Text Paragraph), 수식(Formula), 표(Table) 세 가지 주요 요소 유형에 대해 다양한 공공 테스트셋에서 모델의 성능을 측정했습니다. 텍스트 단락 인식의 경우, Fox-Block과 Dolphin-Block에서 각각 수백 개의 문단 이미지를 기반으로 테스트했으며, Dolphin은 대부분의 샘플에서 낮은 오차율을 기록해 문단 수준의 텍스트 인식에서 우수한 성능을 증명했습니다. 수식 인식은 SPE(단순 수식), SCE(스크린 캡처), CPE(복합 수식) 세 가지 벤치마크에서 Character Difference Metric(CDM)을 사용해 평가되었는데, Dolphin은 모든 케이스에서 전문 수식 인식기와 견줄만한 경쟁력을 보였습니다. 특히 LaTeX 형식으로의 변환에서 높은 정밀도를 기록한 것이 인상적입니다.
표 인식의 경우에는 PubTabNet과 PubTab1M이라는 두 개의 대형 벤치마크를 사용했으며, 이들은 표 구조와 셀 콘텐츠를 HTML 기반으로 평가합니다. Dolphin은 TEDS(Tree-Edit-Distance-based Similarity) 점수에서 다른 모델들과 비교해 월등한 구조적 정합성을 보여주었으며, 복잡한 표 구조를 정확히 재현해내는 능력 또한 확인되었습니다.
이러한 결과는 Dolphin이 단순히 속도만 빠르거나 경량화된 모델이 아니라, 문서의 시각적 레이아웃 구조와 의미 있는 텍스트 내용을 동시에 정확히 인식할 수 있는 고성능 모델임을 보여줍니다. 특히, 프롬프트 기반의 병렬 파싱 구조와 요소별 전용 처리 방식은 실질적인 문서 파싱 작업에서 효율성과 정확도를 모두 만족시키는 매우 실용적인 접근으로 평가받고 있습니다.
 Dolphin: Document Image Parsing via Heterogeneous Anchor Prompting 논문
Dolphin: Document Image Parsing via Heterogeneous Anchor Prompting 논문
 Dolphin GitHub 저장소
Dolphin GitHub 저장소
https://github.com/bytedance/Dolphin
 Dolphin 모델 다운로드
Dolphin 모델 다운로드
 Dolphin 모델 데모
Dolphin 모델 데모
http://115.190.42.15:8888/dolphin/
이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다. ![]()
![]() 파이토치 한국 사용자 모임
파이토치 한국 사용자 모임![]() 이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일
이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일![]() 로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)
![]() 아래
아래![]() 쪽에 좋아요
쪽에 좋아요![]() 를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~
를 눌러주시면 새로운 소식들을 정리하고 공유하는데 힘이 됩니다~ ![]()